Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] GIRAFFE: Representing Scenes As ...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
July 25, 2022
Technology
150
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] GIRAFFE: Representing Scenes As Compositional Generative Neural Feature Fields
Semantic Machine Intelligence Lab., Keio Univ.
PRO
July 25, 2022
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
84
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
AmplifyHostingConstructからSSRフレームワークのためのホスティング設計を考察する/amplify-hosting-construct
fossamagna
1
300
OPENLOGI Company Profile for engineer
hr01
1
74k
クラウドを使う側から、作る側へ / 大吉祥寺.pm 2026前夜祭
fujiwara3
4
1.2k
AIとハーネスで育てるトランスコンパイラ / 20260722 Yasushi Katayama
shift_evolve
PRO
3
780
AI_Dev_Day_製造業領域でのAI活用から見た活用の罠と成功に導く実践知.pdf
kintotechdev
0
160
2年前に削除したPHPクラスが、 ある日突然決済をエラーにした
ykagano
1
780
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
160
伝票作成AIエージェントを支える、LLMOpsとインフラの選択肢 / AICon2026_takeda
rakus_dev
0
260
全社でのソフトウェアサプライチェーン攻撃対策をやってみた with Takumi Guard
z63d
0
270
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
160
[Droidcon Orlando '26] The Android Lens: Applying Mobile Forensics to AI Performance
amanda_hinchman
1
110
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
1
1.3k
Featured
See All Featured
30 Presentation Tips
portentint
PRO
1
350
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
410
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
150
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Visualization
eitanlees
152
17k
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
320
The agentic SEO stack - context over prompts
schlessera
0
850
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
220
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
400
Transcript
GIRAFFE: Representing Scenes As Compositional Generative Neural Feature Fields Michael
Niemeyer, Andreas Geiger, Max Planck Institute for Intelligent Systems, Tubingen University of Tubingenin In CVPR, 2021, pp. 11453-11464 杉浦孔明研究室 飯岡 雄偉
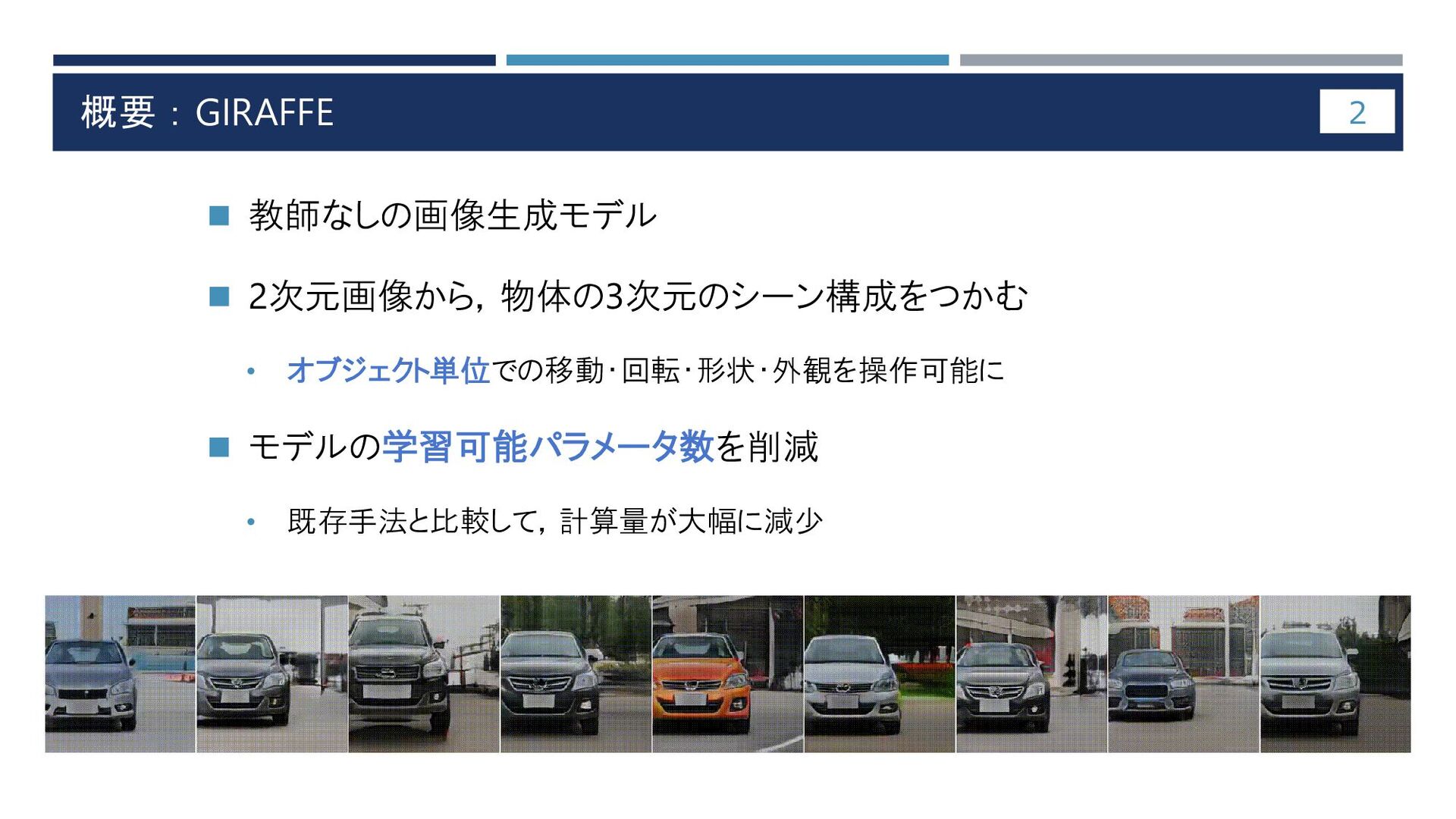
概要:GIRAFFE ◼ 教師なしの画像生成モデル ◼ 2次元画像から,物体の3次元のシーン構成をつかむ • オブジェクト単位での移動・回転・形状・外観を操作可能に ◼ モデルの学習可能パラメータ数を削減 •
既存手法と比較して,計算量が大幅に減少 2
背景:3次元オブジェクトの操作可能性が求められる ◼ ゲームや映画において,3D物体をオブジェクト単位での操作は重要 専用のハードウェアや,技術者が求められる -> 高コスト化 3 https://assetstore.unity.com/packages/templates/tutorials/3d-game-kit-115747?locale=ja-JP
関連研究:3Dのシーン構成を教師なしでつかみきれていない 4 model detail GAN [Ian+ NIPS2014] 〇教師なしでの学習 △3Dのシーン構成はブラックボックス化 NeRF
[Ben+ ECCV2020] 〇3Dのシーン構成をつかむ △カメラパラメータが必要 https://qiita.com/shionhonda/items/330c9fdf78e62db3402b
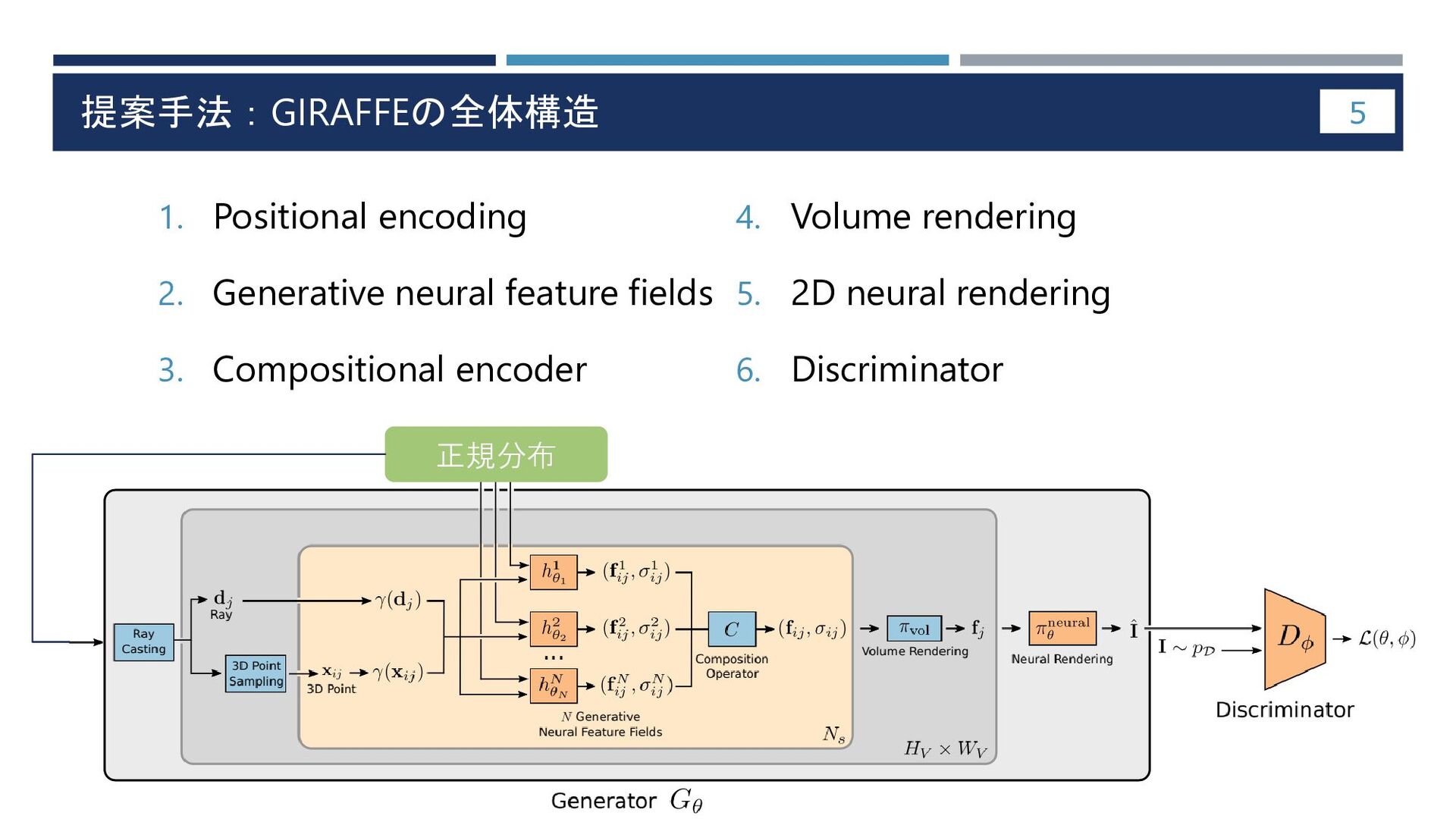
提案手法:GIRAFFEの全体構造 5 1. Positional encoding 2. Generative neural feature fields
3. Compositional encoder 4. Volume rendering 5. 2D neural rendering 6. Discriminator 正規分布
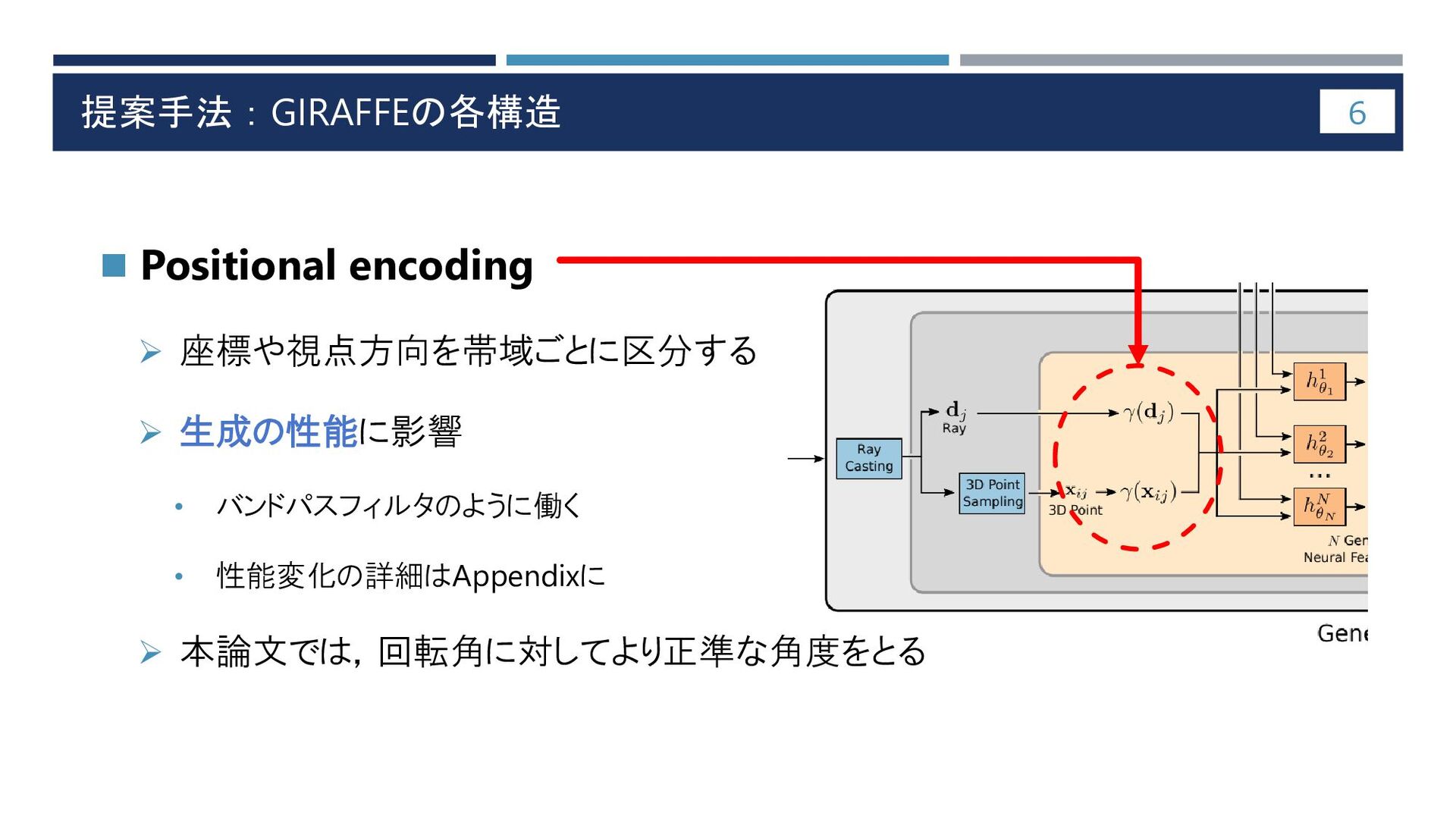
提案手法:GIRAFFEの各構造 6 ◼ Positional encoding ➢ 座標や視点方向を帯域ごとに区分する ➢ 生成の性能に影響 •
バンドパスフィルタのように働く • 性能変化の詳細はAppendixに ➢ 本論文では,回転角に対してより正準な角度をとる
提案手法:GIRAFFEの各構造 7 ◼ Generative neural feature fields ➢ 入力 •
座標𝐱・視点方向𝐝・形状𝐳𝑆 ・外観𝐳𝑎 • 初期値はすべて正規分布に従う ➢ 出力 • 体積密度𝜎(≈不透明度) • 放射輝度𝐟(≈RGB) アフィン変換によるスケール変更・移動・回転の表現 逆変換でオブジェクト固有の空間へ
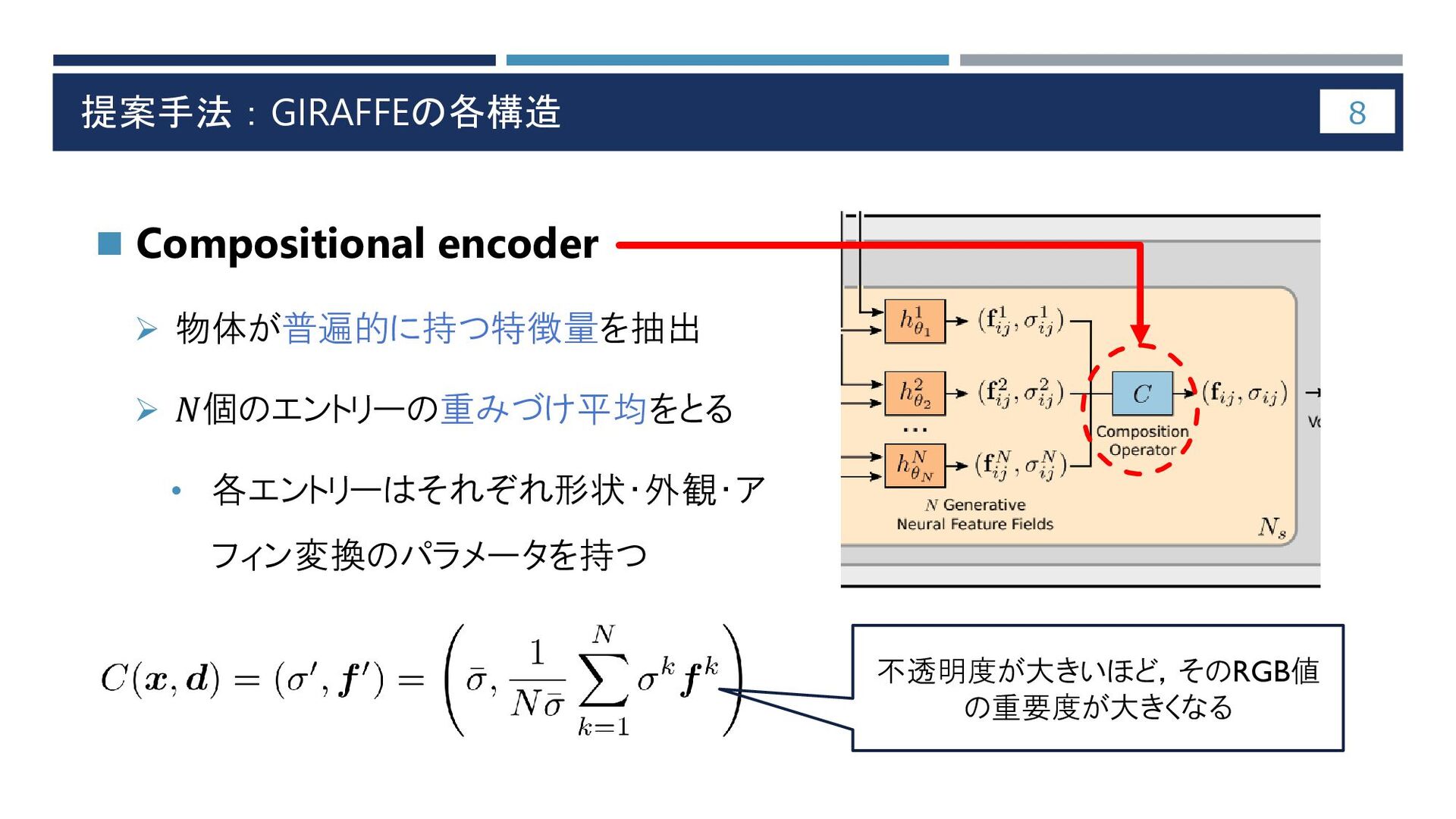
提案手法:GIRAFFEの各構造 8 ◼ Compositional encoder ➢ 物体が普遍的に持つ特徴量を抽出 ➢ 𝑁個のエントリーの重みづけ平均をとる •
各エントリーはそれぞれ形状・外観・ア フィン変換のパラメータを持つ 不透明度が大きいほど,そのRGB値 の重要度が大きくなる
提案手法:GIRAFFEの各構造 9 ◼ Volume rendering ➢ ボクセル->ピクセルの中間特徴量を出力(𝑀𝑓 次元) ➢ 𝑁𝑠
個のレイについて,それぞれ放射輝度を求める • 𝛼𝑗 は体積密度𝜎𝑗 及び𝑗 + 1番目との距離𝛿𝑗 で決まる 𝑗 − 1番目までの透明度 𝑗番目の不透明度
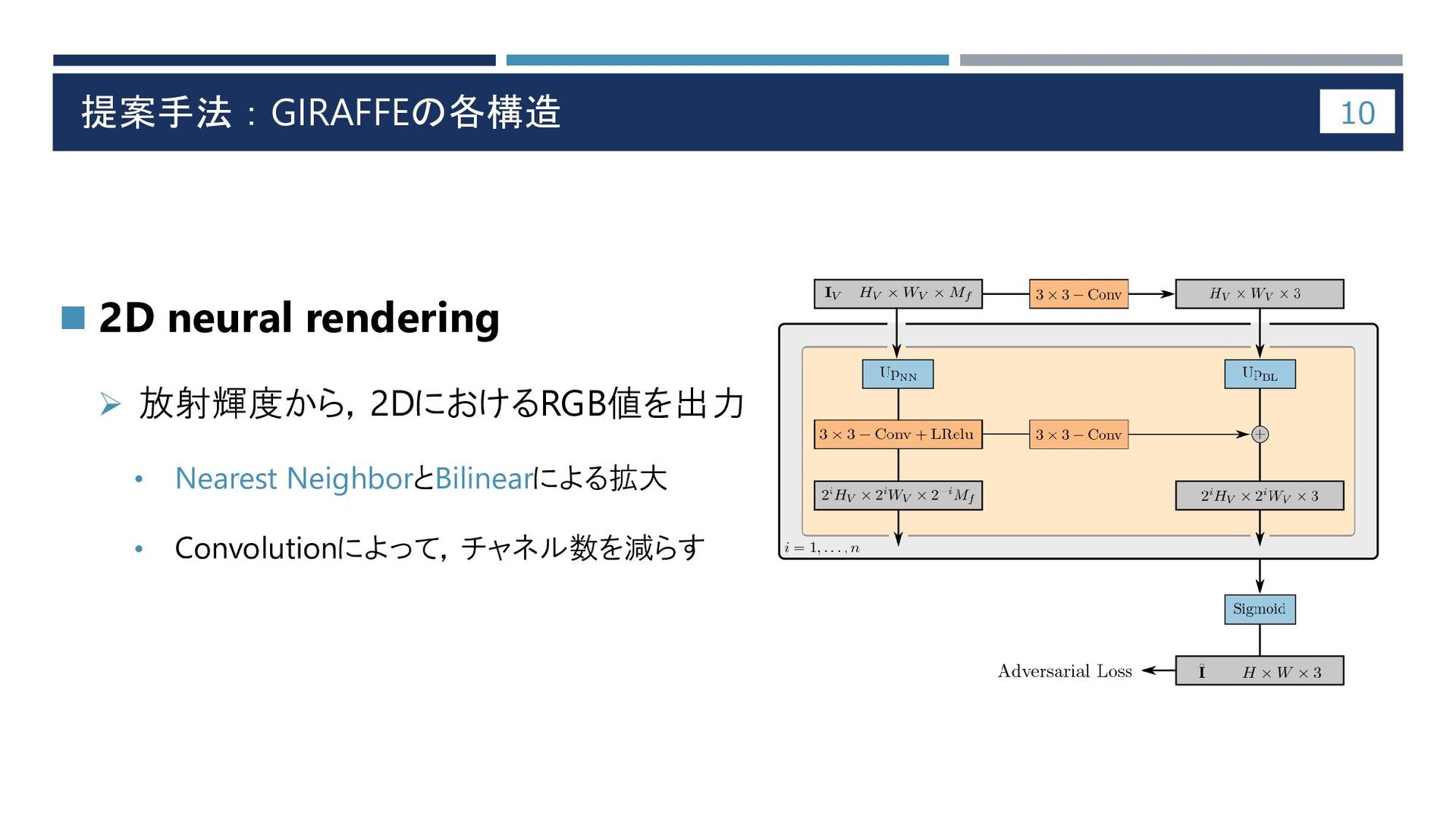
提案手法:GIRAFFEの各構造 10 ◼ 2D neural rendering ➢ 放射輝度から,2DにおけるRGB値を出力 • Nearest
NeighborとBilinearによる拡大 • Convolutionによって,チャネル数を減らす
提案手法:GIRAFFEの各構造 11 ◼ Discriminator / Generator ➢ Adversarial loss(敵対性損失)により学習 1.
識別性能𝑉を最大化するように識別器𝐷を学習 ✓ 生成画像と実画像を2値で分類 2. その中で𝑉を最小化するように生成器𝐺を学習 ✓ 識別器を騙せる画像の生成が目的 Generator
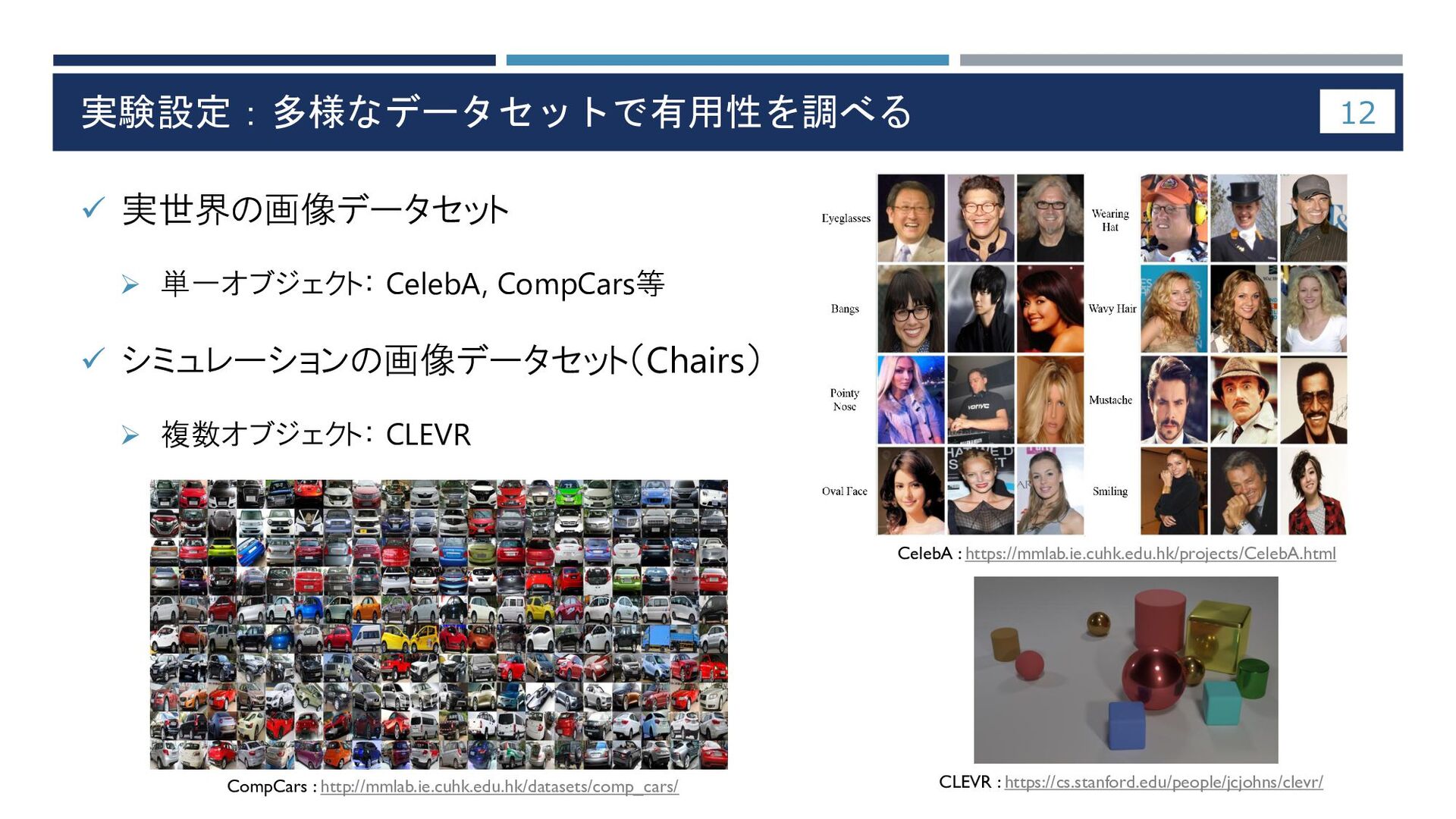
実験設定:多様なデータセットで有用性を調べる ✓ 実世界の画像データセット ➢ 単一オブジェクト: CelebA, CompCars等 ✓ シミュレーションの画像データセット(Chairs) ➢
複数オブジェクト: CLEVR 12 CelebA : https://mmlab.ie.cuhk.edu.hk/projects/CelebA.html CompCars : http://mmlab.ie.cuhk.edu.hk/datasets/comp_cars/ CLEVR : https://cs.stanford.edu/people/jcjohns/clevr/
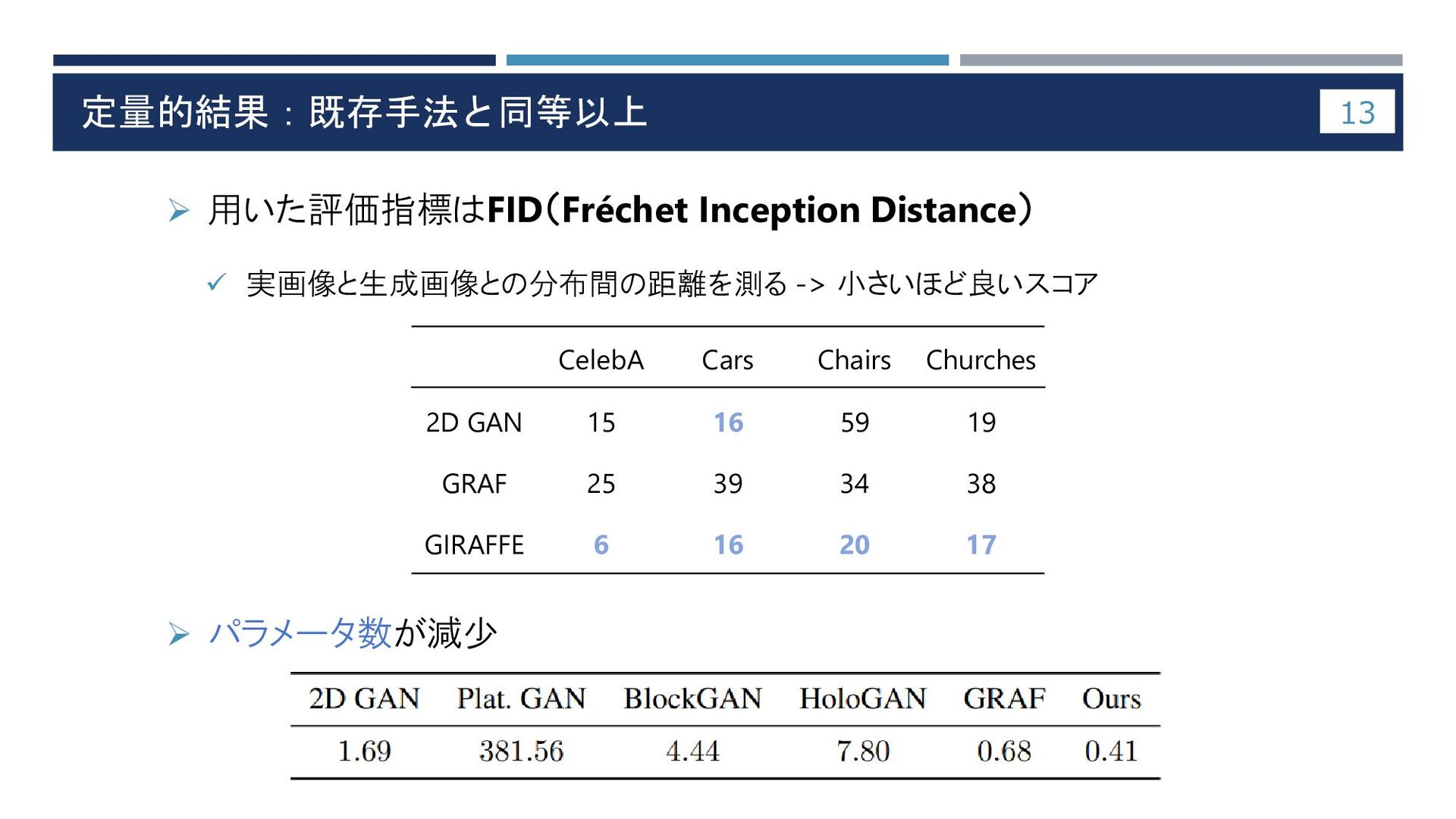
定量的結果:既存手法と同等以上 ➢ 用いた評価指標はFID(Fréchet Inception Distance) ✓ 実画像と生成画像との分布間の距離を測る -> 小さいほど良いスコア ➢
パラメータ数が減少 13 CelebA Cars Chairs Churches 2D GAN 15 16 59 19 GRAF 25 39 34 38 GIRAFFE 6 16 20 17
定性的結果:オブジェクト単位の操作を可能に ➢ 回転や移動時のゆがみが小さい ➢ 外観や形状についても変更が可能 14 更なる生成結果はプロジェクトページ下部へ https://m-niemeyer.github.io/project-pages/giraffe/index.html
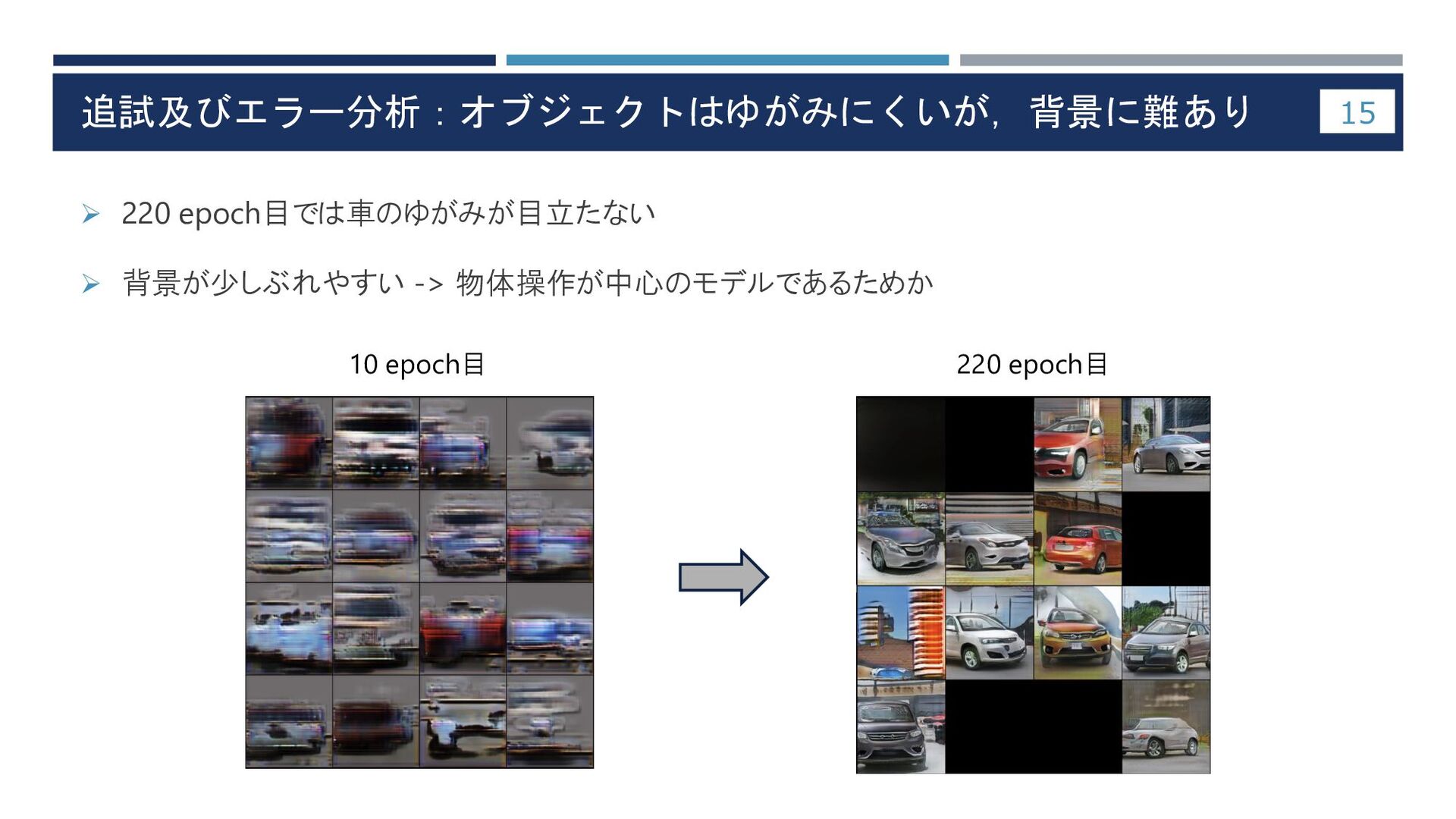
追試及びエラー分析:オブジェクトはゆがみにくいが,背景に難あり ➢ 220 epoch目では車のゆがみが目立たない ➢ 背景が少しぶれやすい -> 物体操作が中心のモデルであるためか 15 10
epoch目 220 epoch目
まとめ:GIRAFFE ◼ 教師なしの画像生成モデル ◼ 2次元画像から,物体の3次元のシーン構成をつかむ • 物体単位での移動・回転・形状・外観を操作可能に ◼ モデルの学習可能パラメータ数を削減 •
既存手法と比較して,計算量が大幅に減少 ◼ 実際に学習をしてみたところ,背景には改善点がありか 16
Appendix:Positional Encodingの有用性 17 ➢ 高周波成分を学習しやすい[Matthew+ 20] • 座標からRGB値を構成するタスクにおいて,以下に示す性能の差がみられる
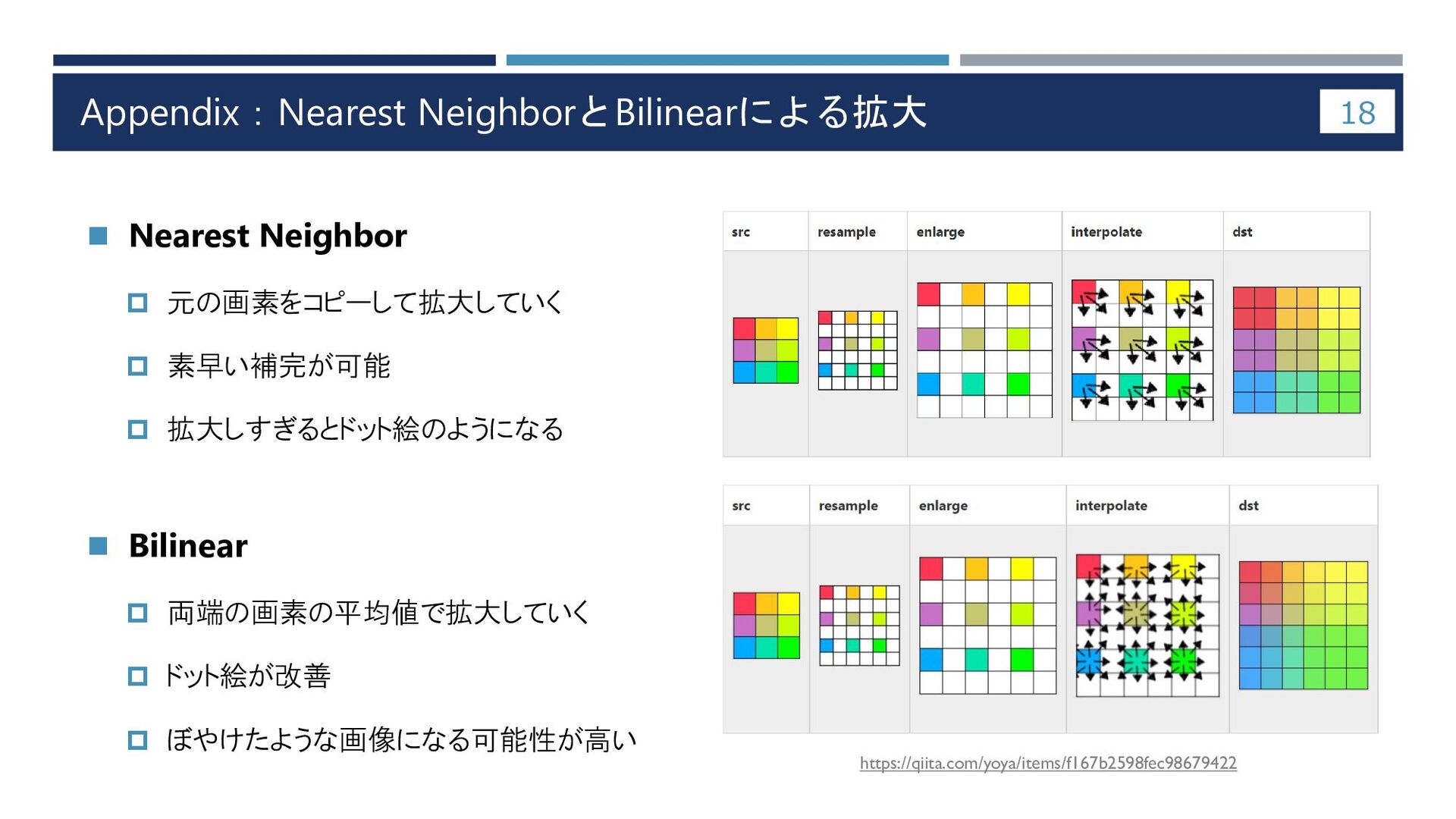
Appendix:Nearest NeighborとBilinearによる拡大 18 ◼ Nearest Neighbor 元の画素をコピーして拡大していく 素早い補完が可能
拡大しすぎるとドット絵のようになる ◼ Bilinear 両端の画素の平均値で拡大していく ドット絵が改善 ぼやけたような画像になる可能性が高い https://qiita.com/yoya/items/f167b2598fec98679422
Appendix:他手法との回転時のゆがみの違い ➢ HoloGANでは平面のように映る前方からや後方 からが苦手 ⇒ 3Dのシーン構成をつかみ切れていないためか ➢ GRAFは回転自体が不得意 ⇒ 背景とオブジェクトを同じ構成でとらえるため,
回転の難易度が高そう ➢ GIRAFFEはオブジェクトはゆがまないが,実際に背景 はかなりノイズが入った ⇒ epoch数が足りなかったか,背景への表現力も あげるべきか 19
{kind=link}
{kind=link}
{kind=link}
![関連研究:3Dのシーン構成を教師なしでつかみきれていない 4 model detail GAN [Ian+ NIPS2014] 〇教師なしでの学習 △3Dのシーン構成はブラックボックス化 NeRF](https://files.speakerdeck.com/presentations/076b612e135744cc86ea5a3d1b2971d1/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Appendix:Positional Encodingの有用性 17 ➢ 高周波成分を学習しやすい[Matthew+ 20] • 座標からRGB値を構成するタスクにおいて,以下に示す性能の差がみられる](https://files.speakerdeck.com/presentations/076b612e135744cc86ea5a3d1b2971d1/slide_16.jpg){kind=link}
{kind=link}
{kind=link}