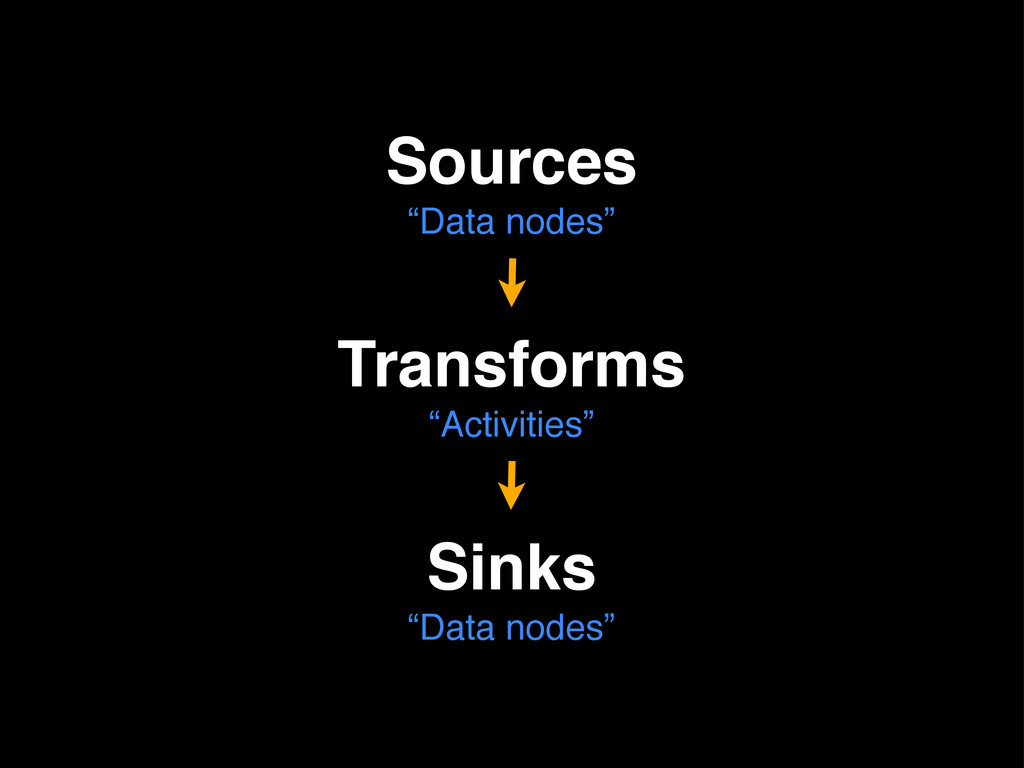
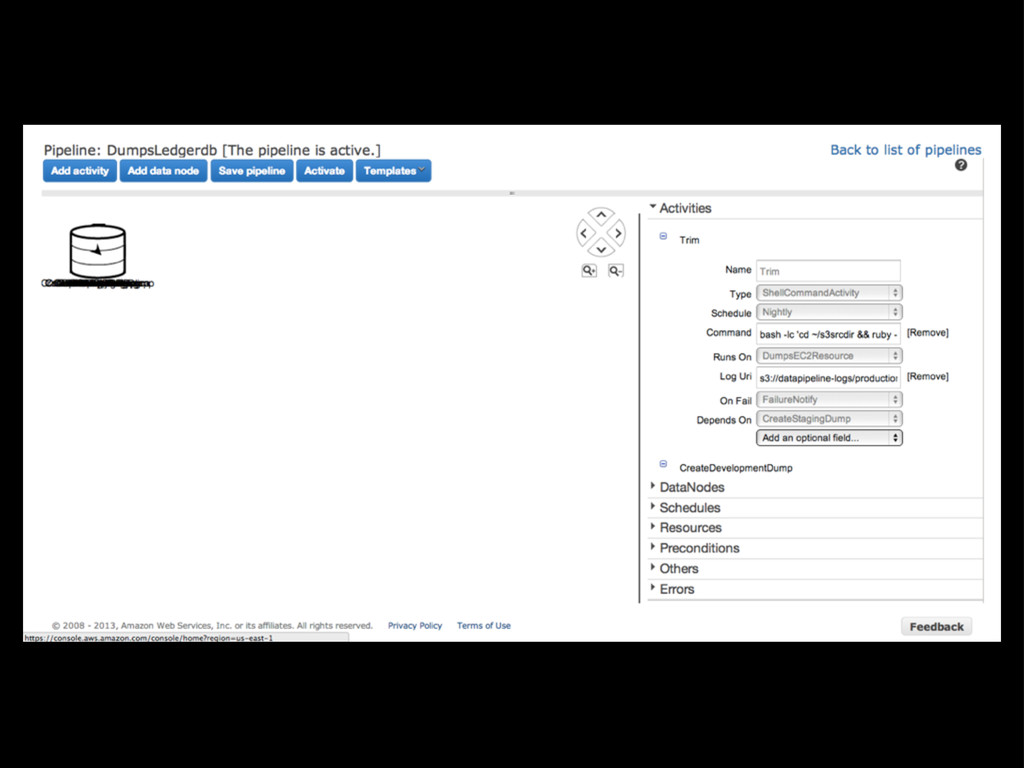
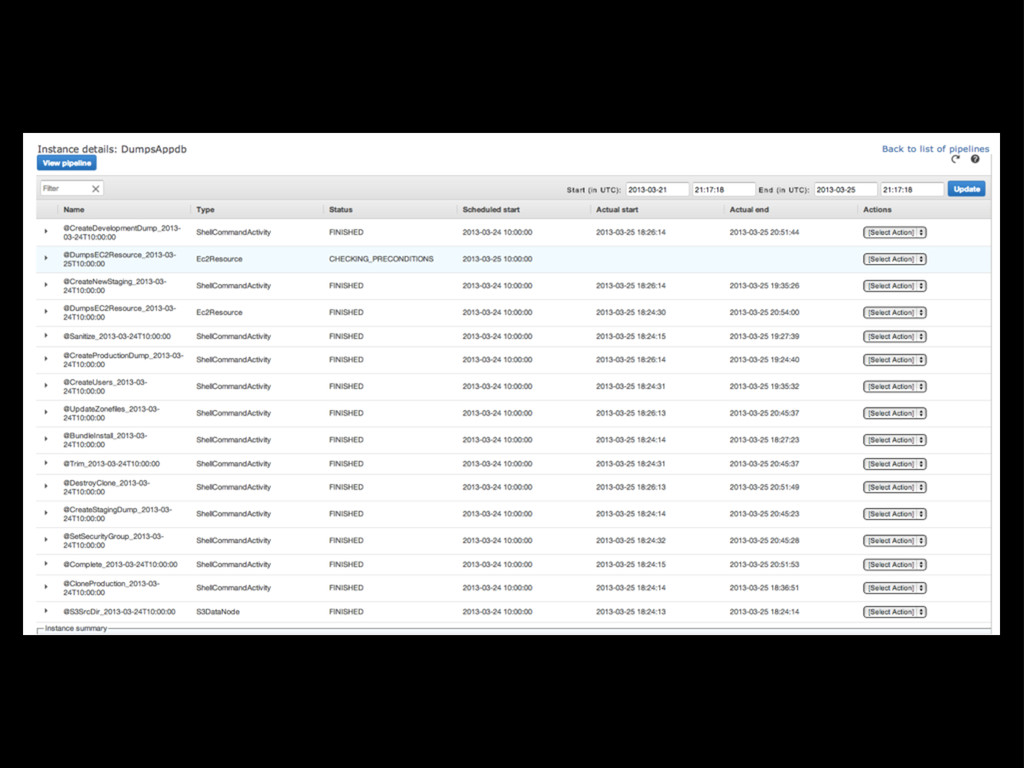
and/or failure Deployment? Pipelines definitions are declarative - Amazon handles the rest Hosting? Instances are spun up as needed and destroyed when done
at writing an testing Ruby code, so we’d like to use Ruby for the mapper and reducer We don’t want to have to administer a Hadoop cluster, or find a way to schedule and monitor an EMR flow
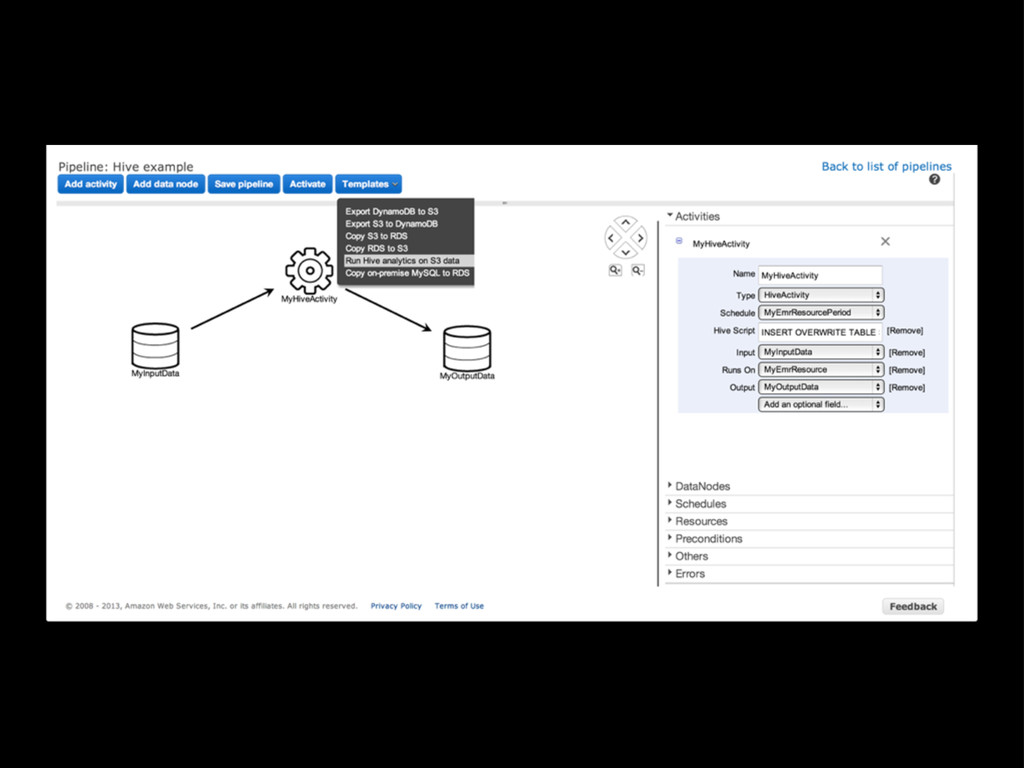
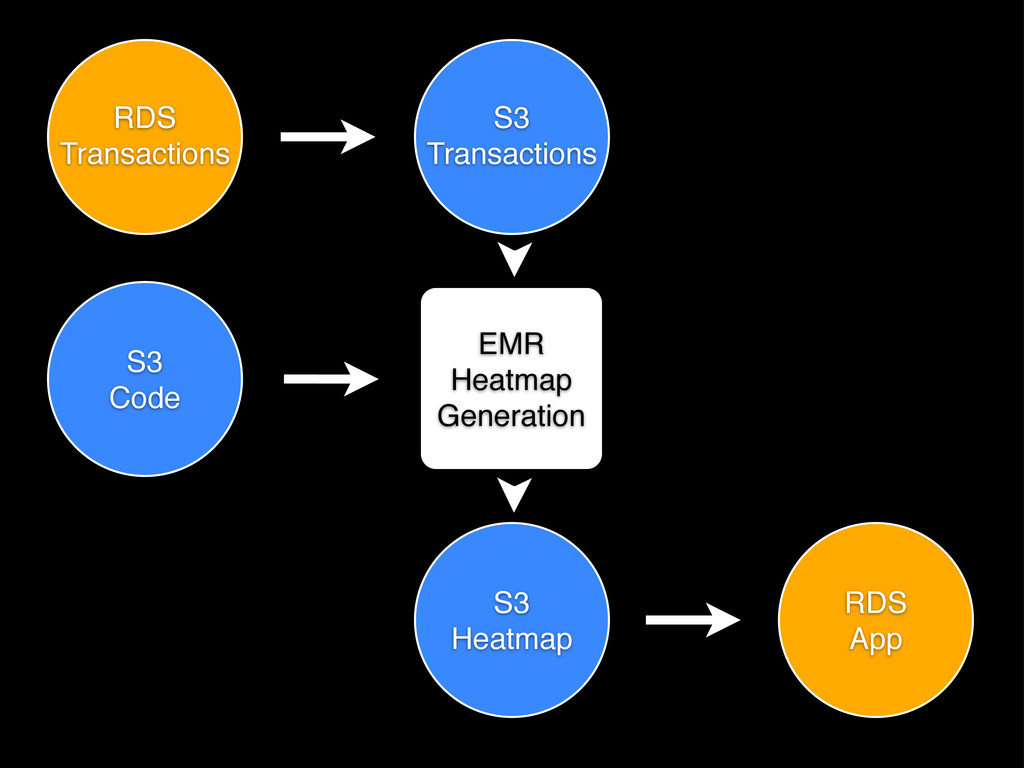
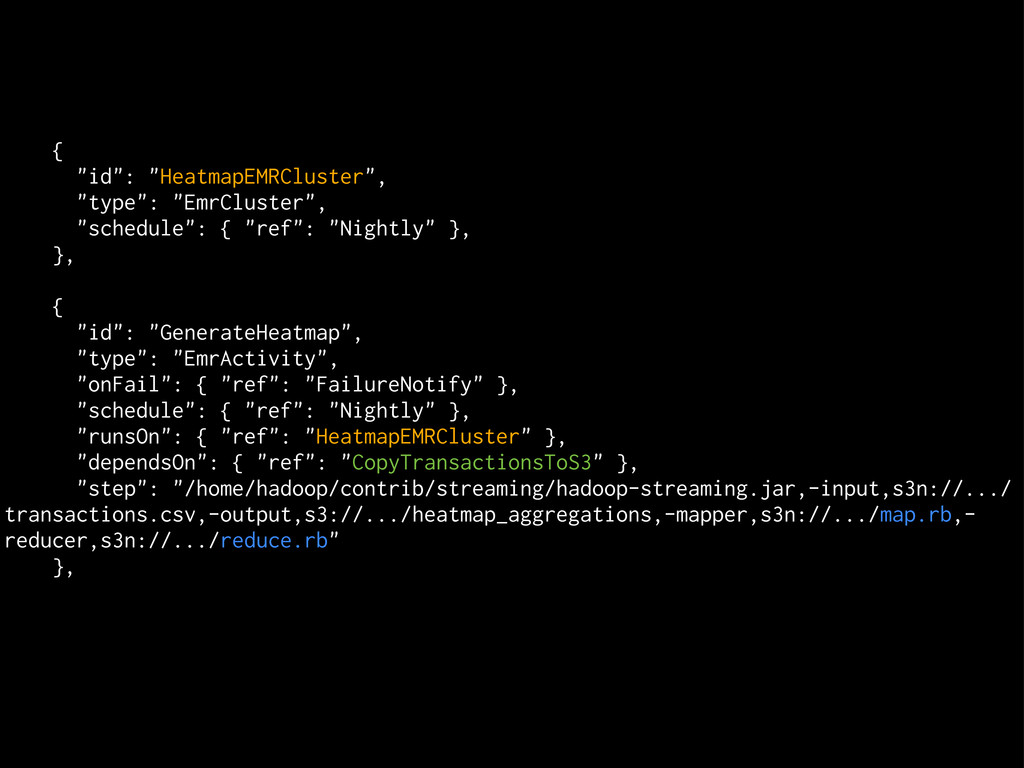
(or fails) Scalable: we can adjust the EMR cluster and scheduling as needed Deployable: devs can work in Ruby, deploy with our usual machinery Simple: pipeline definition is just JSON (albeit 150 lines)
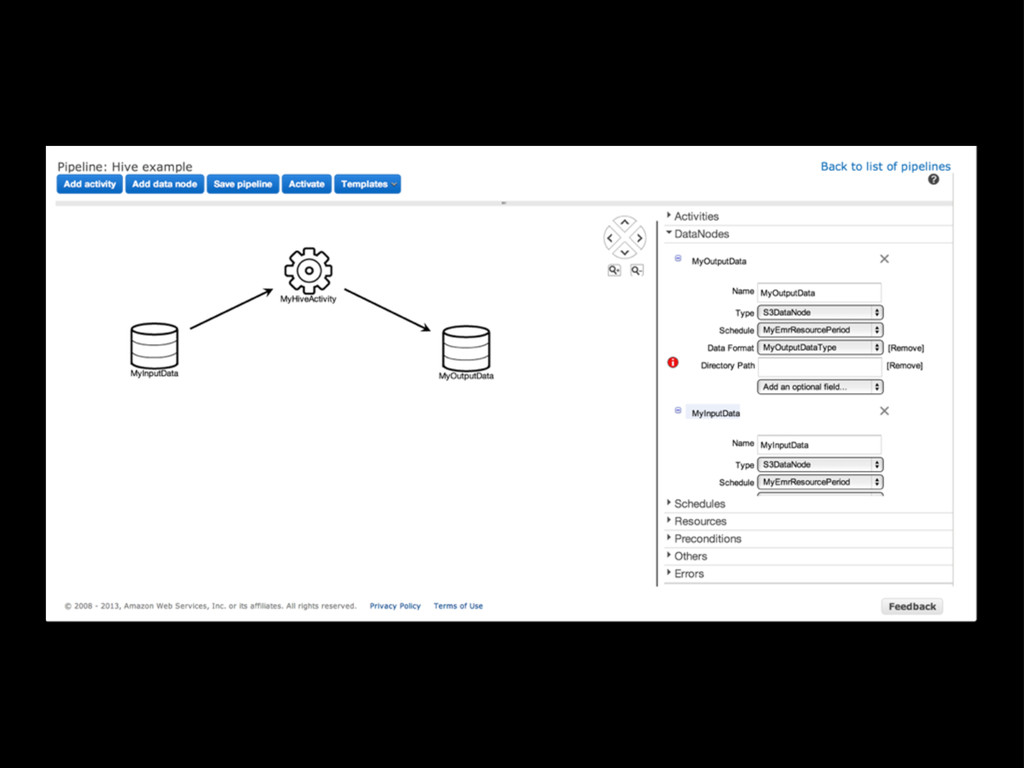
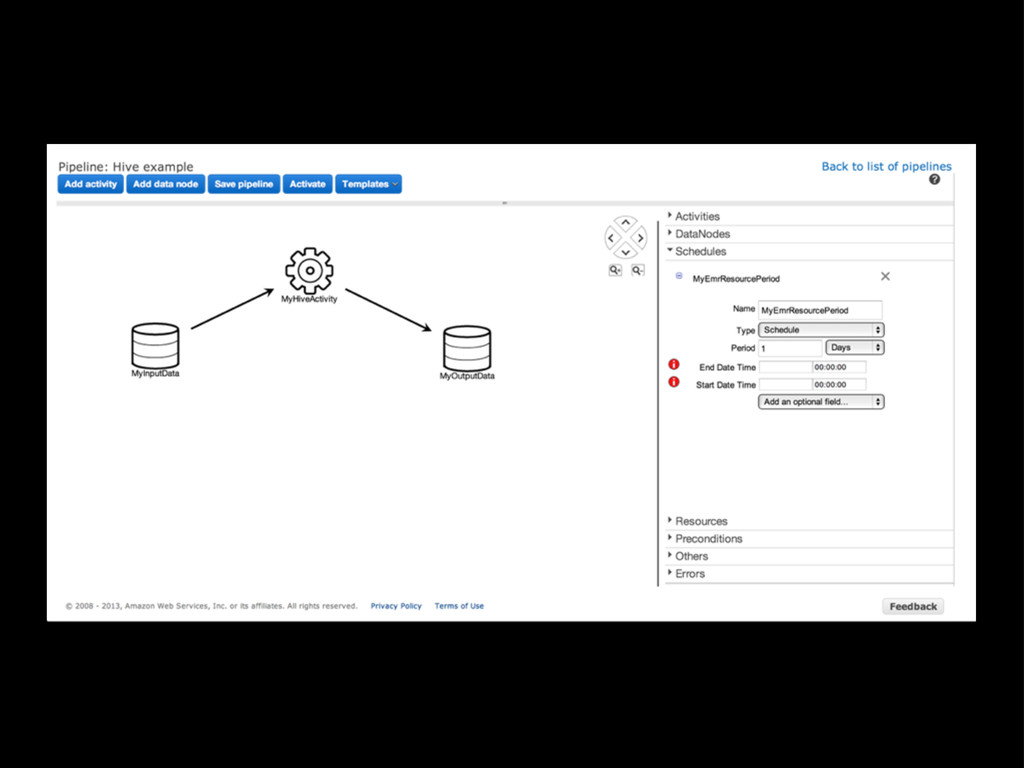
Concurrency: manipulating data in the “scratch” DB can happen while the new staging DB is being set up Automatic S3 staging to instance local FS: write backups, etc to local directories, and they’ll be moved to S3 automatically
![AWS Data Pipeline http://aws.amazon.com/datapipeline/ Keith Barrette [email protected]](https://files.speakerdeck.com/presentations/0c133410787801301f4312313b0319d6/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}