Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データ基盤でのコンテナ活用事例 / jawsug-akita-data-platform-wi...
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
kasacchiful
PRO
April 19, 2025
Programming
180
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データ基盤でのコンテナ活用事例 / jawsug-akita-data-platform-with-container
2025/04/19 (土) JAWS-UG秋田
事例紹介資料
イベントページ
https://jaws-tohoku.connpass.com/event/349739/
kasacchiful
PRO
April 19, 2025
More Decks by kasacchiful
See All by kasacchiful
Step FunctionsでAIエージェント × 人の承認を試す / 20260705jawsug-hokurikushinkansen-agentcore-hitl-workflow
kasacchiful
PRO
0
55
上越のサメ食文化を訪ねて - 新潟市民の初体験レポ / ssmjp-shark
kasacchiful
PRO
1
67
Rust on AWS でデータ分析 / 20260523iotlt-niigata-rust-on-aws
kasacchiful
PRO
0
29
Step Functionsで始めるサーバーレス入門 〜 つないで動かすAWSサーバーレス
kasacchiful
PRO
0
61
Amazon Q Developer CLI (現Kiro CLI) で作った 新潟ランチマップWebアプリのこれまでとこれから / 20260207jawsug-tochigi
kasacchiful
PRO
0
100
Amazon SageMaker Catalogの、AIエージェントによる自動データ分類機能を試してみようとしたが、できなかったので、代わりに最近構築したデータ連携基盤を紹介します / 20260117jawsug-fukui
kasacchiful
PRO
0
120
データファイルをAWSのDWHサービスに格納する / 20251115jawsug-tochigi
kasacchiful
PRO
2
280
テーブル定義書の構造化抽出して、生成AIでDWH分析を試してみた / devio2025tokyo
kasacchiful
PRO
0
950
ワイがおすすめする新潟の食 / 20250912jasst-niigata-lt
kasacchiful
PRO
1
64
Other Decks in Programming
See All in Programming
フロントエンドとバックエンドで「1文字」を揃えよう
youkidearitai
PRO
0
770
Signal Forms: Details & Live Coding @enterJS 2026 in Mannheim
manfredsteyer
PRO
0
200
コンテキストの使い捨てをやめる — ビジネスルール駆動開発と miko —
ioki
0
250
LLM本来の能力を解き放つサンドボックス技術とAI民主化への適用
yukukotani
3
4.6k
LLMによるContent Moderationの本番運用の裏側と品質担保への挑戦
suikabar
3
800
Vite+ Unified Toolchain for the Web
naokihaba
0
370
Javaの型とAI時代に型が大事な理由 / java types and type in AI era
kishida
2
150
Make SRE Operations Easier with Azure SRE Agent
kkamegawa
0
9.1k
Strategic Design in the Frontend: Moduliths & Micro Frontends @DDDEurope
manfredsteyer
PRO
0
130
「なぜそう決めたのか」を残し続ける仕組み ― Notion AI カスタムエージェント × Slack連携による設計判断の自動記録 - NIKKEI Tech Talk #47
niftycorp
PRO
0
240
IBM Bobを活用したレガシーアプリの最新化
oniak3ibm
PRO
1
220
不変条件と整合性境界—ビジネスが決める設計判断と実現パターン / Invariants and Consistency Boundaries
nrslib
14
6k
Featured
See All Featured
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
340
Build your cross-platform service in a week with App Engine
jlugia
234
18k
Typedesign – Prime Four
hannesfritz
42
3.1k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
210
A Tale of Four Properties
chriscoyier
163
24k
AI: The stuff that nobody shows you
jnunemaker
PRO
8
750
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
210
Everyday Curiosity
cassininazir
0
240
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
240
The untapped power of vector embeddings
frankvandijk
2
1.8k
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
Transcript
データ基盤でのコンテナ活用事例 笠原 宏 2025/04/19(土) JAWS-UG秋田
笠原 宏 (@kasacchiful) クラスメソッド株式会社データ事業本部 ビジネスソリューション部 ソリューションアーキテクト 新潟市在住 JAWS-UG新潟 / Python機械学習勉強会in新潟
/ JaSST新潟 / ASTER / SWANII / Cloudflare Meetup Niigata AWS Community Builder (Serverless) 自己紹介 2 / 29
1. データ基盤でのコンテナ活用事例 概要 Lambdaコンテナ導入 LambdaコンテナからECS/Fargateへ移行 LambdaコンテナとECS/Fargateコンテナとの違い 2. まとめ 目次 3
/ 29
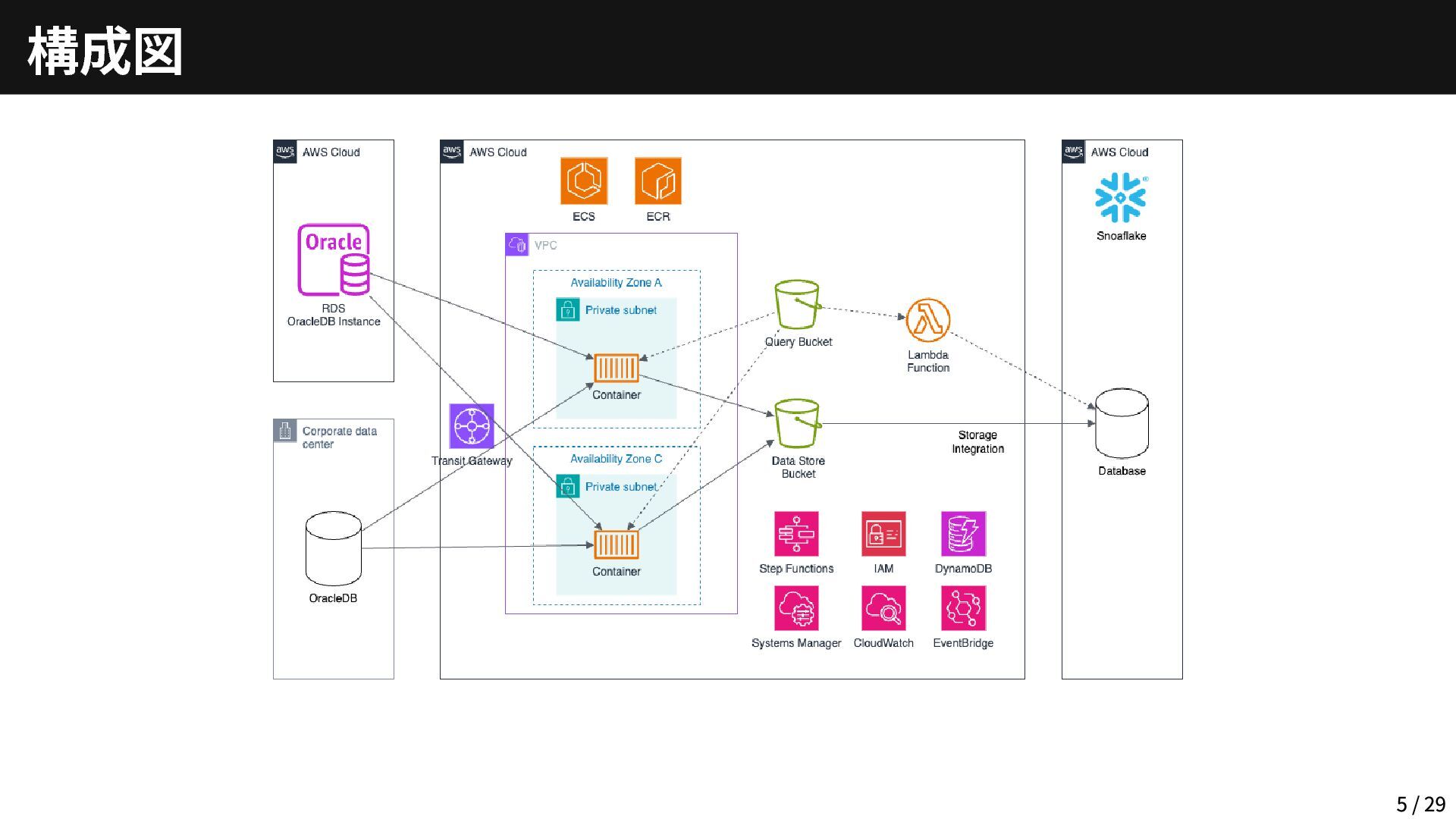
オンプレミスやRDSにあるOracle DBから、DWH(Snowflake)にデータを溜めたい DWHでは、データマートを整備して、BIツールでデータを可視化したい とある事例 4 / 29
構成図 5 / 29
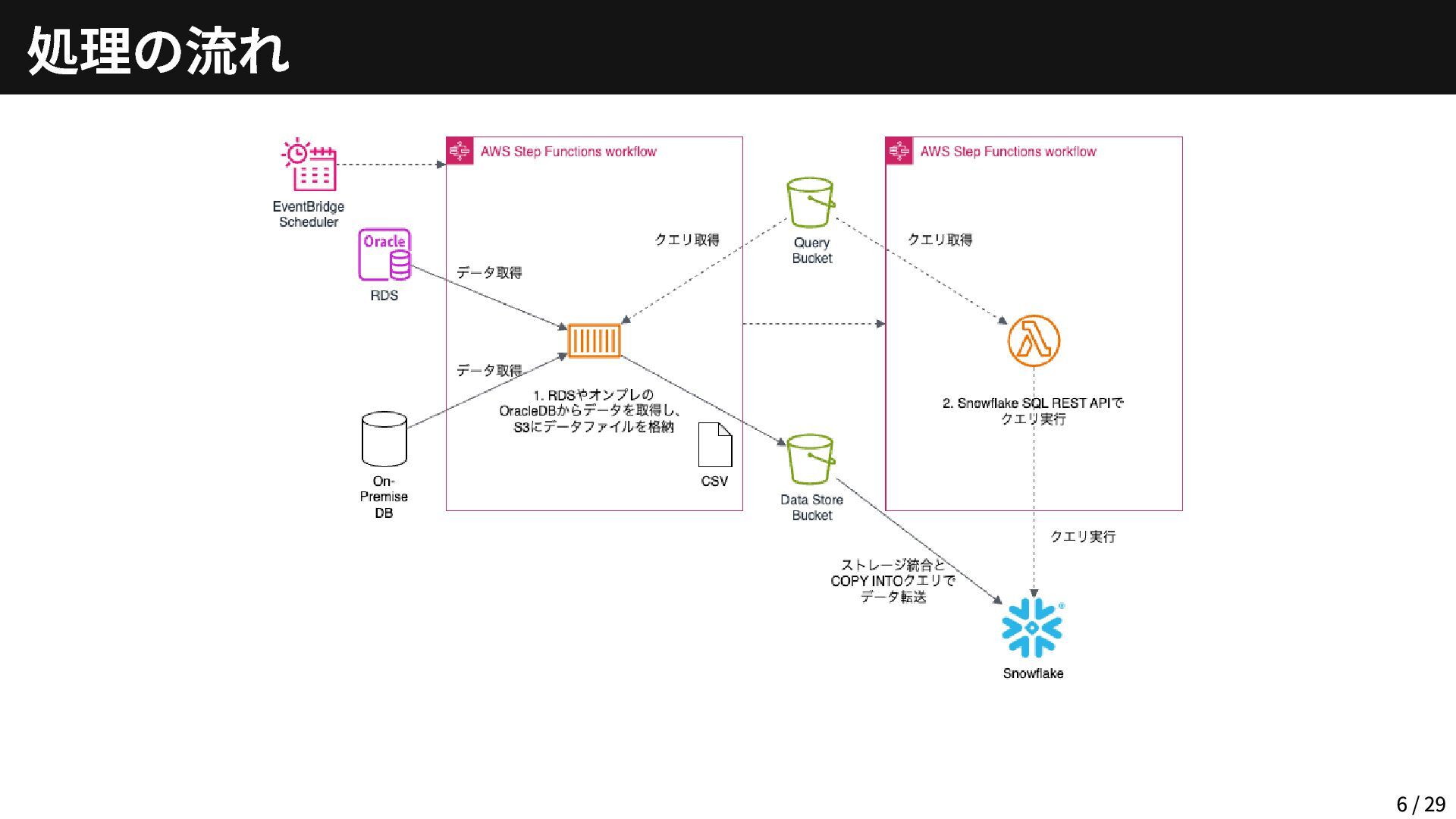
処理の流れ 6 / 29
Oracle DBはオンプレミスや他アカウントのRDSにある お客様にてTransit GatewayやDirectConnectが整備済 Transit Gateway経由でアクセス可能 接続先は4箇所 (オンプレミス・RDS含め) Oracle DBのバージョンは全て19c
ただし、RDS以外は sec_case_sensitive_logon がFalse 「ログイン時のパスワードの大文字・小文字を区別しない」古い設定 「python-oracledb」ライブラリのthinモード(Oracleクライアント不要)では 接続できず、thickモード(Oracleクライアント必要)での接続が必須 Oracle Instant Client導入するにしても容量が大きいため、今回はコンテナ化 (Lambdaコンテナ) で対応する Oracle DBへのクエリはS3に保管しておいて、実行時にダウンロード Oracle DB → S3 7 / 29
Snowflakeには「Snowpipe」という便利な機能がある 今回はSnowflake SQL REST APIをLambdaから実行して、Snowflakeのテーブル にロードする方法をとった (なお、今回のテーマにはあまり関わってこないところなので、詳細は控える) S3 → DWH(Snowflake)
8 / 29
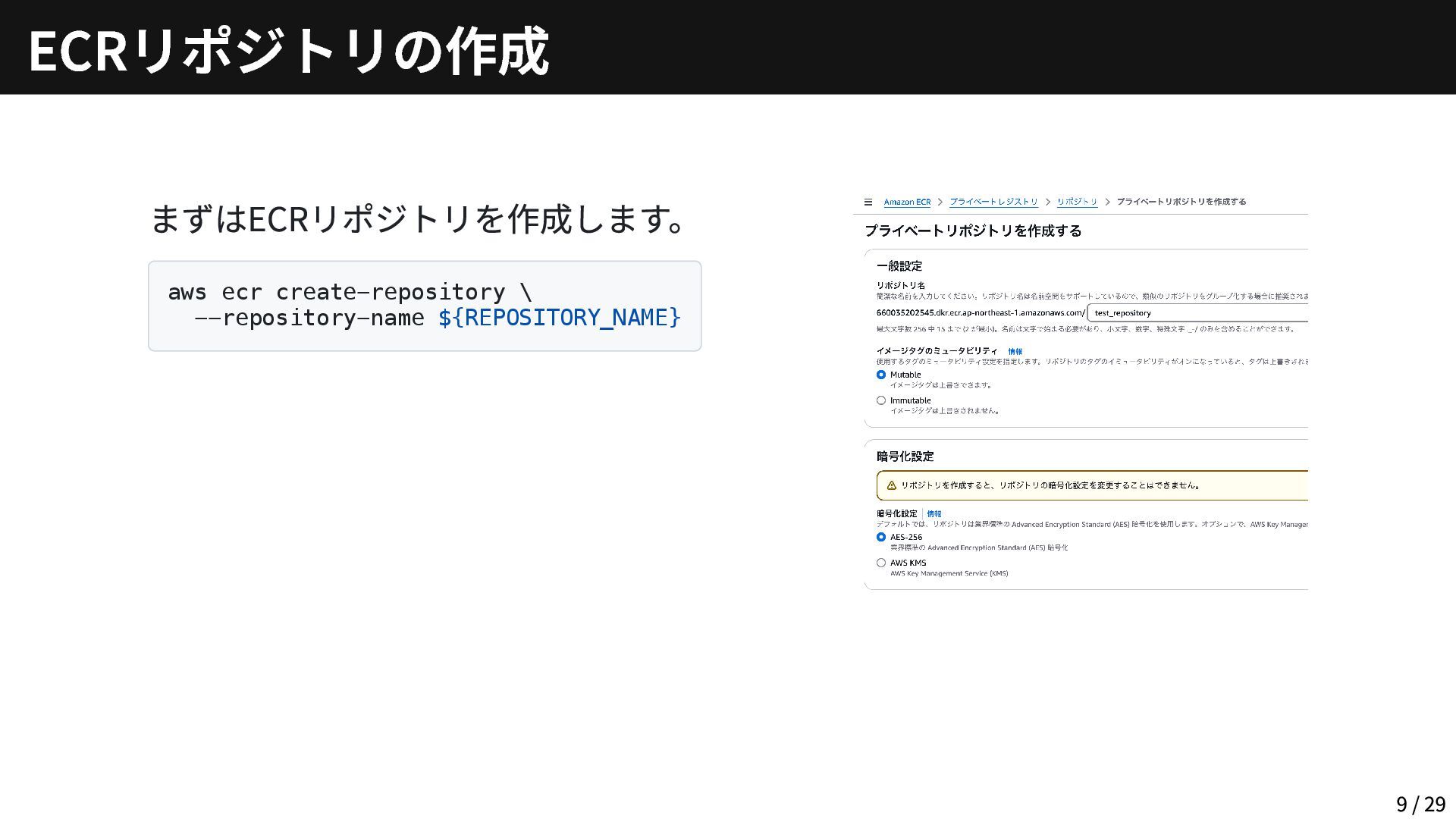
まずはECRリポジトリを作成します。 aws ecr create-repository \ --repository-name ${REPOSITORY_NAME} ECRリポジトリの作成 9 /
29
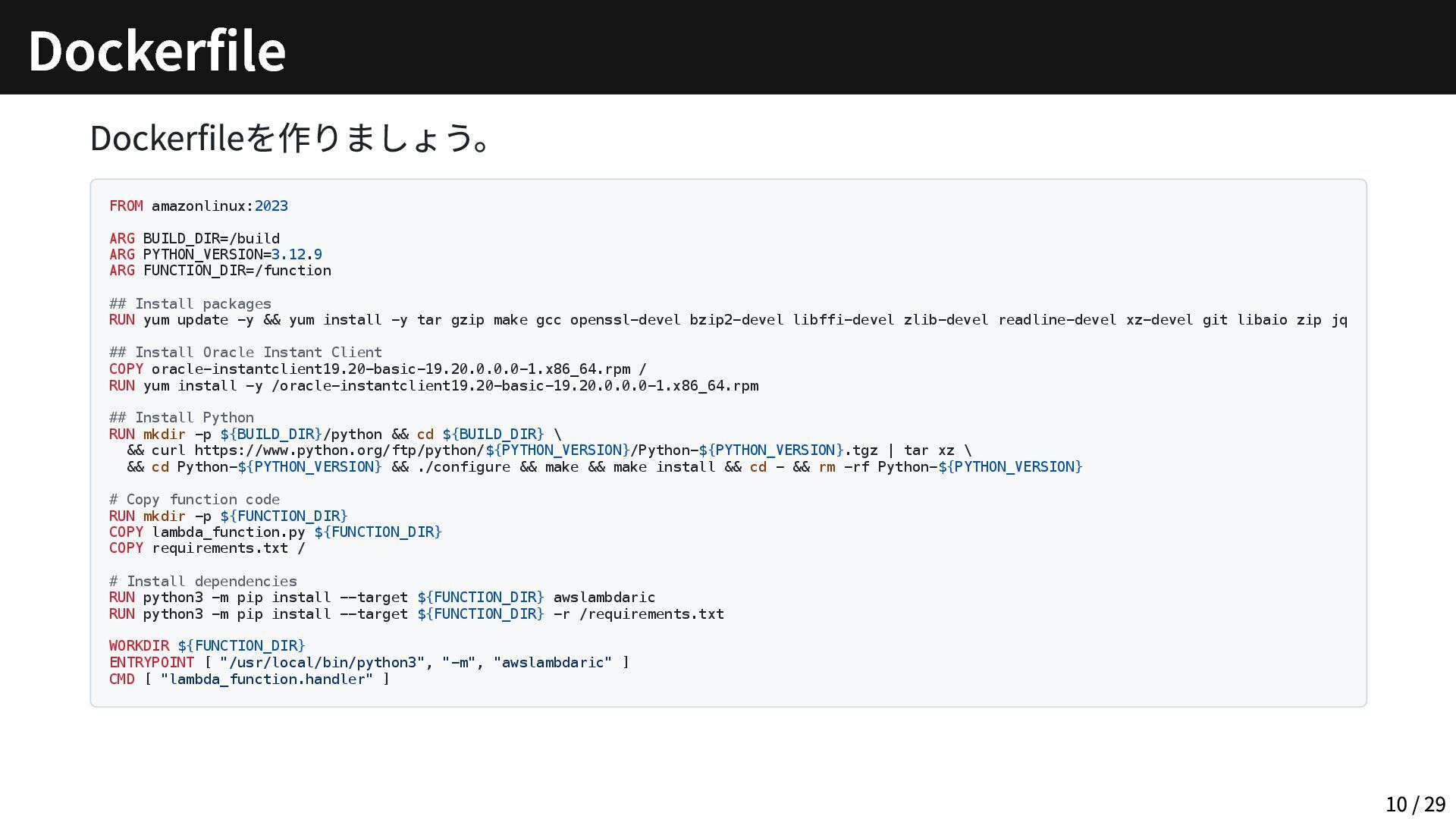
Dockerfileを作りましょう。 FROM amazonlinux:2023 ARG BUILD_DIR=/build ARG PYTHON_VERSION=3.12.9 ARG FUNCTION_DIR=/function ##
Install packages RUN yum update -y && yum install -y tar gzip make gcc openssl-devel bzip2-devel libffi-devel zlib-devel readline-devel xz-devel git libaio zip jq ## Install Oracle Instant Client COPY oracle-instantclient19.20-basic-19.20.0.0.0-1.x86_64.rpm / RUN yum install -y /oracle-instantclient19.20-basic-19.20.0.0.0-1.x86_64.rpm ## Install Python RUN mkdir -p ${BUILD_DIR}/python && cd ${BUILD_DIR} \ && curl https://www.python.org/ftp/python/${PYTHON_VERSION}/Python-${PYTHON_VERSION}.tgz | tar xz \ && cd Python-${PYTHON_VERSION} && ./configure && make && make install && cd - && rm -rf Python-${PYTHON_VERSION} # Copy function code RUN mkdir -p ${FUNCTION_DIR} COPY lambda_function.py ${FUNCTION_DIR} COPY requirements.txt / # Install dependencies RUN python3 -m pip install --target ${FUNCTION_DIR} awslambdaric RUN python3 -m pip install --target ${FUNCTION_DIR} -r /requirements.txt WORKDIR ${FUNCTION_DIR} ENTRYPOINT [ "/usr/local/bin/python3", "-m", "awslambdaric" ] CMD [ "lambda_function.handler" ] Dockerfile 10 / 29
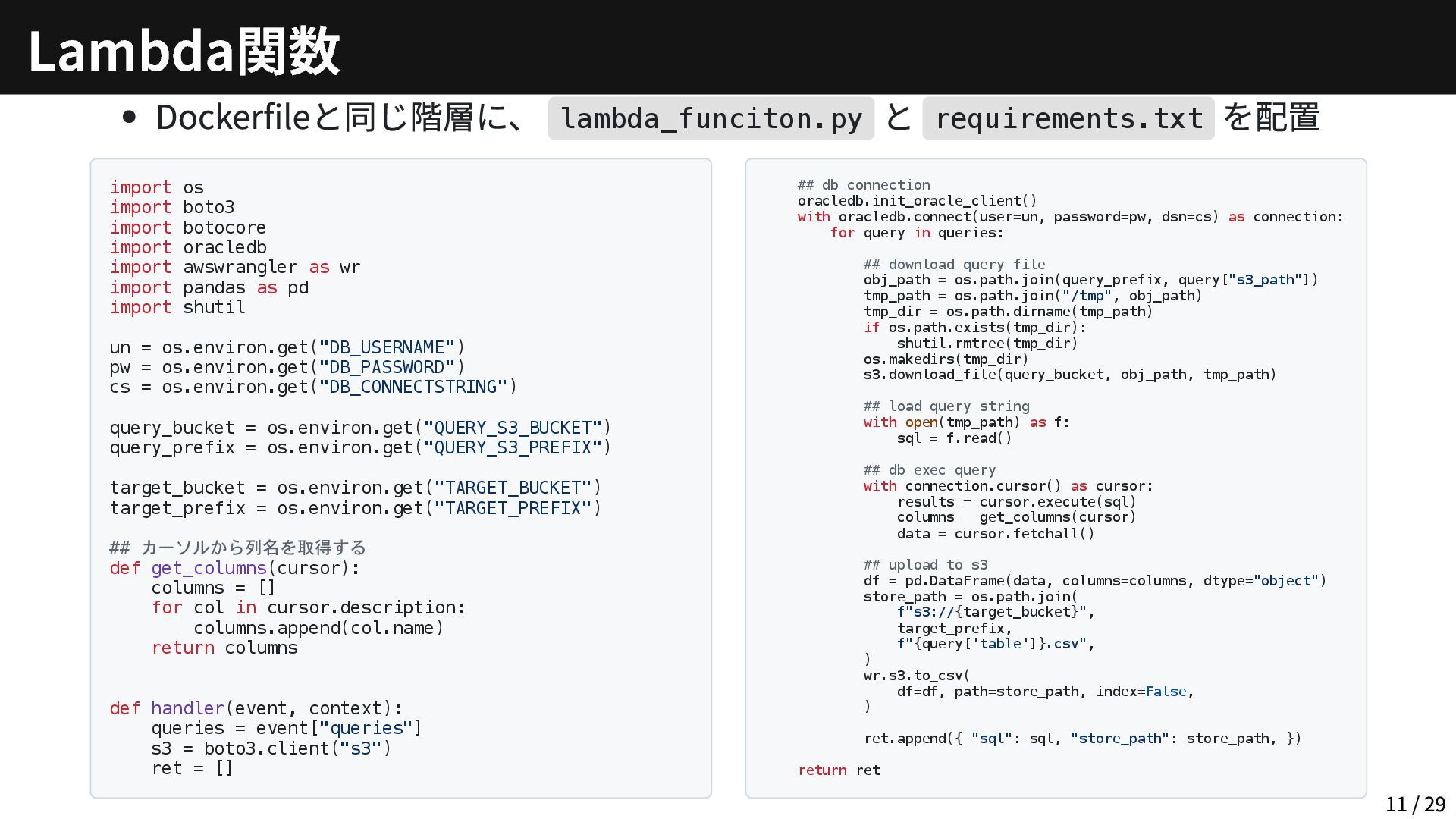
Dockerfileと同じ階層に、 lambda_funciton.py と requirements.txt を配置 import os import boto3 import
botocore import oracledb import awswrangler as wr import pandas as pd import shutil un = os.environ.get("DB_USERNAME") pw = os.environ.get("DB_PASSWORD") cs = os.environ.get("DB_CONNECTSTRING") query_bucket = os.environ.get("QUERY_S3_BUCKET") query_prefix = os.environ.get("QUERY_S3_PREFIX") target_bucket = os.environ.get("TARGET_BUCKET") target_prefix = os.environ.get("TARGET_PREFIX") ## カーソルから列名を取得する def get_columns(cursor): columns = [] for col in cursor.description: columns.append(col.name) return columns def handler(event, context): queries = event["queries"] s3 = boto3.client("s3") ret = [] ## db connection oracledb.init_oracle_client() with oracledb.connect(user=un, password=pw, dsn=cs) as connection: for query in queries: ## download query file obj_path = os.path.join(query_prefix, query["s3_path"]) tmp_path = os.path.join("/tmp", obj_path) tmp_dir = os.path.dirname(tmp_path) if os.path.exists(tmp_dir): shutil.rmtree(tmp_dir) os.makedirs(tmp_dir) s3.download_file(query_bucket, obj_path, tmp_path) ## load query string with open(tmp_path) as f: sql = f.read() ## db exec query with connection.cursor() as cursor: results = cursor.execute(sql) columns = get_columns(cursor) data = cursor.fetchall() ## upload to s3 df = pd.DataFrame(data, columns=columns, dtype="object") store_path = os.path.join( f"s3://{target_bucket}", target_prefix, f"{query['table']}.csv", ) wr.s3.to_csv( df=df, path=store_path, index=False, ) ret.append({ "sql": sql, "store_path": store_path, }) return ret Lambda関数 11 / 29
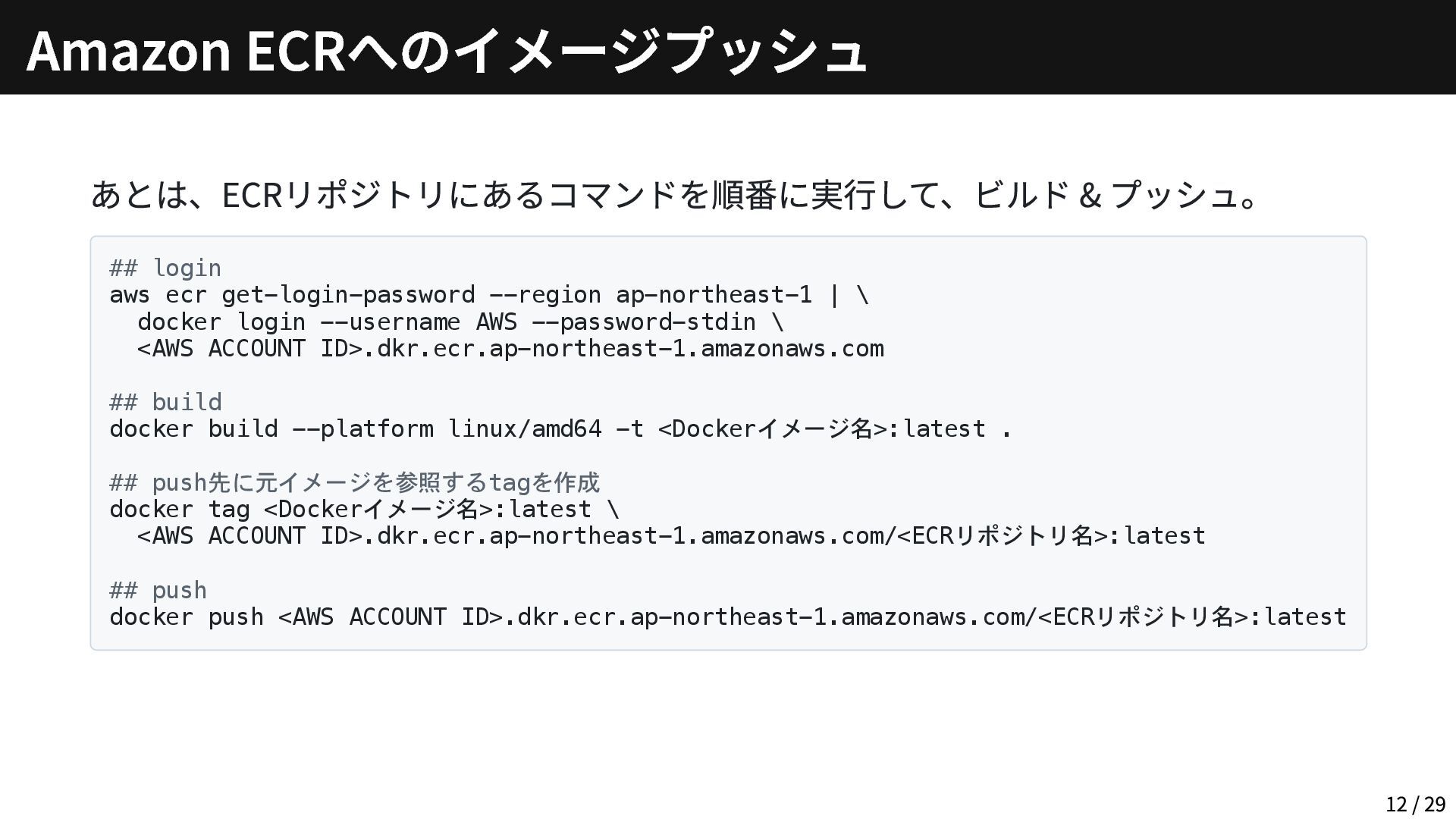
あとは、ECRリポジトリにあるコマンドを順番に実行して、ビルド & プッシュ。 ## login aws ecr get-login-password --region ap-northeast-1
| \ docker login --username AWS --password-stdin \ <AWS ACCOUNT ID>.dkr.ecr.ap-northeast-1.amazonaws.com ## build docker build --platform linux/amd64 -t <Dockerイメージ名>:latest . ## push先に元イメージを参照するtagを作成 docker tag <Dockerイメージ名>:latest \ <AWS ACCOUNT ID>.dkr.ecr.ap-northeast-1.amazonaws.com/<ECRリポジトリ名>:latest ## push docker push <AWS ACCOUNT ID>.dkr.ecr.ap-northeast-1.amazonaws.com/<ECRリポジトリ名>:latest Amazon ECRへのイメージプッシュ 12 / 29
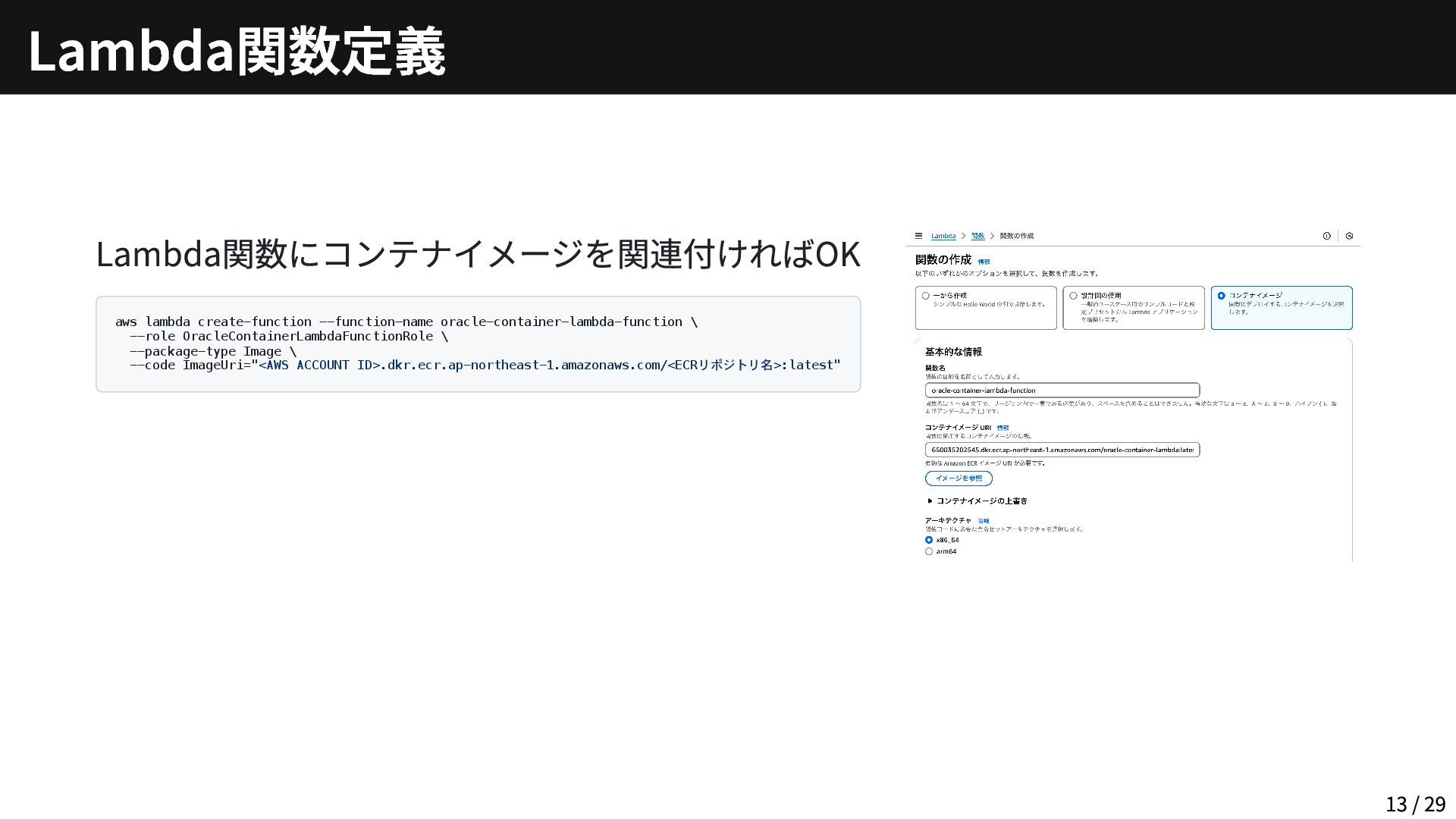
Lambda関数にコンテナイメージを関連付ければOK aws lambda create-function --function-name oracle-container-lambda-function \ --role OracleContainerLambdaFunctionRole \
--package-type Image \ --code ImageUri="<AWS ACCOUNT ID>.dkr.ecr.ap-northeast-1.amazonaws.com/<ECRリポジトリ名>:latest" Lambda関数定義 13 / 29
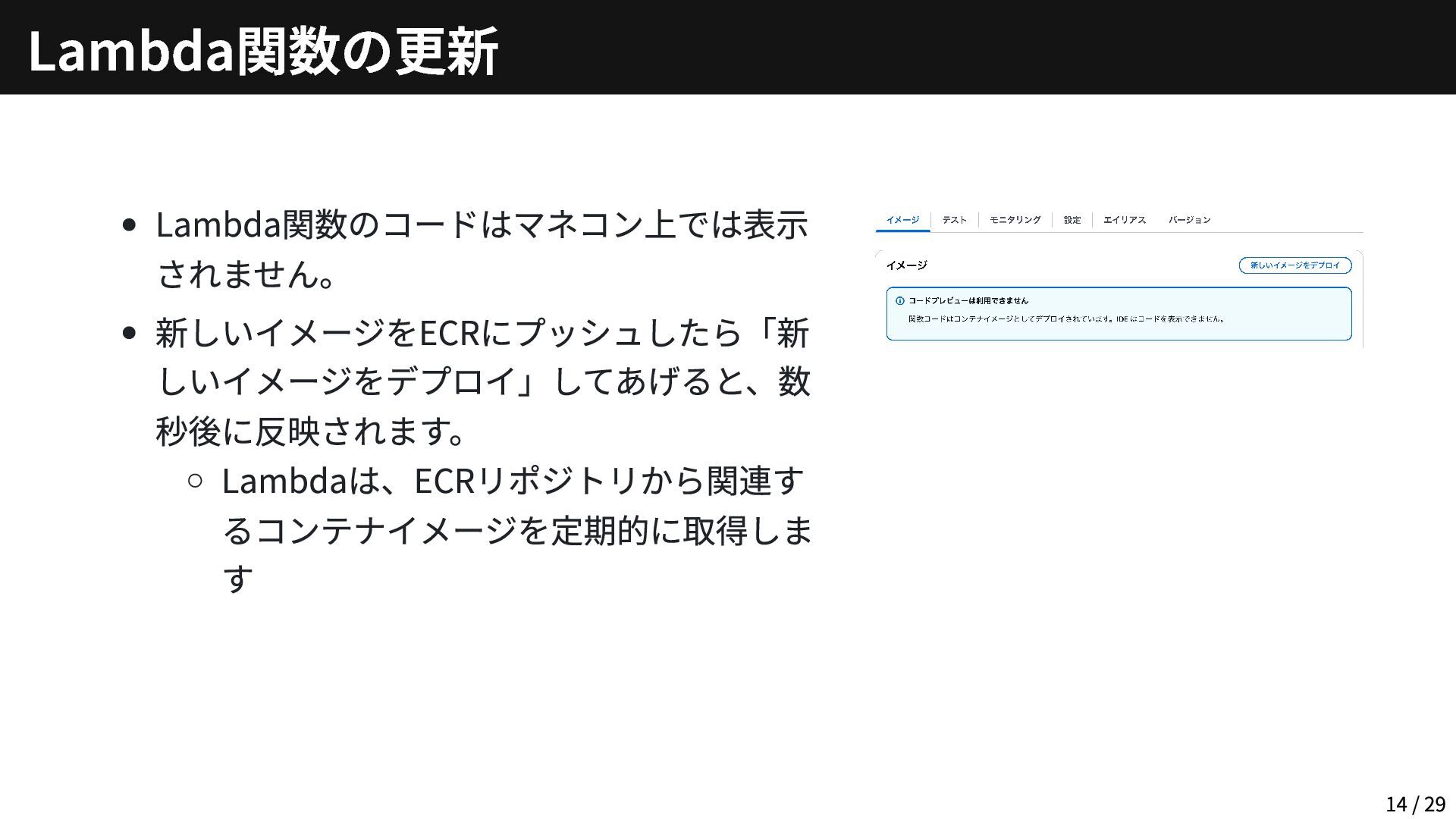
Lambda関数のコードはマネコン上では表示 されません。 新しいイメージをECRにプッシュしたら「新 しいイメージをデプロイ」してあげると、数 秒後に反映されます。 Lambdaは、ECRリポジトリから関連す るコンテナイメージを定期的に取得しま す Lambda関数の更新 14
/ 29
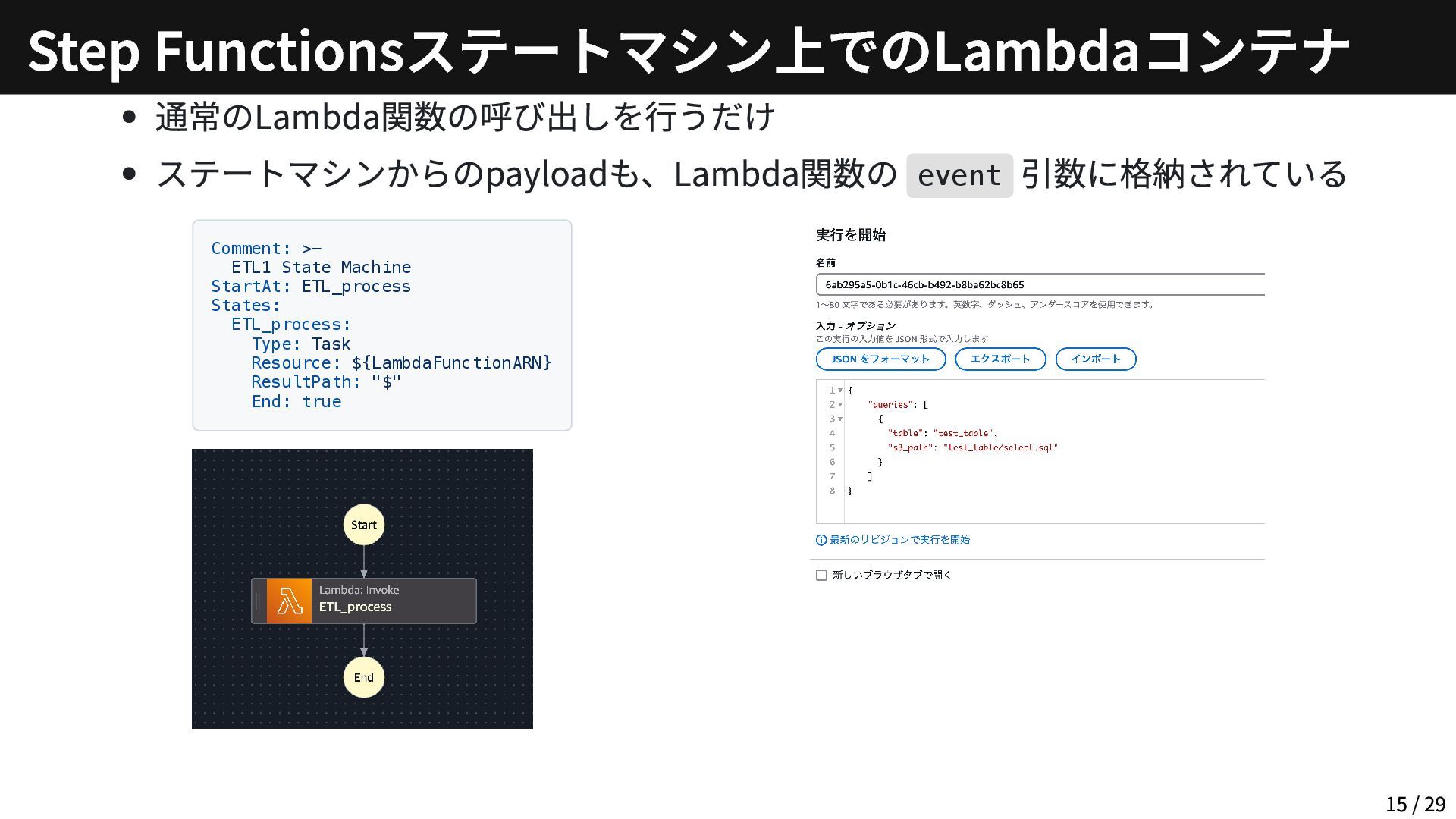
通常のLambda関数の呼び出しを行うだけ ステートマシンからのpayloadも、Lambda関数の event 引数に格納されている Comment: >- ETL1 State Machine StartAt:
ETL_process States: ETL_process: Type: Task Resource: ${LambdaFunctionARN} ResultPath: "$" End: true Step Functionsステートマシン上でのLambdaコンテナ 15 / 29
Lambdaコンテナではなく、通常のzipアーカイブの関数を用意 今回はSnowflakeのSQL REST APIをコールして、SQLでデータを取り込む ## <省略> def handler(event, context): query
= event["query"] query_s3_path = query["s3_path"] ## 認証トークン生成 jwt_token, account_id = generate_jwt_token() ## クエリ取得 sql = load_query_statement(query_s3_path) ## Snowflake SQL APIコール用設定 url = "" ## <省略> headers = {} ## <省略> query_params = {} ## <省略> ## Snowflake SQL APIコール response = requests.post(url, headers=headers, json=query_params,) ## <省略> return {} S3 → Snowflakeも似たような感じ 16 / 29
Lambdaの実行時間制限「15分」を超える処理が必要になる メモリも上限10GBじゃ足りなくなる Lambdaコンテナから、ECS/Fargateへ移行 その後の運用にて 17 / 29
1. Lambda関数はそのままに、ECS/Fargateのエントリポイント用の関数を用意する 2. Dockerfileのエントリポイントを変更する 3. Step Functionsのステートマシン上でサービス定義 4. ステートマシン上のpayloadは、必要な項目をCommandに渡す 5.
VPCエンドポイントを各種用意する 6. ステートマシンの実行権限に注意 LambdaコンテナからECS/Fargateへの変更方法 18 / 29
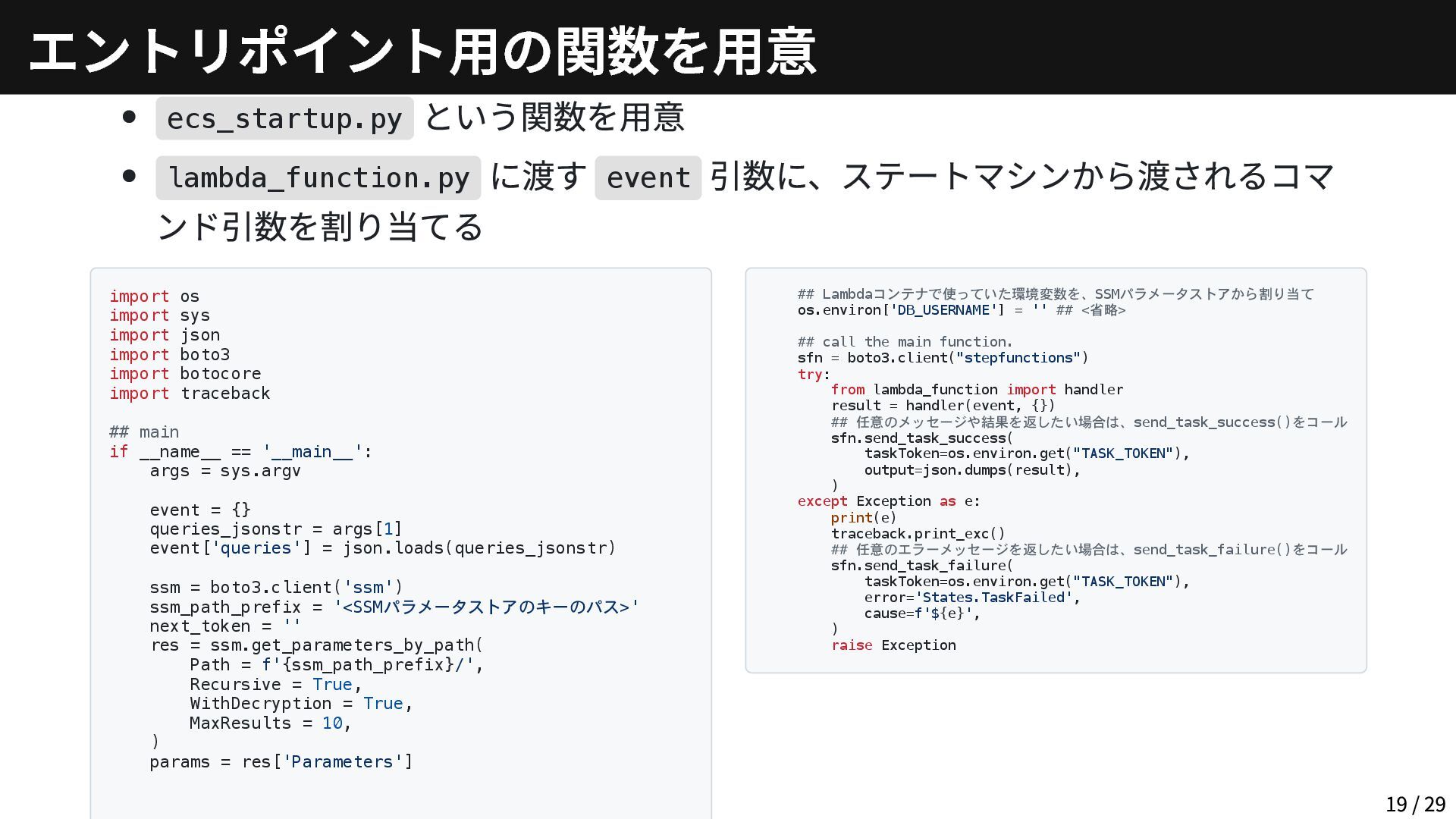
ecs_startup.py という関数を用意 lambda_function.py に渡す event 引数に、ステートマシンから渡されるコマ ンド引数を割り当てる import os import
sys import json import boto3 import botocore import traceback ## main if __name__ == '__main__': args = sys.argv event = {} queries_jsonstr = args[1] event['queries'] = json.loads(queries_jsonstr) ssm = boto3.client('ssm') ssm_path_prefix = '<SSMパラメータストアのキーのパス>' next_token = '' res = ssm.get_parameters_by_path( Path = f'{ssm_path_prefix}/', Recursive = True, WithDecryption = True, MaxResults = 10, ) params = res['Parameters'] ## Lambdaコンテナで使っていた環境変数を、SSMパラメータストアから割り当て os.environ['DB_USERNAME'] = '' ## <省略> ## call the main function. sfn = boto3.client("stepfunctions") try: from lambda_function import handler result = handler(event, {}) ## 任意のメッセージや結果を返したい場合は、send_task_success()をコール sfn.send_task_success( taskToken=os.environ.get("TASK_TOKEN"), output=json.dumps(result), ) except Exception as e: print(e) traceback.print_exc() ## 任意のエラーメッセージを返したい場合は、send_task_failure()をコール sfn.send_task_failure( taskToken=os.environ.get("TASK_TOKEN"), error='States.TaskFailed', cause=f'${e}', ) raise Exception エントリポイント用の関数を用意 19 / 29
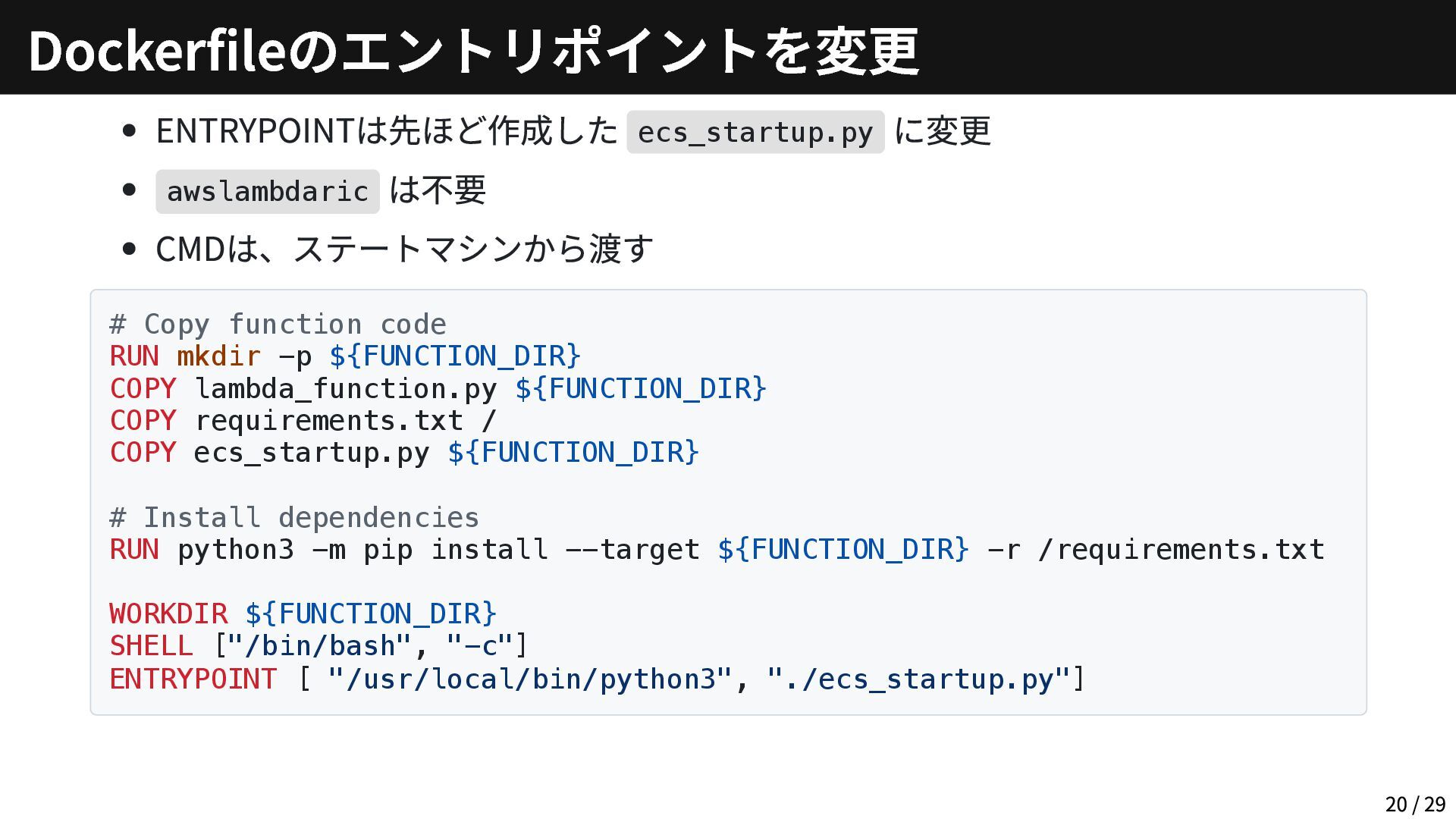
ENTRYPOINTは先ほど作成した ecs_startup.py に変更 awslambdaric は不要 CMDは、ステートマシンから渡す # Copy function code
RUN mkdir -p ${FUNCTION_DIR} COPY lambda_function.py ${FUNCTION_DIR} COPY requirements.txt / COPY ecs_startup.py ${FUNCTION_DIR} # Install dependencies RUN python3 -m pip install --target ${FUNCTION_DIR} -r /requirements.txt WORKDIR ${FUNCTION_DIR} SHELL ["/bin/bash", "-c"] ENTRYPOINT [ "/usr/local/bin/python3", "./ecs_startup.py"] Dockerfileのエントリポイントを変更 20 / 29
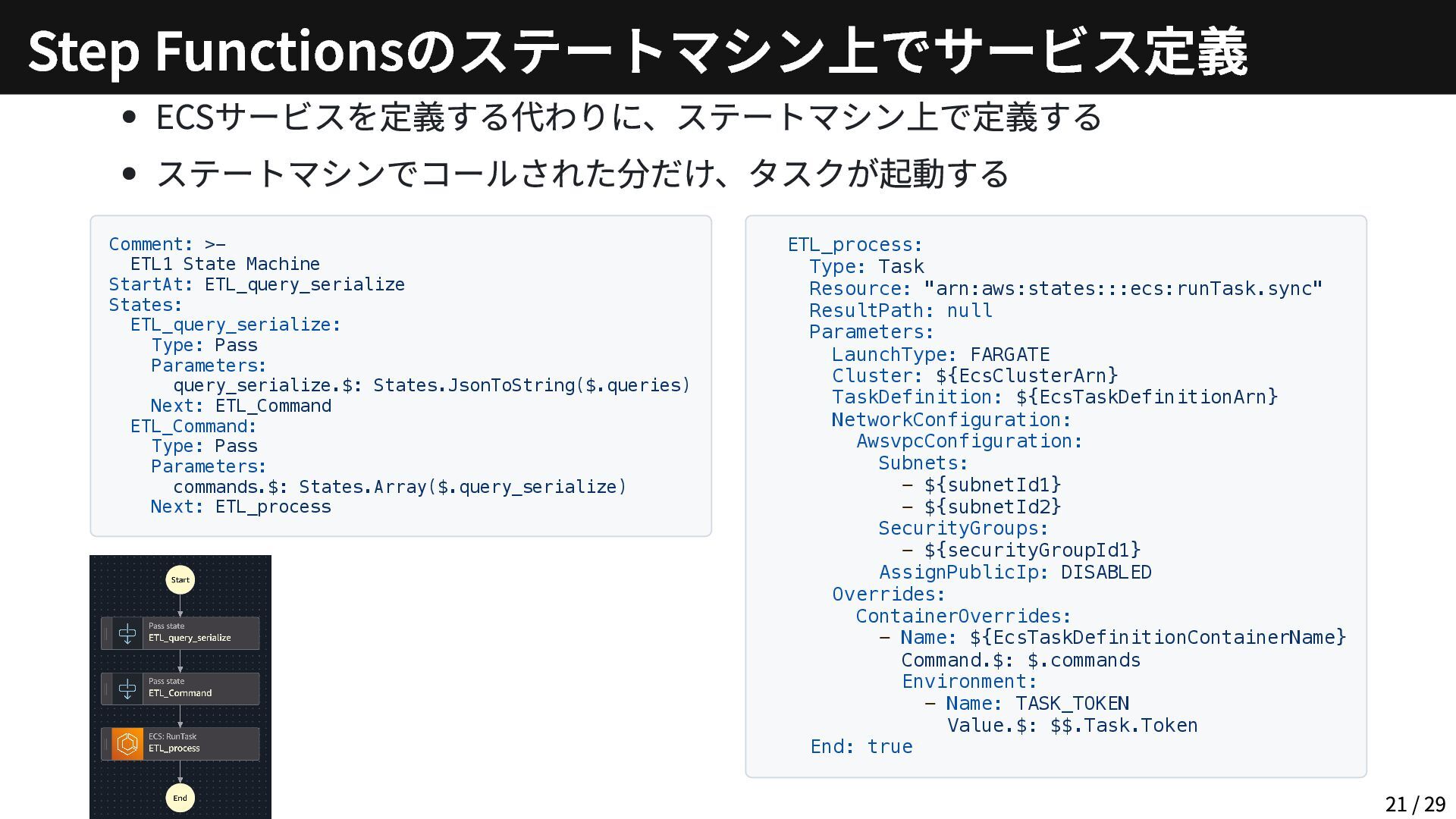
ECSサービスを定義する代わりに、ステートマシン上で定義する ステートマシンでコールされた分だけ、タスクが起動する Comment: >- ETL1 State Machine StartAt: ETL_query_serialize States:
ETL_query_serialize: Type: Pass Parameters: query_serialize.$: States.JsonToString($.queries) Next: ETL_Command ETL_Command: Type: Pass Parameters: commands.$: States.Array($.query_serialize) Next: ETL_process ETL_process: Type: Task Resource: "arn:aws:states:::ecs:runTask.sync" ResultPath: null Parameters: LaunchType: FARGATE Cluster: ${EcsClusterArn} TaskDefinition: ${EcsTaskDefinitionArn} NetworkConfiguration: AwsvpcConfiguration: Subnets: - ${subnetId1} - ${subnetId2} SecurityGroups: - ${securityGroupId1} AssignPublicIp: DISABLED Overrides: ContainerOverrides: - Name: ${EcsTaskDefinitionContainerName} Command.$: $.commands Environment: - Name: TASK_TOKEN Value.$: $$.Task.Token End: true Step Functionsのステートマシン上でサービス定義 21 / 29
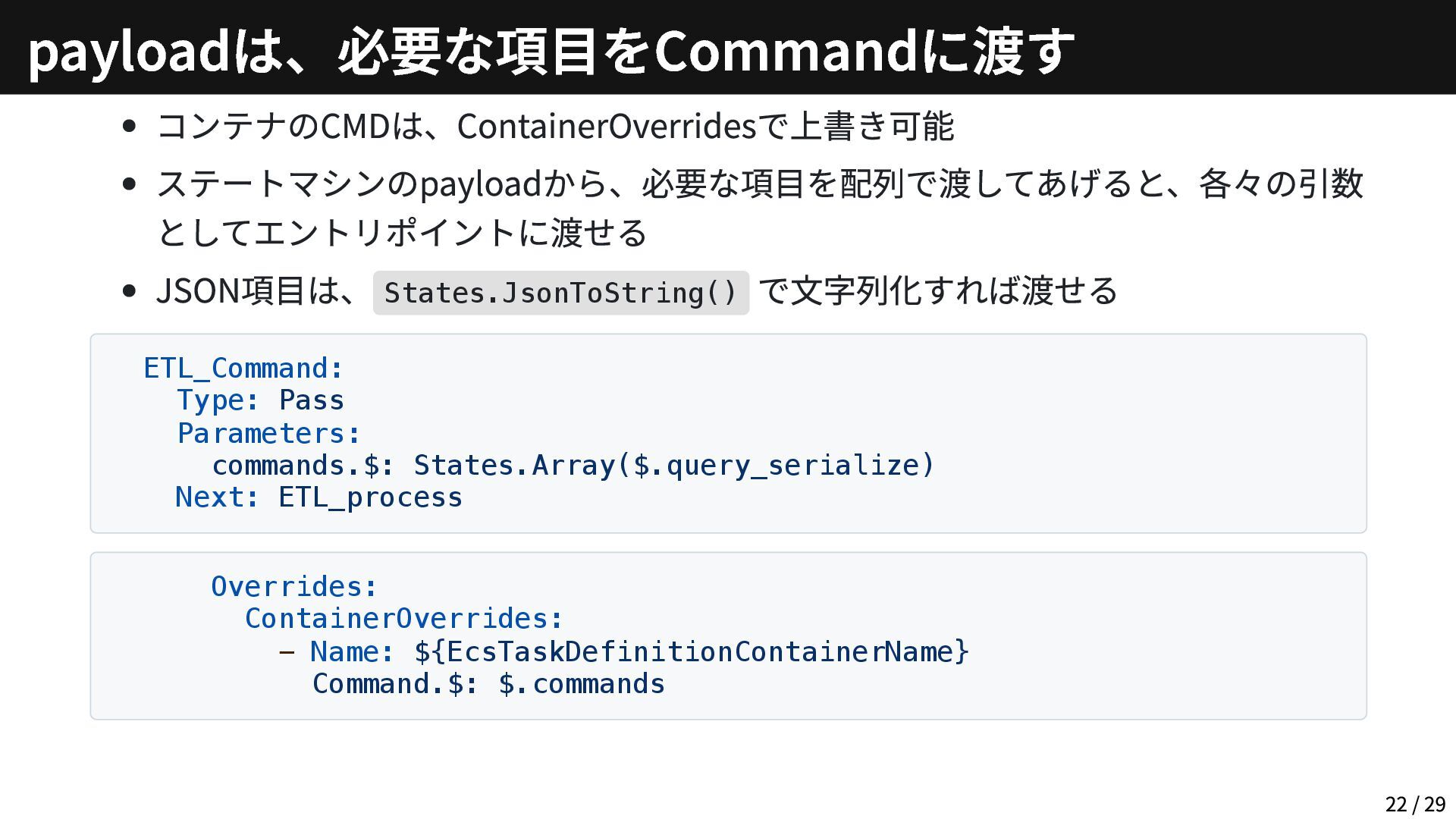
コンテナのCMDは、ContainerOverridesで上書き可能 ステートマシンのpayloadから、必要な項目を配列で渡してあげると、各々の引数 としてエントリポイントに渡せる JSON項目は、 States.JsonToString() で文字列化すれば渡せる ETL_Command: Type: Pass Parameters:
commands.$: States.Array($.query_serialize) Next: ETL_process Overrides: ContainerOverrides: - Name: ${EcsTaskDefinitionContainerName} Command.$: $.commands payloadは、必要な項目をCommandに渡す 22 / 29
今回のハンズオンではNAT Gateway使っていたので、VPCエンドポイントは不要。 プライベートなVPC環境では、AWSサービスにアクセスするためにはVPCエンドポイン トが必要になる。 Fargate起動時にECRから docker pull するために必要 com.amazonaws.ap-northeast-1.ecr.dkr ステートマシンに結果やメッセージを返したい場合は、これも追加
com.amazonaws.ap-northeast-1.states 他、Lambdaコンテナの際でも利用したサービスのVPCエンドポイントは、そのま まECS/Fargateでも利用する。 VPCエンドポイントを各種用意 23 / 29
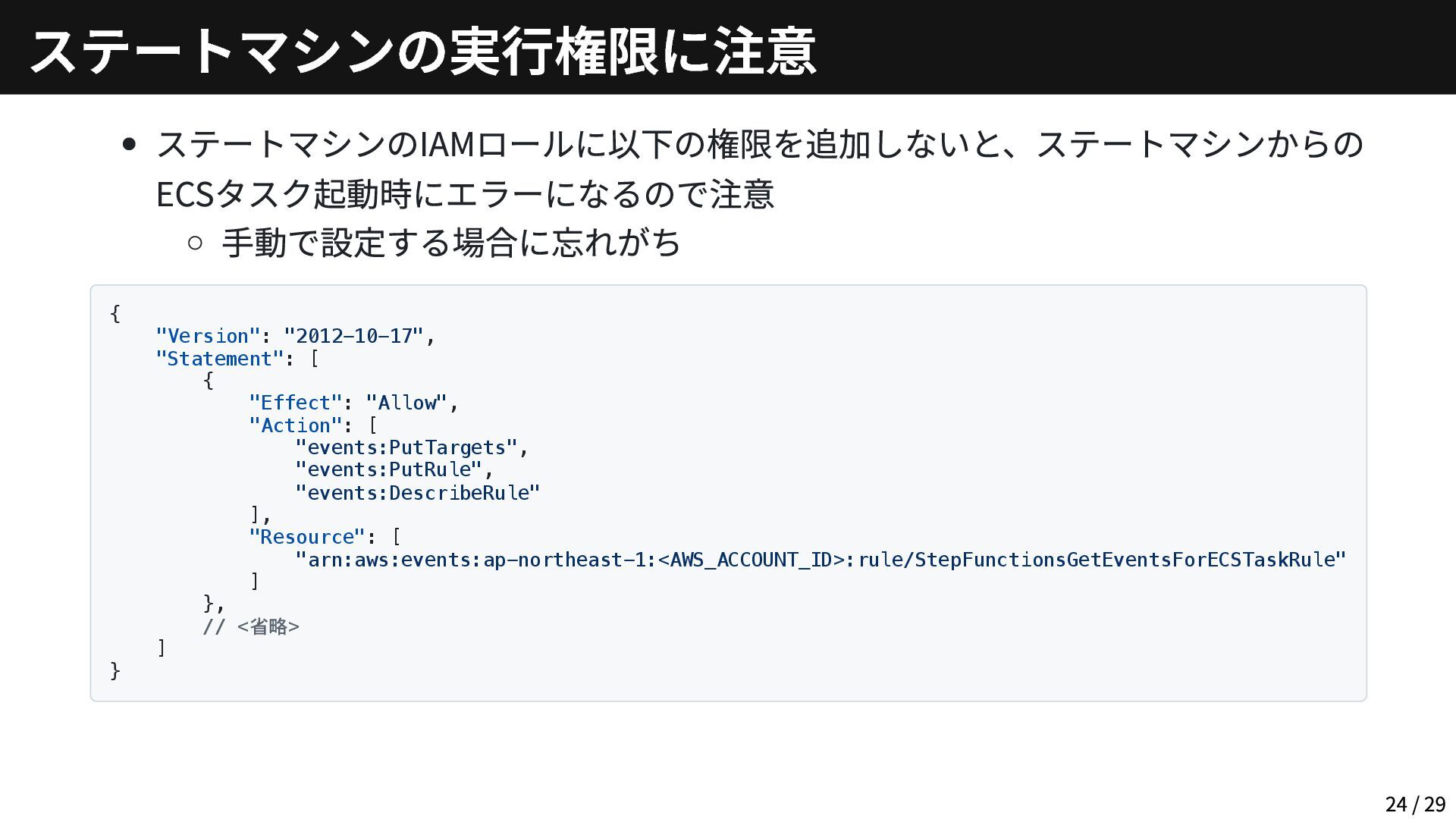
ステートマシンのIAMロールに以下の権限を追加しないと、ステートマシンからの ECSタスク起動時にエラーになるので注意 手動で設定する場合に忘れがち { "Version": "2012-10-17", "Statement": [ { "Effect":
"Allow", "Action": [ "events:PutTargets", "events:PutRule", "events:DescribeRule" ], "Resource": [ "arn:aws:events:ap-northeast-1:<AWS_ACCOUNT_ID>:rule/StepFunctionsGetEventsForECSTaskRule" ] }, // <省略> ] } ステートマシンの実行権限に注意 24 / 29
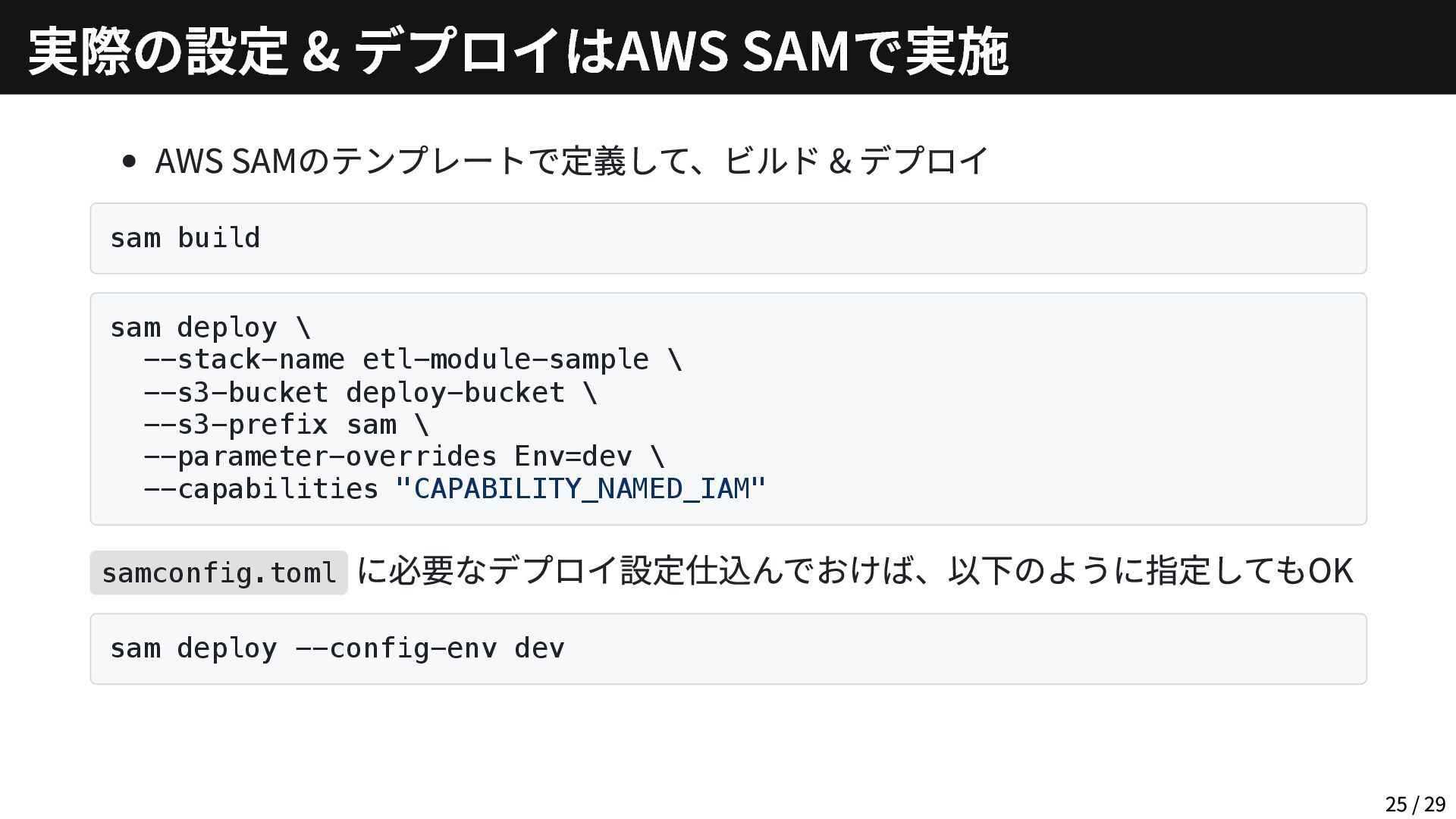
AWS SAMのテンプレートで定義して、ビルド & デプロイ sam build sam deploy \ --stack-name
etl-module-sample \ --s3-bucket deploy-bucket \ --s3-prefix sam \ --parameter-overrides Env=dev \ --capabilities "CAPABILITY_NAMED_IAM" samconfig.toml に必要なデプロイ設定仕込んでおけば、以下のように指定してもOK sam deploy --config-env dev 実際の設定 & デプロイはAWS SAMで実施 25 / 29
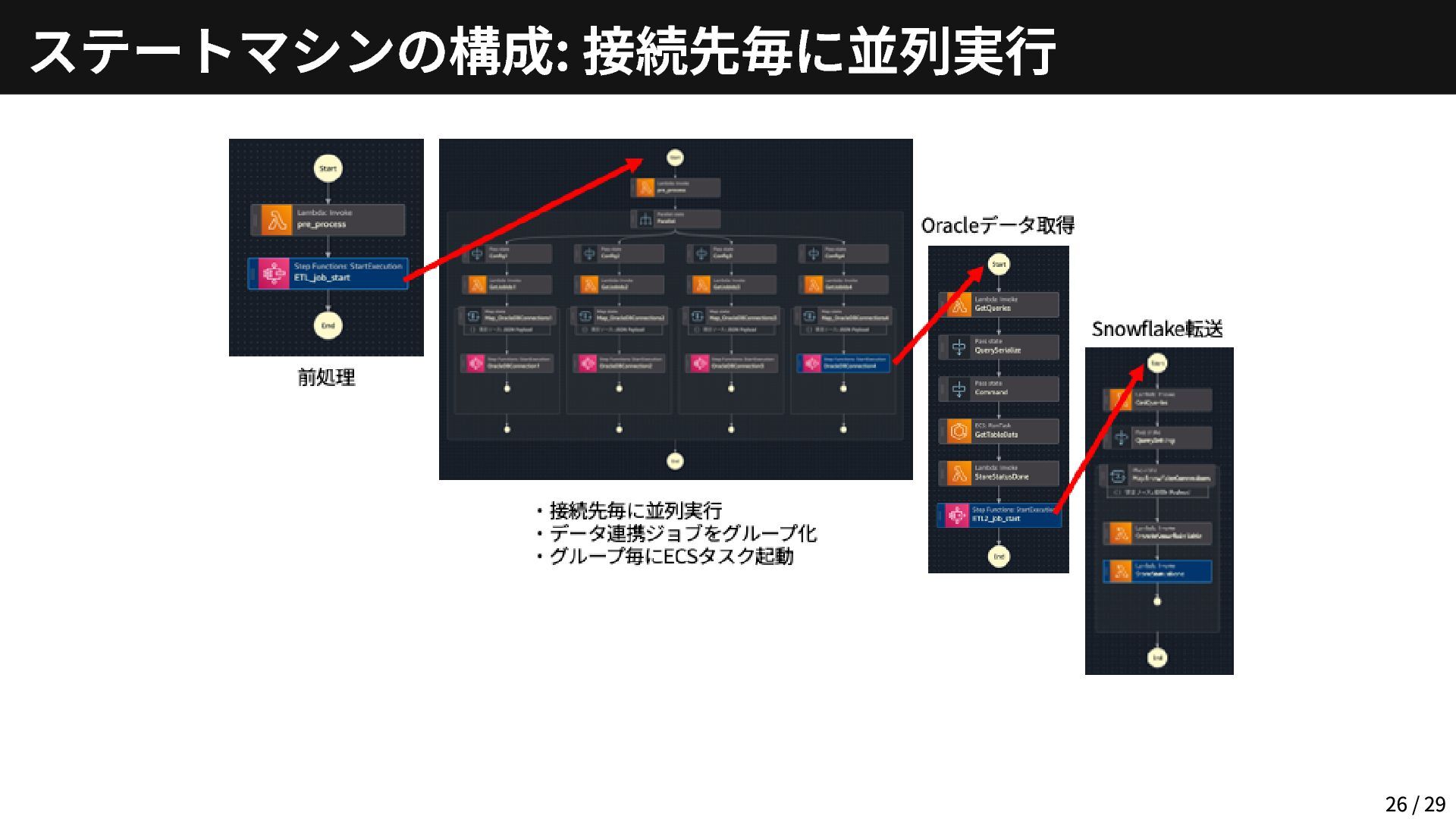
ステートマシンの構成: 接続先毎に並列実行 26 / 29
Lambda → 軽めのタスクを並列でぶん回したい場合はLambdaが良い 起動は早い タイムアウト・メモリ・ストレージ等の制約は大きい タイムアウト: 最大15分 メモリ: 最大10GB エフェメラルストレージ(
tmp ): 512MB〜10GB ECS/Fargate → 重めのタスク起動に向いている 起動するまで時間はそれなりにかかる タイムアウト・メモリ・ストレージ等の制約は少ない タイムアウト: 最大14日 メモリ: 最大120GB エフェメラルストレージ: 20GB〜200GB LambdaコンテナとECS/Fargateコンテナの違い 27 / 29
データ基盤でコンテナを活用した際のお話 Step FunctionsのステートマシンからECSタスクを実行する際の参考にどうぞ ECSサービスに相当する部分をステートマシン上で定義する 必要なリソースを適宜追加する LambdaコンテナからECS/Fargateコンテナに変更する際は、なるべく元の Lambda関数に変更を加えないように移行した エントリポイントのpythonコードで、Lambda関数に必要な引数や環境変数 を定義 まとめ
28 / 29
おわり
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}