#NLP #TexttoSQL #Semanticparsing #NLtoSQL
카카오엔터프라이즈에서 개발한 한국어 Text2SQL 모델인 RYANSQL을 소개하고, 서비스를 위해 고려했던 내용을 정리해서 발표합니다.
발표자 : index.sh
카카오엔터프라이즈 AI Assistant 팀 신명철입니다. 저는 kakao i 자연어처리 엔진 개발을 담당하고 있고, 주요 관심 분야는 목적지향 대화처리, 개체명 인식, 오픈 도메인 질의응답, 최적화, 언어모델 등입니다.
{kind=link}
{kind=link}
{kind=link}
![Text2SQL োয SQL [1] - Text2SQL - 자연어 질의를](https://files.speakerdeck.com/presentations/d3fb4a9e8db4400d87170fc598732209/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
![- WikiSQL [2] - table : 1개 - select :](https://files.speakerdeck.com/presentations/d3fb4a9e8db4400d87170fc598732209/slide_6.jpg){kind=link}
![- WikiSQL [2] - table : 1개 - select :](https://files.speakerdeck.com/presentations/d3fb4a9e8db4400d87170fc598732209/slide_7.jpg){kind=link}
![- Spider [3] - 난이도 : Easy / Medium /](https://files.speakerdeck.com/presentations/d3fb4a9e8db4400d87170fc598732209/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
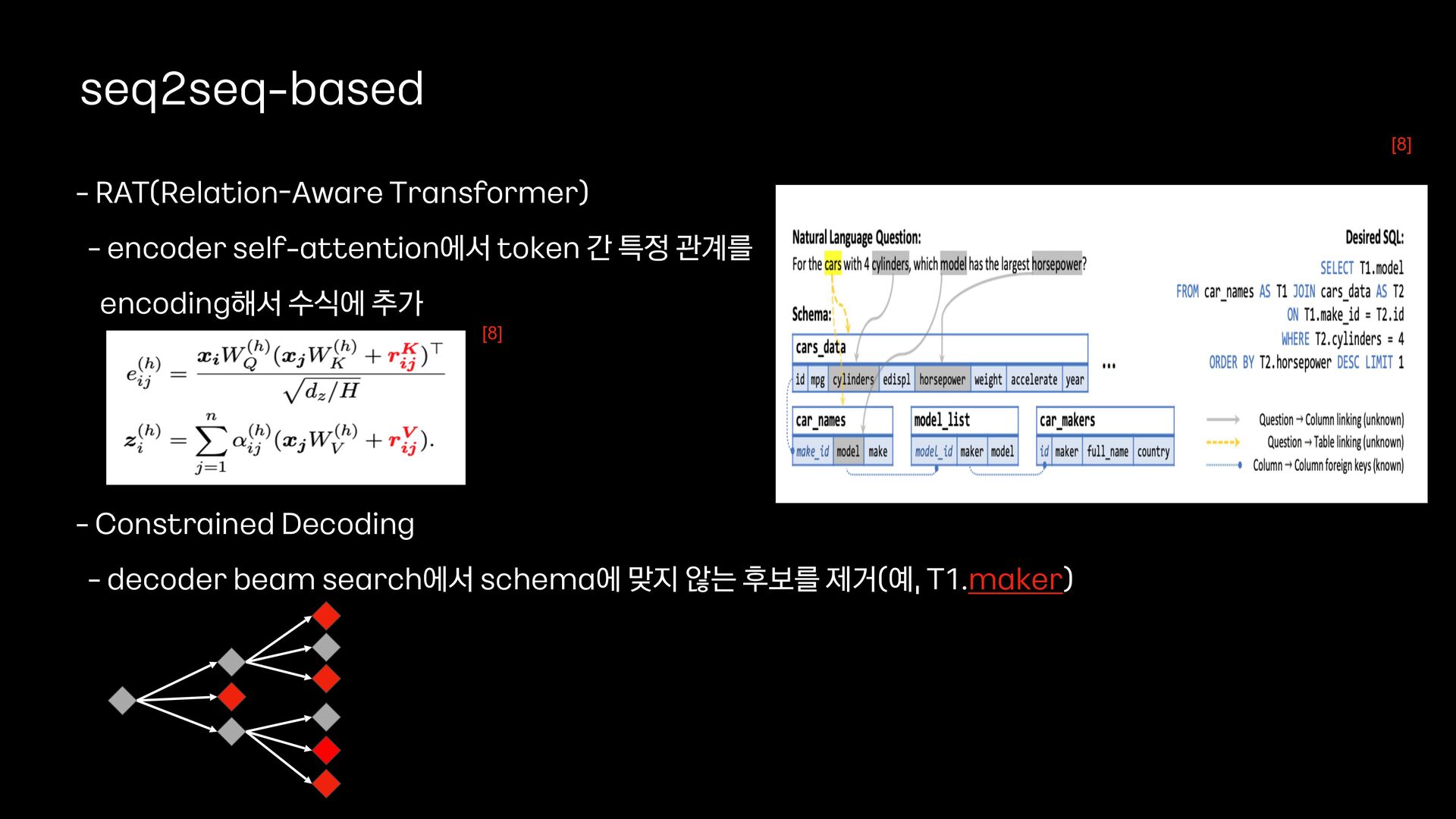{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![RYANSQL - 평가 - Spider Challenge [4], [5], [7] Models](https://files.speakerdeck.com/presentations/d3fb4a9e8db4400d87170fc598732209/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![참고 문헌 [1] database product brand logoٜ wikiীࢲ оઉ৳णפ. [2]](https://files.speakerdeck.com/presentations/d3fb4a9e8db4400d87170fc598732209/slide_52.jpg){kind=link}