search query • Inverted index: special data structure to facilitate large-scale retrieval • Evaluation: measuring the goodness of a ranking against the ground truth using binary or graded relevance 2 / 49
as a bag (multiset) of words ◦ Disregards word ordering, but keeps multiplicity • Common form of a retrieval function score(d, q) = t∈q wt,d × wt,q ◦ Note: we only consider terms in the query, t ∈ q ◦ wt,d is the term’s weight in the document ◦ wt,q is the term’s weight in the query • score(d, q) is (in principle) to be computed for every document in the collection 4 / 49
= t∈q wt,d × wt,q • Example 1: Count the number of matching query terms in the document wt,d = 1, ct,d > 0 0, otherwise ◦ where ct,d is the number of occurrences of term t in document d wt,q = ct,q ◦ where ct,q is the number of occurrences of term t in query q 5 / 49
= t∈q wt,d × wt,q • Example 2: Instead of using raw term frequencies, assign a weight that reflects the term’s importance wt,d = 1 + log ct,d, ct,d > 0 0, otherwise ◦ where ct,d is the number of occurrences of term t in document d wt,q = ct,q ◦ where ct,q is the number of occurrences of term t in query q 6 / 49
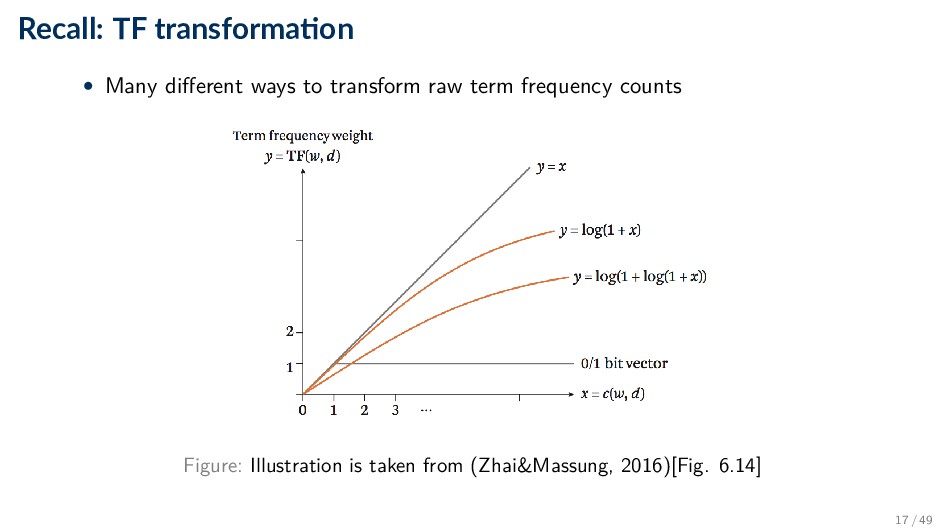
the 1960s and 70s • Still used • Provides a simple and intuitively appealing framework for implementing ◦ Term weighting ◦ Ranking ◦ Relevance feedback 8 / 49
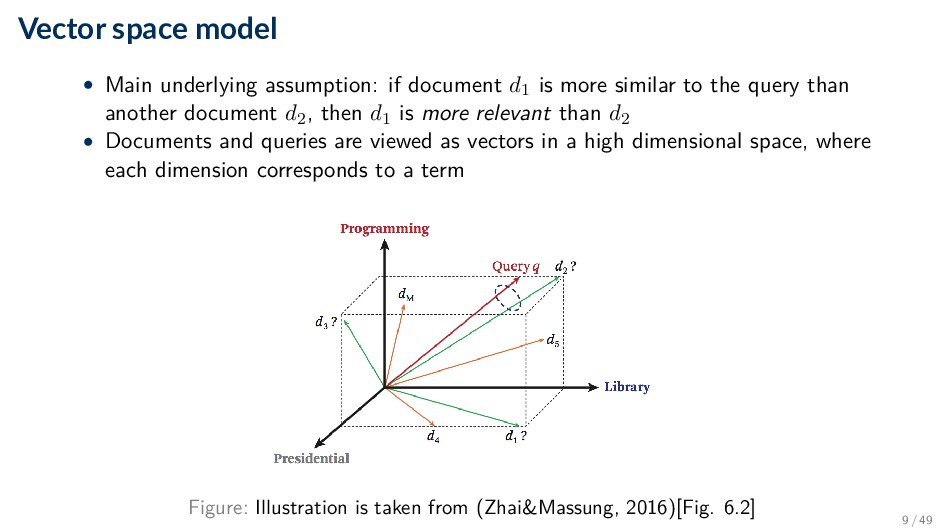
is more similar to the query than another document d2, then d1 is more relevant than d2 • Documents and queries are viewed as vectors in a high dimensional space, where each dimension corresponds to a term Figure: Illustration is taken from (Zhai&Massung, 2016)[Fig. 6.2] 9 / 49
framework that needs to be instantiated by deciding ◦ How to select terms? (i.e., vocabulary construction) ◦ How to place documents and queries in the vector space (i.e., term weighting) ◦ How to measure the similarity between two vectors (i.e., similarity measure) 10 / 49
word in the vocabulary V defines a dimension • Bit vector representation of queries and documents (i.e., only term presence/absence) • Similarity measure is the dot product sim(q, d) = q · d = t∈V wt,q × wt,d ◦ where wt,q and wt,d are either 0 or 1 11 / 49
term importance by considering term frequency (TF) and inverse document frequency (IDF) ◦ TF rewards terms that occur frequently in the document ◦ IDF rewards terms that do not occur in many documents • A possible ranking function using the TF-IDF weighting scheme: score(d, q) = t∈q∩d tft,q × tft,d × idft • Note: the above formula uses raw term frequencies and applies IDF only on one of the (document/query) vectors 13 / 49
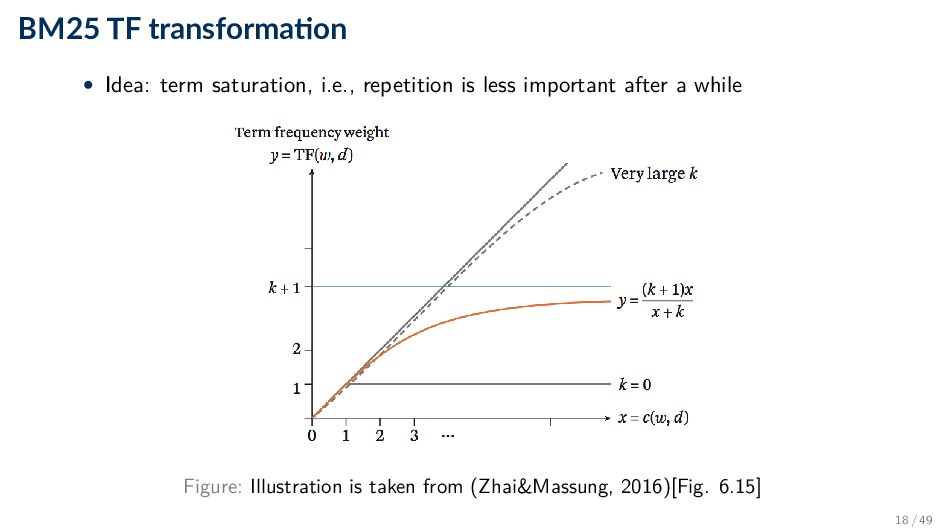
series of experiments (“Best Match”) • Popular and effective ranking algorithm • The reasoning behind BM25 is that good term weighting is based on three principles ◦ Term frequency ◦ Inverse document frequency ◦ Document length normalization 15 / 49
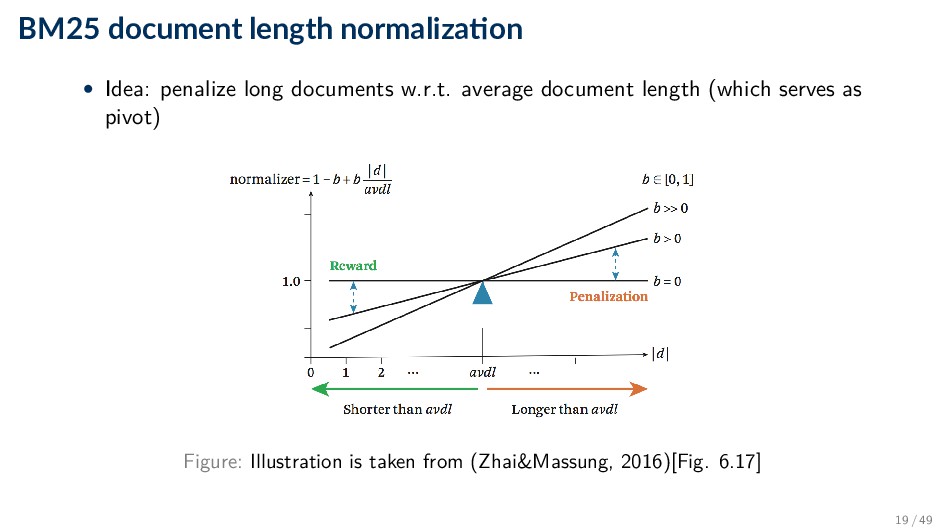
◦ 0 corresponds to a binary model ◦ large values correspond to using raw term frequencies ◦ typical values are between 1.2 and 2.0; a common default value is 1.2 • b: document length normalization ◦ 0: no normalization at all ◦ 1: full length normalization ◦ typical value: 0.75 20 / 49
processes for generating text • Wide range of usage across different applications ◦ Speech recognition • “I ate a cherry” is a more likely sentence than “Eye eight uh Jerry” ◦ OCR and handwriting recognition • More probable sentences are more likely correct readings ◦ Machine translation • More likely sentences are probably better translations 22 / 49
a multinomial probability distribution over terms • Estimate the probability that the query was “generated” by the given document ◦ How likely is the search query given the language model of the document? 23 / 49
their likelihood of being relevant given a query q: P(d|q) = P(q|d)P(d) P(q) ∝ P(q|d)P(d) • Query likelihood: Probability that query q was “produced” by document d P(q|d) = t∈q P(t|θd)ct,q • Document prior, P(d): Probability of the document being relevant to any query 24 / 49
document language model ◦ Multinomial probability distribution over the vocabulary of terms • ct,q is the raw frequency of term t in the query • Smoothing: ensuring that P(t|θd) is > 0 for all terms 25 / 49
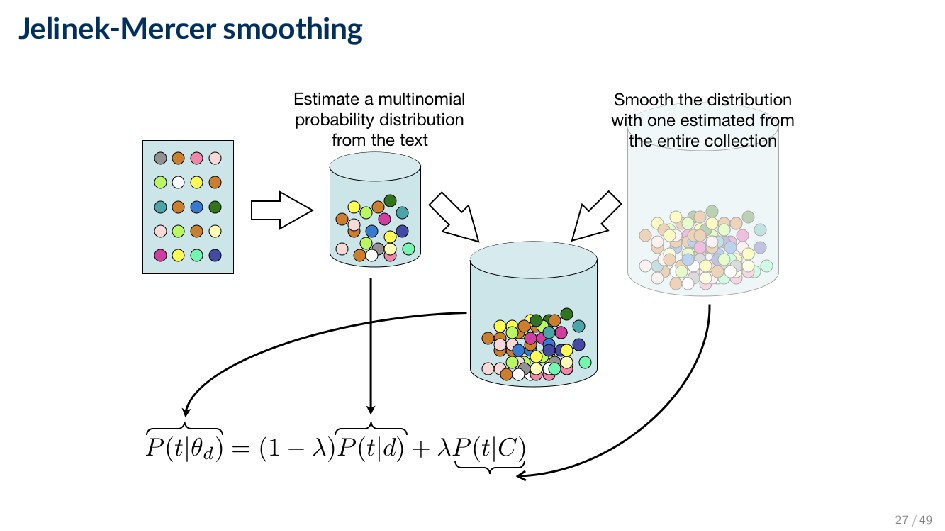
and a collection (background) language model P(t|θd) = (1 − λ)P(t|d) + λP(t|C) ◦ λ ∈ [0, 1] is the smoothing parameter ◦ Empirical document model (maximum likelihood estimate): P(t|d) = ct,d |d| ◦ Collection (background) language model (maximum likelihood estimate): P(t|C) = d ct,d d |d | 26 / 49
length P(t|θd) = ct,d + µP(t|C) |d| + µ ◦ µ is the smoothing parameter (typically ranges from 10 to 10000) • Notice that Dirichlet smoothing may also be viewed as a linear interpolation in the style of Jelinek-Mercer smoothing, by setting λ = µ |d| + µ (1 − λ) = |d| |d| + µ 28 / 49
P(sea|θd) × P(submarine|θd) = (1 − λ)P(sea|d) + λP(sea|C) × (1 − λ)P(submarine|d) + λP(submarine|C) • where ◦ P(sea|d) is the relative frequency of term “sea” in document d ◦ P(sea|C) is the relative frequency of term “sea” in the entire collection ◦ ... 29 / 49
probabilities, it is better to perform computations in the log space P(q|d) = t∈q P(t|θd)ct,q ⇓ log P(q|d) = t∈q ct,q × log P(t|θd) • Notice that it is a particular instantiation of our general scoring function score(d, q) = t∈q wt,d × wt,q by setting ◦ wt,d = log P(t|θd ) ◦ wt,q = ct,q 30 / 49
IDF computation) (int) • Document length for each document (dictionary) • Average document length in the collection (int) • (optionally pre-computed) IDF score for each term (dictionary) 35 / 49
Sum TF for each term (dictionary) • Sum of all document lengths in the collection (int) • (optionally pre-computed) Collection term probability P(t|C) for each term (dictionary) 36 / 49
Retrieval and Databases Bressanone, Italy 4 - 8 February 2013 The aim of the PROMISE Winter School 2013 on "Bridging between Information Retrieval and Databases" is to give participants a grounding in the core topics that constitute the multidisciplinary area of information access and retrieval to unstructured, semistructured, and structured information. The school is a week-long event consisting of guest lectures from invited speakers who are recognized experts in the field. The school is intended for PhD students, Masters students or senior researchers such as post-doctoral researchers form the fields of databases, information retrieval, and related fields. [...] 40 / 49
School 2013 d2: meta PROMISE, school, PhD, IR, DB, [...] PROMISE Winter School 2013, [...] d3: headings PROMISE Winter School 2013 Bridging between Information Retrieval and Databases Bressanone, Italy 4-8 February 2013 d4: body The aim of the PROMISE Winter School 2013 on "Bridging between Information Retrieval and Databases" is to give participants a grounding in the core topics that constitute the multidisciplinary area of information access and retrieval to unstructured,semistructured, and structured information. The school is a week-long event consisting of guest lectures from invited speakers who are recognized experts in the field. The school is intended for PhD students, Masters students or senior researchers such as postdoctoral researchers form the fields of databases, information retrieval, and related fields. [...] 42 / 49
soft normalization and term frequencies need to be adjusted • Original BM25 retrieval function: score(d, q) = t∈q ct,d × (1 + k1) ct,d + k1 × B × idft • where B is is the soft normalization: B = (1 − b + b |d| avgdl ) 44 / 49
˜ ct,d • BM25F retrieval function: score(d, q) = t∈q ˜ ct,d k1 + ˜ ct,d × idft • Pseudo term frequency calculation ˜ ct,d = i wi × ct,di Bi • where ◦ i corresponds to the field index ◦ wi is the field weight (such that i wi = 1) ◦ Bi is soft normalization for field i, where bi becomes a field-specific parameter Bi = (1 − bi + bi |di | avgdli ) 45 / 49
language model for each field, then take a linear combination of them P(t|θd) = i wiP(t|θdi ) • where ◦ i corresponds to the field index ◦ wi is the field weight (such that i wi = 1) ◦ P(t|θdi ) is the field language model 46 / 49
models, but term statistics are restricted to the given field i • Using Jelinek-Mercer smoothing: P(t|θdi ) = (1 − λi)P(t|di) + λiP(t|Ci) • where both the empirical field model (P(t|di)) and the collection field model (P(t|Ci)) are maximum likelihood estimates: P(t|di) = ct,di |di| P(t|di) = d ct,d i d |di | 47 / 49
that must be tuned to get the best performance for specific types of data and queries • For experiments ◦ Use training and test data sets ◦ If less data available, use cross-validation by partitioning the data into k subsets • Many techniques exist to find optimal parameter values given training data ◦ Standard problem in machine learning • For standard retrieval models, involving few parameters, grid search is feasible ◦ Perform a sweep over the possible values of each parameter, e.g., from 0 to 1 in steps of 0.1 48 / 49
![Retrieval Models [DAT640] Informa on Retrieval and Text Mining Krisz](https://files.speakerdeck.com/presentations/0a1b66e28799433a819aac063dd4f573/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}