1. You can’t tell where a program is going to spend its time. Bottlenecks occur in surprising places, so don’t try to second guess and put in a speed hack until you’ve proven that’s where the bottleneck is. Rule 2. Measure. Don’t tune for speed until you’ve measured, and even then don’t unless one part of the code overwhelms the rest. ルール1:プログラムがどこで時間を消費しているかを事前に予測することはできませ ん。ボトルネックは予想外の場所に発生するため、推測で高速化を試みるのではな く、まず実際に測定してボトルネックの発生箇所を特定することが重要です。 ルール2:測定を行いましょう。速度チューニングは、実際に測定を行った後でも必要 最小限に留めてください。特に、コードの一部が全体の処理時間の大部分を占めてい る場合にのみ実施すべきです。
sliceを宣言するだけ for i := 0; i < n; i++ { s = append(s, i) } } func AppendFromPreallocated(n int) { s := make([]int, 0, n) // capacityをn個分確保したslice for i := 0; i < n; i++ { s = append(s, i) } }
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
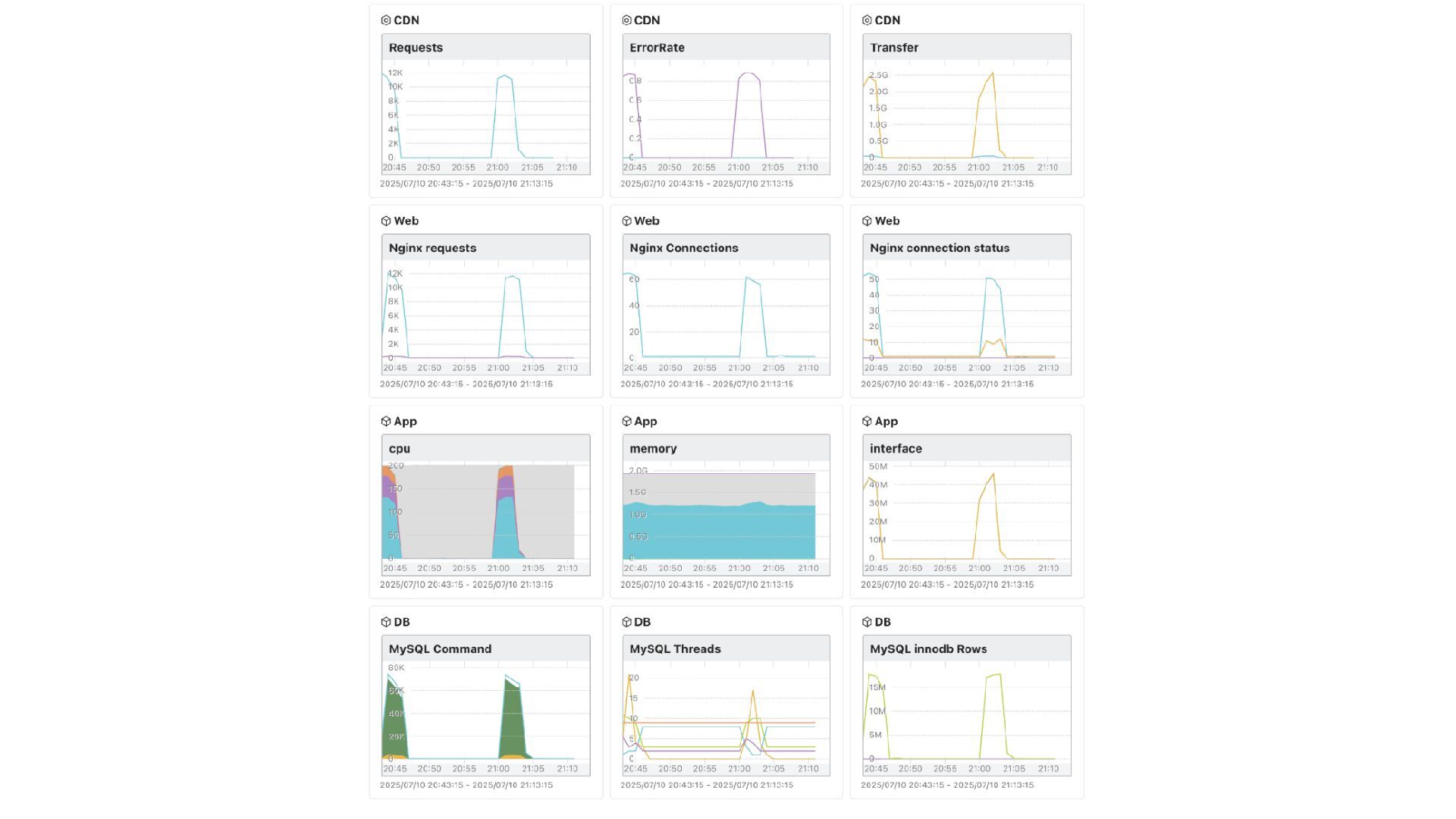{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
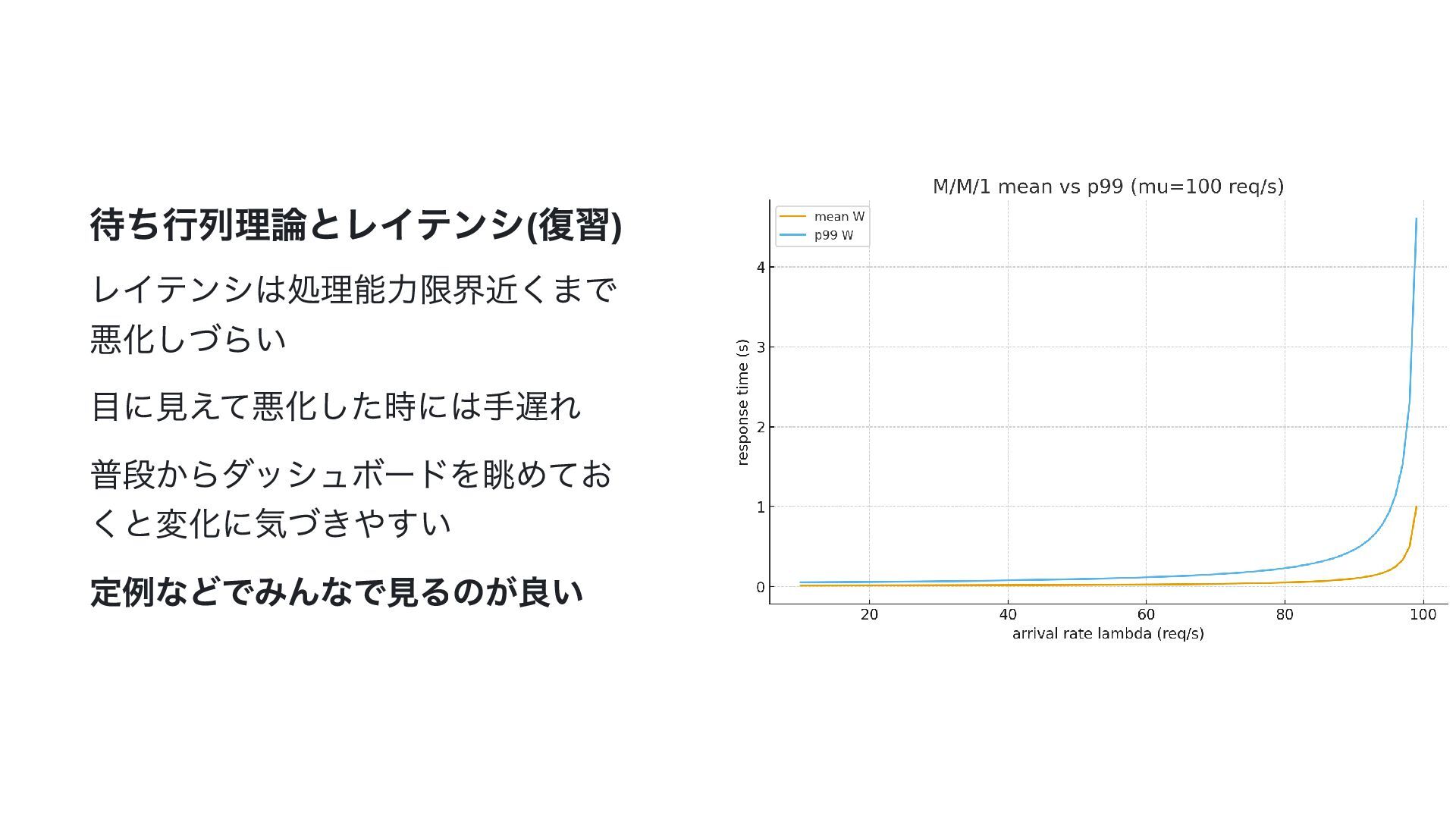{kind=link}
{kind=link}
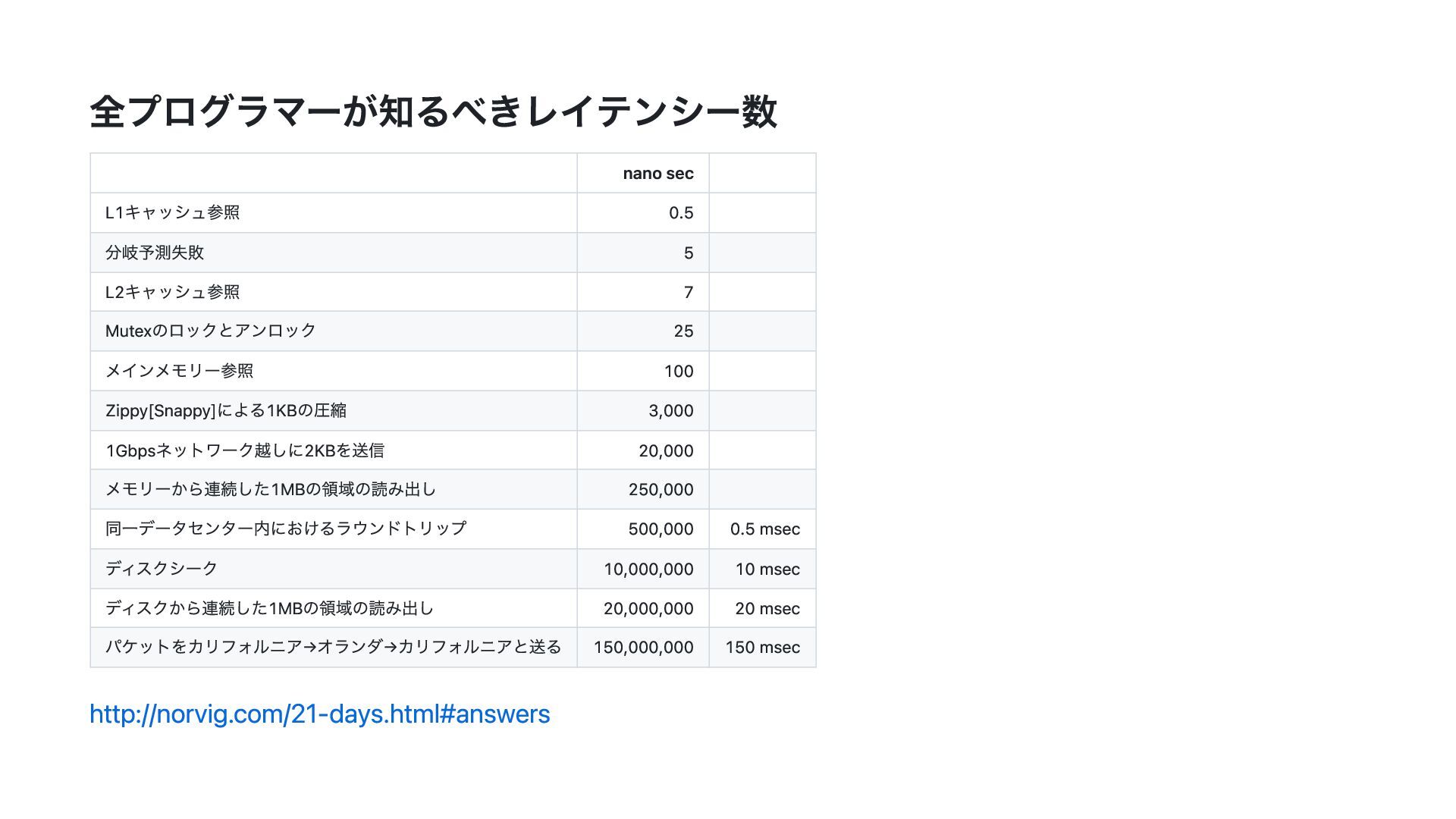{kind=link}
{kind=link}
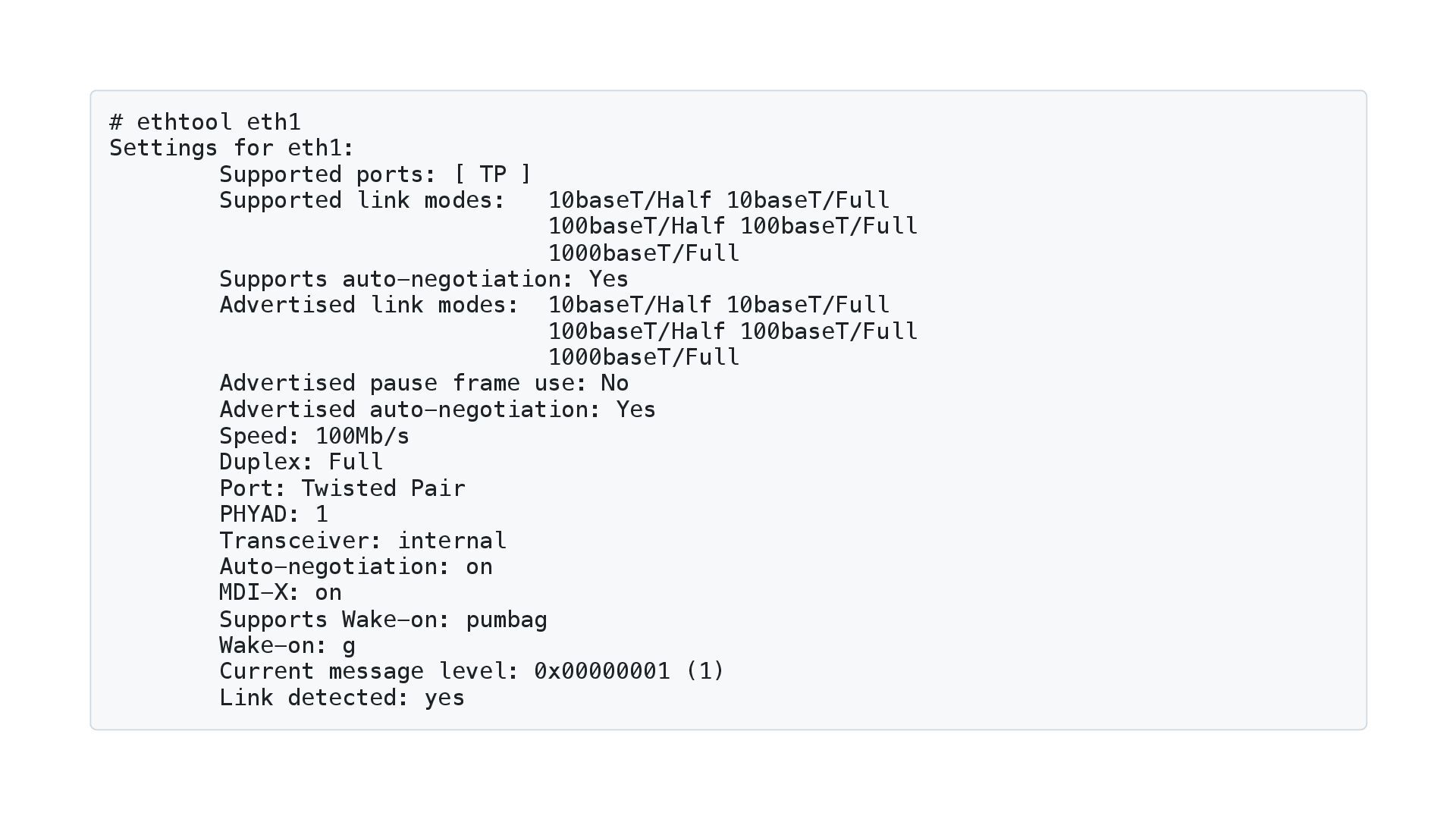
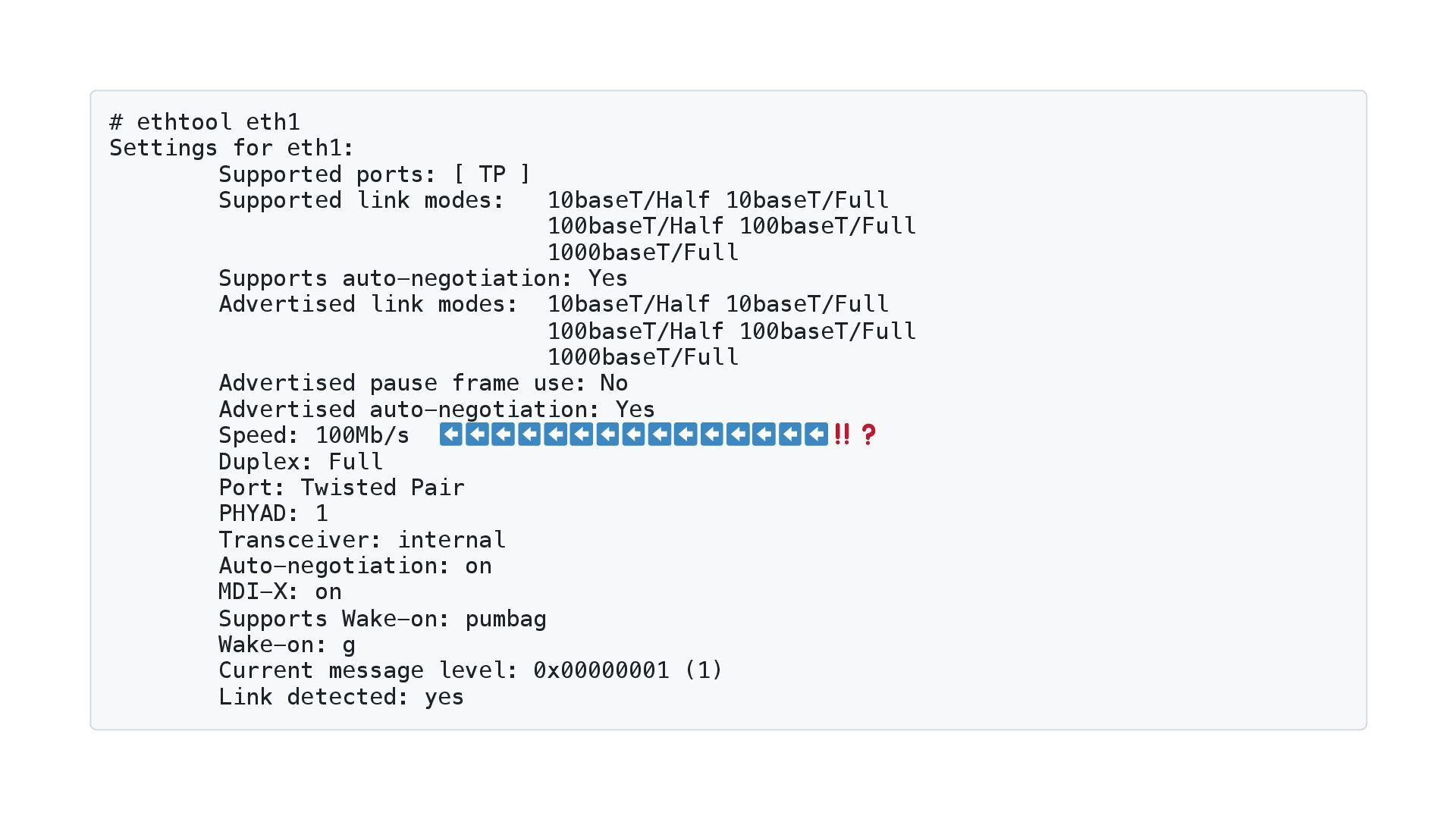
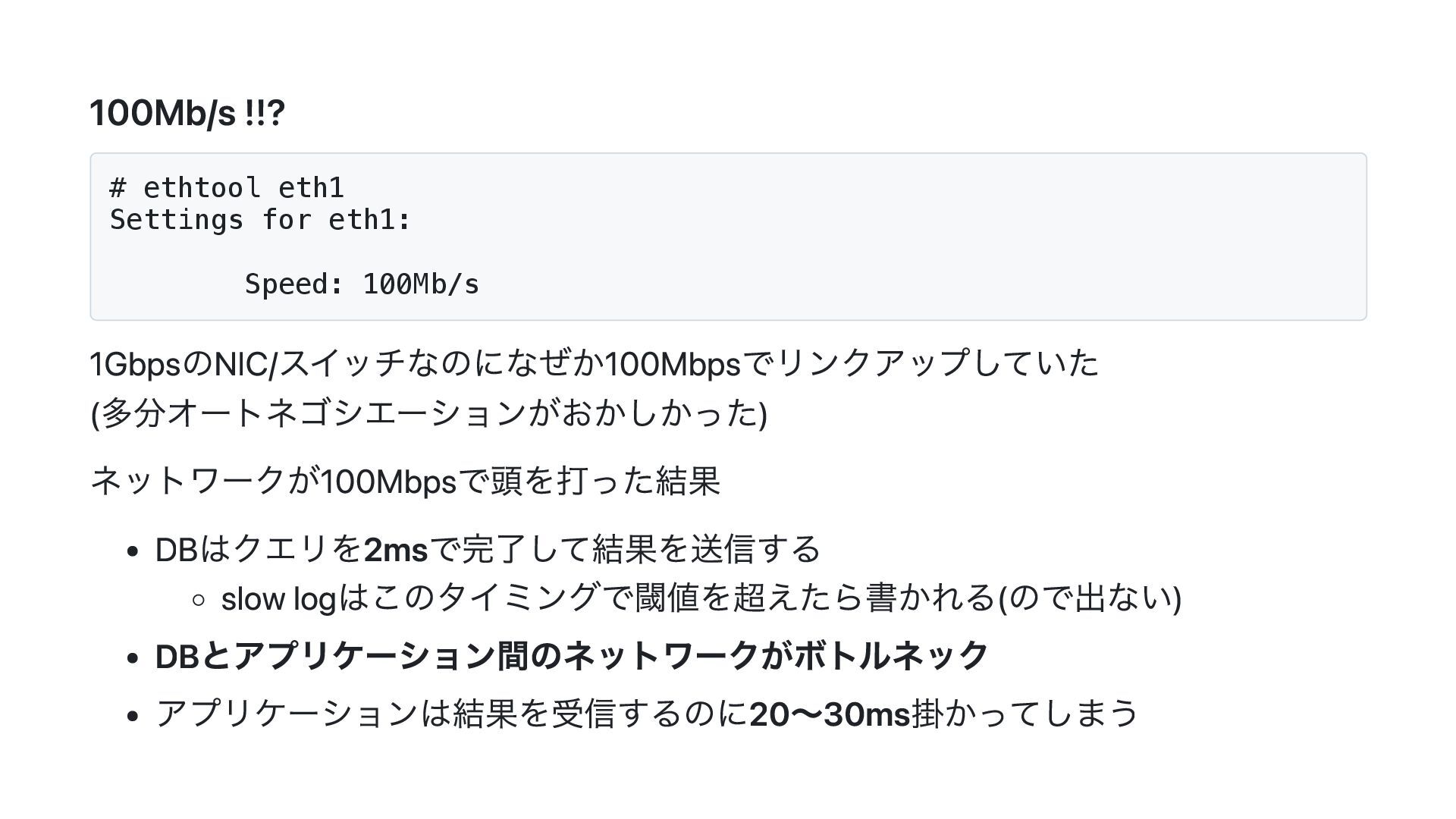
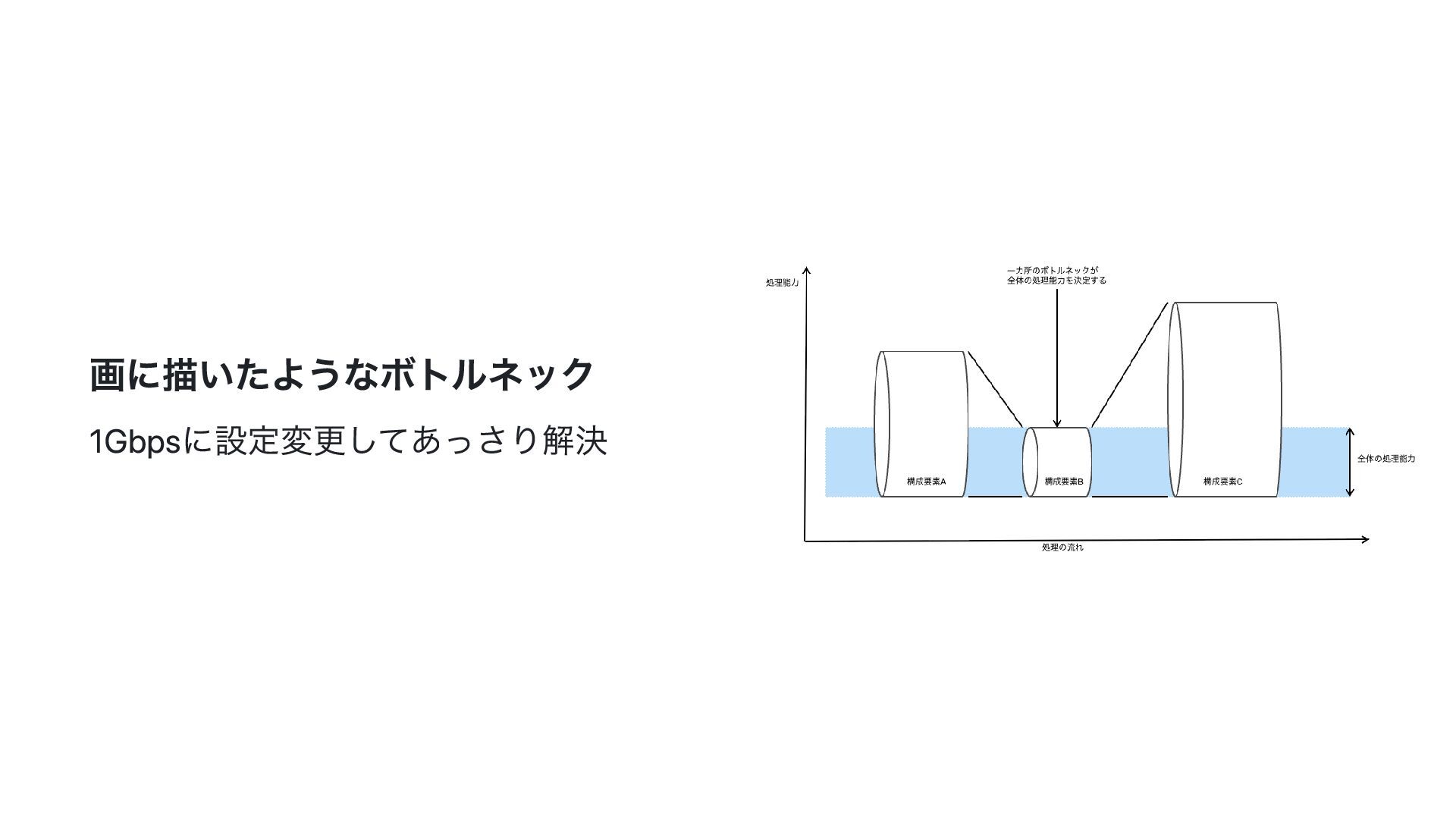
![マイクロベンチマークを手癖にする 例:「Goでsliceに要素を追加する場合、先にキャパシティを確保したほうが速い」 func AppendFromEmpty(n int) { var s []int //](https://files.speakerdeck.com/presentations/085ca03c971e42c8a4cff3c3fc88f0a5/slide_36.jpg){kind=link}
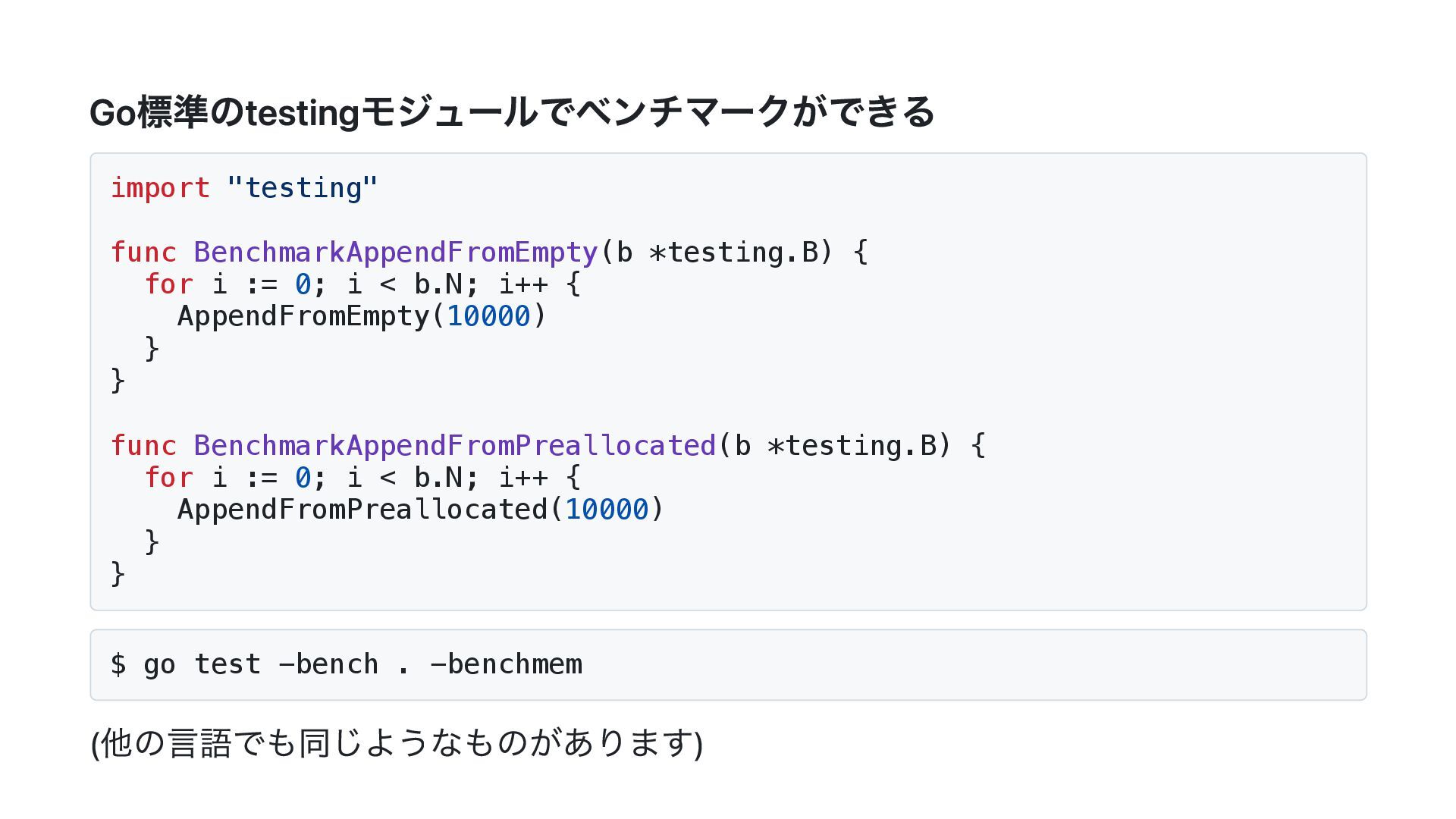{kind=link}
{kind=link}
{kind=link}
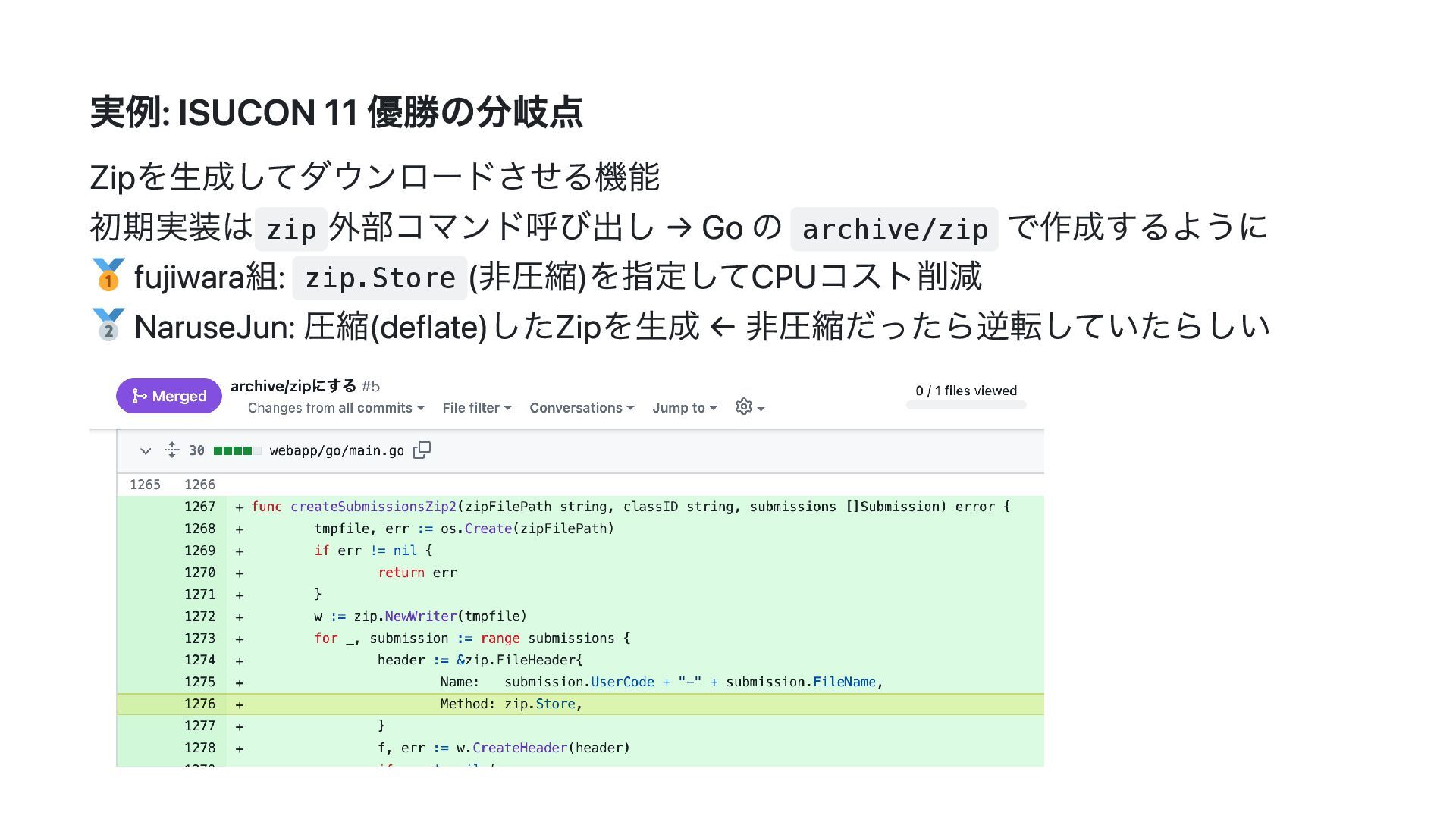{kind=link}
{kind=link}
{kind=link}
{kind=link}