Kubernetes is complex. This is further compounded by the complexity of microservice architecture and continuous delivery.
In this presentation, Kevin describes USE, RED, and the Golden Signals from the Google SRE handbook and how they relate to applications running in Kubernetes. By the end of this presentation, you will understand not only how your services are performing, but how your Kubernetes environment relates to every transaction and Golden Signal that occurs in your application.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
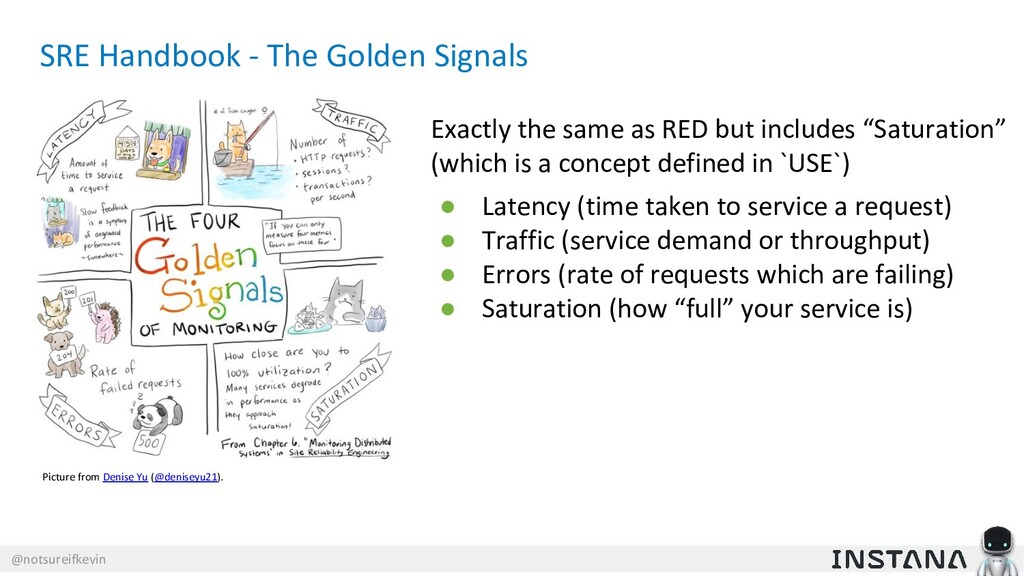
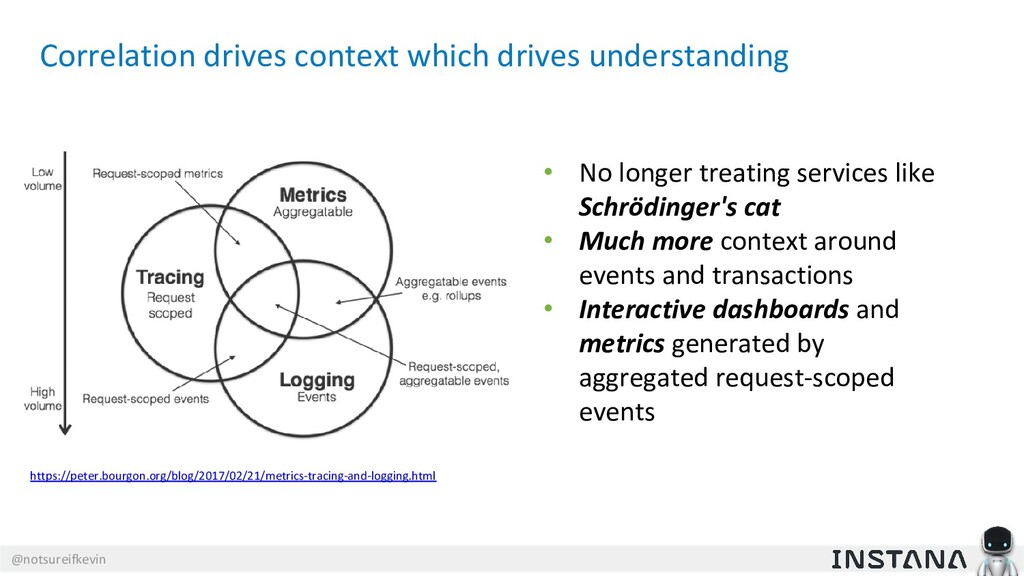{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}