Share
2026年03月にZennに投稿した記事をClaude designでスライドにしました。 記事:https://zenn.dev/nitic_students/articles/e2e331dea0c616
{kind=link}
{kind=link}
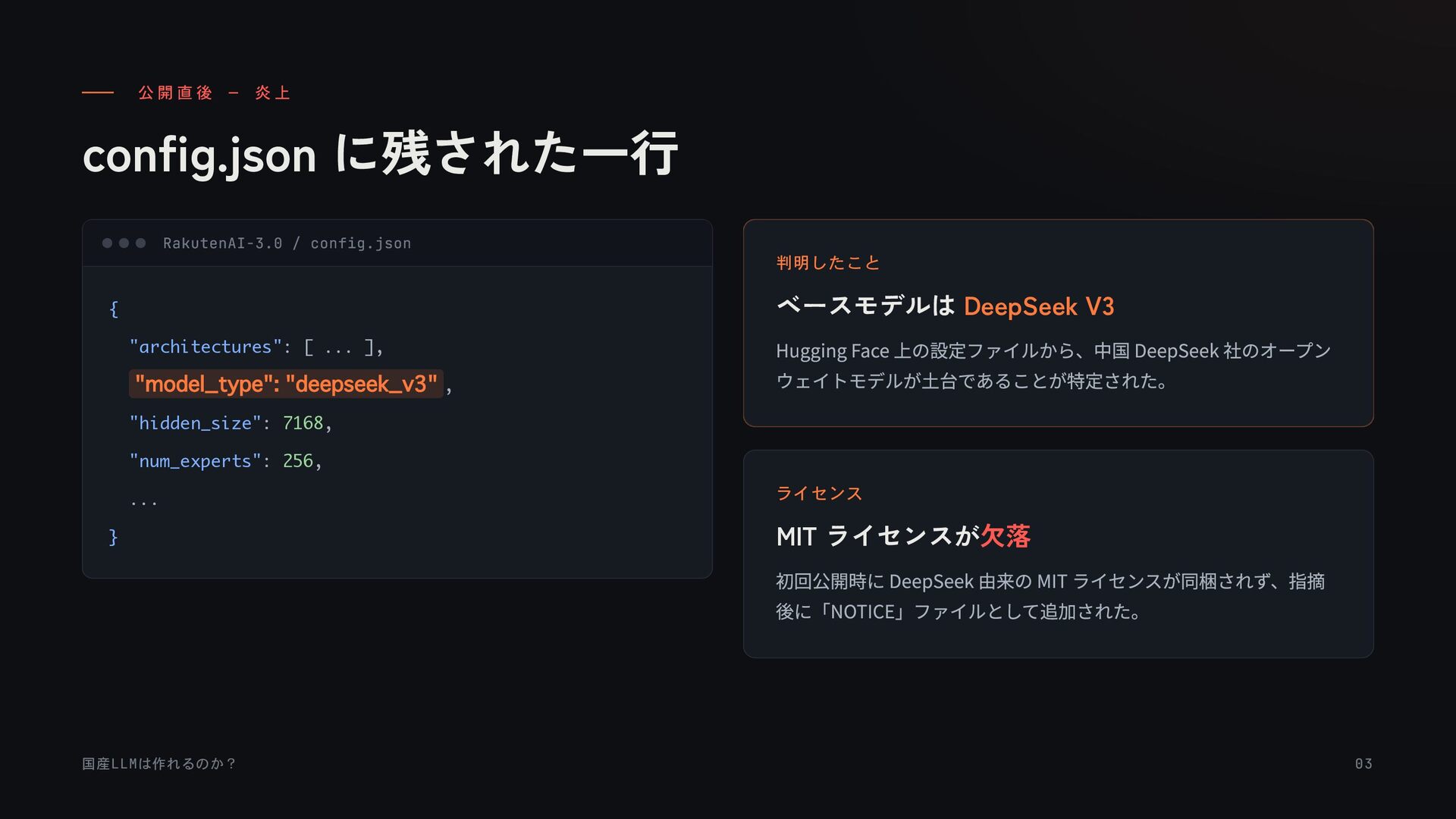{kind=link}
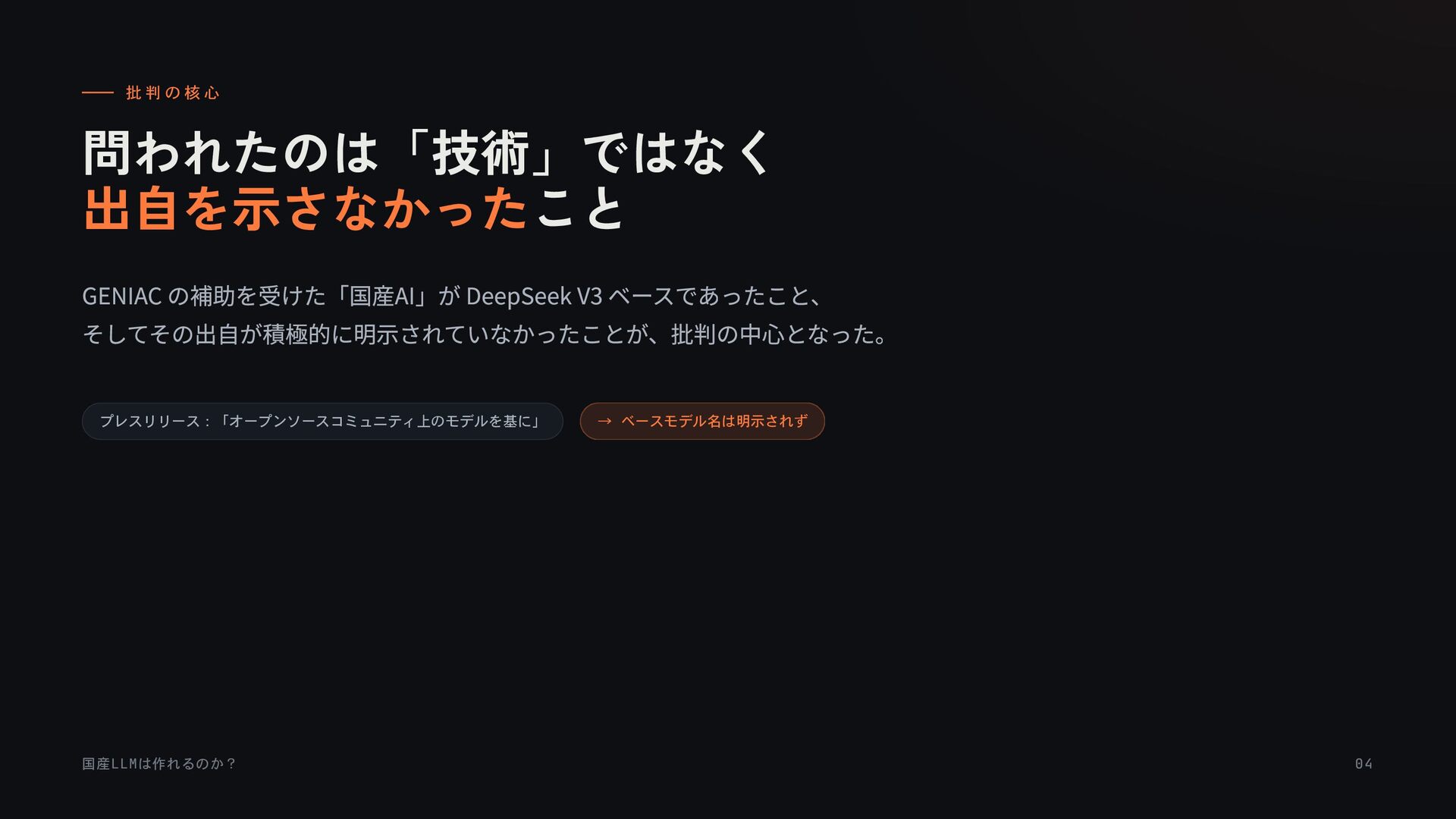{kind=link}
{kind=link}
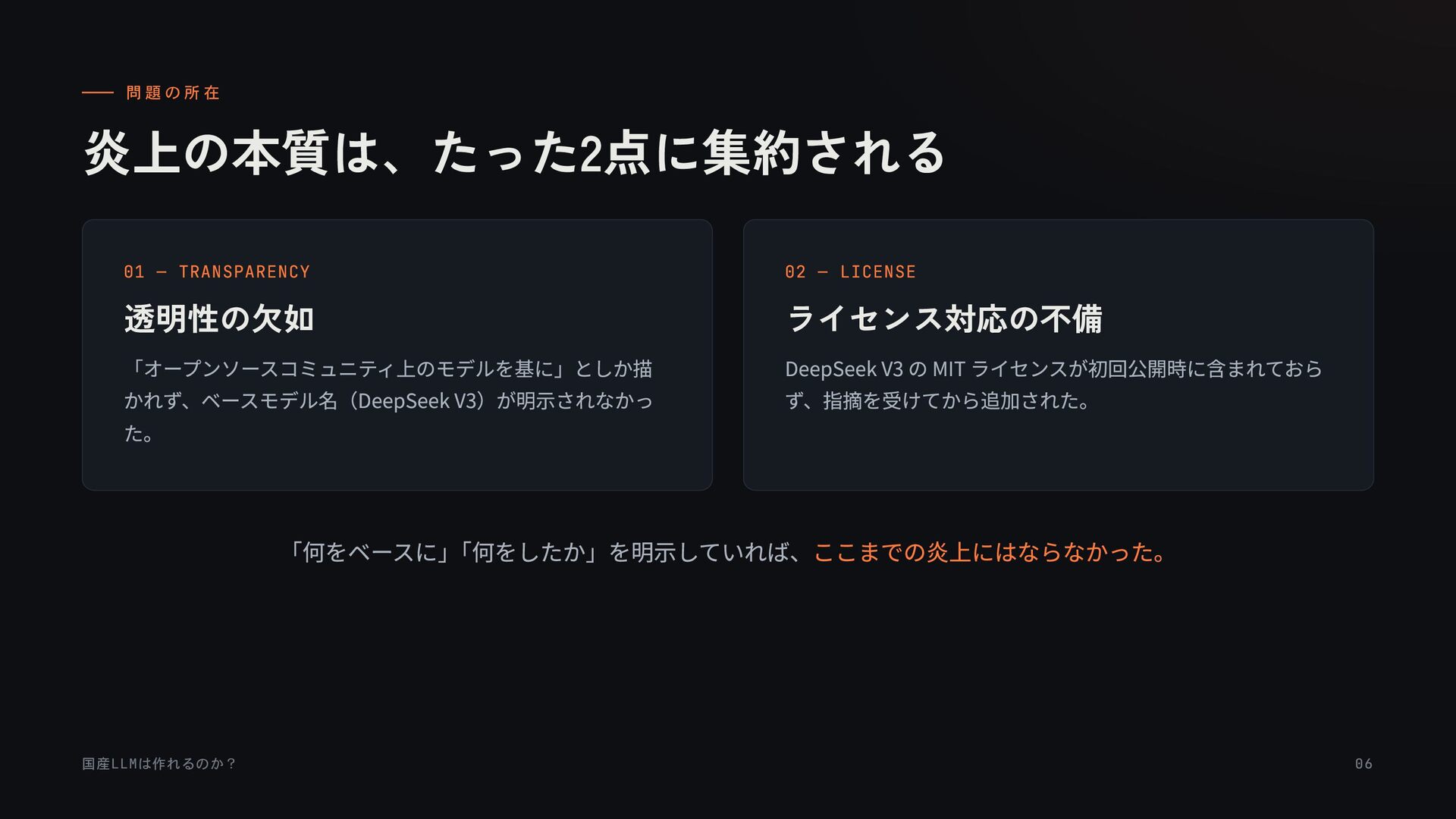{kind=link}
{kind=link}
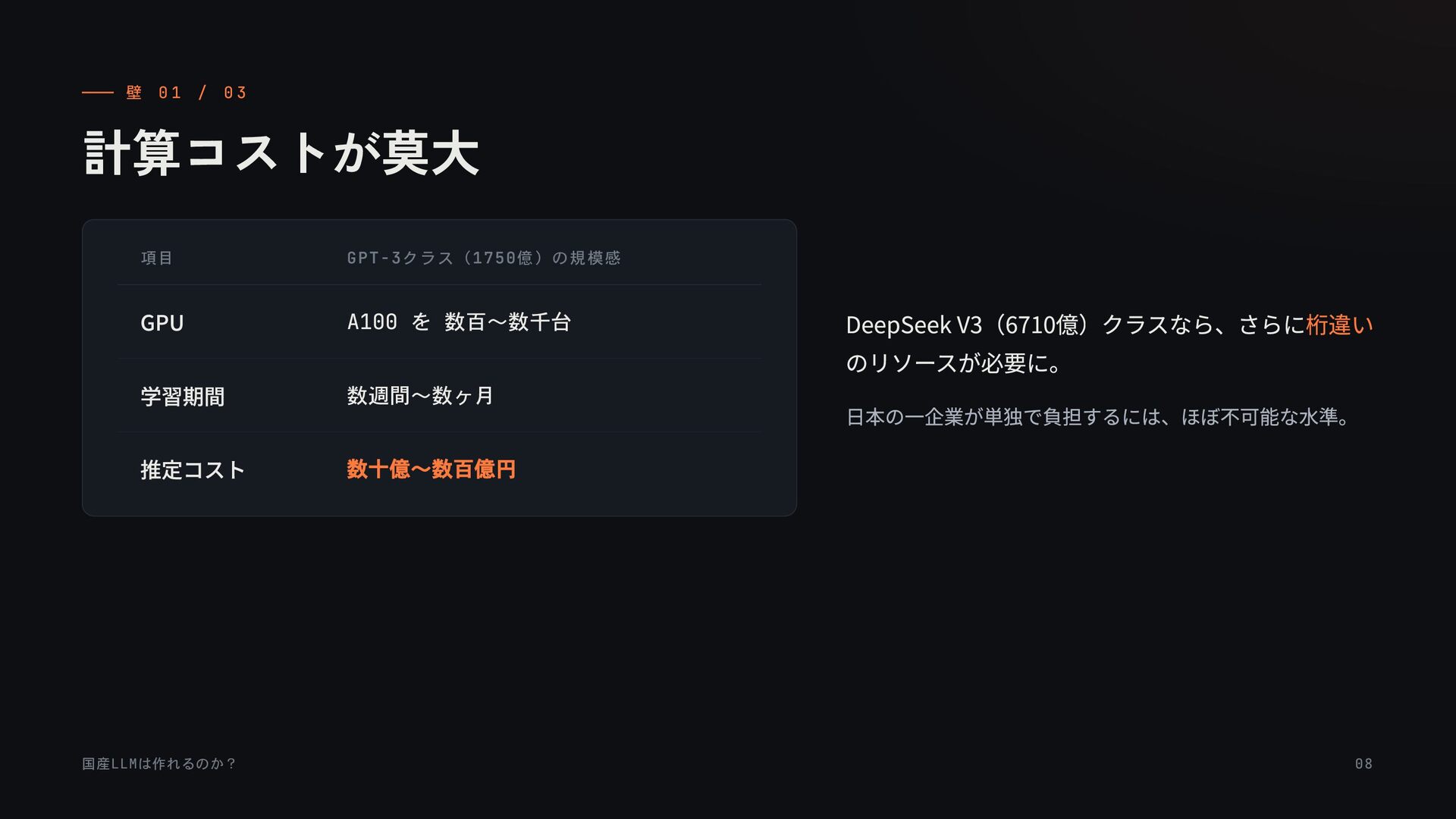{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}