start_urls = [ 'http://www.example.com/1.html', ] def parse(self, response): msg = 'A response from %s just arrived!' % response.url self.logger.info(msg) What is a Spider?
start_urls = [ ‘http://www.example.com/1.html' ] def parse(self, response): for h3 in response.xpath(‘//h3/text()’).extract(): yield {‘title’: h3} for url in response.xpath('//a/@href').extract(): yield scrapy.Request(url, callback=self.parse) What is a Spider? 1.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![import scrapy class MySpider(scrapy.Spider): name = 'example.com' allowed_domains = ['example.com']](https://files.speakerdeck.com/presentations/35bc78b700e6475dace320a7d23be8fd/slide_18.jpg){kind=link}
{kind=link}
![import scrapy class MySpider(scrapy.Spider): name = 'example.com' allowed_domains = ['example.com']](https://files.speakerdeck.com/presentations/35bc78b700e6475dace320a7d23be8fd/slide_20.jpg){kind=link}
{kind=link}
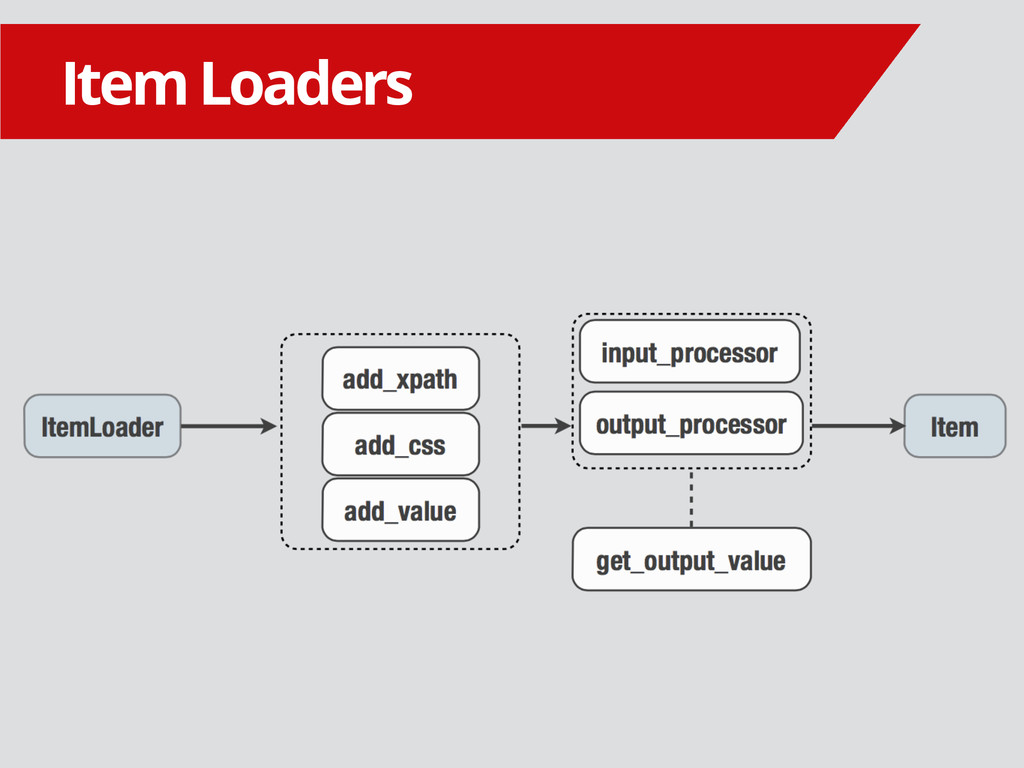{kind=link}
{kind=link}
{kind=link}
{kind=link}
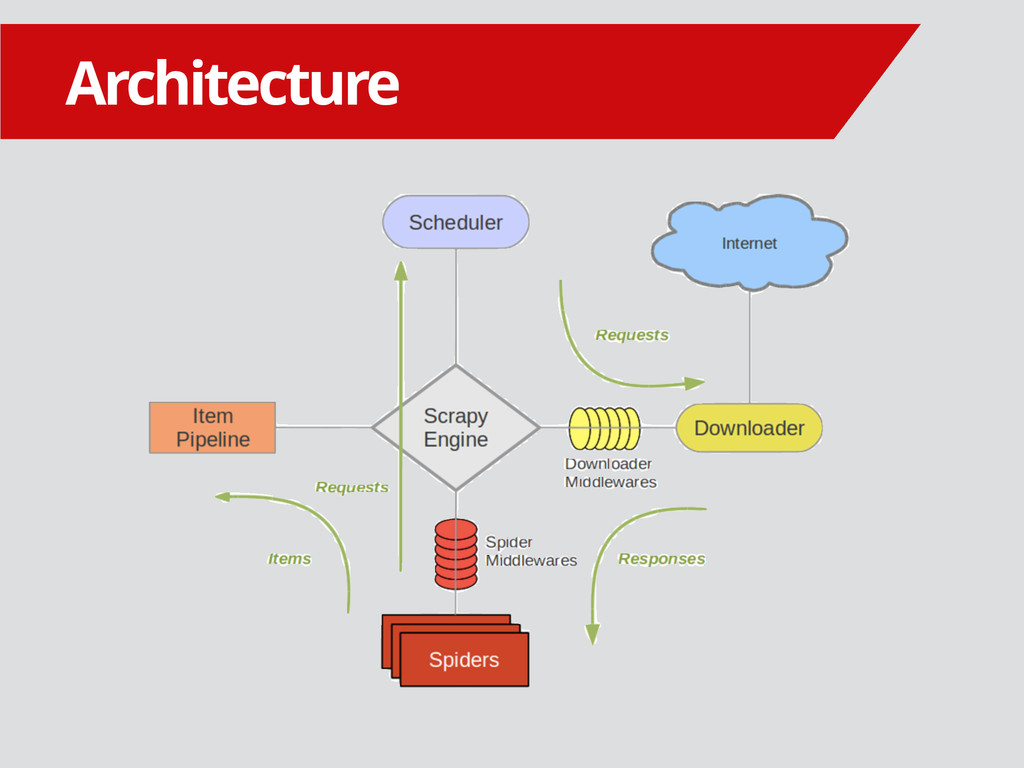{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}