Fleuret. Idiap Research Institute, EPFL NeurIPS, 2019. 慶應義塾大学 杉浦孔明研究室 B4小松 拓実 Srinivas, Suraj, and François Fleuret. "Full-gradient representation for neural network visualization." Advances in neural information processing systems 32 (2019).
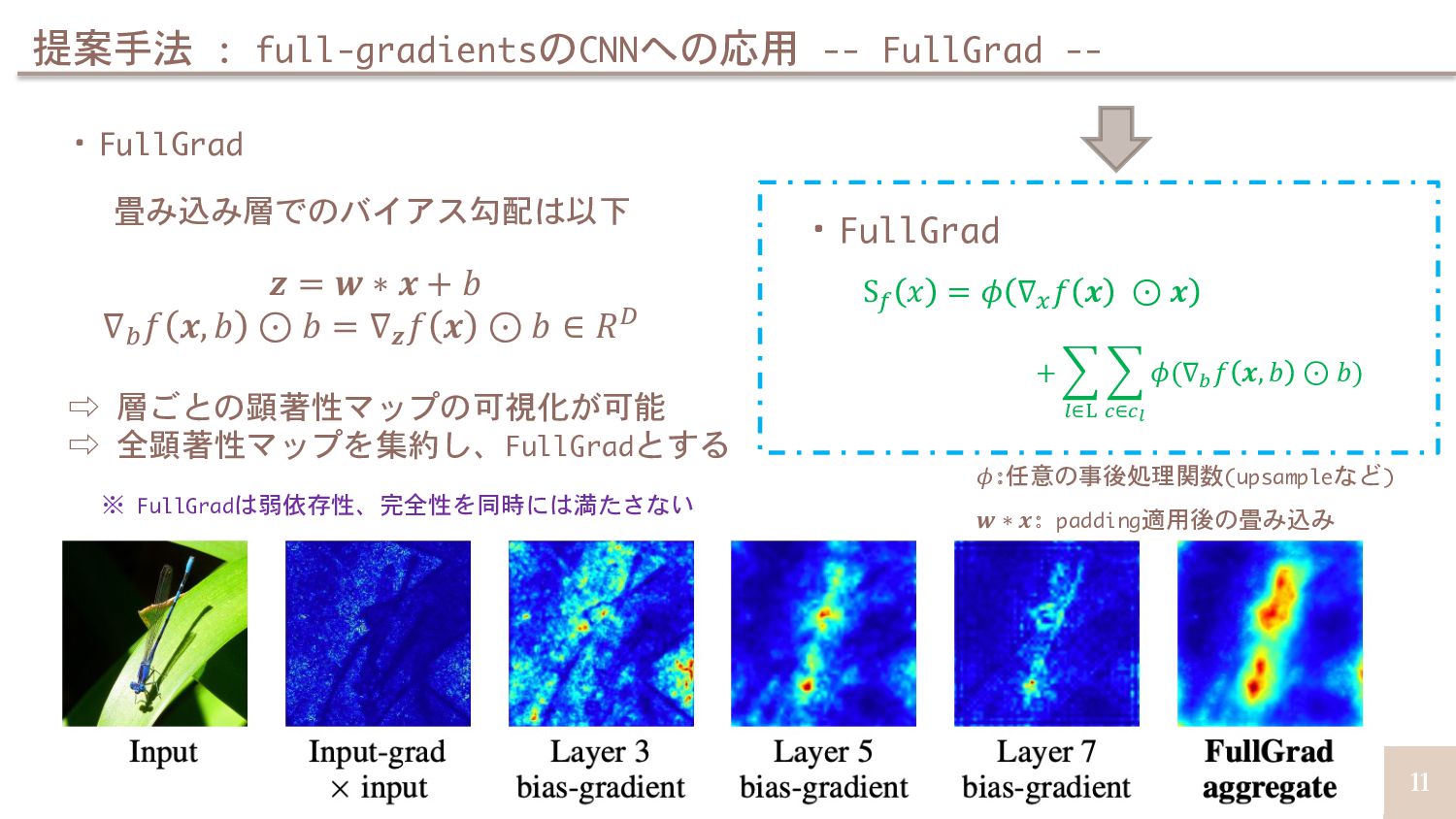
顕著性マップを作成する手法 DeconvNet[Matthew+, ECCV14] Guided-Backprop[Tobias+, ICLR15] 入力勾配に対する逆伝播の方法を 変えることで鮮明化した手法 Deep Taylor decomposition[Gregoire+,PR17] DeepLIFT[Shrikumar+, JMLR17] 顕著性マップとモデルの出力との関係を数 値的に求めた手法(完全性を満たす) Input-Gradient Guided-Backprop Deep Taylor decomposition
{kind=link}
{kind=link}
{kind=link}
![4 関連研究 : 微分系の手法ではバイアスを考慮できない 説明手法 概要 Input-Gradient [Karen+, ICLR13] 出力に対する入力の勾配から](https://files.speakerdeck.com/presentations/3396c66aa172464488e917ec11b6cc12/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
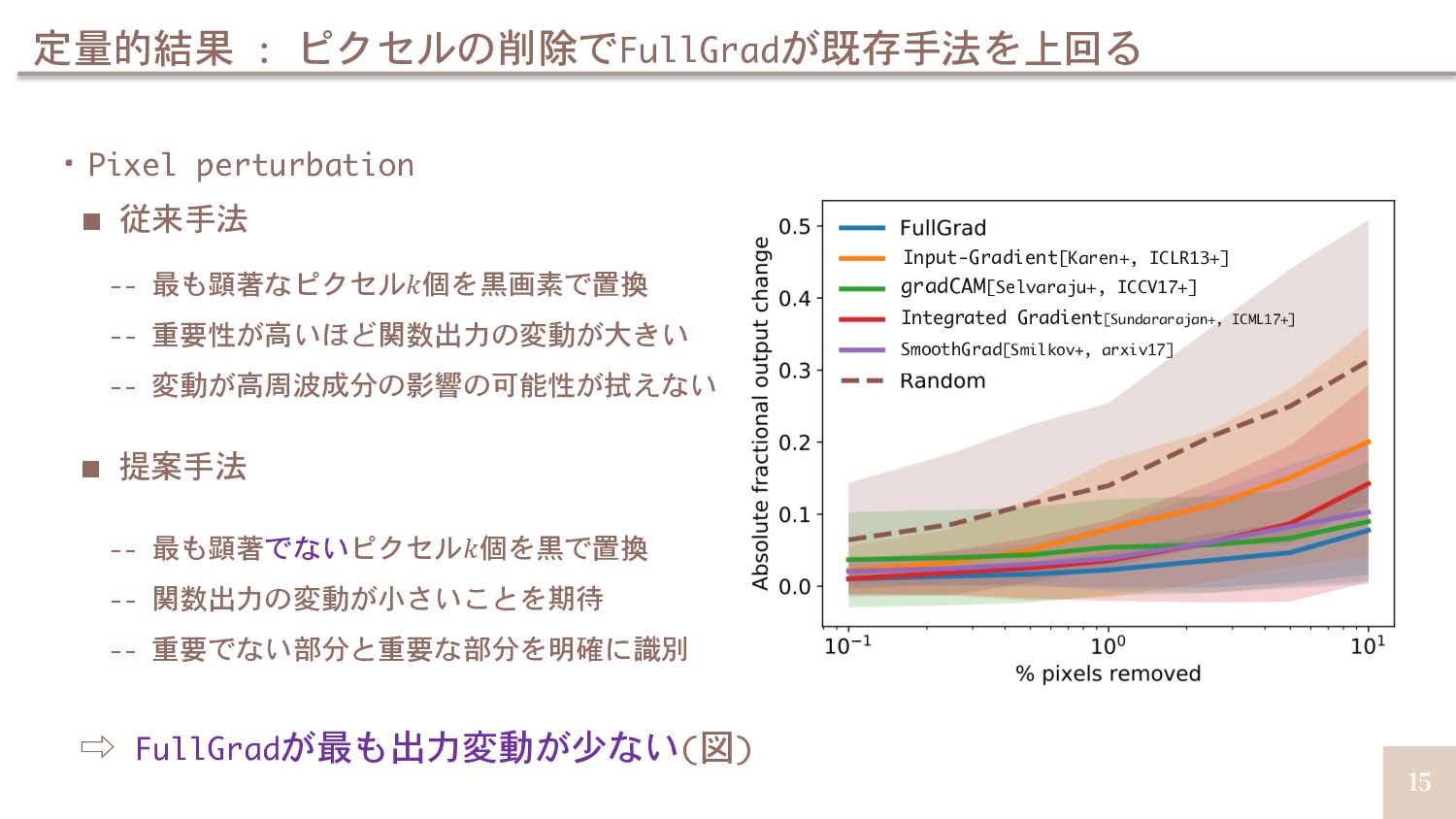{kind=link}
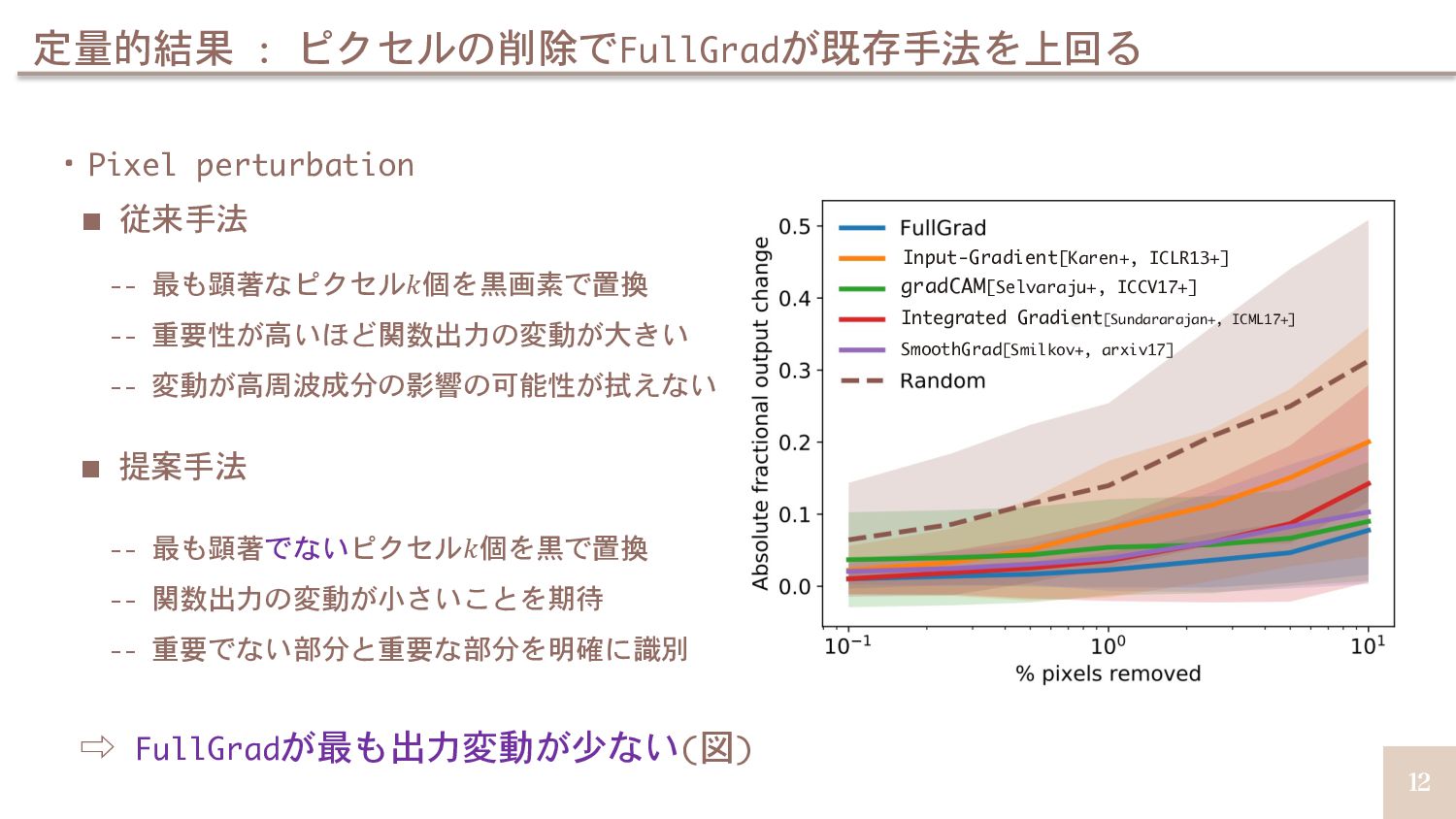
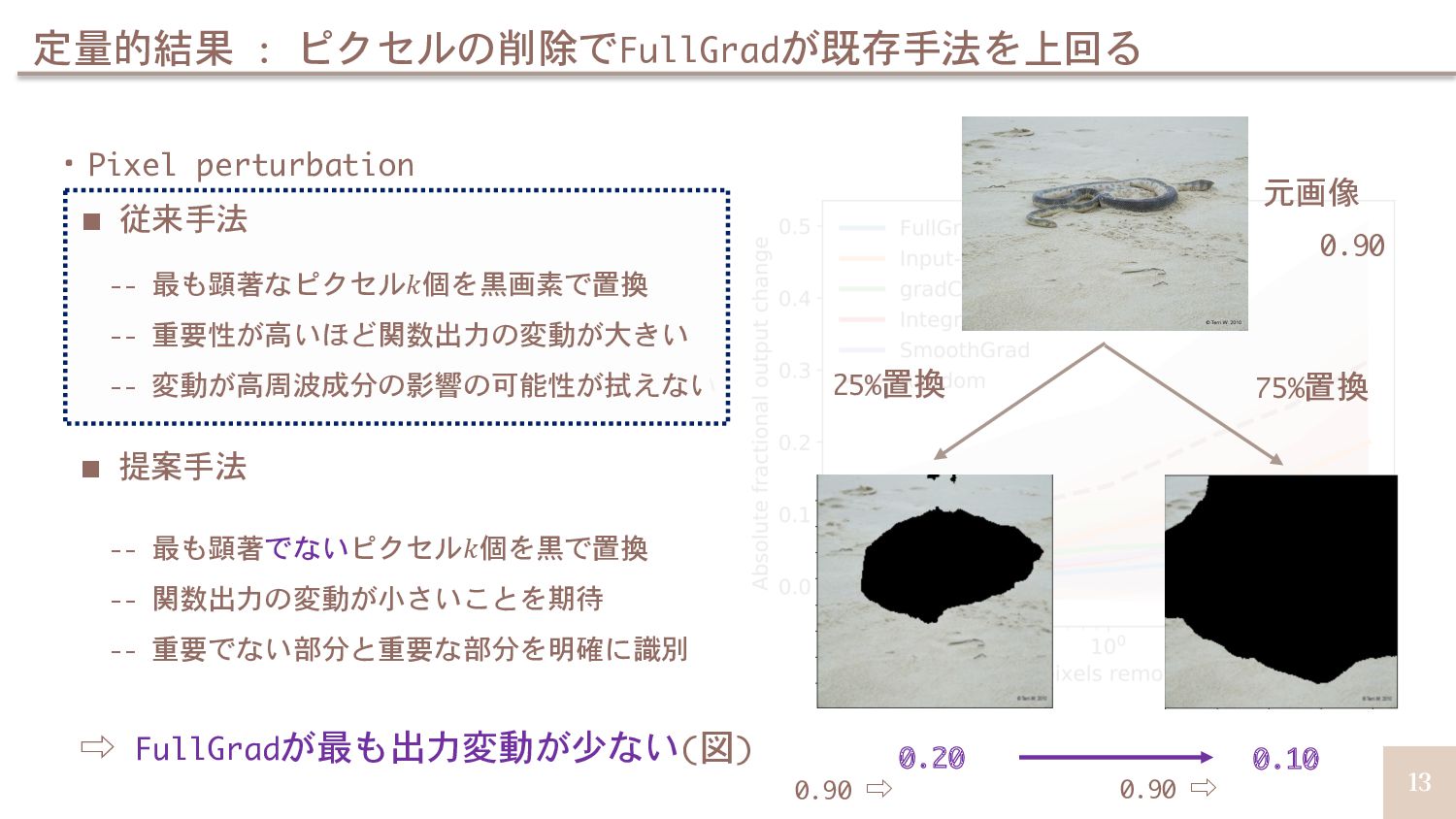
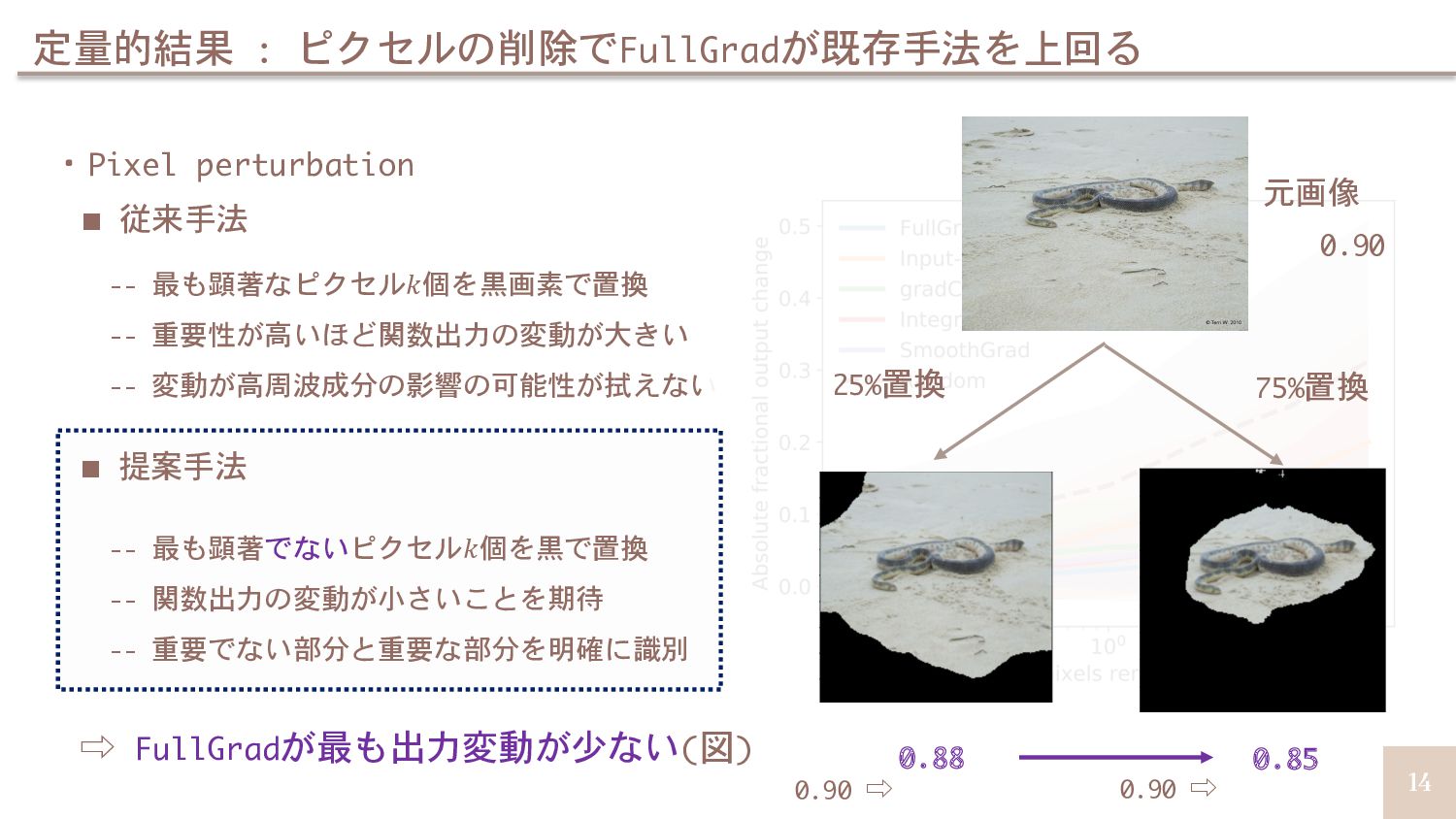
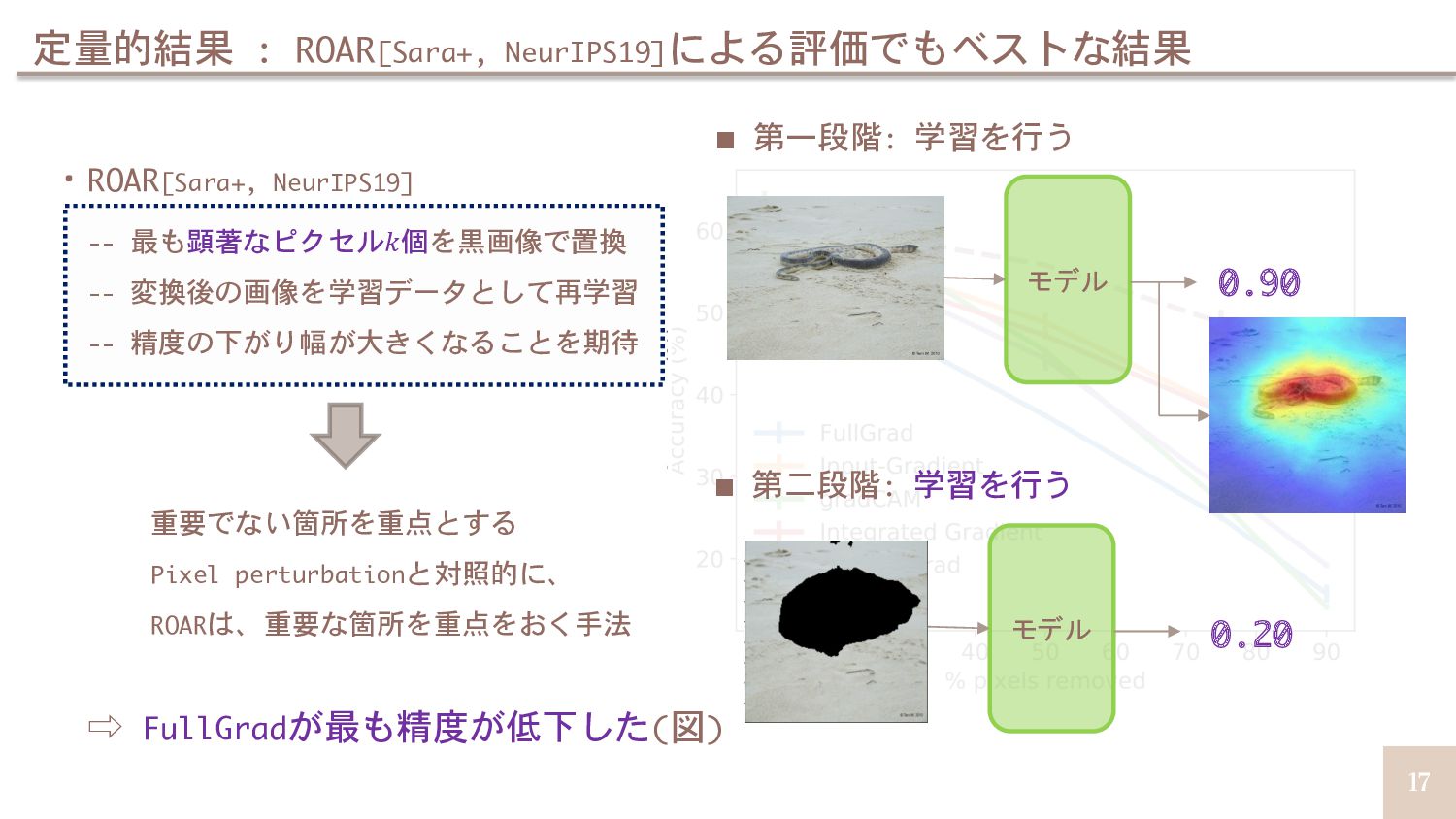
![16 定量的結果 : ROAR[Sara+, NeurIPS19]による評価でもベストな結果 ・ROAR[Sara+, NeurIPS19] -- 最も顕著なピクセル𝑘個を黒画像で置換 --](https://files.speakerdeck.com/presentations/3396c66aa172464488e917ec11b6cc12/slide_15.jpg){kind=link}
{kind=link}
![18 ・ROAR[Sara+, NeurIPS19] -- 最も顕著なピクセル𝑘個を黒画像で置換 -- 変換後の画像を学習データとして再学習 -- 精度の下がり幅が大きくなることを期待 重要でない箇所を重点とする](https://files.speakerdeck.com/presentations/3396c66aa172464488e917ec11b6cc12/slide_17.jpg){kind=link}
{kind=link}
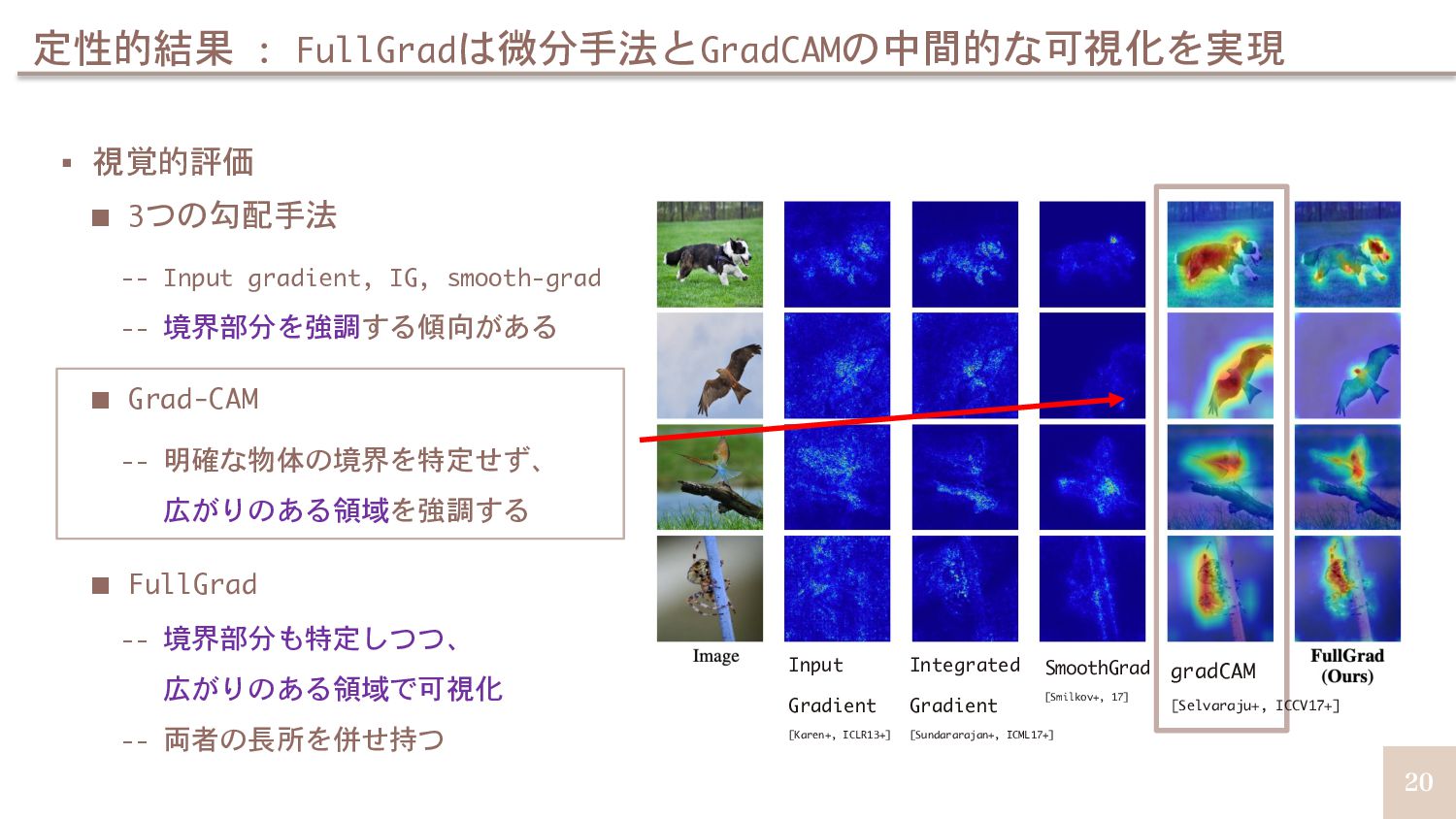{kind=link}
{kind=link}
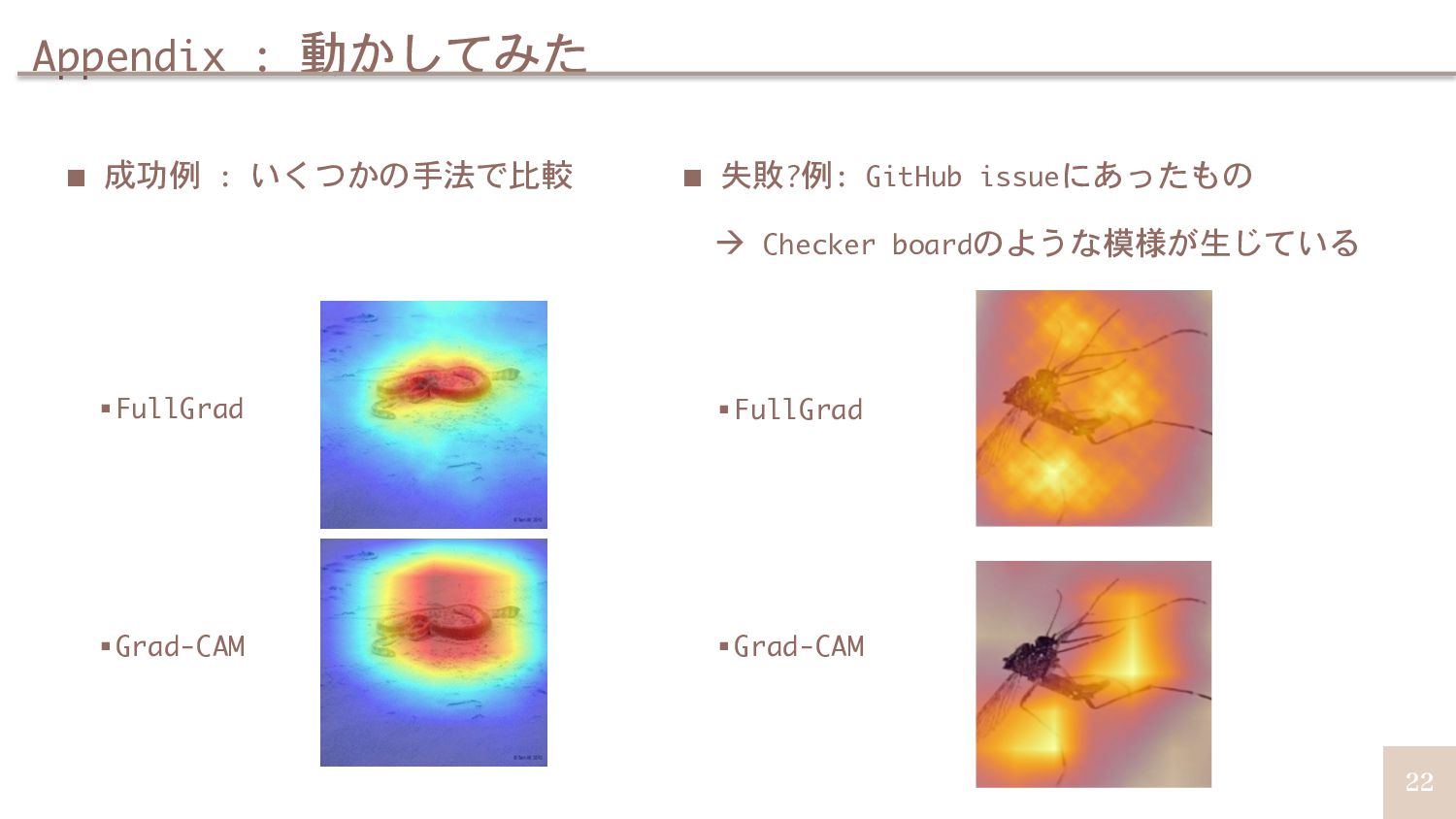{kind=link}
{kind=link}
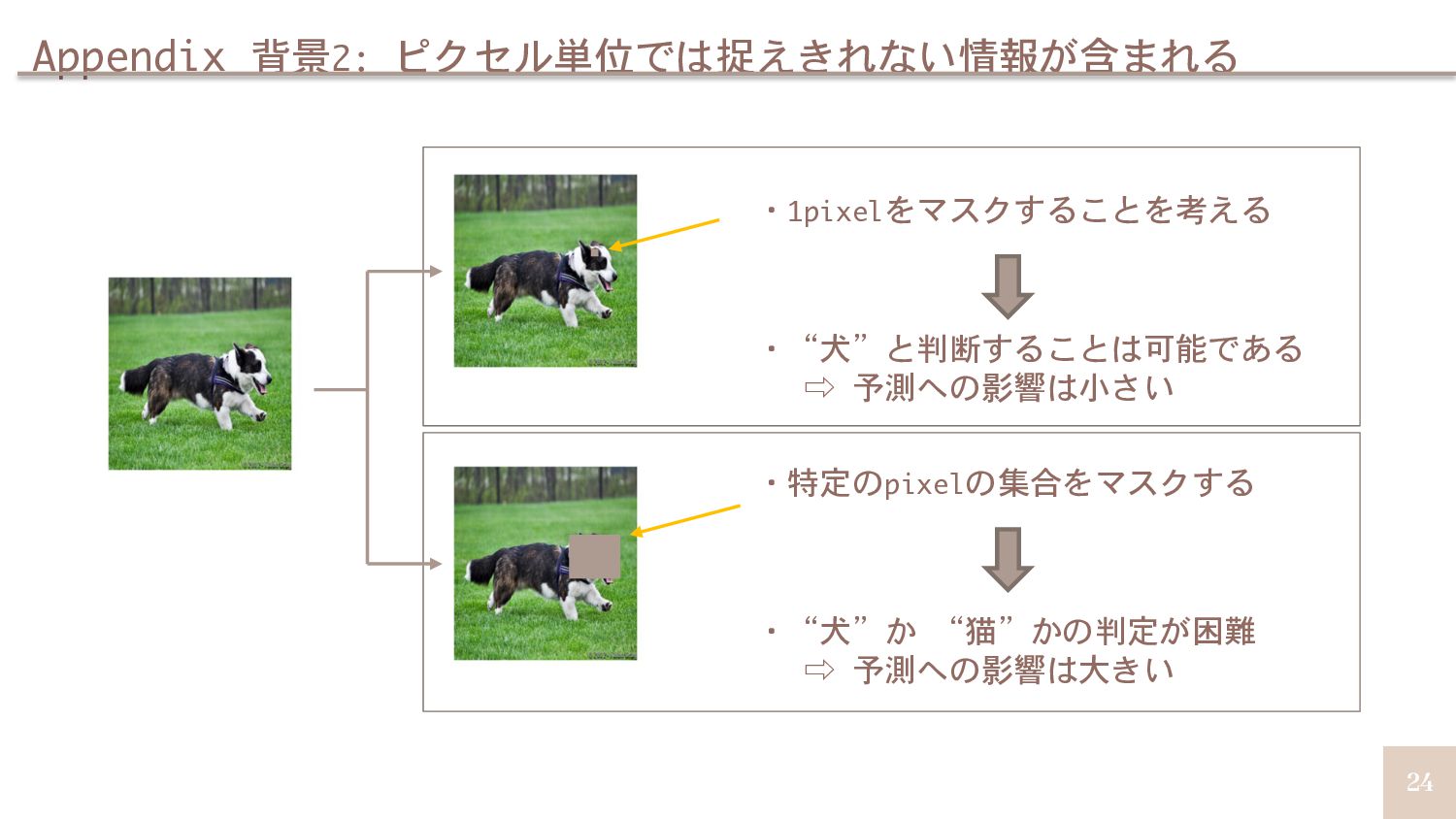{kind=link}
![25 Appendix: Integrated-gradient[Mukund+,2017]は弱依存性を満たさない ・Integrated-gradient[Sundararajan+, ICML17] 𝐼𝐺# 𝒙 = 𝑥# −](https://files.speakerdeck.com/presentations/3396c66aa172464488e917ec11b6cc12/slide_24.jpg){kind=link}
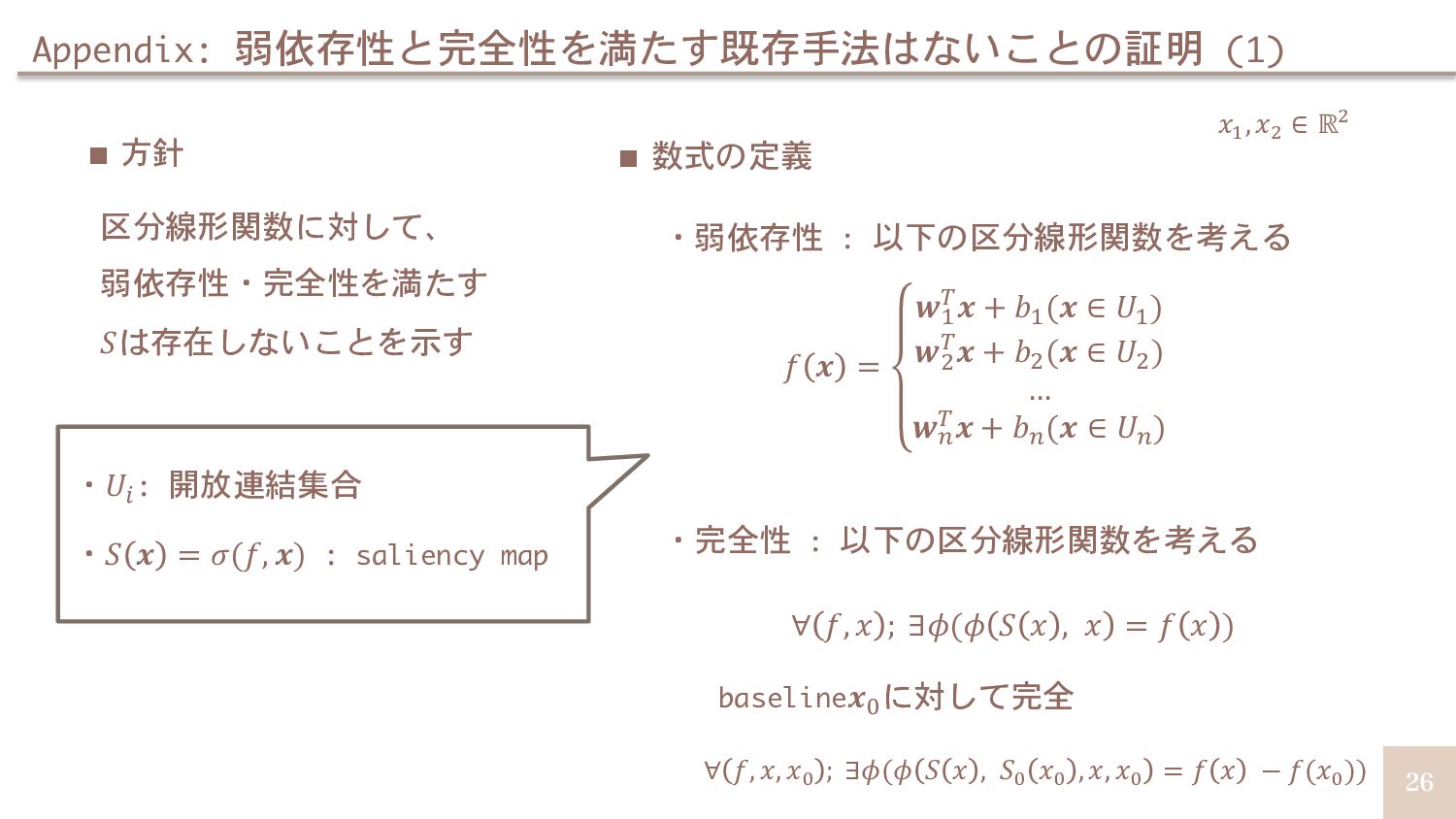{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
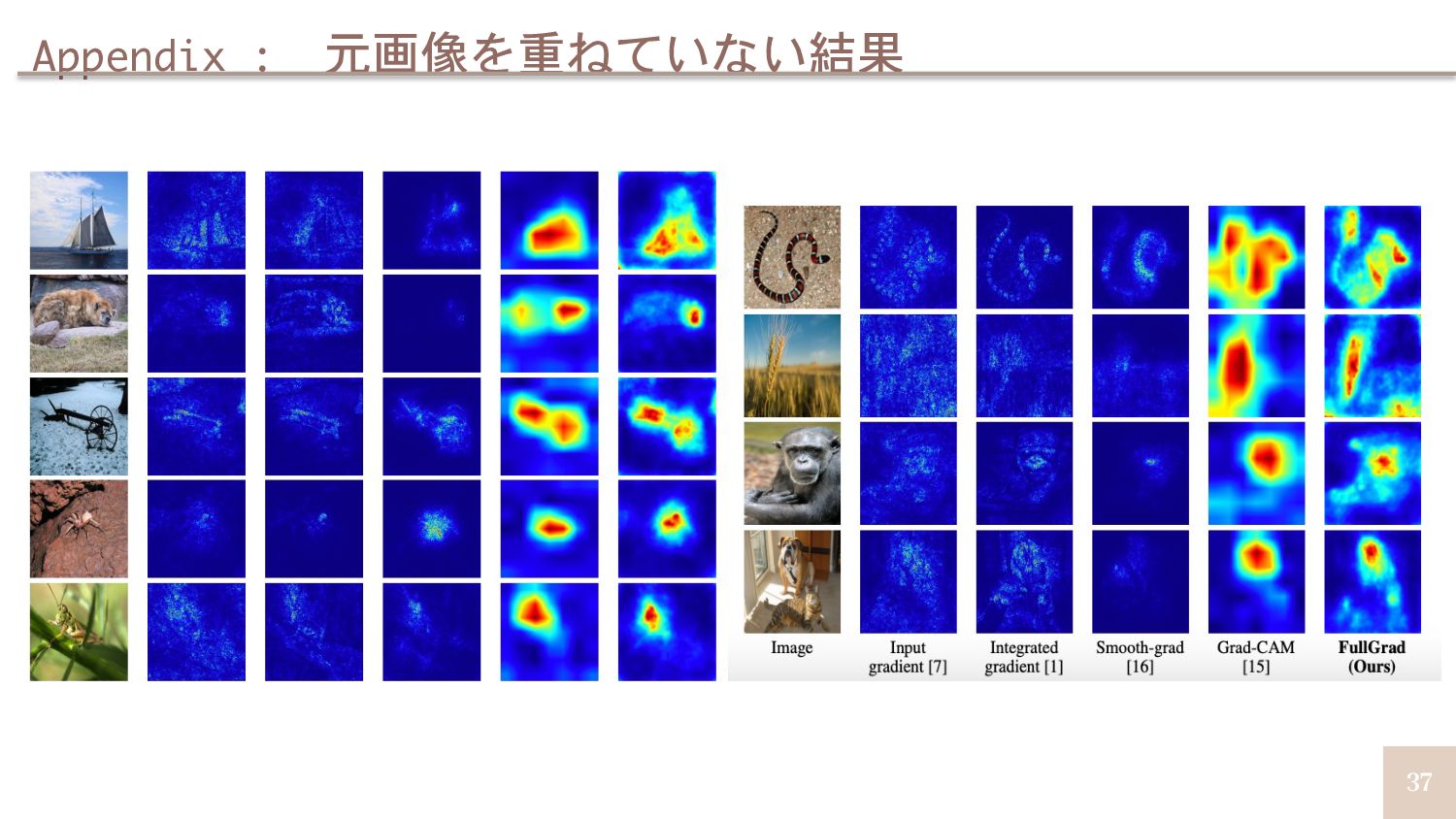{kind=link}
{kind=link}