Em tempos que o assunto Big Data está cada vez mais presente em nossos dias o PostgreSQL não poderia ficar de fora dessa.
Neste trabalho algumas explanações sobre o assunto e interações entre PostgreSQL e Hadoop.
/ interação com o PostgreSQL; • Fomentar a cultura Big Data para DBAs PostgreSQL; • Apresentar o PostgreSQL para profissionais Big Data; • Disseminar conhecimentos :) Objetivos
sócio da VORio Tecnologia da Informação, atua a mais de 20 anos nas áreas de Desenvolvimento de Sistemas, Banco de Dados, Servidores FreeBSD, Linux e Windows. Possui mais de 10 anos de experiência com o PostgreSQL, utilizando-o em seus sistemas e também atuando como DBA para diversas empresas com grande volume de informações e transações e em ambientes de missão crítica. Professor do Curso de Extensão em Banco de Dados PostgreSQL na Universidade do Estado do Rio de Janeiro (UERJ).
Paulo – SP, no curso “Informática para Gestão de Negócios”. Trabalha em uma grande empresa do Governo Federal atuando como DBA e Instrutor PostgreSQL, cujo trabalho é realizar tarefas rotineiras de um Administrador de Banco de Dados tais como Gerenciamento, Migração, Execução de Fluxos de RDM, SS, tratamentos de RIs, atividades de consultoria interna orientando e auxiliando na modelagem de bases de dados e Instrutoria Interna.
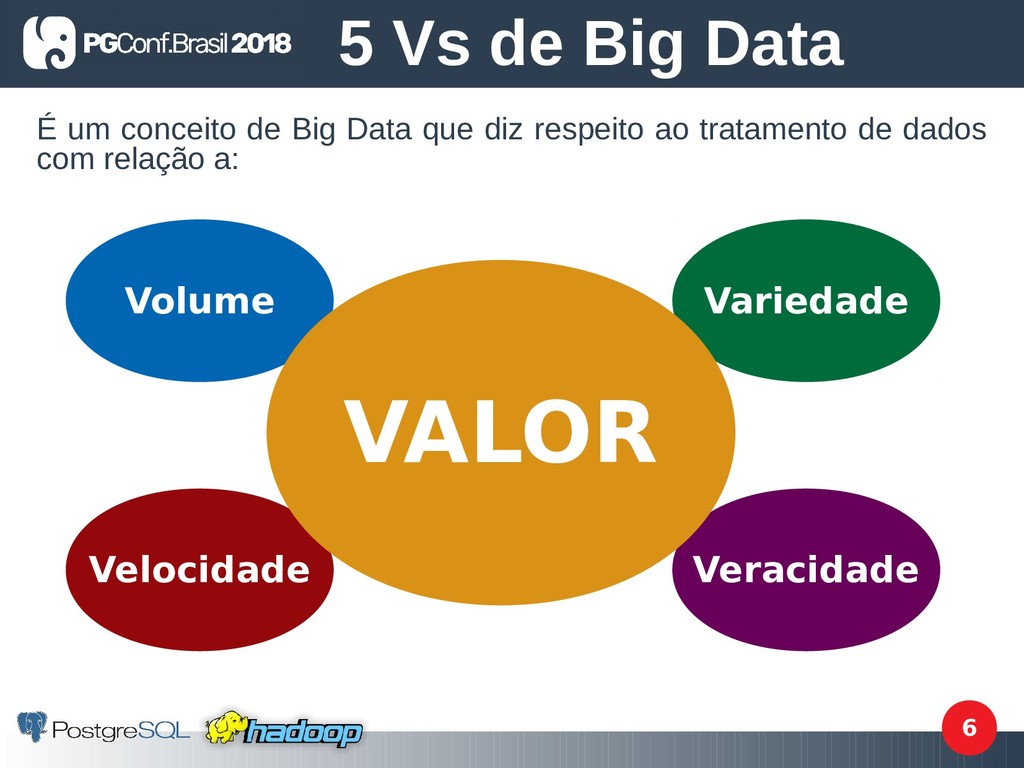
para nomear conjuntos de dados muito grandes ou complexos, que os aplicativos de processamento de dados tradicionais ainda não conseguem lidar. Os desafios desta área incluem: análise, captura, curadoria de dados, pesquisa, compartilhamento, armazenamento, transferência, visualização e informações sobre privacidade dos dados.” https://pt.wikipedia.org/wiki/Big_data Big Data
de Transparência do Governo Federal referentes a pagamentos do programa social Bolsa Família: http://www.portaltransparencia.gov.br/download-de- dados/bolsa-familia-pagamentos Dados de Laboratório
Dados desde janeiro de 2013; • Ano e mês estão no formato YYYYMM; • Shell Script para automatizar os downloads; • Arquivos em formato DOS (CR/LF): converter para formato Unix (dos2unix); Tratamento de Dados
Extrair apenas colunas que interessam (cut); • Converter nomes de campos para fcarem iguais aos da tabela de carga no PostgreSQL tirando letras maiúsculas, espaços e caracteres especiais (sed); • Por questões de falta de espaço, compactar cada arquivo baixado no formato xz com compactação máxima com nomenclatura no formato YYYYMM.csv.xz. Tratamento de Dados
ENCRYPTED PASSWORD '123' LOGIN; Criação da base de dados: > CREATE DATABASE db_bf OWNER user_bf; Conectar à base criada (psql): > \c db_bf user_bf Carga no PostgreSQL
open-source para computação distribuída de forma escalável e confável. • É um framework que permite o processamento distribuído de grandes volumes de dados através de clusters de computadores. Hadoop
milhares de máquinas cada uma oferecendo seu próprio processamento e armazenamento. • É um sistema de arquivos distribuído que o Hadoop com recursos de replicação e tolerância a falhas. http://hadoop.apache.org/ Hadoop
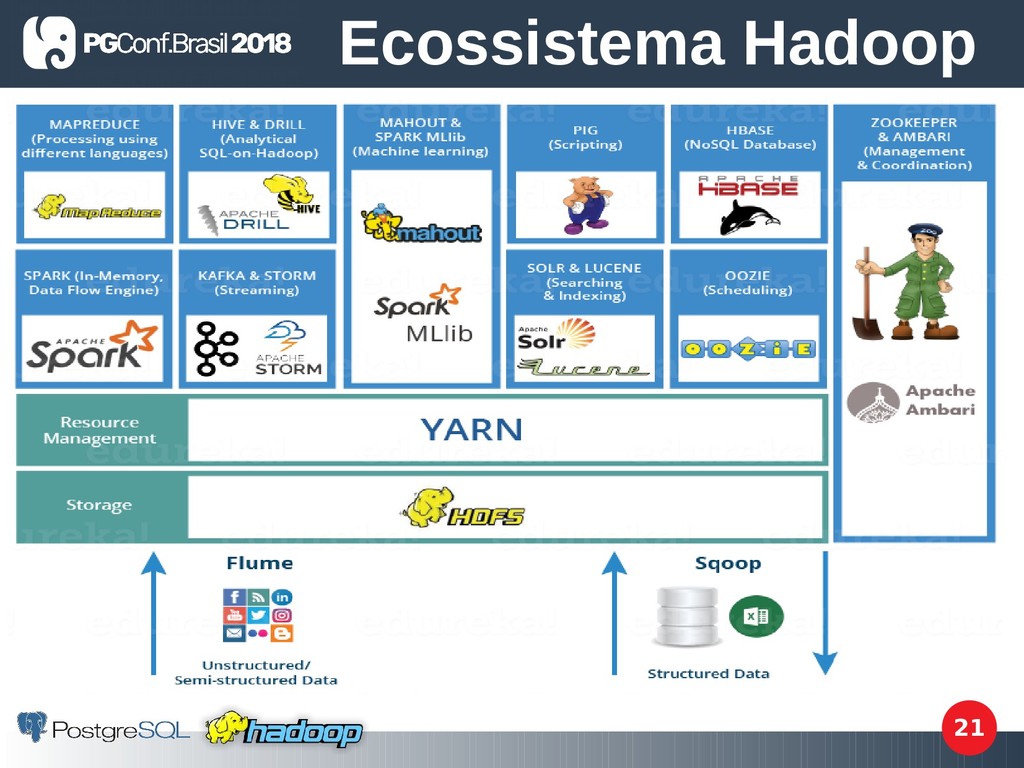
da biblioteca do Apache Hadoop, bem como outras ferramentas / projetos fornecidos pela Apache Software Foundation e as formas de trabalharem juntos. Ecossistema Hadoop
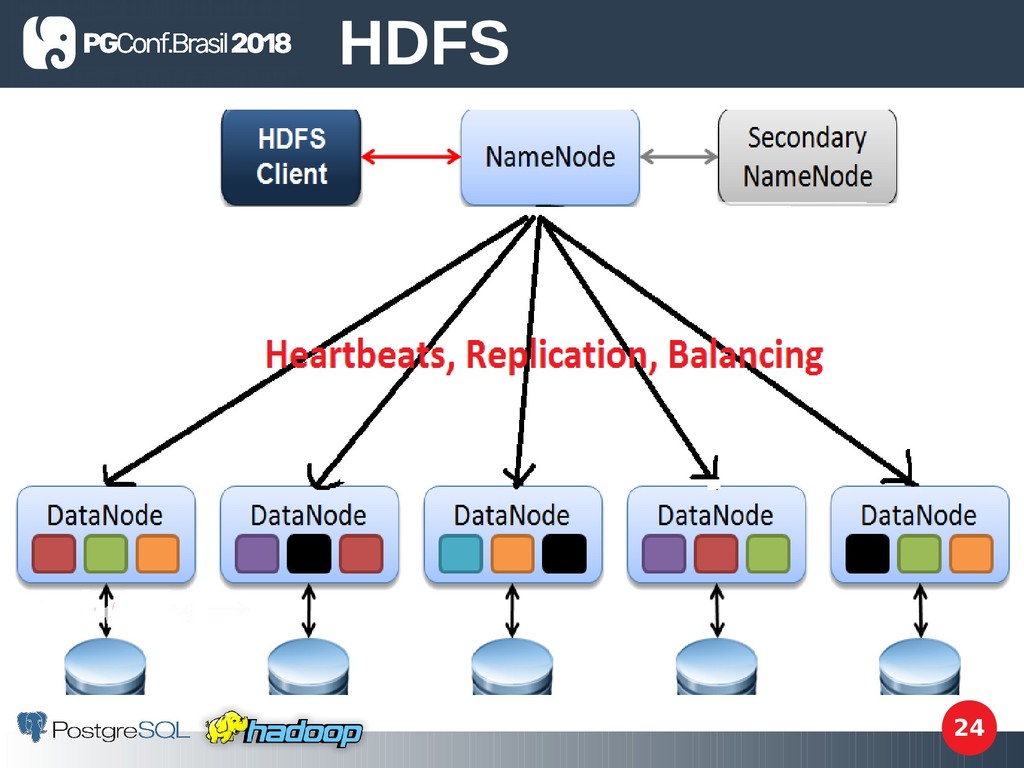
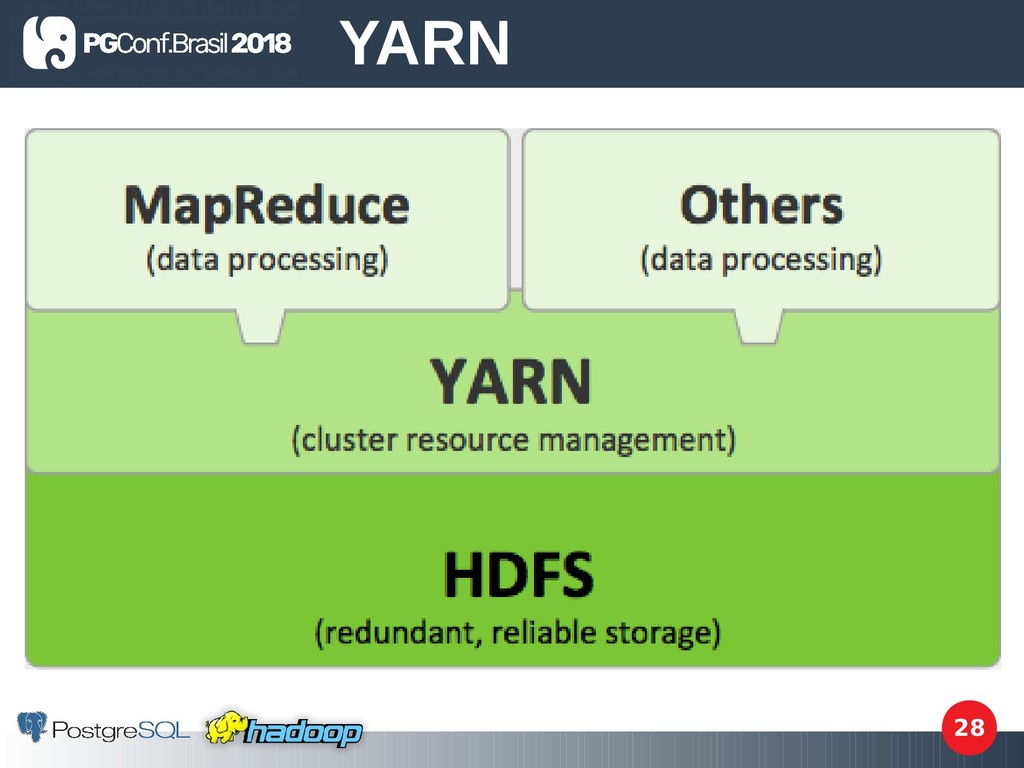
arquivos distribuído que o Hadoop utiliza e tem tolerância a falhas. • Feito com base na especifcação do GFS (Google File System); • Projetado para atender demandas de volume, velocidade e variedade (3 Vs de Big Data); HDFS
• Filesystem de computação distribuída, cujos dados são mapeados por um Namenode (que é gerenciado pelo YARN) sabendo onde está cada bloco de arquivo no cluster; • Divide arquivos em blocos de 64MB ou 128 e armazena cada bloco em um datanote sendo que esse bloco é replicado, 3 vezes por padrão, o que é conhecido como fator de replicação. HDFS
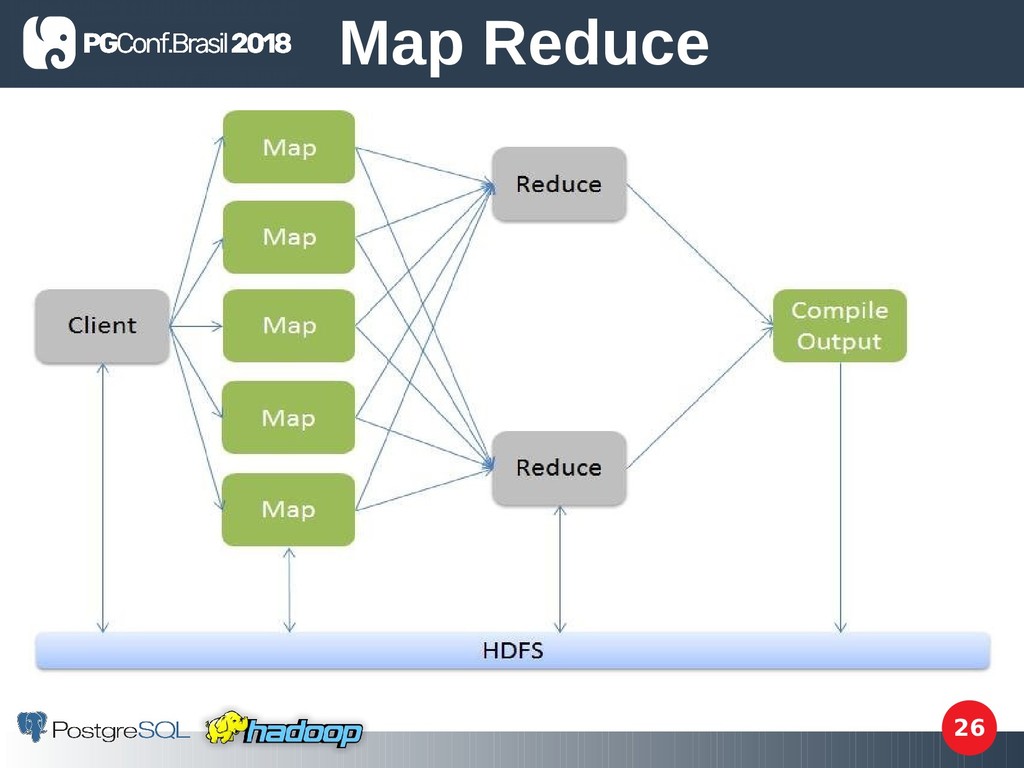
É um modelo de programação para processamento de dados; • É um processo / uma tarefa que o Hadoop executa, um map reduce job; • Transforma dados maiores em dados menores conforme o objetivo; Map Reduce
recursos), é o gerenciador de recursos e agendamento de tarefas para cluster Hadoop a partir da versão 2; • É um framework para fornecer recursos computacionais (CPU, memória, I/O de disco e banda de rede) para motores (engines) de execução; • Map Reduce, Spark, Storm, Solr e Tez funcionam rodam sobre o YARN, assim sendo o YARN os intermedia com o HDFS; • Oferece API de recursos do Hadoop. YARN
open-source para data warehouse, facilita leitura, escrita e gerenciamento de gandes volumes de dados que estão em armazenamento distribuído usando SQL (HiveQL). • Fornece um mecanismo para projetar estrutura para esses dados usando uma linguagem como SQL chamada HiveQL. Hive
os programadores tradicionais de map/reduce conectem seus mapeadores e redutores personalizados quando é inconveniente ou inefciente expressar essa lógica no HiveQL. http://hive.apache.org/ Hive
open-source é um engine unifcado de análise para grandes volumes de processamento de dados. • É um framework de computação de propósito geral que suporta uma grande variedade de casos de uso. Spark
ele depende de armazenamento de terceiros como Hadoop (HDFS), HBase, Cassandra, S3, etc. • O Spark integra-se perfeitamente ao Hadoop e pode processar dados existentes. http://spark.apache.org/ Spark
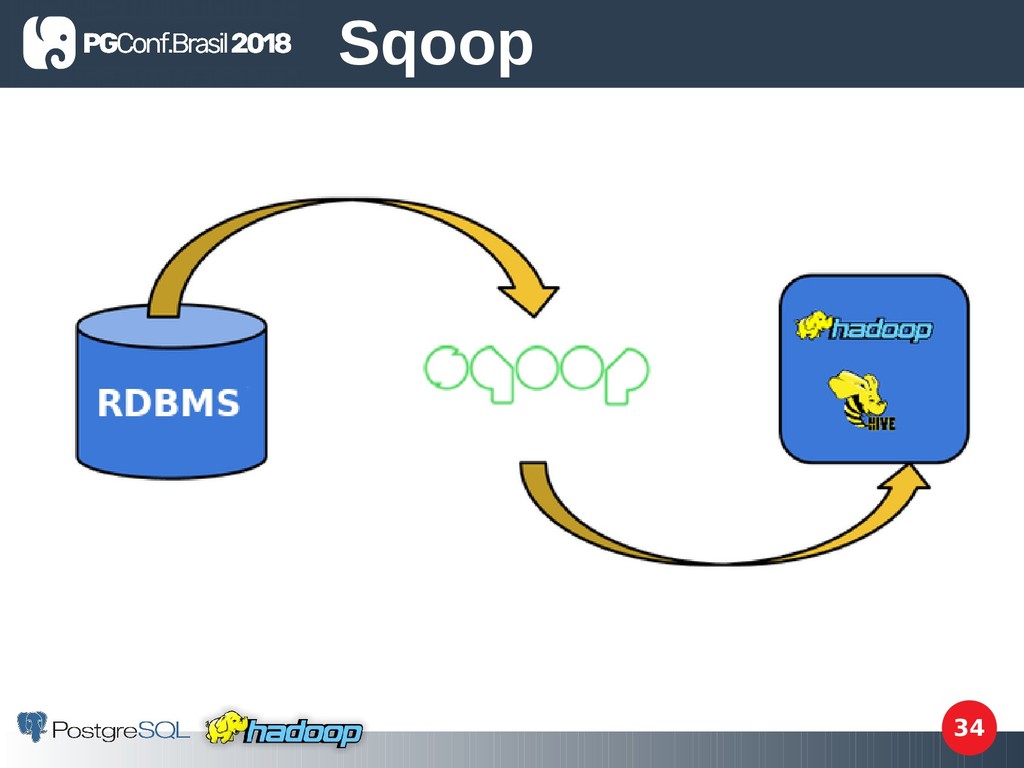
open-source é uma ferramenta projetada para efcientemente transferir dados em massa (bulk data) entre o Hadoop e bases de dados relacionais estruturadas. Sqoop
pela EnterpriseDB e seu código-fonte é aberto; Seu objetivo é fornecer uma interface entre o PostgreSQL e o Hive. https://github.com/EnterpriseDB/hdfs_fdw HDFS FDW
FDW via yum: # yum install -y hdfs_fdw_10 java-1.8.0-openjdk Precisamos de bibliotecas java (.jar) necessárias para o FDW funcionar, que devem ser extraídas do Hadoop e do Hive. HDFS FDW
ls *.gz | xargs -i tar xf {} Variável de ambiente para o diretório de bibliotecas da instalação do PostgreSQL: # export PGLIB=`/usr/pgsql-10/bin/pg_config --libdir` HDFS FDW
para o diretório de bibliotecas da instalação do PostgreSQL: # mv hadoop-3.1.0/share/hadoop/common/\ hadoop-common-3.1.0.jar ${PGLIB}/ # mv apache-hive-3.1.0-bin/jdbc/\ hive-jdbc-3.1.0-standalone.jar ${PGLIB}/ HDFS FDW
/ ou descompactado: # rm -fr apache-hive-* hadoop-* Atualizar a base de dados de flesystem do SO: # updatedb Criar um link da biblioteca C da JVM no diretório de bibliotecas do PostgreSQL: # ln -s `locate libjvm.so` ${PGLIB}/ HDFS FDW
PGDATA=`su - postgres -c "psql -Atqc \ 'SHOW data_directory'"` O FDW HDFS tem GUCs próprias e por questões de boas práticas, tais confgurações estarão em um arquivo separado dentro do $PGDATA. No postgresql.conf, será utilizada a directiva include: include = 'hdfs_fdw.conf' HDFS FDW
FDW HDFS: # cat << EOF > ${PGDATA}/hdfs_fdw.conf hdfs_fdw.jvmpath = '${PGLIB}/' hdfs_fdw.classpath = '${PGLIB}/hadoop-common-3.1.0.jar:\ ${PGLIB}/hive-jdbc-3.1.0-standalone.jar:\ ${PGLIB}/HiveJdbcClient-1.0.jar' EOF Dar propriedade para o usuário e grupo postgres do SO: # chown postgres: ${PGDATA}/hdfs_fdw.conf HDFS FDW
CREATE EXTENSION hdfs_fdw; Criação do objeto SERVER do FDW: > CREATE SERVER srv_hdfs FOREIGN DATA WRAPPER hdfs_fdw OPTIONS (host '192.168.0.6', client_type 'spark'); HDFS FDW
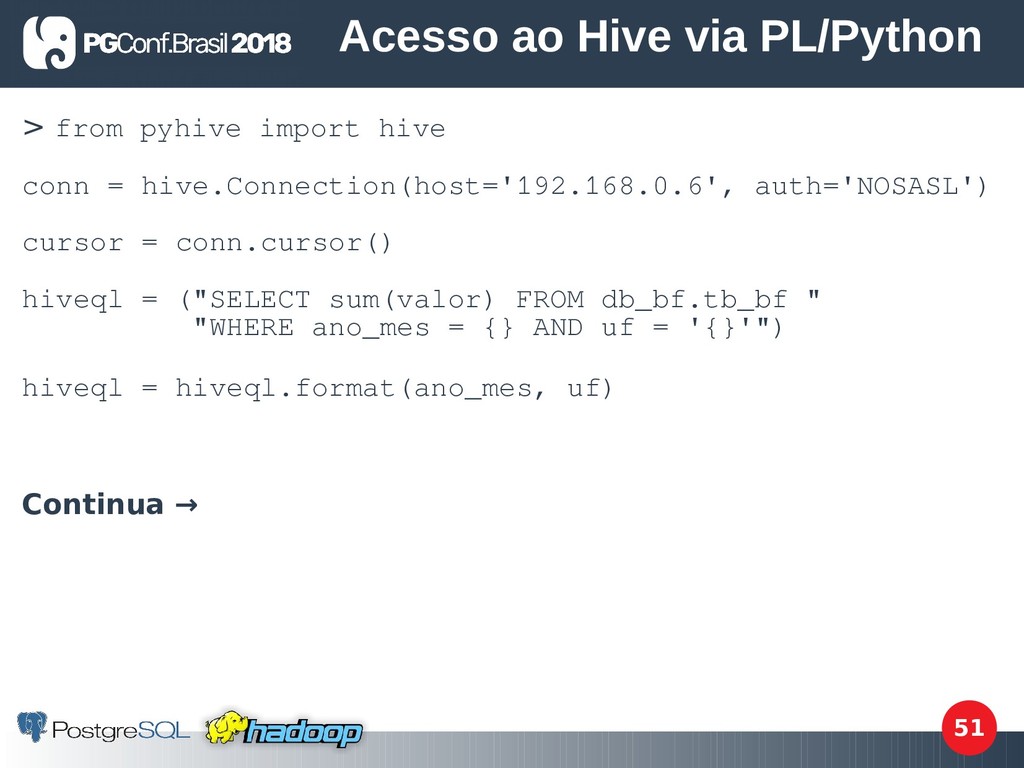
para uso geral, interpretada, fácil de aprender e de dar manutenção e totalmente orientada a objetos. PL/Python é a implementação de Python como linguagem procedural dentro do PostgreSQL, muito útil para operações fora dele. Acesso ao Hive via PL/Python
via Python. Recebe como parâmetro ano e mês no formato YYYYMM e a UF. Retorna a soma dos valores pagos: > CREATE OR REPLACE FUNCTION fc_bf_soma_valor_uf(ano_mes INT, uf CHAR(2)) RETURNS NUMERIC(10, 2) AS $$ Continua → Acesso ao Hive via PL/Python
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![52 > cursor.execute(hiveql) result = cursor.fetchone() cursor.close() conn.close() return result[0]](https://files.speakerdeck.com/presentations/6627d9c5a90d4da08528b156f58e0088/slide_51.jpg){kind=link}
{kind=link}
{kind=link}