Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
IoT向けストレージにTiKVを採用したときの話 / 2024-10-25 TiUG Meet...
Search
kamijin_fanta
October 25, 2024
Programming
180
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
IoT向けストレージにTiKVを採用したときの話 / 2024-10-25 TiUG Meetup 3 Using TiKV as IoT storage
https://tiug.connpass.com/event/327074/
kamijin_fanta
October 25, 2024
More Decks by kamijin_fanta
See All by kamijin_fanta
2026-06-11 Iceberg Trinoログ基盤の 設計ポイント - Design Points for an Iceberg + Trino Log Platform
kamijin_fanta
0
6
2025-09-22 Iceberg, Trinoでのログ基盤構築と パフォーマンス最適化
kamijin_fanta
1
850
2025-04-14 Data & Analytics 井戸端会議 Multi tenant log platform with Iceberg
kamijin_fanta
1
760
TrinoとIcebergで ログ基盤の構築 / 2023-10-05 Trino Presto Meetup
kamijin_fanta
1
2.5k
Unicodeと符号化形式
kamijin_fanta
0
1.2k
Reactとフォームとスキーマバリデーション / React forms with Schema Validation
kamijin_fanta
0
2.7k
2020/05/25 さくらのクラウド向けツールを使いこなす
kamijin_fanta
3
380
2019-01-24 業務でのOSSとの関わり方
kamijin_fanta
7
5k
関数型言語で始めるネットワークプログラミング
kamijin_fanta
0
1.2k
Other Decks in Programming
See All in Programming
SREの積み重ねがAI駆動開発のガードレールになった ― 7つの実践/SRE Guardrails The 7
tomoyakitaura
8
3.7k
なぜ型を書くのか? TSKaigi2026で改めて考える #tskaigi_smarthr
kajitack
0
330
これからAgentCoreを触る方へ トレンドはGatewayです
har1101
6
480
Signal Forms: Details & Live Coding @enterJS 2026 in Mannheim
manfredsteyer
PRO
0
220
Go1.27で導入されるジェネリクスメソッドでできること
mackee
0
270
Creating Composable Callables in Contemporary C++
rollbear
0
200
才能?センス?知らん、 続けたもん勝ちだ。-- 結婚・出産・癌を越えてなお、私がプロダクトを創り続ける理由
16bitidol
2
820
キャリア迷子上等 ─ "ない道"は自分で作ればいい
16bitidol
3
2.8k
AI がコードを書く時代における新卒エンジニアの仕事風景 (2026) / New Graduate Engineers in the Era of AI Coding (2026)
sushichan044
0
210
「なぜそう決めたのか」を残し続ける仕組み ― Notion AI カスタムエージェント × Slack連携による設計判断の自動記録 - NIKKEI Tech Talk #47
niftycorp
PRO
0
260
例外の正しい扱い方 そのエラー try-catchして大丈夫?
jinwatanabe
0
360
Hatena Engineer Seminar #37「言語モデルの活用に関する研究」
slashnephy
0
500
Featured
See All Featured
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
500
A Tale of Four Properties
chriscoyier
163
24k
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
Raft: Consensus for Rubyists
vanstee
141
7.6k
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Mind Mapping
helmedeiros
PRO
1
280
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
Code Reviewing Like a Champion
maltzj
528
40k
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
How GitHub (no longer) Works
holman
316
150k
Transcript
IoT向けストレージに TiKVを採用したときの話 2024-10-25 TiUG Meetup #3 Tadahisa Kamijo
上條 忠久 • さくらインターネット 2016年 新卒入社 • ずっと大阪勤務 • クラウド事業本部
所属 • 今は監視基盤を開発中 ◦ Go, Kotlin, React, TypeScript, TiDB, Trino, Iceberg… ※今日の話は多分当時はこうだったという適当な話です
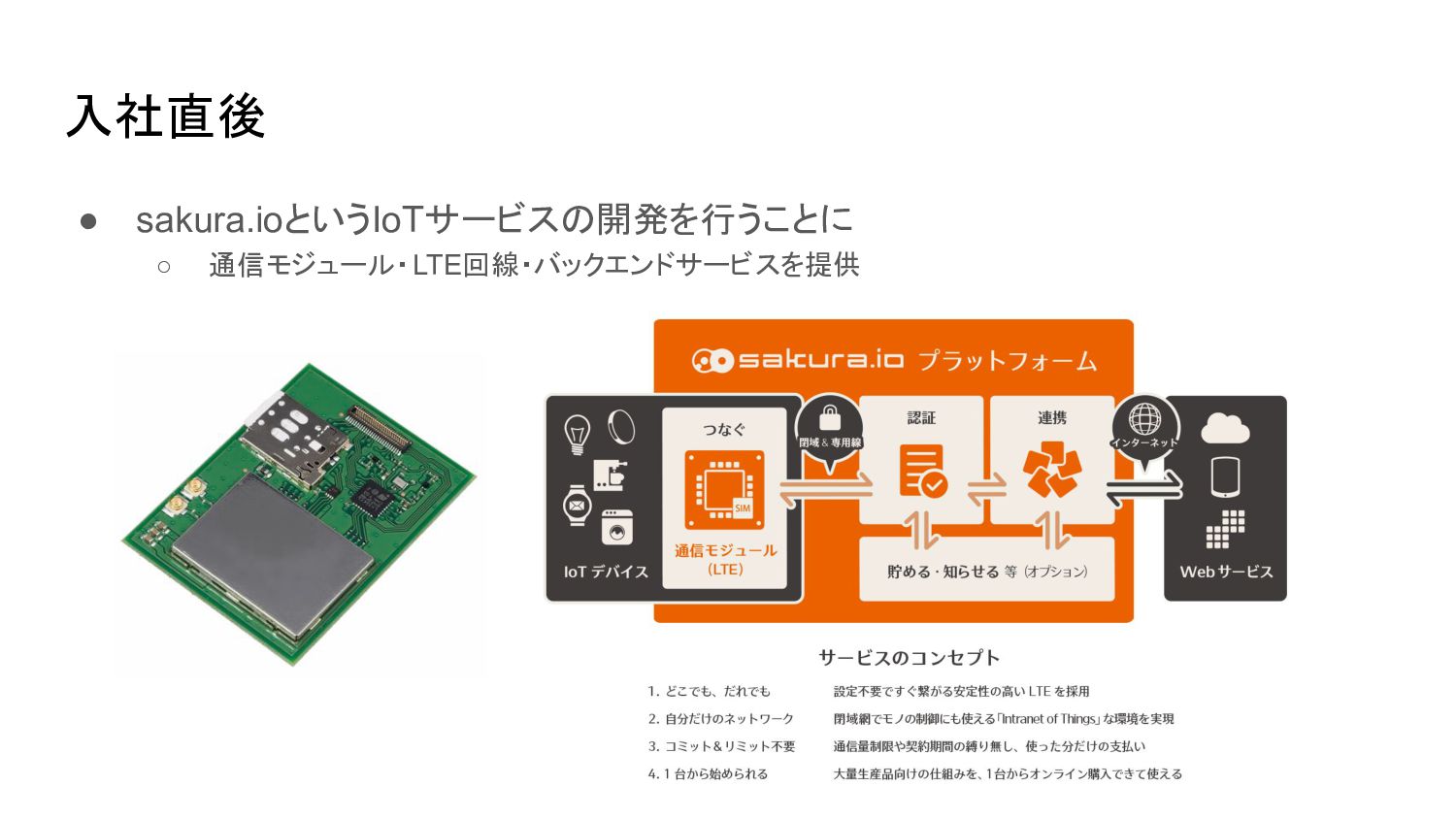
入社直後 • sakura.ioというIoTサービスの開発を行うことに ◦ 通信モジュール・LTE回線・バックエンドサービスを提供
無限にスケールする IoTストレージを作って えっ? ワイ えらい人
第一世代 • 当時DBはMySQL, Postgresql, Elasticsearchくらいしか知らなかった • Elasticsearch良さそう ◦ クラスタリング対応 スケーラビリティ・耐障害性高そう!
◦ レプリカ・シャードを割と自由に設定できるらしい! ◦ 自由にJSONでクエリ書ける! • 社内でも何台か動いているらしい • とりあえず作ってみよう ◦ Elasticsearchにデータを入れるところは JavaSDK + Scala + Akka http ◦ ユーザがアクセスする REST APIをPython + flask • 2016年6月から開発・同年12月にリリース
第一世代 つらかった • 実際にあった問題 ◦ メモリ使用量が異様に多い・開くファイルの数が多すぎて止まる ◦ データを投入する時にたまに止まる ◦ クラスタリングしているのに、サーバ
1台止まるだけで止まる ◦ クラスタにサーバを1台足すと止まる 調べると全部Elasticsearchが悪いんじゃなくて使い方が悪かった
なんで辛かったか • ElasticsearchにはIndexという保存領域が存在 • 毎日デバイス毎にIndexを作っていた ◦ 1000デバイスが3ヶ月間保存すると9万Index • どうやIndexあたり数MBのメモリが必要らしい ◦
9万Indexに必要なメモリ総量は 900GB…? ◦ 当時1台に割り当て可能なメモリは 32GBが最大 ◦ サーバ1台で30デバイスくらいしか収容できない … 1日1通のデバイスも居るんですが … • Index毎にPrimary/Secondaryの選出等が行われる ◦ ノードが追加・削除されたタイミングで全て選出し直される • ノード間のデータの容量に偏りが少なくなるようにリバランスが入る ◦ Indexあたり数十秒掛かる 並列でも数時間~数日単位で性能劣化 …
直した 毎日デバイス毎にIndexを作っていた ↓ 毎日全デバイスのメッセージを受け入れるIndexを作成
教訓 • パフォーマンステストやったほうが良い • ちゃんと仕組みを理解したほうが良い
どうしよう… • ElasticsearchのIndex毎にWriteのスケール限界がある • ”無限にスケール”からは遠ざかってしまった… • 運用性も改善はされたが課題は残る ◦ ノード追加・削除時にサービス断時間が減ったが …
第二世代の開発を開始 • 主な要件 ◦ デバイスから送信される JSONを保存・ユーザがHTTP APIでクエリできる事 ◦ 1日に1メッセージのデバイス・ 1秒に1メッセージのデバイス
数万倍の差を吸収できる事 • 色々なDBを調査 ◦ Cassandra, HBase, Hypertable, Kudu, MapR, Druid, InfluxDB, TimescaleDB ◦ 要件に合う・DB自体の運用が楽・アプリケーション側の実装が楽 なDBは意外と少ない • 色々試した結果TiKVが一番向いていそうだ
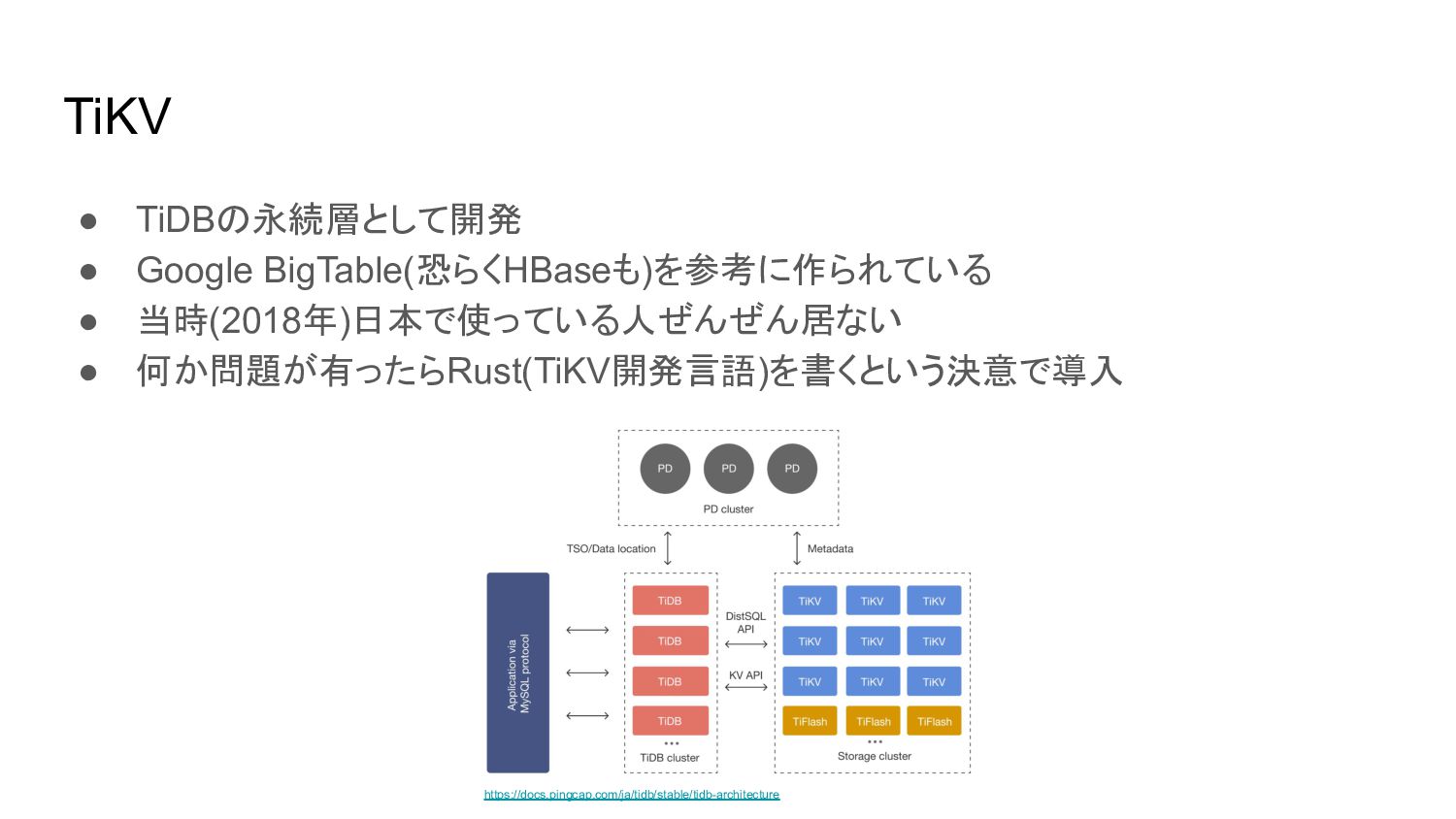
TiKV • TiDBの永続層として開発 • Google BigTable(恐らくHBaseも)を参考に作られている • 当時(2018年)日本で使っている人ぜんぜん居ない • 何か問題が有ったらRust(TiKV開発言語)を書くという決意で導入
https://docs.pingcap.com/ja/tidb/stable/tidb-architecture
第二世代 • ストレージはTiKV • 開発言語はGo ◦ TiKVのクライアントはGo向けが一番ちゃんとしていた • TiKVは便利なクエリ/Indexがない ◦
基本的に↓だけでアプリケーションを作る ◦ Get(key []byte) => []byte ◦ Put(key []byte, value []byte) ◦ Delete(key []byte) ◦ Scan(keyStart []byte, keyEnd []byte) => [][]byte • シンプルなので運用が比較的楽・コントロールしやすい
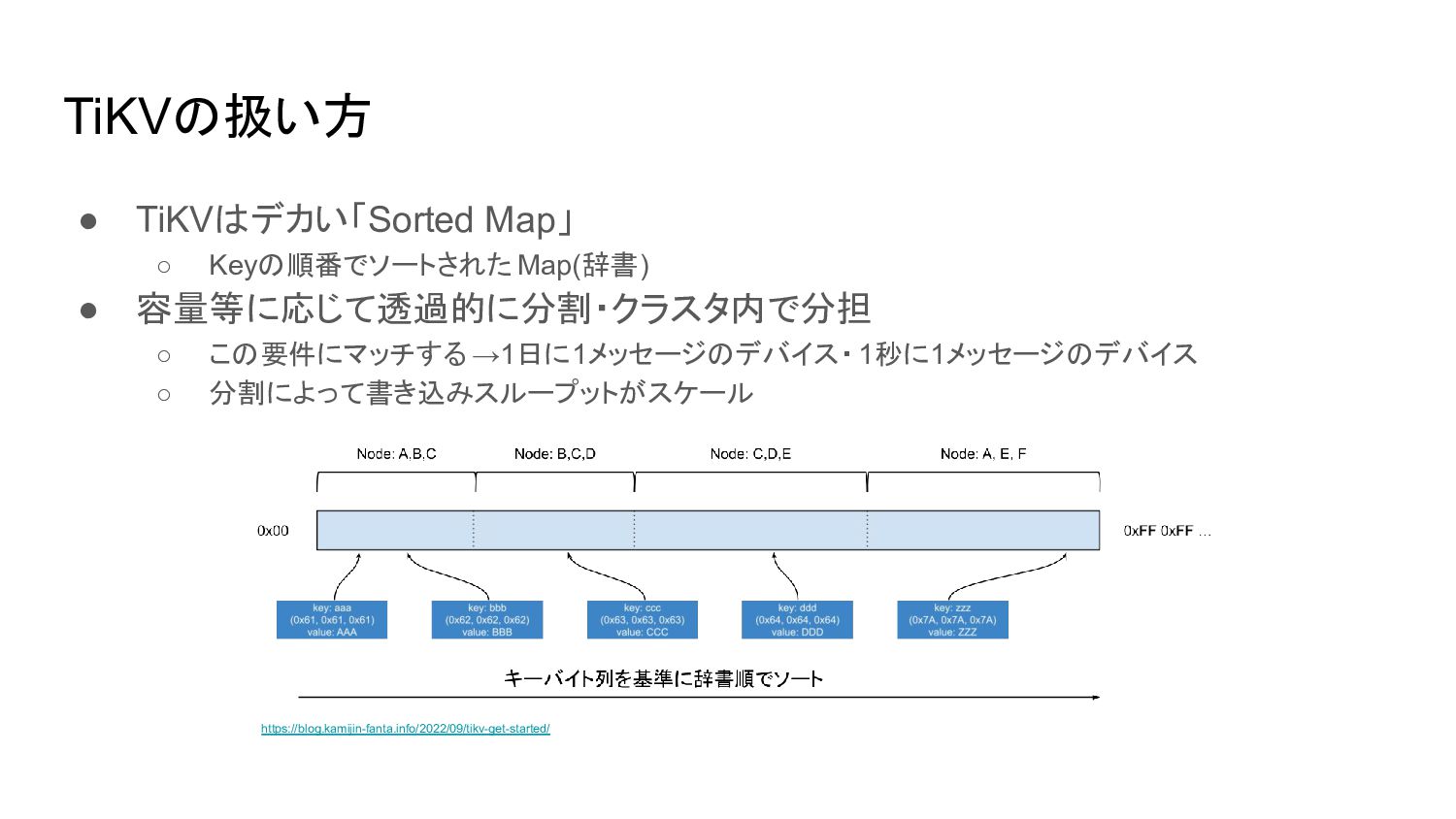
TiKVの扱い方 • TiKVはデカい「Sorted Map」 ◦ Keyの順番でソートされた Map(辞書) • 容量等に応じて透過的に分割・クラスタ内で分担 ◦
この要件にマッチする →1日に1メッセージのデバイス・ 1秒に1メッセージのデバイス ◦ 分割によって書き込みスループットがスケール https://blog.kamijin-fanta.info/2022/09/tikv-get-started/
TiKVでのキー設計 IoTストレージでの利用例 • Key: iotmsg_{deviceId}_{time}_{insertId} • Value: JSON Payload Scanの仕方
• 開始キー・終了キーを指定する 例: デバイス”aaa”の12:00:00~12:20:00 • 開始: iotmsg_aaa_2024-10-25_12-00-00_ • 終了: iotmsg_aaa_2024-10-25_12-20-00_ Key Value iotmsg_aaa_2024-10-25_12-10-00_AAAA {“paylaod”: … iotmsg_aaa_2024-10-25_12-20-00_BBBB {“paylaod”: … iotmsg_aaa_2024-10-25_12-30-00_CCCC {“paylaod”: … iotmsg_bbb_2024-10-25_12-05-00_DDDD {“paylaod”: … iotmsg_bbb_2024-10-25_12-15-00_EEEE {“paylaod”: … iotmsg_ccc_2024-10-25_12-08-00_FFFF {“paylaod”: … iotmsg_ddd_2024-10-25_12-09-00_GGGG {“paylaod”: …
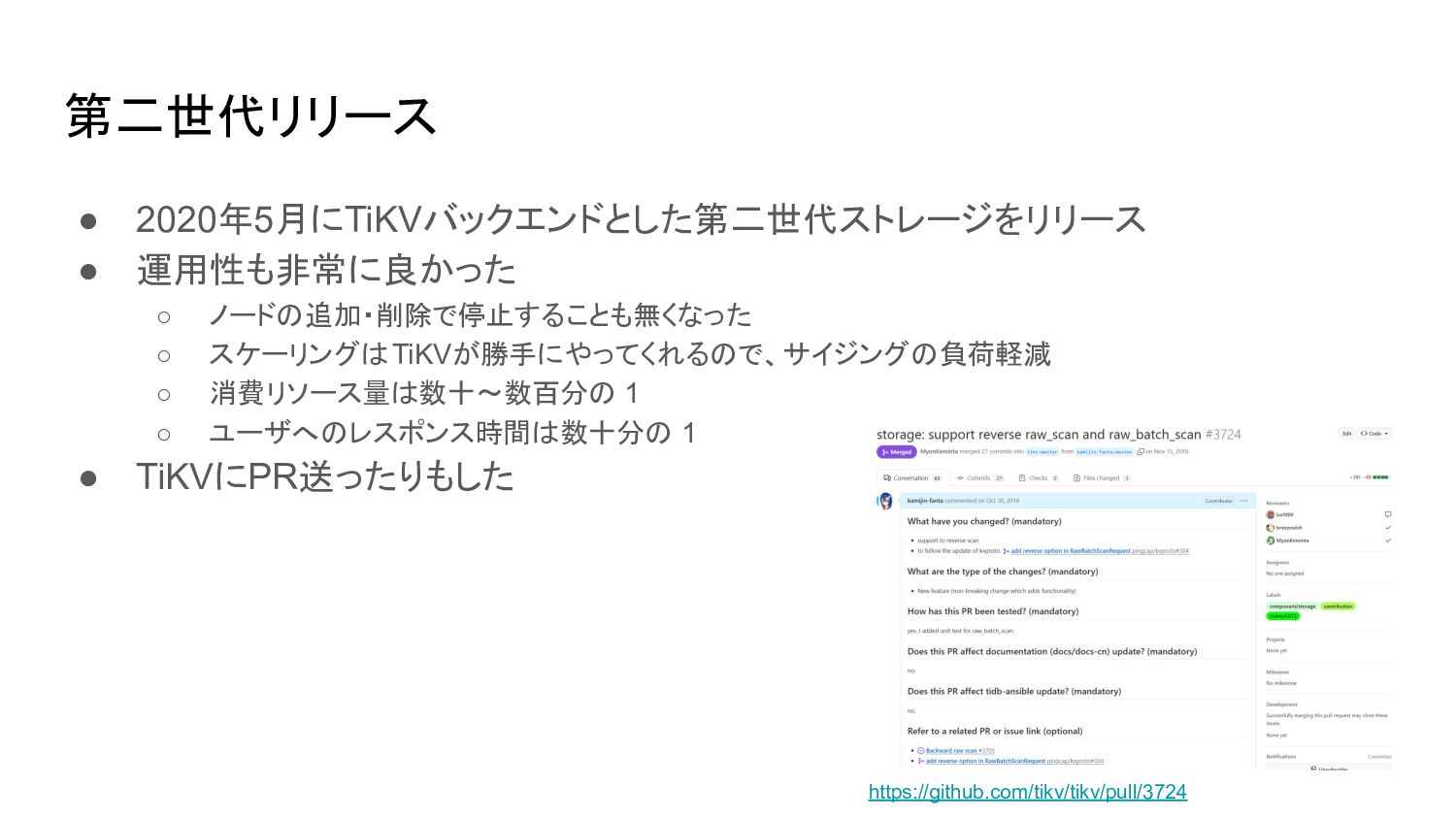
第二世代リリース • 2020年5月にTiKVバックエンドとした第二世代ストレージをリリース • 運用性も非常に良かった ◦ ノードの追加・削除で停止することも無くなった ◦ スケーリングはTiKVが勝手にやってくれるので、サイジングの負荷軽減 ◦
消費リソース量は数十~数百分の 1 ◦ ユーザへのレスポンス時間は数十分の 1 • TiKVにPR送ったりもした https://github.com/tikv/tikv/pull/3724
さくらインターネットのIoTサービス 頑張って作ったが… • 2016年4月1日 sakura.io パブリックα提供開始 • 2017年4月18日 sakura.io 正式サービス提供開始
• 2022年3月24日 後継サービス モノプラットフォーム提供開始 • 2024年5月30日 モノプラットフォーム 新規申し込み停止 SIM 1枚月額13円から利用可能なセキュアモバイルコネクトは継続して提供中
なぜTiDBを使わなかった? • TiDBはTiKV上に保存する際のキーを自由に指定できない ◦ Key: table{tableId}_record{rowId} ◦ tableIdはテーブルを分けることで変更できる・ rowIdはPKのint64 •
1テーブルに書き込む場合はスケールに限界がある ◦ 基本的にテーブルの末尾に追記する形になるので Prefixが分散しない(調整可能) ◦ WriteよりReadが非常に多いサービスは特に問題にならない • Key Prefixを分けるためにはTableを分ける必要がある ◦ 今回のケースだと、1デバイス毎に1テーブル ◦ スキーマ管理などのオペレーションが煩雑になりそう ※性能検証した上で受け入れられるならTiDBを使いましょう
IoT向けストレージにTiKVを採用したときの話 まとめ • TiDBで利用されるTiKVの性質 ◦ 大きいSorted Map ◦ 便利クエリは存在しないが安定性・スケーラビリティに優れる •
アーキテクチャを理解・パフォーマンステストした上でリリースしよう • GoからTiKVを触る話ブログで詳しく書いているので興味あれば ◦ NewSQL TiDBを支える分散KVS "TiKV"入門 https://blog.kamijin-fanta.info/2022/09/tikv-get-started/ さくらインターネットでは“こういう”ストレージの話が出来る人も募集中です
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}