beslutningsdygtigt flertal. Beslutningsdygtigt flertal A small number of traitors can affect the decision only if the loyal generals were almost equally divided between the two possibilities.
fra andre loyale. Udfordringer Det nytter ikke at hver general sender samtlige beskeder til alle andre uden videre, for beskederne kan jo forfalskes - og det skaber et værre rod. Derfor er hovedreglen: for hver besked fra en loyal general, der skal alle andre loyale generaler bruge samme besked.
proces har sin egen værdi, og når alle processer kommunikerer med hinanden for at afgøre hvilken værdi, der er den korrekte. Der er tale om en række private værdier, der udveksles for at finde en offentlig værdi i den givne consensus vector.
om majority-algoritmer Forekomster Valg af den forekomst af en værdi, der optræder flest af. Sandsynlighed Valg af den værdi, der forekommer mest sandsynlig. Tillid Valg af den værdi, der optræder hos flest med den største tillid. Type Valg af den værdi, der passer med den type som er anvendt.
Ingen forrædere, total tillid Hvis der ingen forrædere er, så sender generalen sin besked til alle løjtnanter, som læser beskeden og handler derefter. OM(0) Hvis en løjtnant ingen besked modtager, så falder han tilbage og angriber ikke (fallback policy).
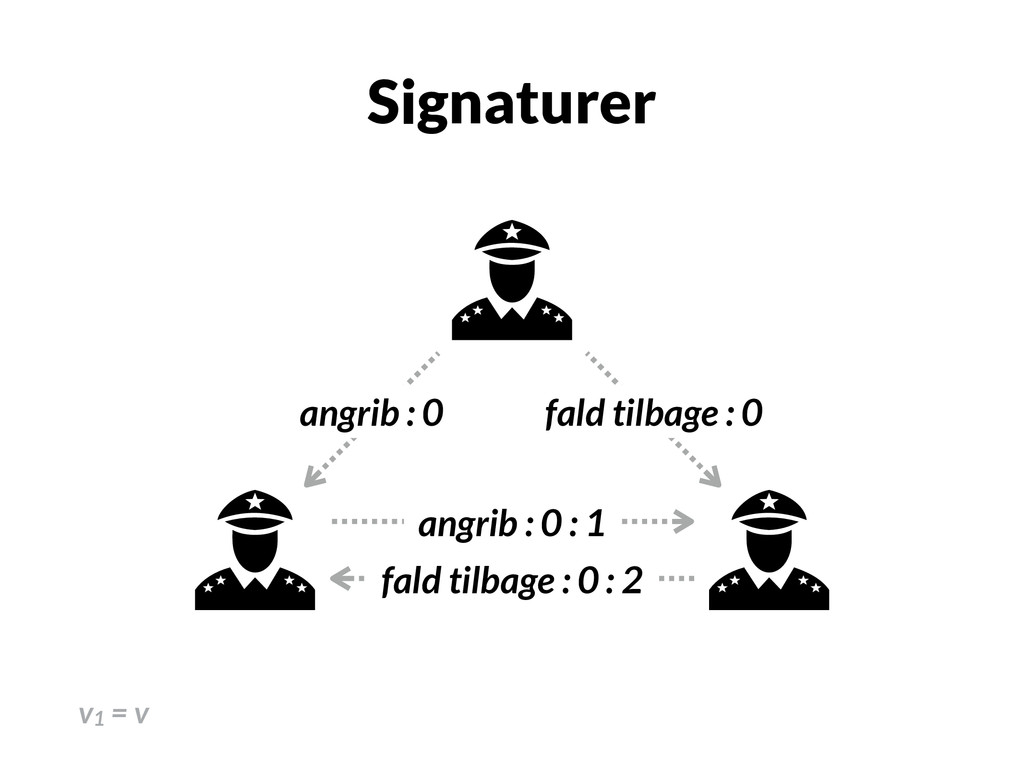
forrædere, begrænset tillid Hvis der er forrædere, så sender generalen sin besked til alle løjtnanter, som sender beskeden til hinanden. Hvis v er den oprindelige besked og v1 = v2 = v, men v3 = x, så er majority(v, v, x) = v. OM(m) hvor m > 0
alle de beskeder. Første citat af Leslie Achieving reliability in the face of arbitrary malfunctioning is a difficult problem, and its solutions seems to be inherently expensive.
det skal være godt. Andet citat af Leslie The only way to reduce the cost is to make assumptions about the type of failure that may occur. However, when extremely high reliability is required, such assumptions cannot be made, and the full expense of a Byzantine Generals solution is required.
er et Agreement Problem, der opstår når deltagere i et distribueret system har modtaget en række operationer at udføre, men ikke er enige om rækkefølgen. At vi kender til en rækkefølge er jo netop det, der gør en serie operationer transaktionelle.
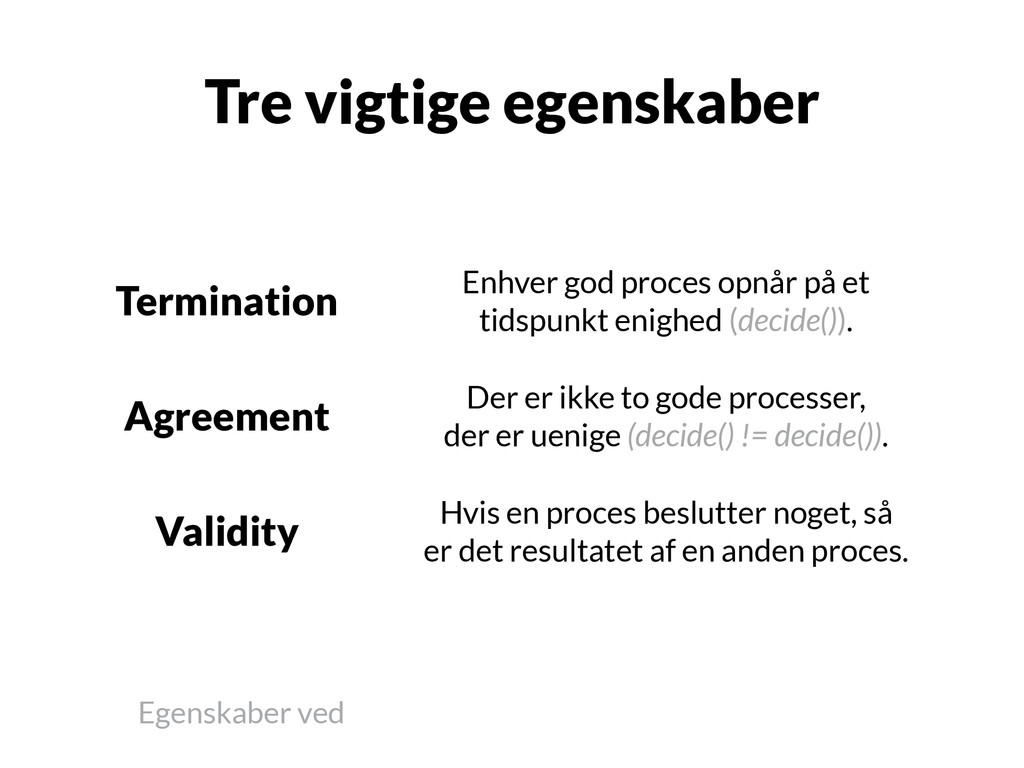
på et tidspunkt enighed (decide()). Agreement Der er ikke to gode processer, der er uenige (decide() != decide()). Validity Hvis en proces beslutter noget, så er det resultatet af en anden proces.
i vores paper. Rækkefølge 1. En proces sender en beslutning til afstemning hos alle andre processer. 2. Processen afventer enten ja, nej eller intet svar alt efter omstændighederne. 3. Hvis alle andre processer vender tilbage med et ja, så foretages et commit.
Failure detection Strong completeness er når alle dårlige processer før eller siden bliver opdaget af de gode processer. Weak accuracy er når en god proces aldrig bliver mistænkeliggjort af en anden god proces.
opnås før eller siden, så er spørgsmålet hvorvidt vi kan vente på en proces, der er gået nedenom og hjem. Hvis vi ikke kan det, så er der tale om no recovery. Hvis vi godt kan vente på at processen genskaber sig selv, så er der tale om recovery.
den, hvis det er. Først og fremmest: Paxos Paxos er en protokol til distribuering af et system, som er opfundet af - surprise! - Leslie Lamport. Paxos udstikker en række retningslinjer for hvorledes deltagere skal opføre sig for at kunne håndtere nedbrud og opnå konsensus. Paxos er temmelig langhåret læsning.
Diego Ontaro og John Ousterhout var begge studerende på Stanford University, og de var trætte af al den tunge læsning. Derfor besluttede de sig for at skrive en letvægtsudgave af Paxos, som mundede ud i Raft. Raft er en algoritme til at opnå konsensus via en log, der er replikeret.
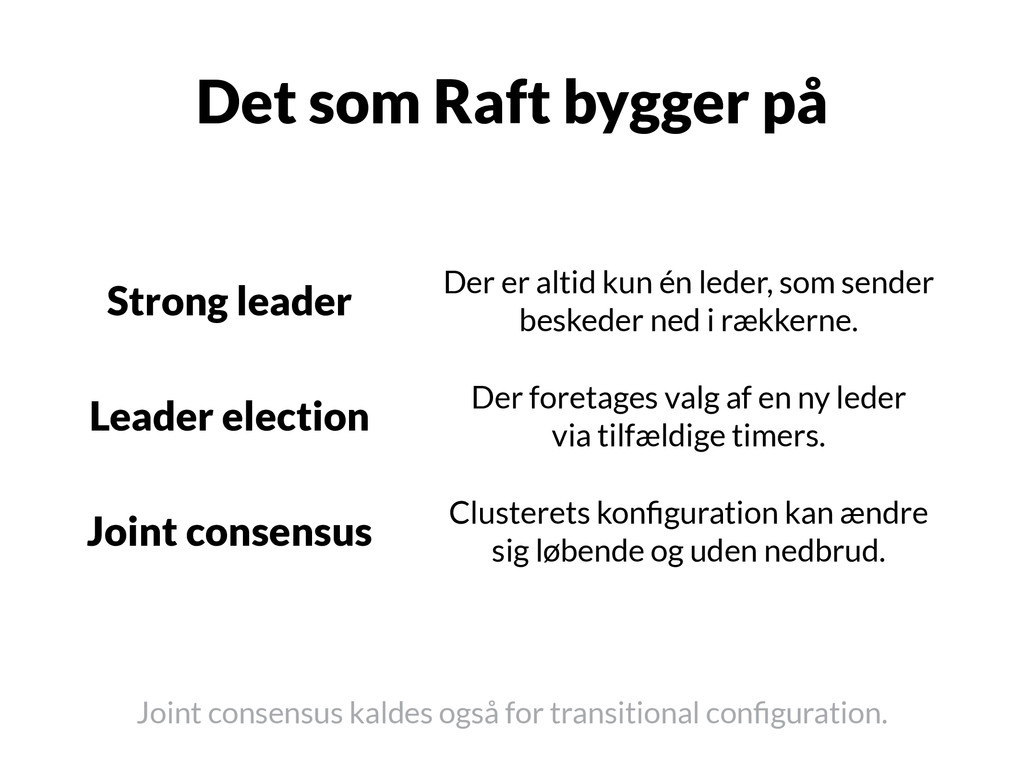
bygger på Strong leader Der er altid kun én leder, som sender beskeder ned i rækkerne. Leader election Der foretages valg af en ny leder via tilfældige timers. Joint consensus Clusterets konfiguration kan ændre sig løbende og uden nedbrud.
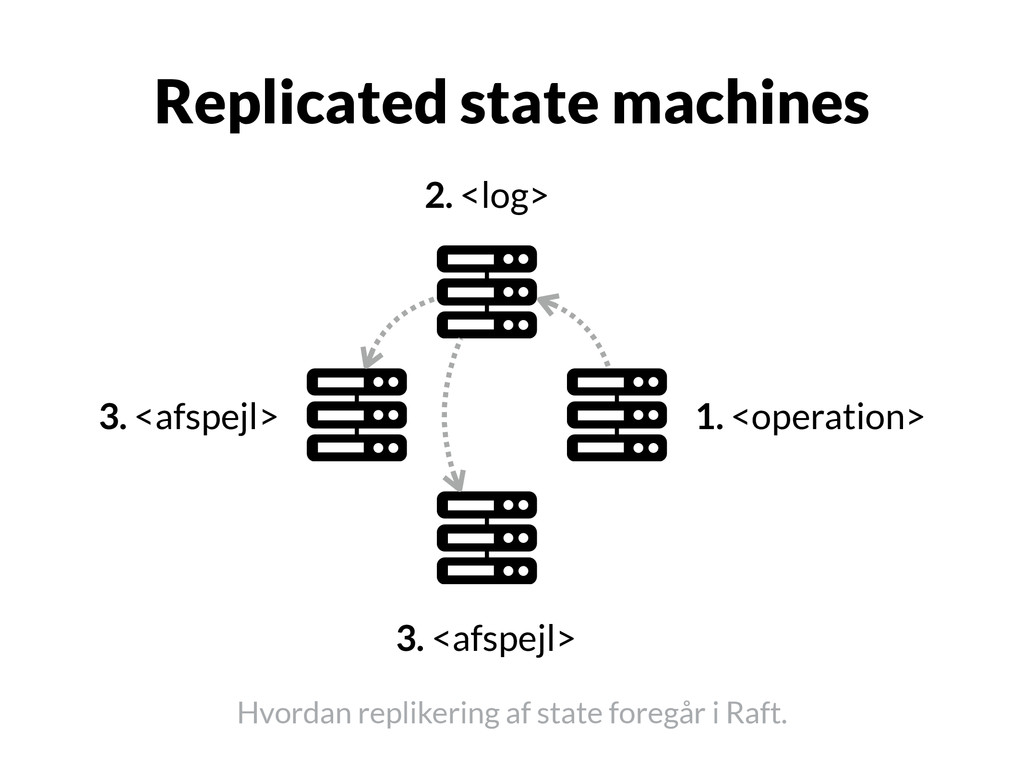
har ansvaret for den replikerede log her og nu. 2. Lederen modtager operationer til loggen, som så sendes til deltagerne. 3. Deltagerne sørger for at udføre de givne operationer og afspejle resultaterne i deres individuelle state machines.
elections. Er lederen altid den samme? Nej, der skiftes mellem lederen løbende. Forløb i Raft opdeles i terms, der følger en nummerserie. Hver term begynder med en election mellem en række candidates baseret på first-come-first- serve.
den samme? Nej, for lederen kan jo gå ned af den ene eller anden årsag. Lederen bevarer sin autoritet ved at udsende heartbeats til alle followers, så de ved at lederen stadig er der.
afsluttes den nuværende term og en ny påbegyndes med en election. Hvis en følger fejler, så forsøger lederen at sende opgaven om og om igen indtil den er løst - lidt i tråd med recovery-delen af den tidligere konsensus-algoritme.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}