6/28 2022に実施したTech Dojoで使用した資料の一部更新バージョンです。
https://ibm-developer.connpass.com/event/252174/
***
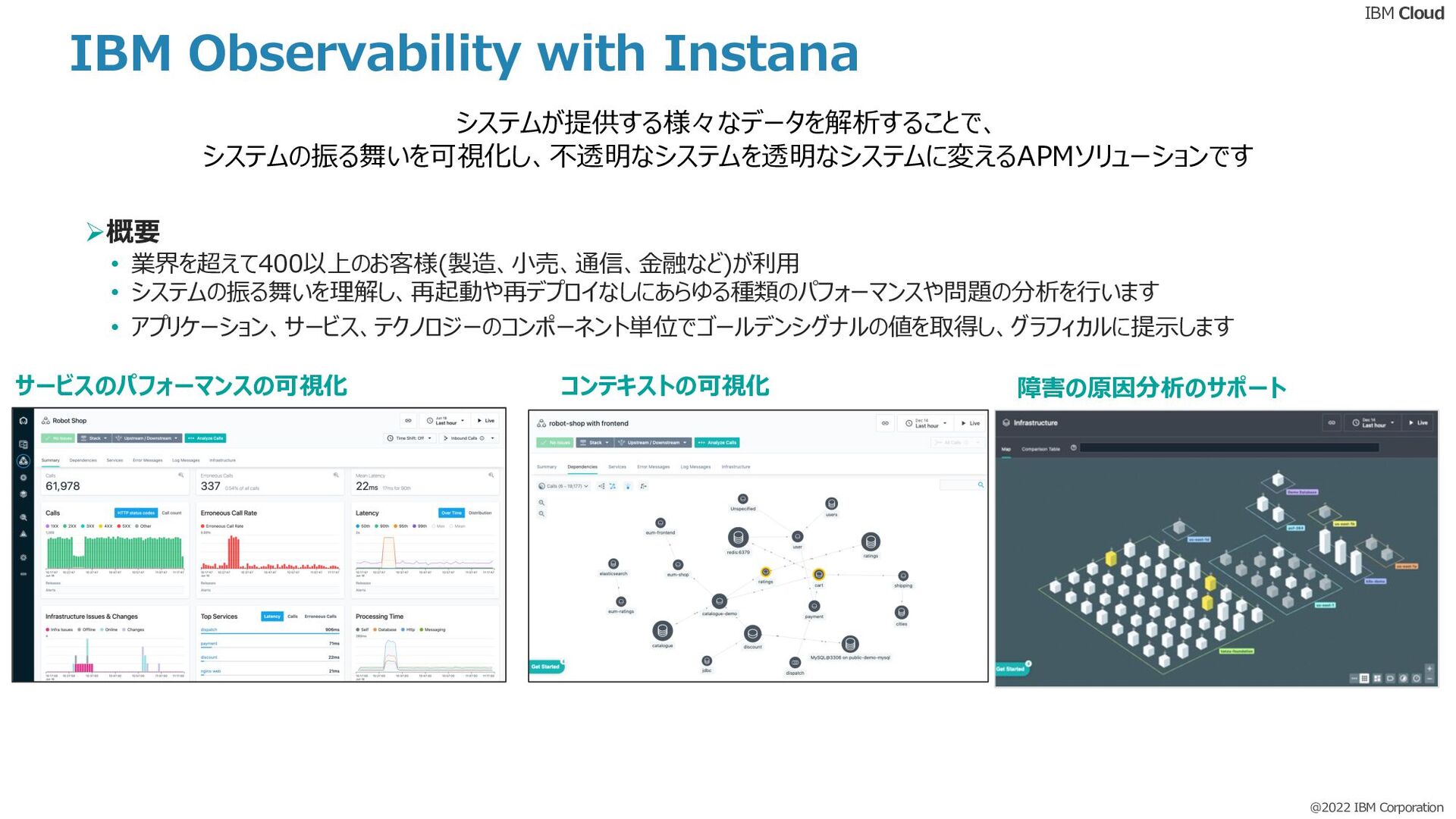
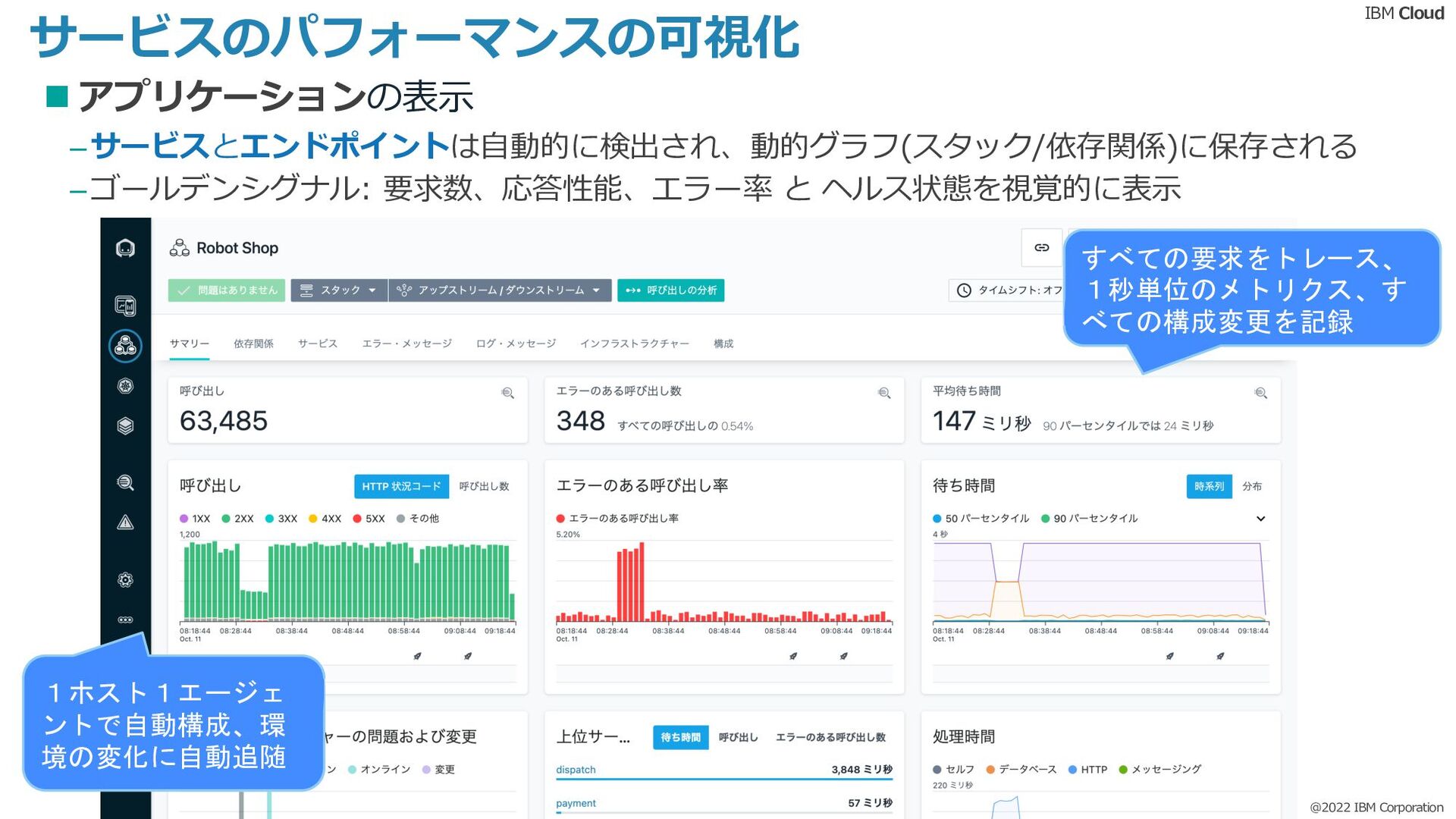
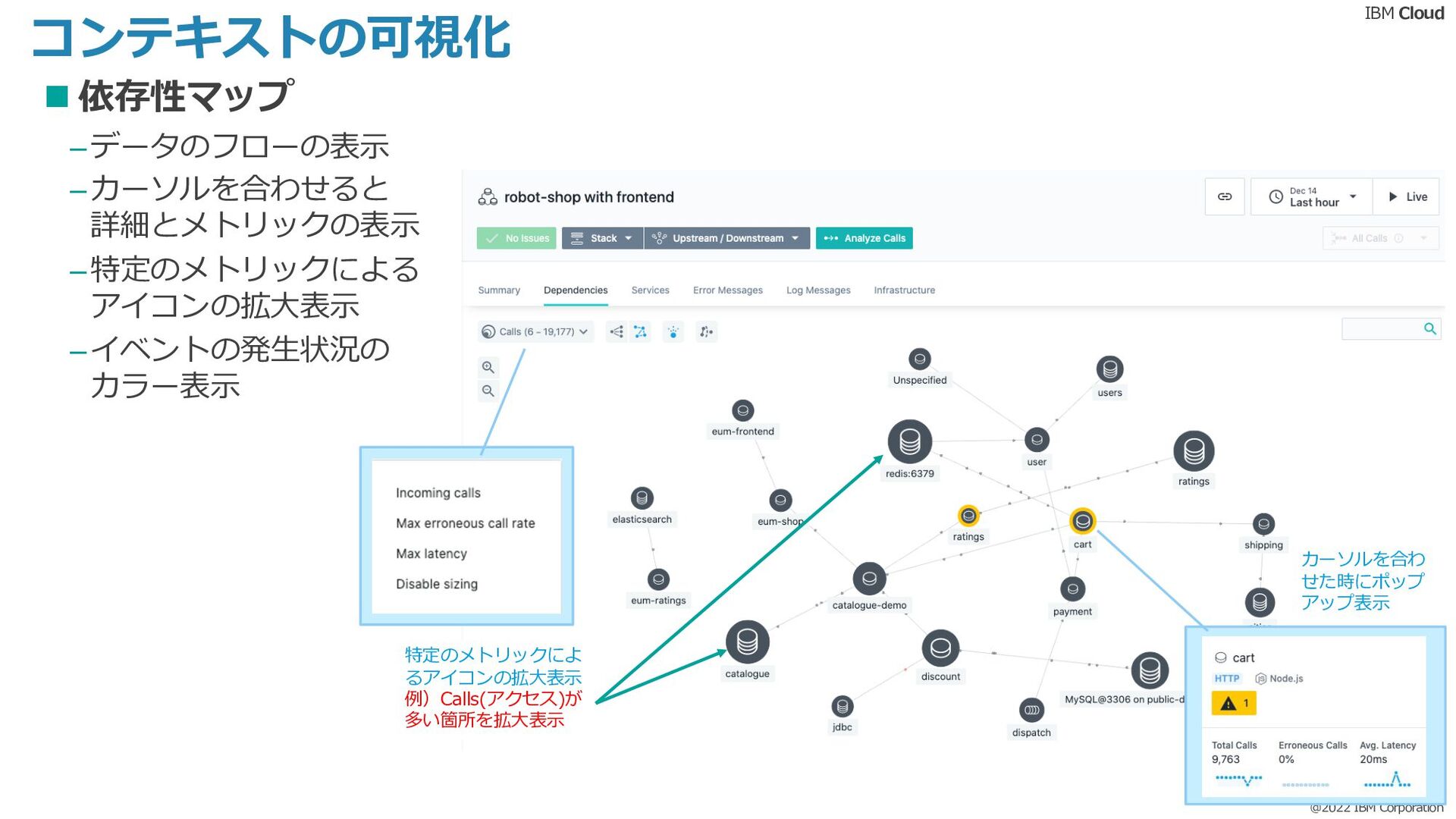
本Dojoでは、#APM #Instana #監視というタグに興味がある方向けに、APM入門的な内容をご紹介します。
- Observability?可観測性?
- APMと可観測性って違うの?
- エンドユーザモニタリングに興味がある
- サーバーの運用監視が大変...
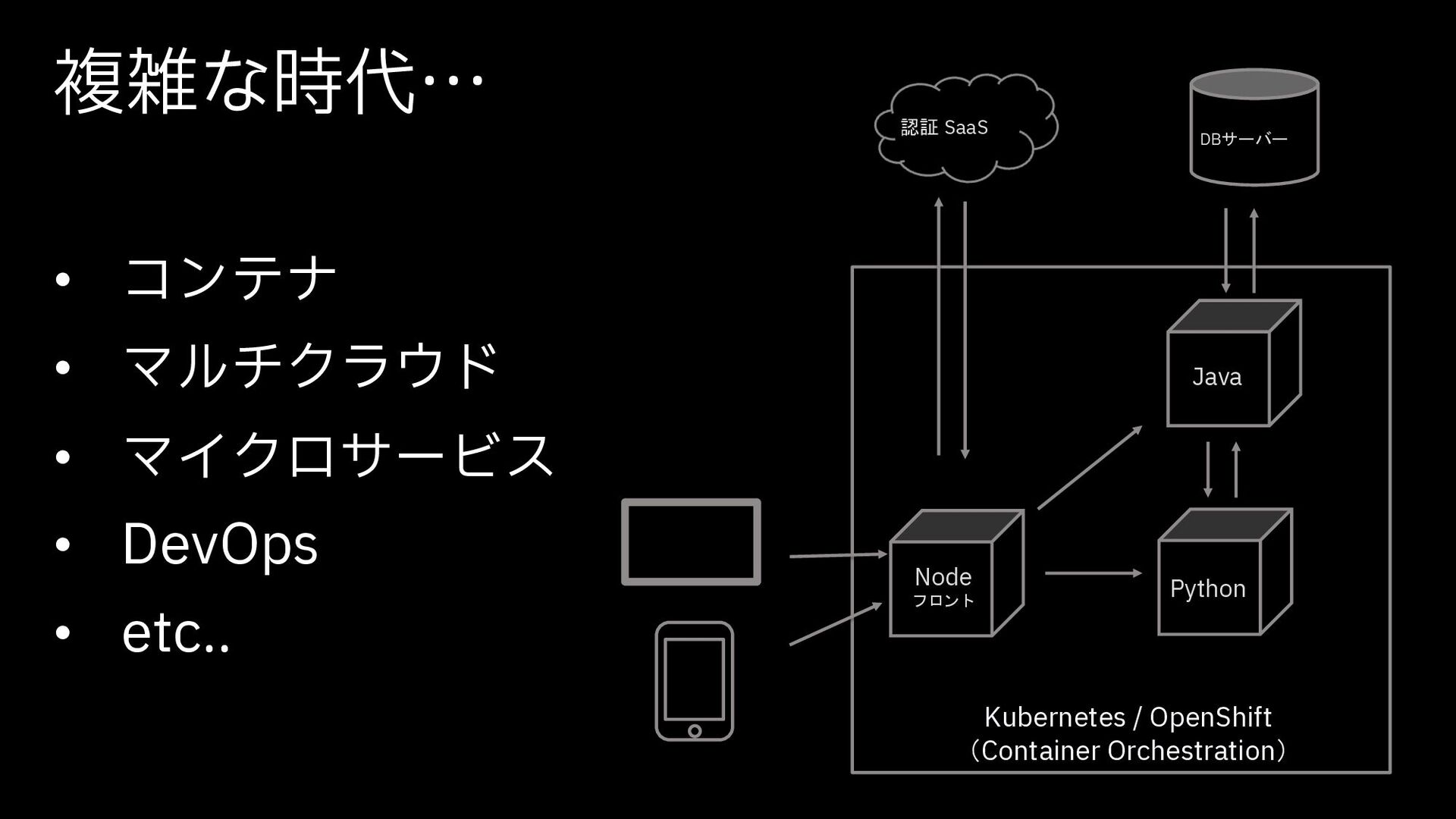
コンテナ環境の監視って今までとなにか変わるの?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}