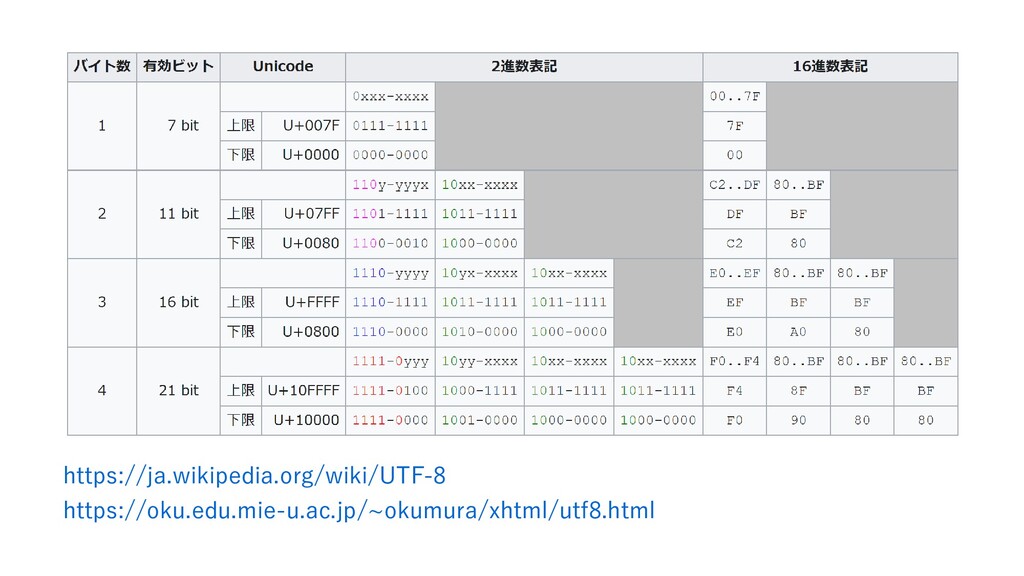
1998 https://tools.ietf.org/html/rfc2279 2003 https://tools.ietf.org/html/rfc3629 What is the maximum number of bytes for a UTF-8 encoded character? https://stackoverflow.com/questions/9533258/what-is-the-maximum-number- of-bytes-for-a-utf-8-encoded-character 結合文字 (NFC,NFD) https://tama-san.com/combining_character_sequence/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}