objects to one of several predefined categories ◦ One of the fundamental problems in machine learning, where it is performed the basis of a training dataset (instances whose category membership is known) • In text classification (or text categorization) the objects are text documents • Binary classification (two classes, 0/1 or -/+) ◦ E.g., deciding whether an email is spam or not • Multiclass classification (n classes) ◦ E.g., Categorizing news stories into topics (finance, weather, politics, sports, etc.) 2 / 18
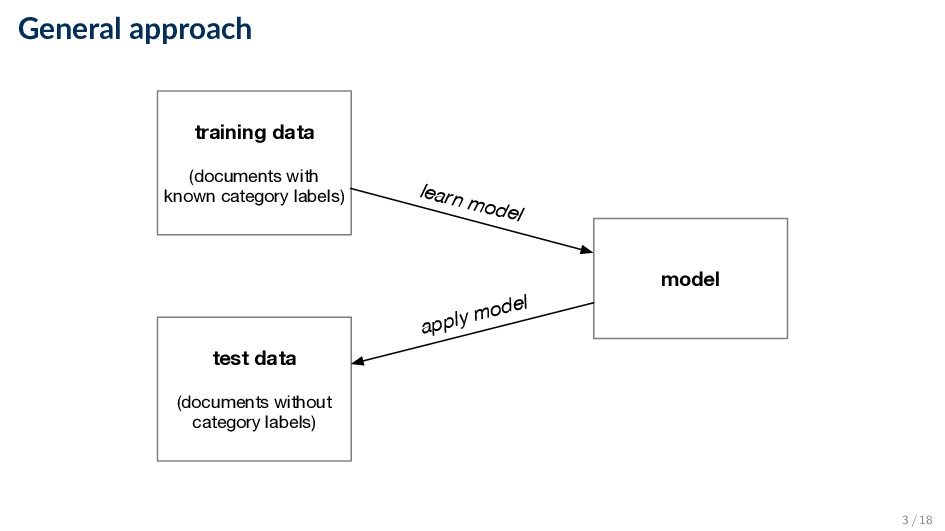
is a set of documents with corresponding labels y, from a set Y of possible labels, the task is to learn a function f(·) that can predict the class y = f(x) for an unseen document x. 4 / 18
(bag-of-words) ◦ Words will be referred to as terms • Values can be, e.g., binary (term presence/absence) or integers (term counts) • Documents are represented by their term vector • Document-term matrix is huge, but most of the values are zeros; stored as a sparse matrix t1 t2 t3 . . . tm d1 1 0 2 0 d2 0 1 0 2 d3 0 0 1 0 . . . dn 0 1 0 0 Document-term matrix 7 / 18
in a document should get high weights ◦ E.g., The more often a document contains the term “dog,” the more likely that the document is “about” dogs • Intuition #2: terms that appear in many documents should get low weights ◦ E.g., stopwords, like “a,” “the,” “this,” etc. • How do we capture this mathematically? ◦ Term frequency ◦ Inverse document frequency 11 / 18
count of a term in a document • Term frequency tft,d reflects the importance of a term (t) in a document (d) • Variants ◦ Binary: tft,d ∈ {0, 1} ◦ Raw count: tft,d = ct,d ◦ L1-normalized: tft,d = ct,d |d| • where |d| is the length of the document, i.e., the sum of all term counts in d: |d| = t∈d ct,d ◦ L2-normalized: tft,d = ct,d ||d|| • where ||d|| = t∈d (ct,d )2 ◦ Log-normalized: tft,d = 1 + log ct,d ◦ ... • By default, when we refer to TF we will mean the L1-normalized version 12 / 18
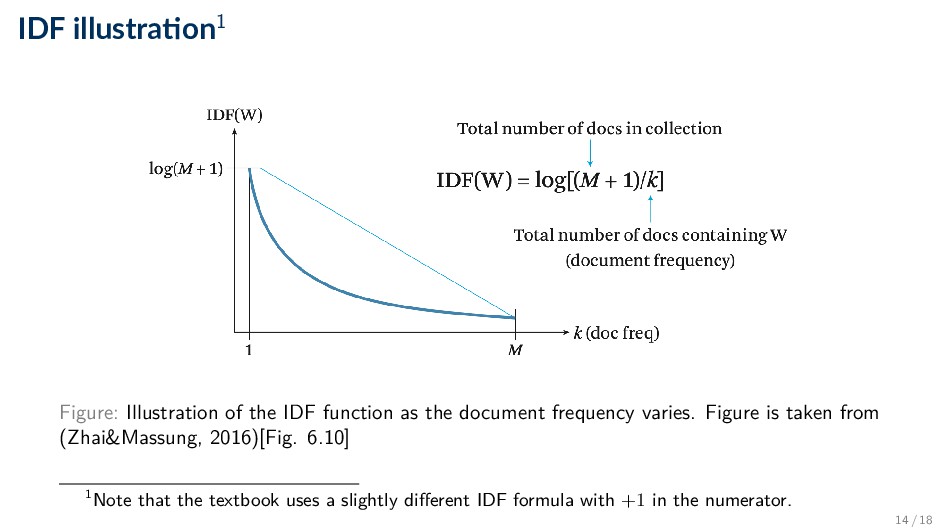
the importance of a term (t) in a collection of documents ◦ The more documents that a term occurs in, the less discriminating the term is between documents, consequently, the less “useful” idft = log N nt ◦ where N is the total number of documents in the collection and nt is the number of documents that contain t ◦ Log is used to “dampen” the effect of IDF 13 / 18
the document frequency varies. Figure is taken from (Zhai&Massung, 2016)[Fig. 6.10] 1Note that the textbook uses a slightly different IDF formula with +1 in the numerator. 14 / 18
by multiplying them: tfidft,d = tft,d · idft ◦ Term frequency weight measures importance in document ◦ Inverse document frequency measures importance in collection 15 / 18
![Text Classifica on [DAT640] Informa on Retrieval and Text Mining](https://files.speakerdeck.com/presentations/2a9ef886f0ca44deabbabf3138cccc19/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}