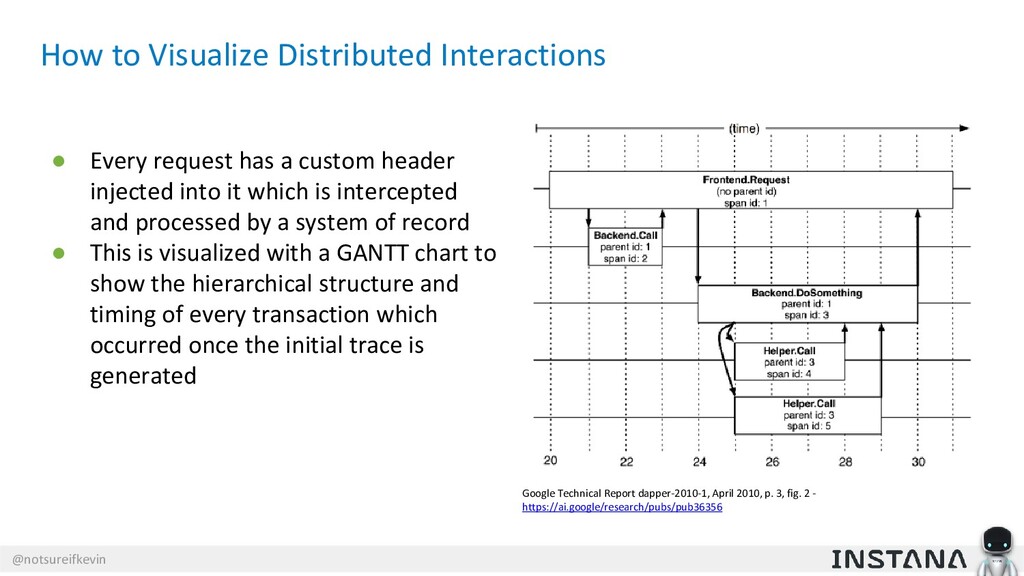
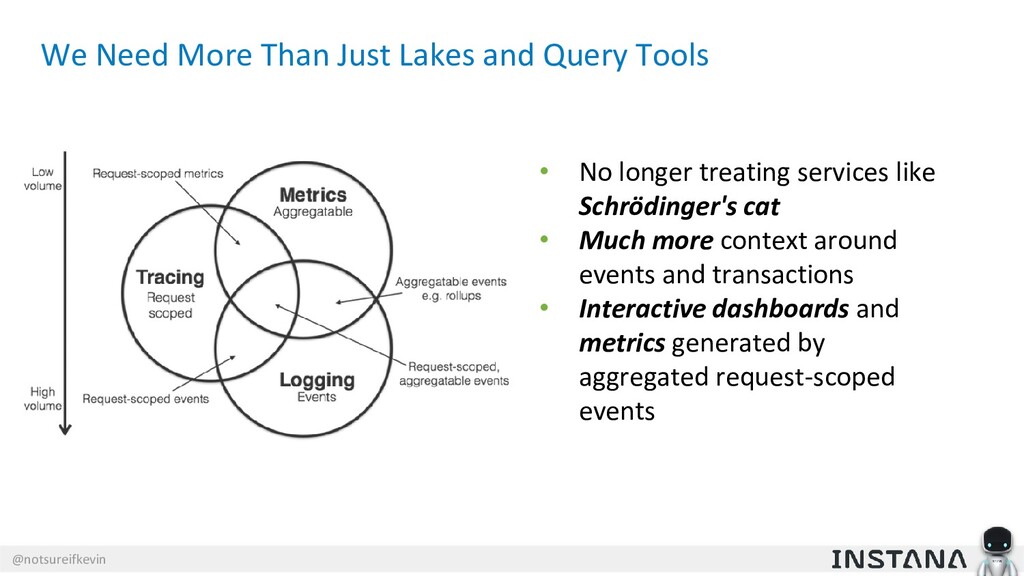
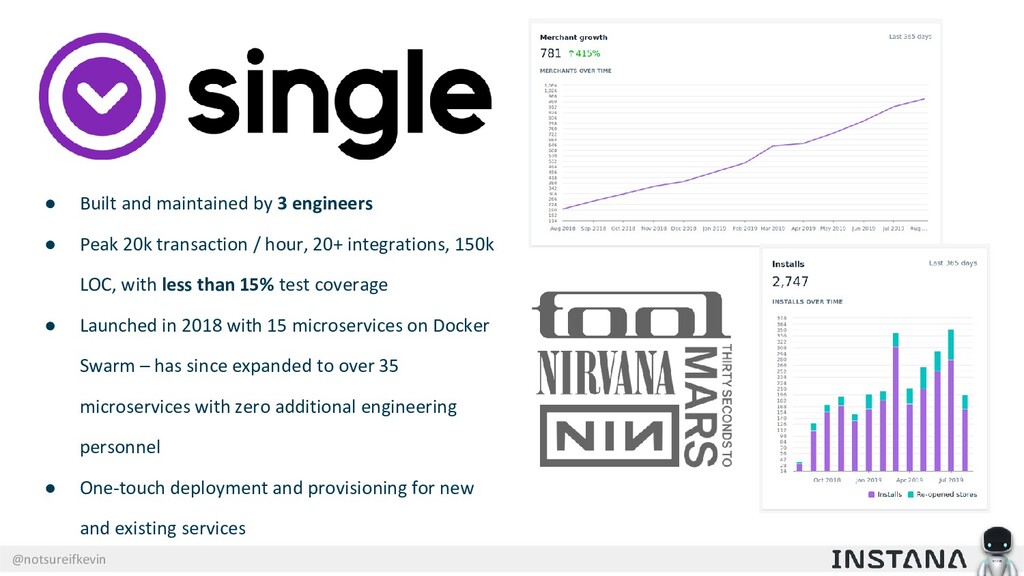
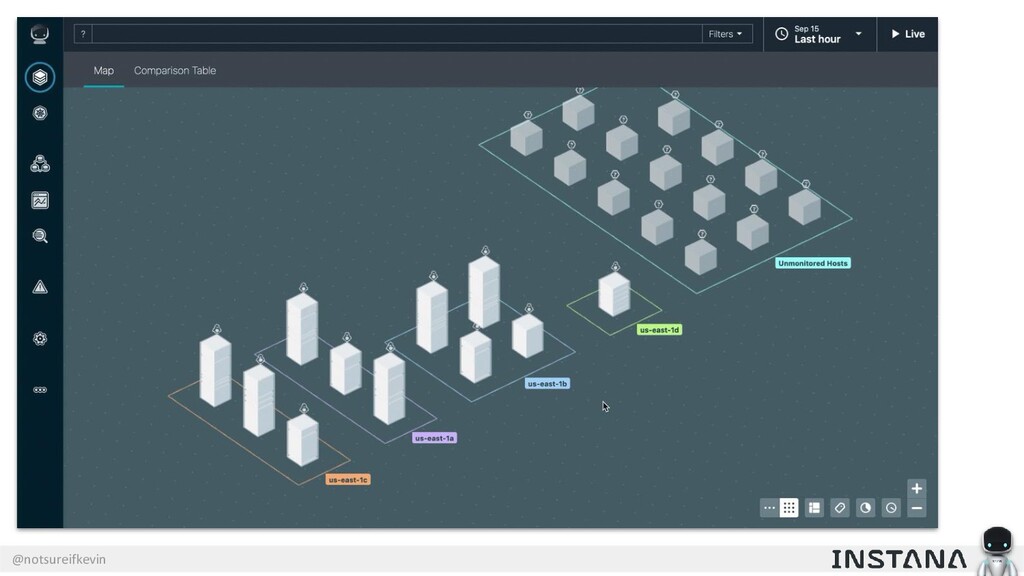
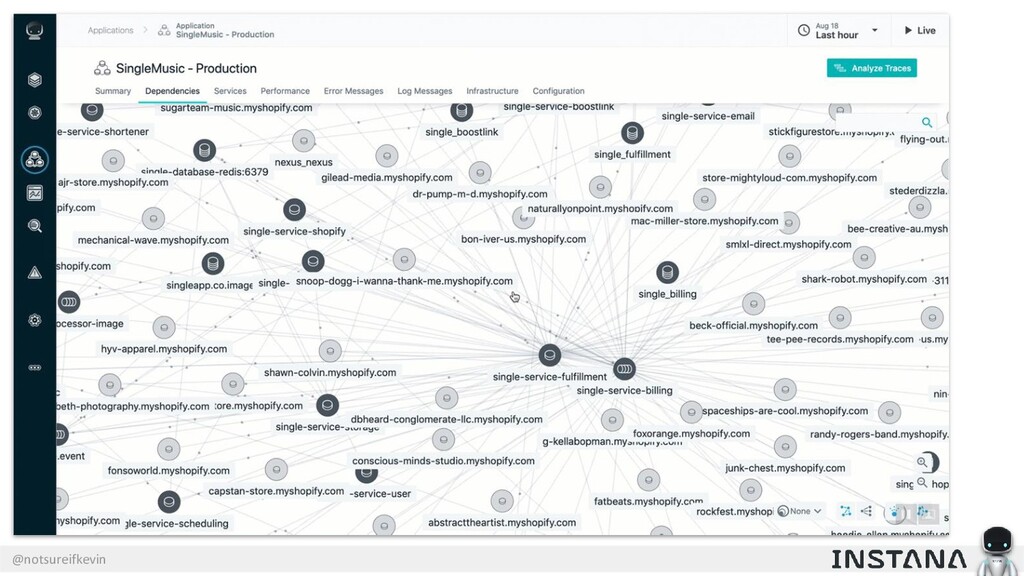
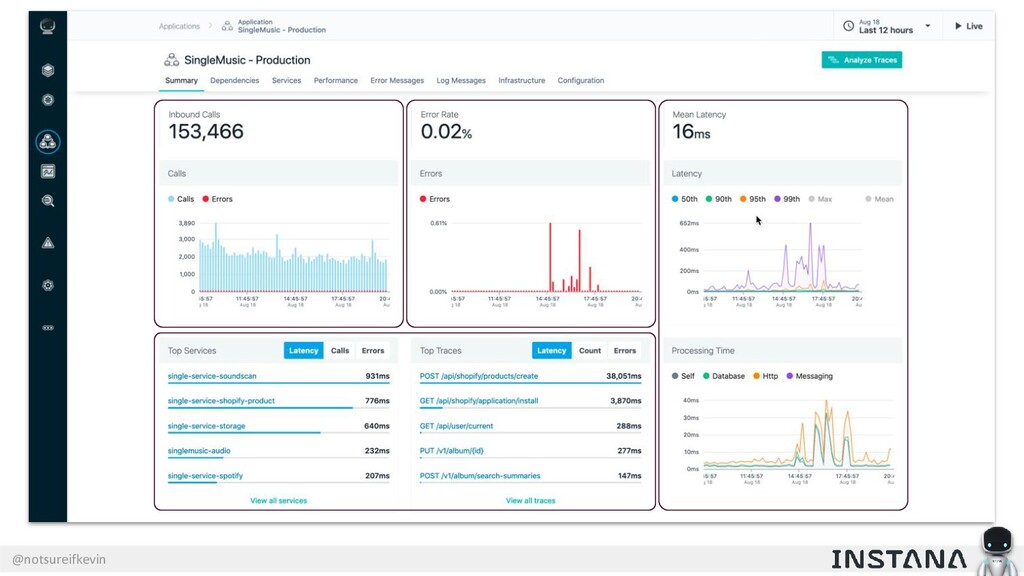
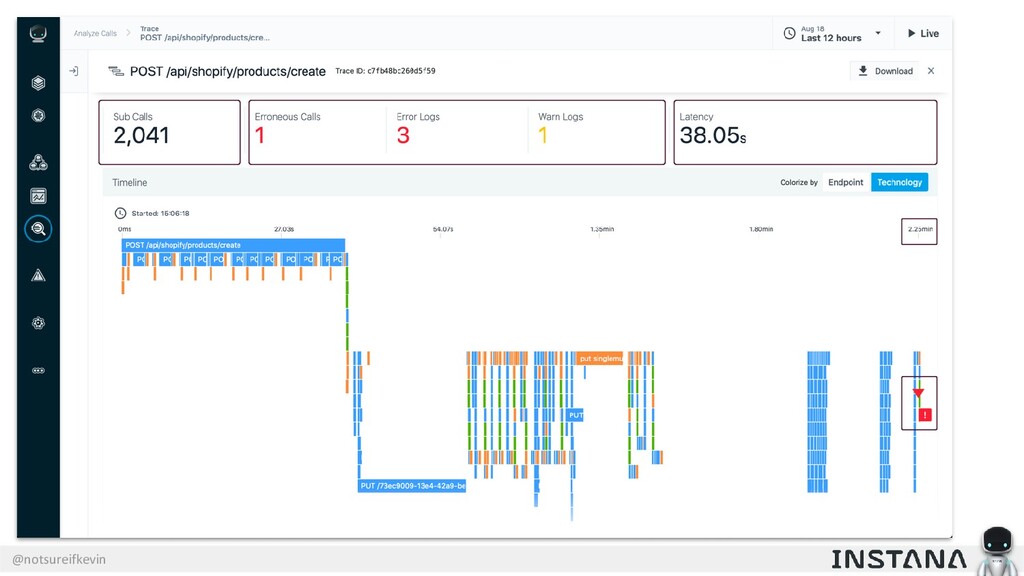
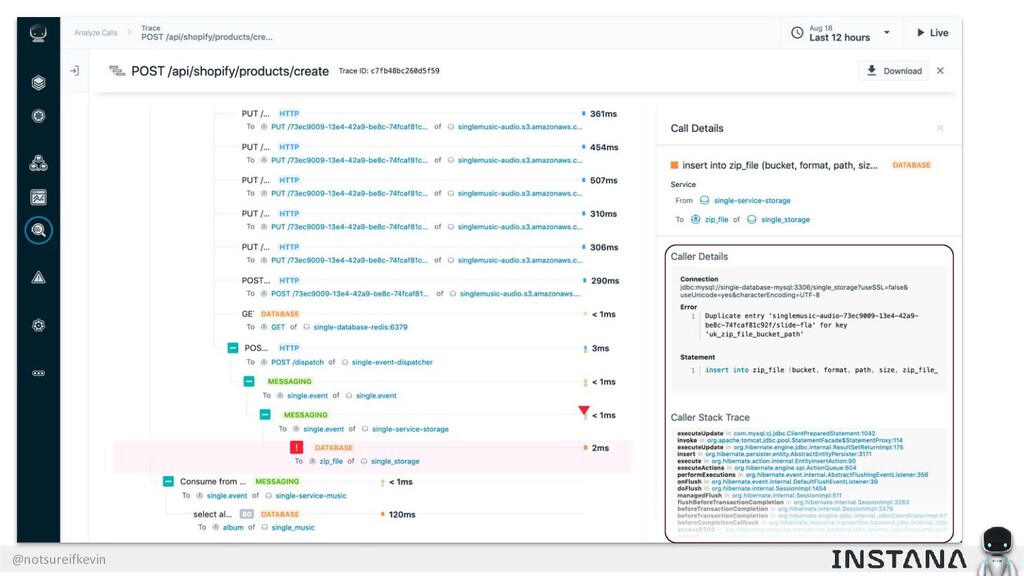
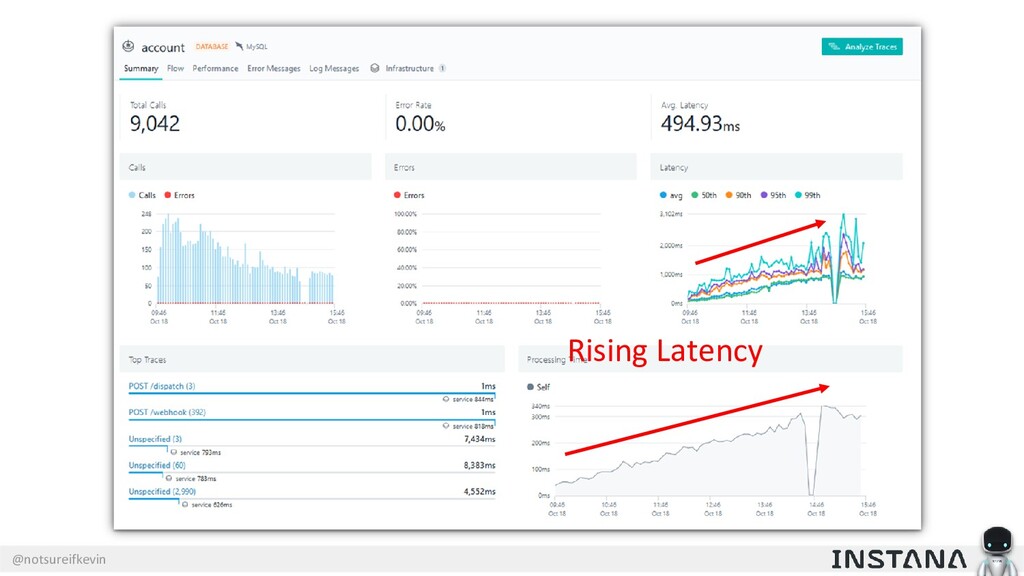
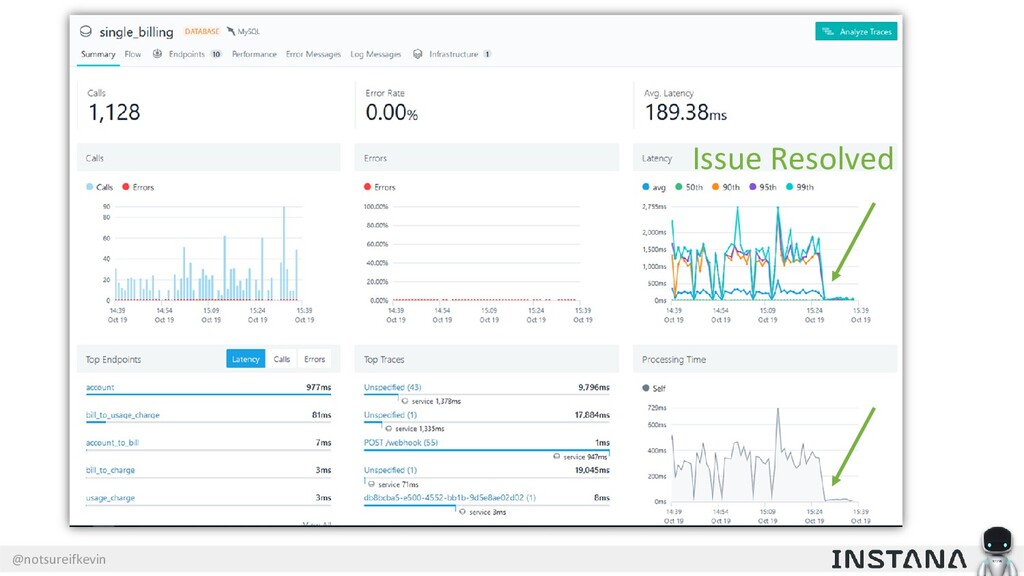
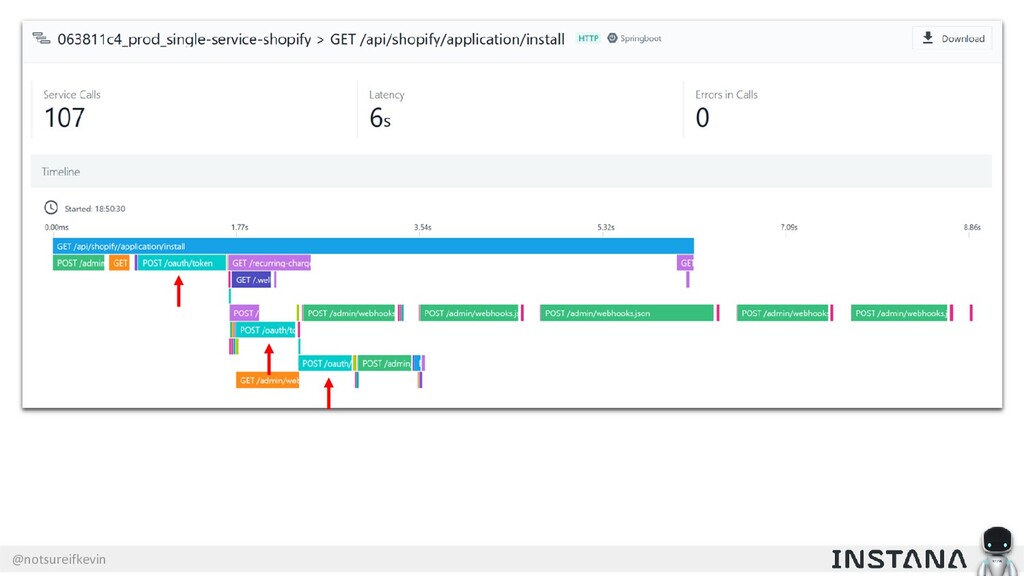
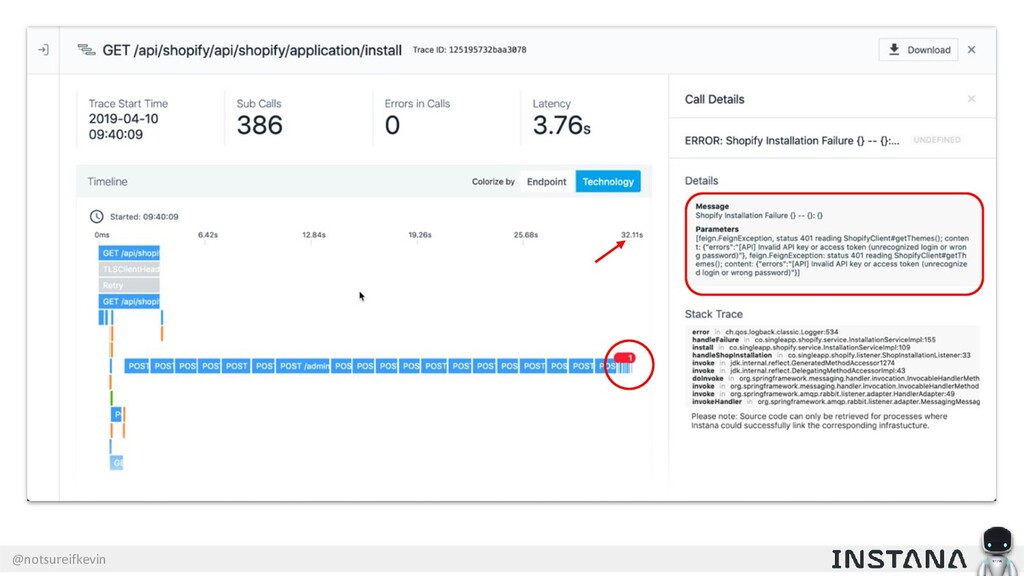
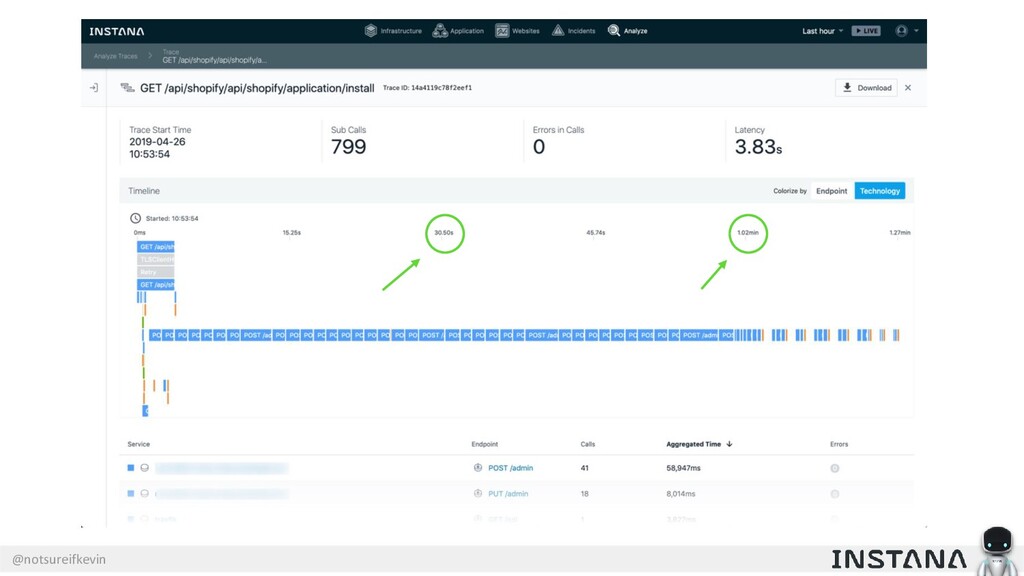
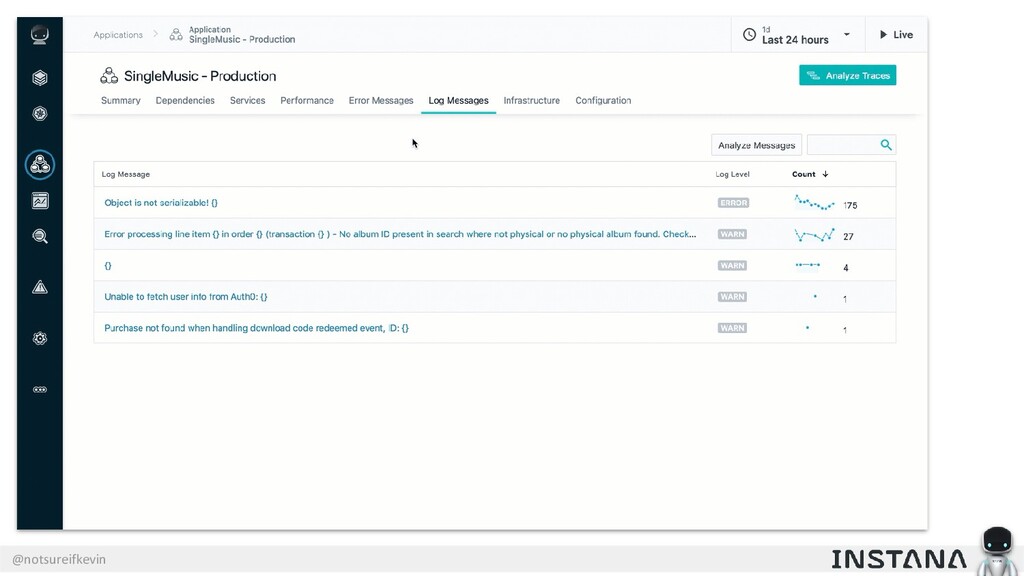
Unit testing and integration testing fall short in helping engineers understand how their applications run in production and avoid testing bits of code that should never be tested. In this session, Kevin Crawley of Instana shows real-world examples of modern observability tools that enable organizations to operate on as little as 15% code coverage and focus on what actually matters: the health of their production application. With these examples, Kevin demonstrates how sufficiently advanced monitoring is indistinguishable from testing and ultimately helps organizations recover from test coverage fatigue.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
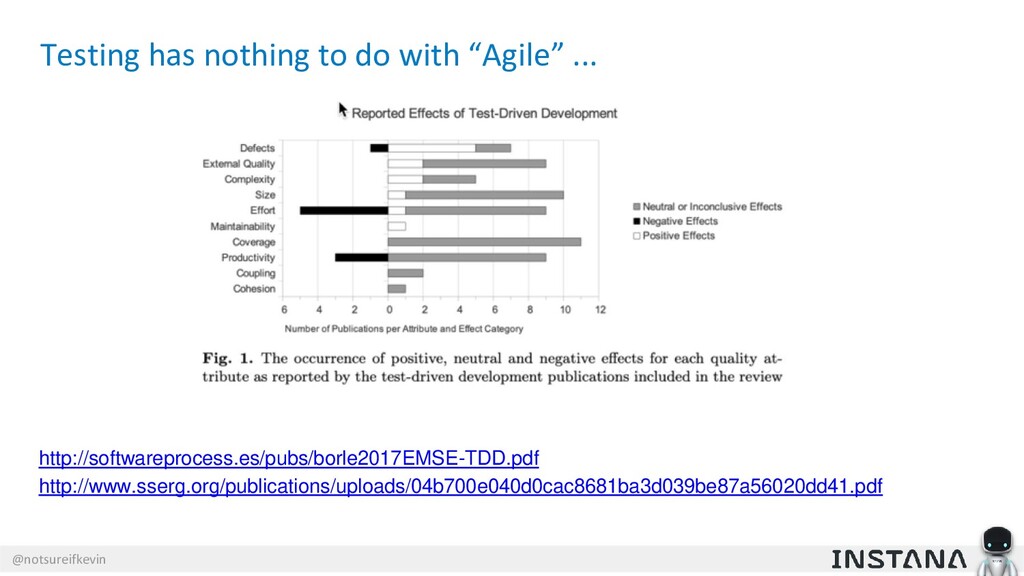{kind=link}
{kind=link}
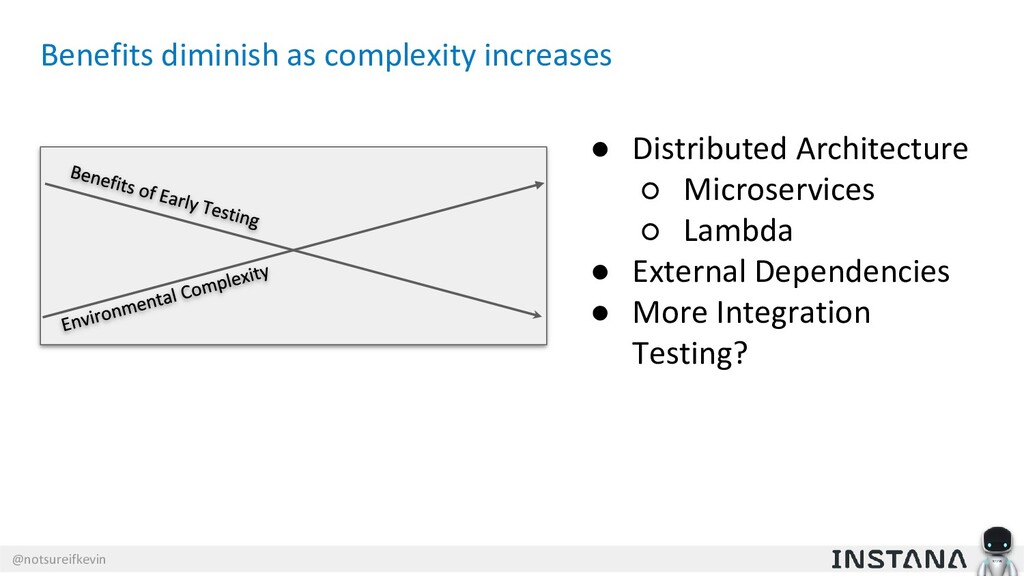{kind=link}
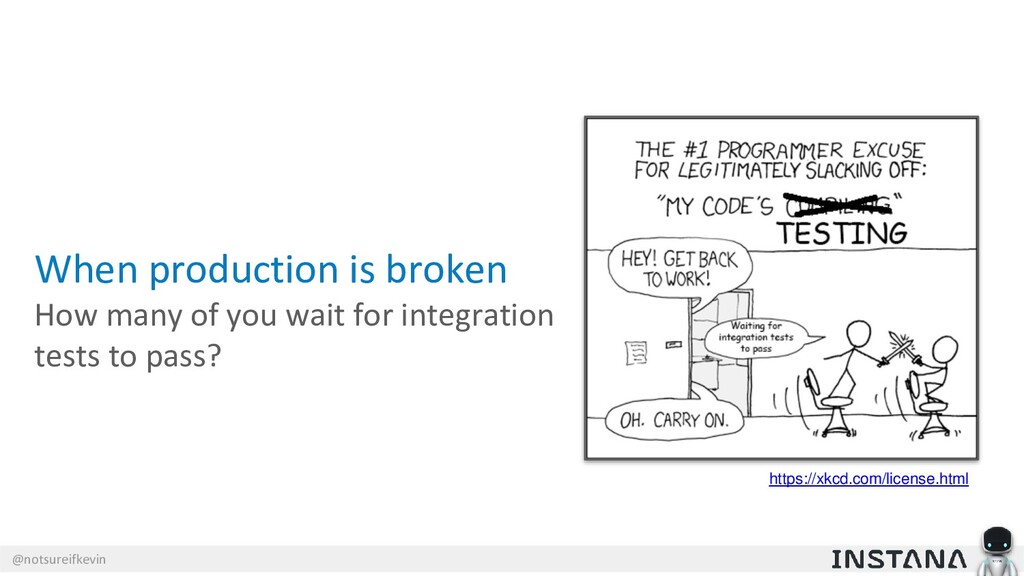{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}