glue that binds your data ecosystem together •Open source, wricen in Python •Was started in Oct 2014 by Max Beauchemin at •IncubaXng at since 2016 •550+ contributors, 5300+ commits, 9300+ stars Overview MAD · NOV 23-24 · 2018
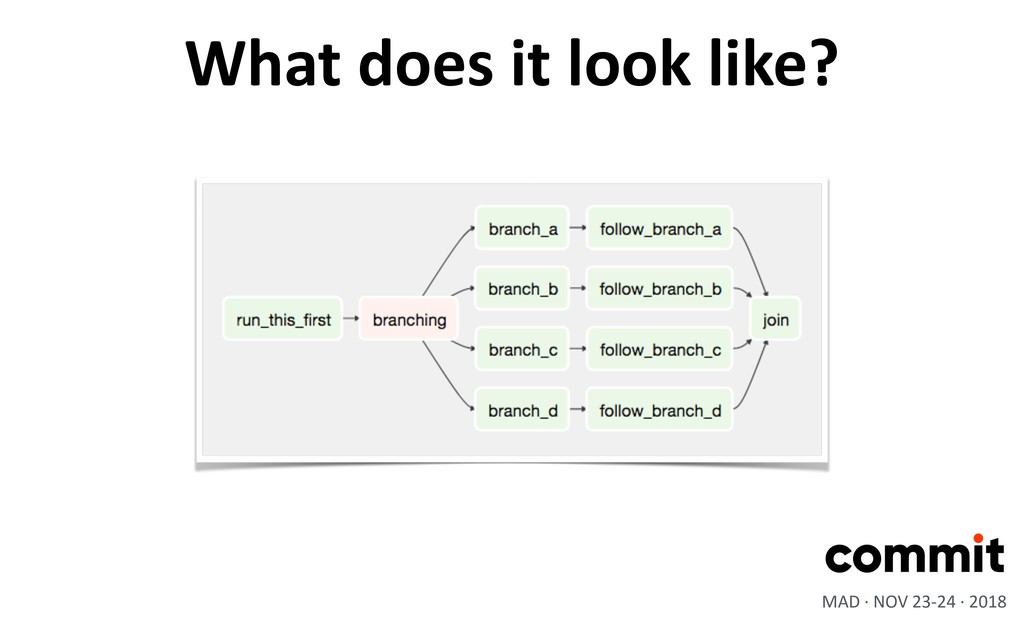
an external system to perform another acXon •Transfer: move data from one system to another •Sensor: wait for and detect some condiXon in a source system Operators MAD · NOV 23-24 · 2018
or from S3 to Hive •Built-in HiveToMySqlTransfer, S3ToHiveTransfer •Community contributed Databricks, AWS, GCP Transfer operators MAD · NOV 23-24 · 2018
criteria is met. For example, checking for a certain file has become available on S3 before using it downstream •Built-in HiveParXXonSensor, HcpSensor, S3KeySensor, SqlSensor, FTPSensor, … •Community contributed Databricks, AWS, GCP Sensor operators MAD · NOV 23-24 · 2018
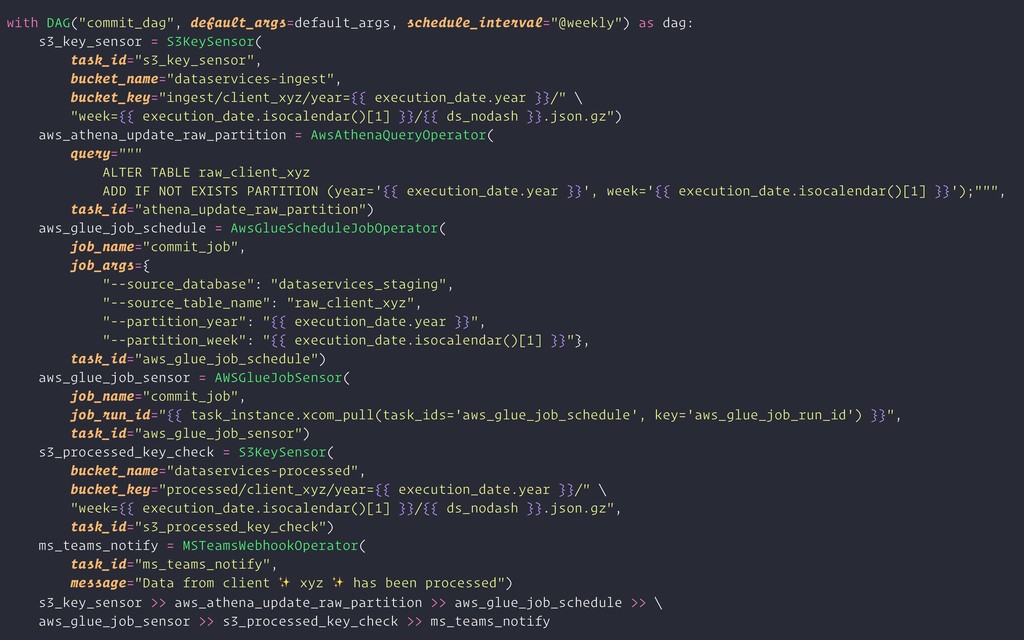
a key (a file-like instance on S3) to be present in a S3 bucket •Add a new AWS Athena parXXon •Run an AWS Glue job and wait unXl its done •NoXfy the #dataservices channel at MicrosoE Teams S3KeySensor AwsAthenaQueryOperator AwsGlueScheduleJobOperator & AWSGlueJobSensor MSTeamsWebhookOperator
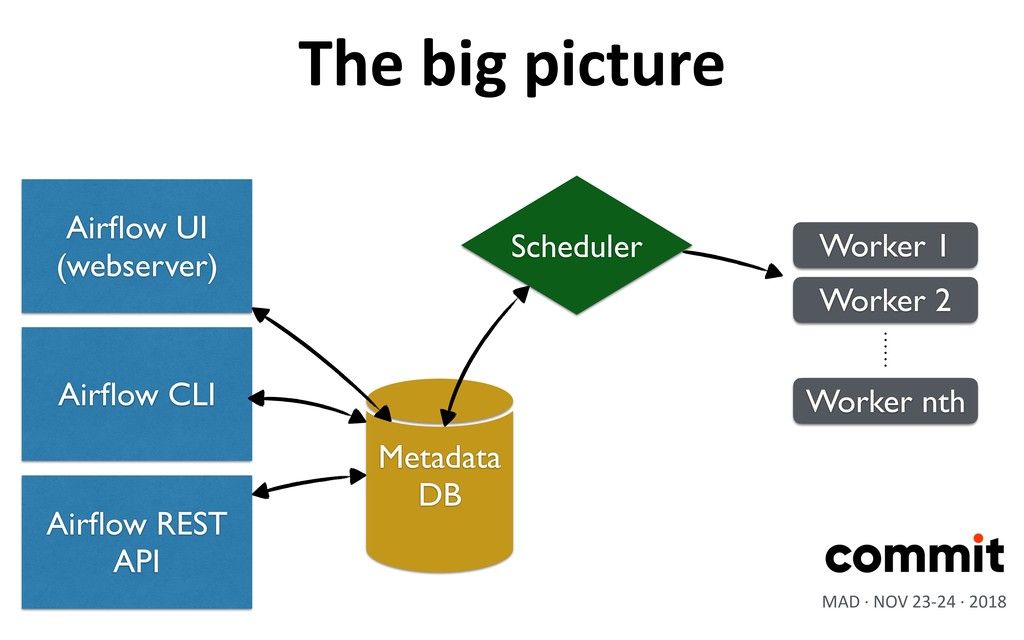
"cross communicaXon” CommunicaXon between tasks. Such as file name found by a sensor •ConnecIons: JDBCs, auth, etc. Airflow’s metadata storage MAD · NOV 23-24 · 2018
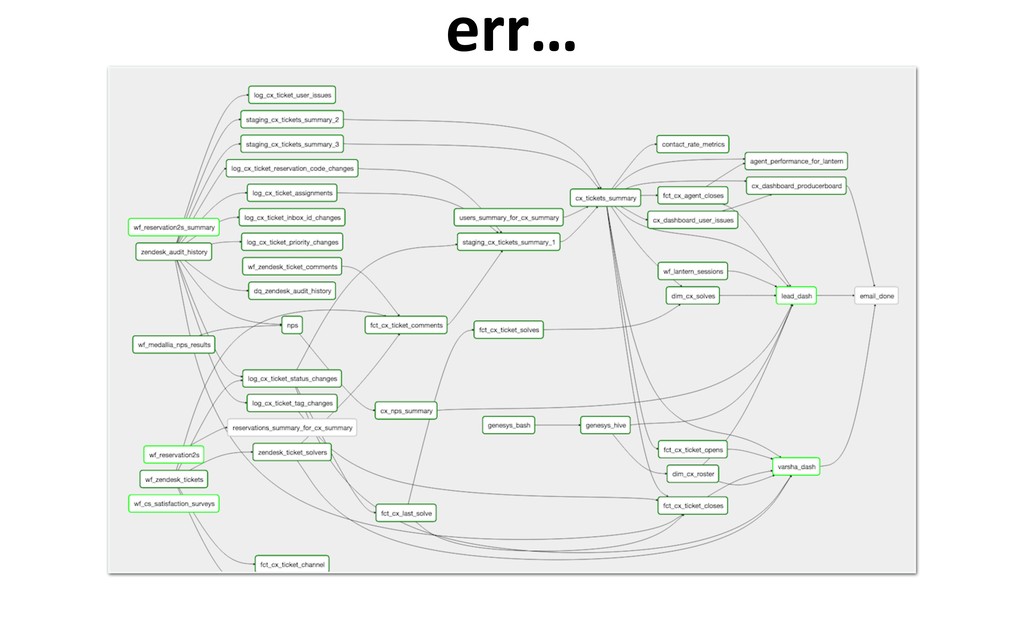
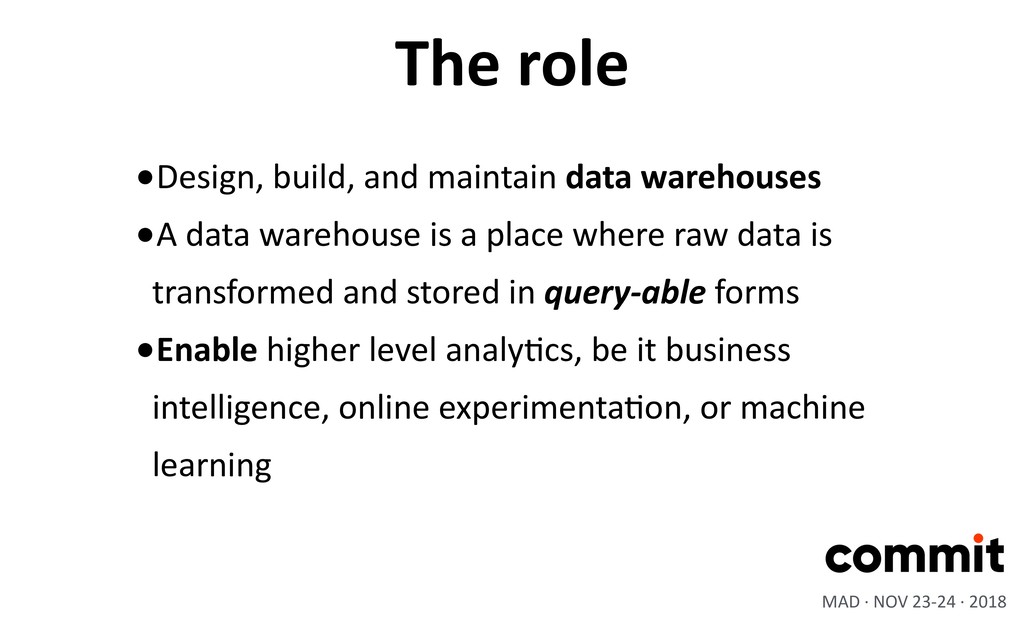
a place where raw data is transformed and stored in query-able forms •Enable higher level analyXcs, be it business intelligence, online experimentaXon, or machine learning MAD · NOV 23-24 · 2018 The role
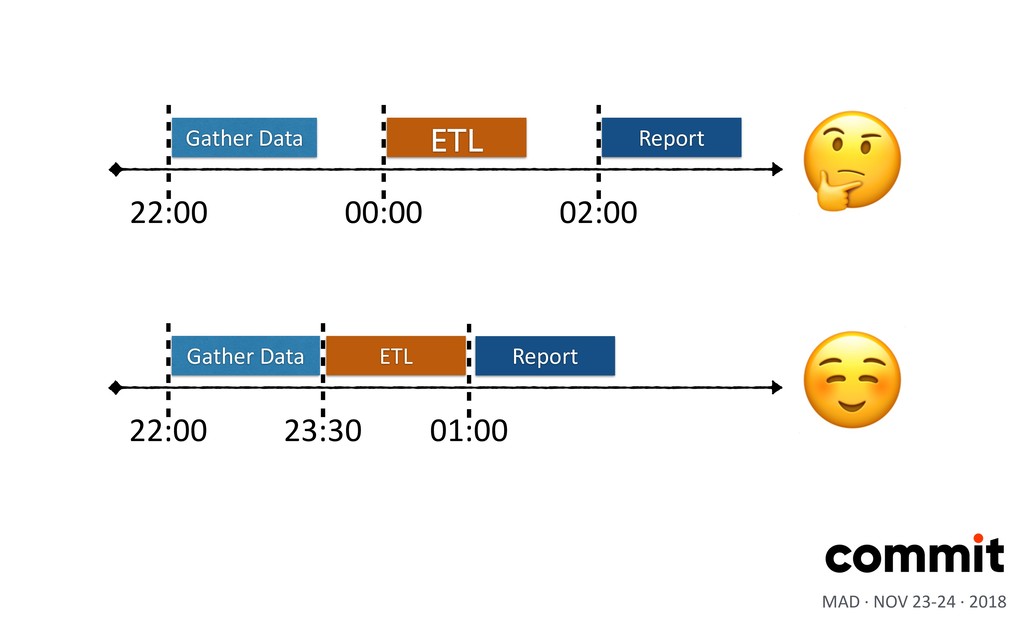
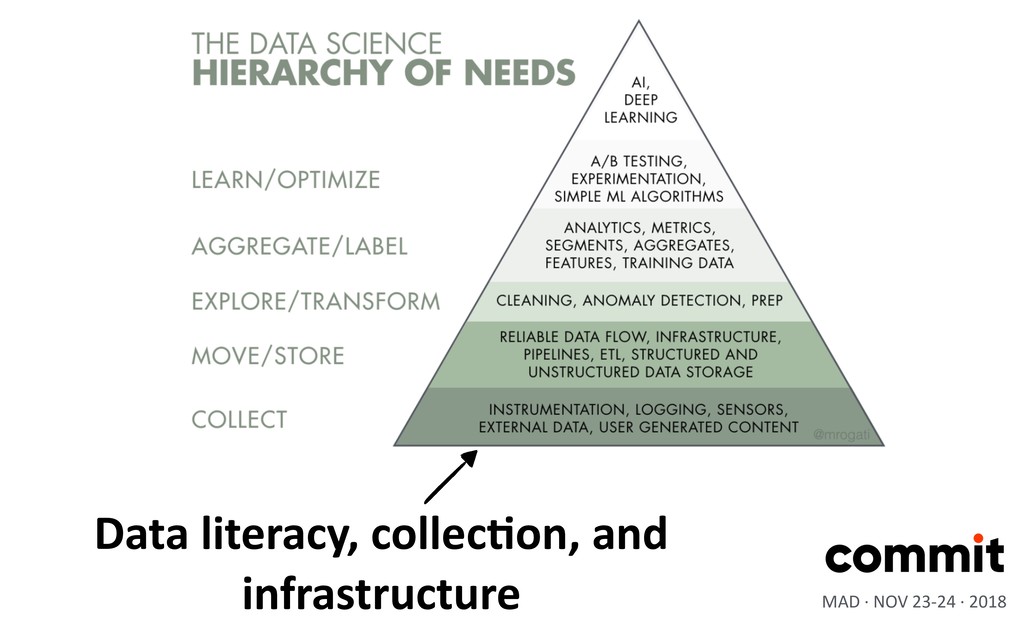
is the language of data •Load data incrementally •Process historic data (backfilling) •ParXXon ingested data •Enforce the idempotency constrain MAD · NOV 23-24 · 2018 Key skills
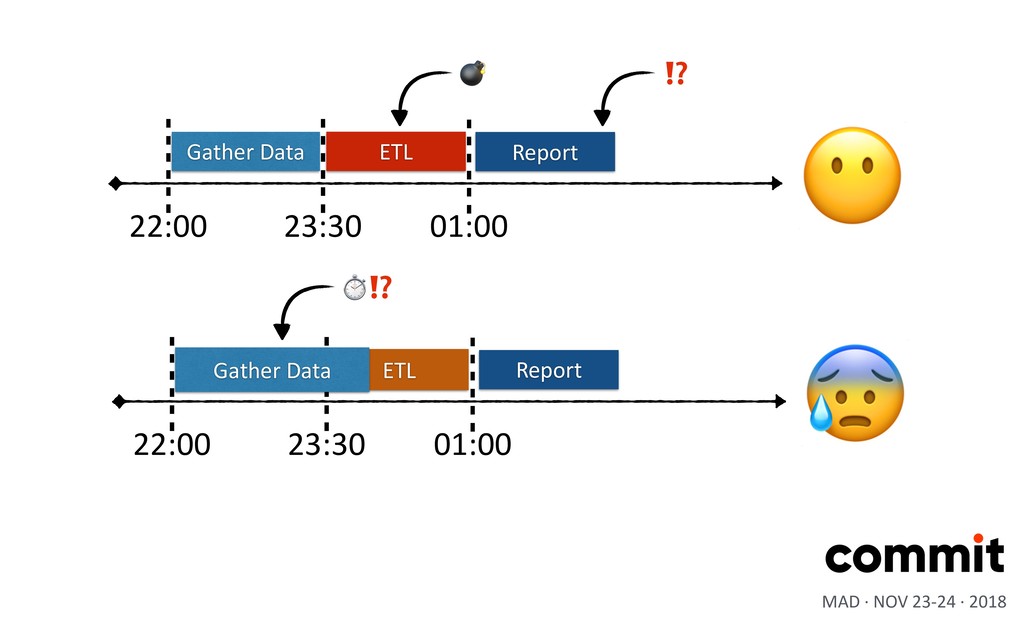
date should always produce same output •Future proof: backfilling, versioning •Data can be repaired by rerunning the new code, either by clearing tasks or doing backfills MAD · NOV 23-24 · 2018 FuncIonal data engineering
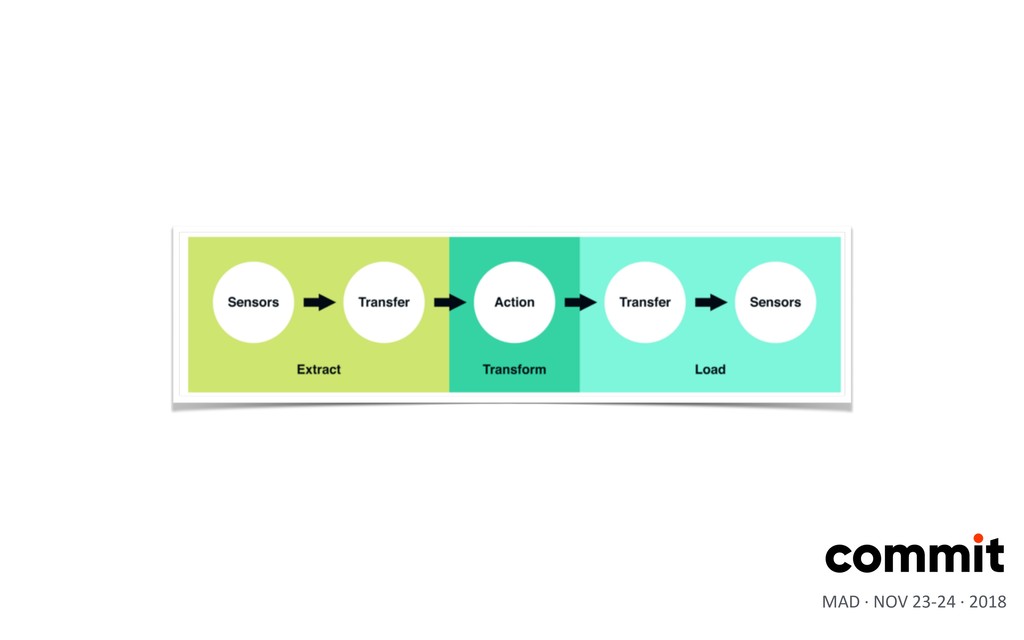
•Transform: where we apply business logic and perform acXons such as filtering, grouping, and aggregaXon to translate raw data into analysis- ready datasets •Load: we load the processed data and transport them to a final desXnaXon ETLs MAD · NOV 23-24 · 2018
queries for Apache Airflow •Astronomer guides •Airflow maintenance dags •A Beginner’s Guide to Data Engineering by Robert Chang •The Rise of the Data Engineer by Maxime Beauchemin
Slide 3: image from XKCD (hcps://xkcd.com/2054/) • Slide 4: picture by Andrew Seaman (hcps://unsplash.com/photos/EuDUHo5yyAg) • Slide 8: image from Pinterest (hcps://www.pinterest.com/pin/377739487476469866/) • Slide 9: Apache Airflow logo (hcps://airflow.apache.org/) • Slide 11: logos belong to the respecXve companies • Slide 14: image from Wikipedia (hcps://en.wikipedia.org/wiki/Directed_acyclic_graph) • Slide 31: picture by Garec Mizunaka (hcps://unsplash.com/photos/xFjX9rYILo) • Slide 33: Flask logo (hcp://flask.pocoo.org/), Mesos logo (hcp://mesos.apache.org/), Kubernetes logo (hcps://kubernetes.io/) • Slide 42: picture by Dan Gold (hcps://unsplash.com/photos/5O1ddenSM4g) • Slide 43-45: hcps://www.astronomer.io/guides/dynamically-generaXng-dags/ • Slide 48: Monica RogaX’s “The AI Hierarchy of Needs” hcps://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007 • Slide 49: Robert Chang’s “A Beginner’s Guide to Data Engineering” hcps://medium.com/@rchang/a-beginners-guide-to-data-engineering-part- i-4227c5c457d7 • Slide 50: Maxime Beauchemin’s “The Rise of the Data Engineer” hcps://medium.freecodecamp.org/the-rise-of-the-data-engineer-91be18f1e603 • Slide 51: picture by Jesse Gardner (hcps://unsplash.com/photos/mERlBKFGJiQ) • Slide 54: Vineet Goel’s “Why Robinhood uses Airflow?” (hcps://robinhood.engineering/why-robinhood-uses-airflow-aed13a9a90c8) • Slide 56: Ansible logo (hcps://www.ansible.com/) • Slide 57: Astronomer logo (hcps://www.astronomer.io) • Slide 58: Google Cloud Pla`orm logo and Google Cloud Composer logo (hcps://cloud.google.com/composer/) • Slide 60: picture by Edwin Andrade (hcps://unsplash.com/photos/4V1dC_eoCwg) • Commit logo (hcps://2018.commit-conf.com)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
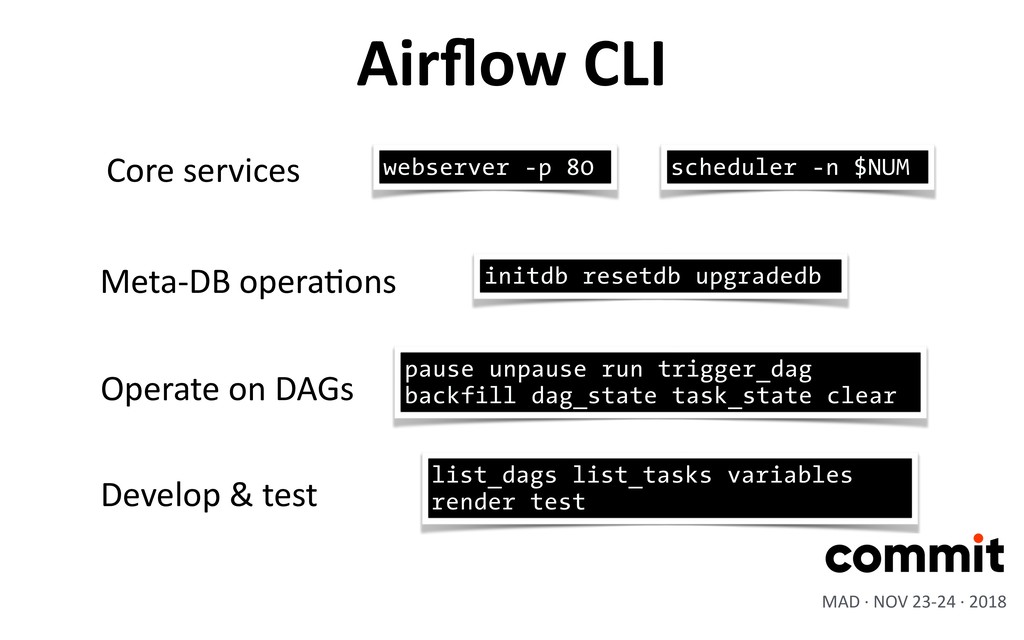
![Airflow CLI $ airflow [-h] <command> MAD · NOV 23-24](https://files.speakerdeck.com/presentations/78639a73875f47fbb4ea1617259c63ca/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}