Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
猫でもわかった気になるRedshift Serverless(更新系限定)
Search
Hiroo Katoh
August 21, 2024
Technology
5.5k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
猫でもわかった気になるRedshift Serverless(更新系限定)
本資料はRedshift Serverlessの更新処理に限定した知見についてまとめたものになります
Hiroo Katoh
August 21, 2024
More Decks by Hiroo Katoh
See All by Hiroo Katoh
Kiro CLI v2.0.0がやってきた!
kentapapa
0
340
猫でもわかるKiro CLI(CDKコーディング編)
kentapapa
1
260
今年60歳のおっさんCBになる
kentapapa
2
450
猫でもわかるKiro CLI(AI 駆動開発への道編)
kentapapa
0
570
猫でもわかるKiro CLI(セキュリティ編)
kentapapa
1
690
猫でもわかるS3 Tables(その後編)
kentapapa
1
140
猫でもわかるQ Developer CLI(できる子編)
kentapapa
2
180
猫でもわかるAmazon Q Developer CLI 解体新書
kentapapa
2
630
猫でもわかるJAWS-UG登壇発表の道標
kentapapa
0
2k
Other Decks in Technology
See All in Technology
LiDAR SLAMの実装とセンサ融合 ~Lie群からContinuous-Time LIOまで~
naokiakai
1
980
AI Driven AI Governance
pict3
0
150
AI時代のエンジニアキャリアについて今一度考える
sakamoto_582
1
1.2k
cccccc
moznion
0
1.8k
スタートアップにおけるアジャイルの実践について #shibuyagile
murabayashi
3
2.1k
Claude Code 珍プレー好プレー
shinyasaita
0
270
なぜ人は自分のプロジェクトを 「なんちゃってアジャイル」と 自嘲するのか
kozotaira
0
260
最近評価が難しくなった
maroon8021
0
250
FinOps X 2026 Recap from Engineer Side #JapanFinOps
chacco38
0
260
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
390
そのタスクオンスケですか?
poropinai1966
0
140
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.3k
Featured
See All Featured
Color Theory Basics | Prateek | Gurzu
gurzu
0
380
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
330
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
Ruling the World: When Life Gets Gamed
codingconduct
0
270
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
210
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
150
The browser strikes back
jonoalderson
0
1.4k
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
410
Art, The Web, and Tiny UX
lynnandtonic
304
22k
Become a Pro
speakerdeck
PRO
31
6k
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.6k
Transcript
© 2024 NTT TechnoCross Corporation JAWS-UG 朝会 #60 【更新系限定】 猫でもわかった気になるRedshift
Serverless 2024/08/22 NTTテクノクロス株式会社 加藤 洋雄
2 © 2024 NTT TechnoCross Corporation 目次 1. はじめに 2.
結論 3. Redshift概要 4. Provisioned版概要 5. Serverless版でデータ分析に専念 6. Redshift Serverless版概要 7. 更新処理時RPU値の割当観測結果の事例 8. Serverless版サブネットの必要な空きIPアドレス 9. 疑問があるなら確認してみよう! 10.基本RPU値の設定変更時の観測結果事例 11.Redshift 更新処理 基本の「キ」 12.さいごに 13.告知 このマークがある頁は 駆け足で説明します
3 © 2024 NTT TechnoCross Corporation • NTTテクノクロス株式会社在籍 AWS業務歴約4年 加藤
洋雄 (X:@kamogashira) • AWS認定資格 2024 Japan AWS All Certifications Engineers+1 • JAWS-UG 朝会 発表履歴(今回やっとセッション枠で発表できるぐらいになりました) 2023年2月#42 LT: 猫でもわかるDirectConnect(更新版を2023/12 Qiitaに投稿) 2024年2月#54 LT: 猫でもわかるBLEA (更新版を2024/7 Qiitaに投稿) • 最近嬉しかったこと 「猫でもわかるBLEA」Qiita記事をXで宣伝したらAWS JAPAN BLEA開発者の高野さんに 「いいね」してもらったこと。 • うさぎのけんた(ネザーランドドワーフ)の飼い主 自己紹介
4 © 2024 NTT TechnoCross Corporation 1.はじめに 本資料は私が2023年11月から2024年3月末まで担当した業務を通じて得たRedshift Serverlessの更新処理に限定した知見についてまとめたものになります。
注意事項 本資料はあくまでも筆者が実際に構築した環境において観測した情報を元にしています。 そのため限定された条件での情報であり、他の条件では参考にならない可能性があります。 上記ご理解の上、あくまでも参考情報と思ってください。 本資料では私が独自に推測した記載が含まれます。推測箇所には赤字で 【推測】と記載してあります。 補足 ベース容量はDWHのワークロードを処理するために使用するベース容量を設定。 本資料では、Redshift Serverlessの「ベース容量」、「基本容量」をRPU値を現すこと が直感的に伝わるように「基本RPU」と記載します。(PRUについては資料内にて説明) 「基本RPU」 「ベース容量」 「基本容量」
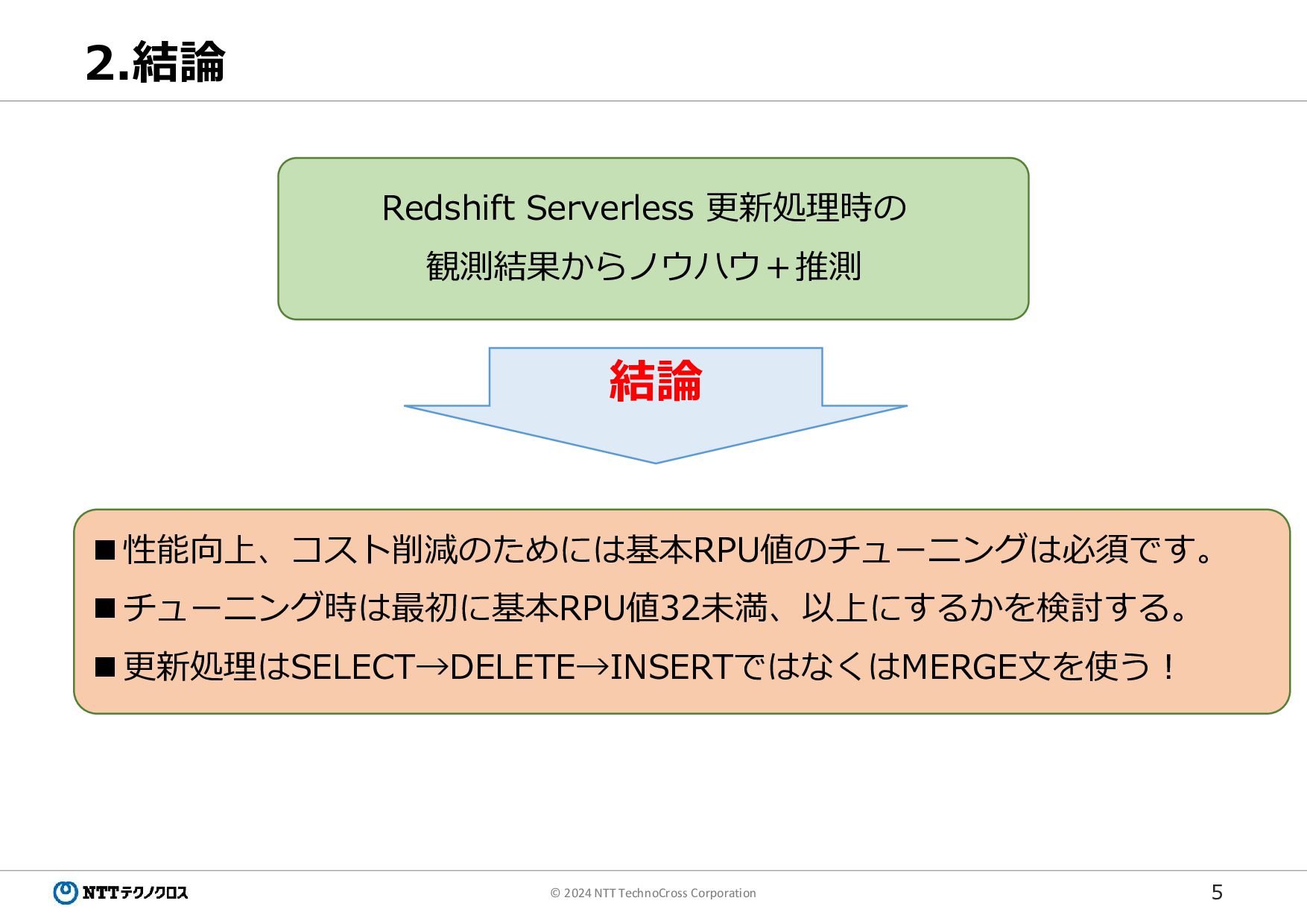
5 © 2024 NTT TechnoCross Corporation 2.結論 性能向上、コスト削減のためには基本RPU値のチューニングは必須です。
チューニング時は最初に基本RPU値32未満、以上にするかを検討する。 更新処理はSELECT→DELETE→INSERTではなくはMERGE文を使う! 結論 Redshift Serverless 更新処理時の 観測結果からノウハウ+推測
6 © 2024 NTT TechnoCross Corporation 3.Redshift概要(その1) 高速、スケーラブルで費用対効果の高いデータウェアハウス(DWH)、データレイク分析基盤。
DWHの分析クエリは大量のレコード中少数の列だけを読みだす。 (だいたいのデータ規模目安:数百GB~数PB) 書込み:レコード中の更新した列の追加書込み、または大量データの一括インポート。 Provisioned版とServerless版(東京リージョン2022年7月GA)がある。大阪リージョンは 2024年8月時点で未GAです(★大阪リージョンにディザスタリカバリ環境構築時は要注意)。 AWS BlackBelt資料抜粋:https://pages.awscloud.com/rs/112-TZM-766/images/20200318_AWS_BlackBelt_Redshift.pdf
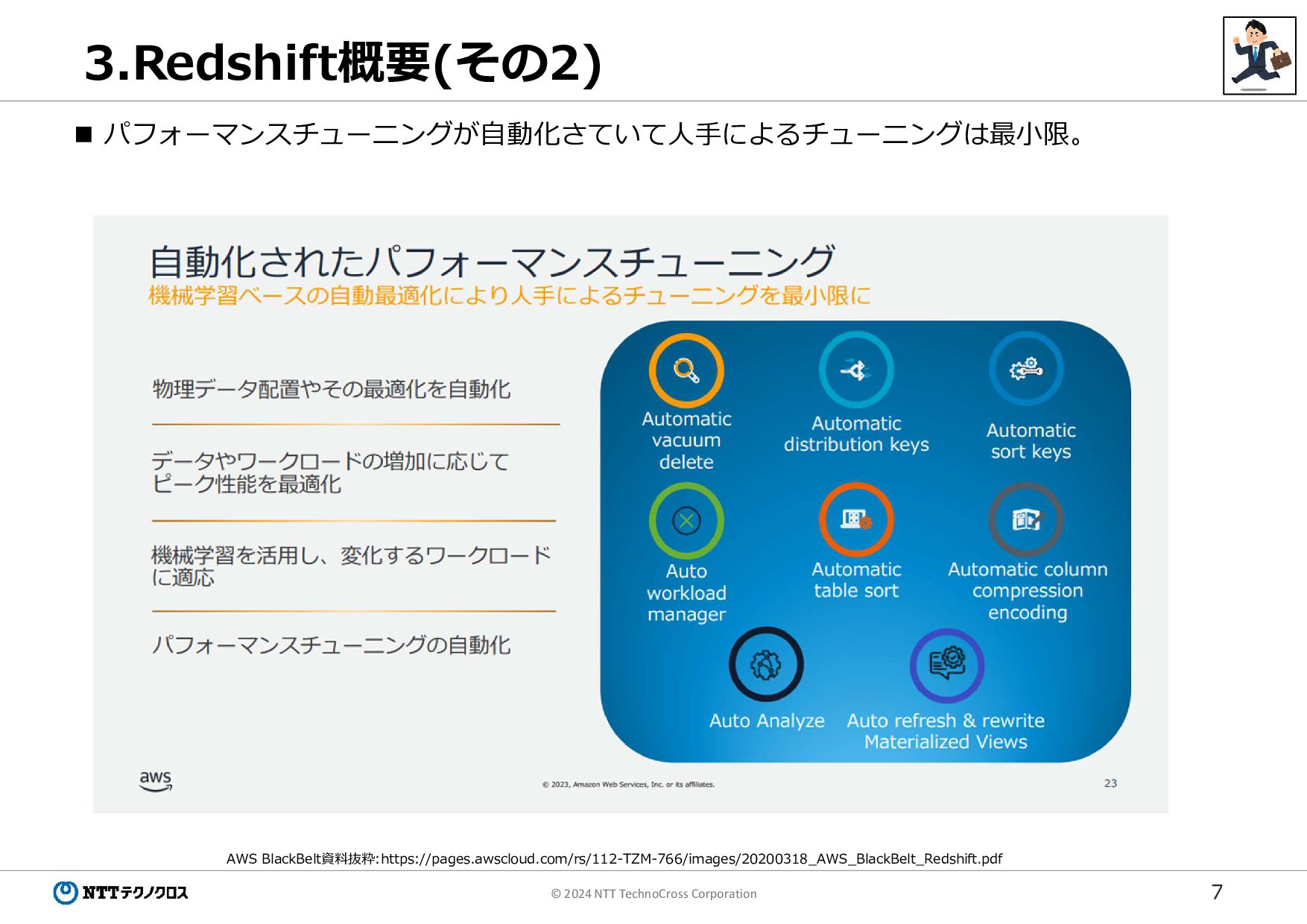
7 © 2024 NTT TechnoCross Corporation 3.Redshift概要(その2) パフォーマンスチューニングが自動化さていて人手によるチューニングは最小限。 AWS
BlackBelt資料抜粋:https://pages.awscloud.com/rs/112-TZM-766/images/20200318_AWS_BlackBelt_Redshift.pdf
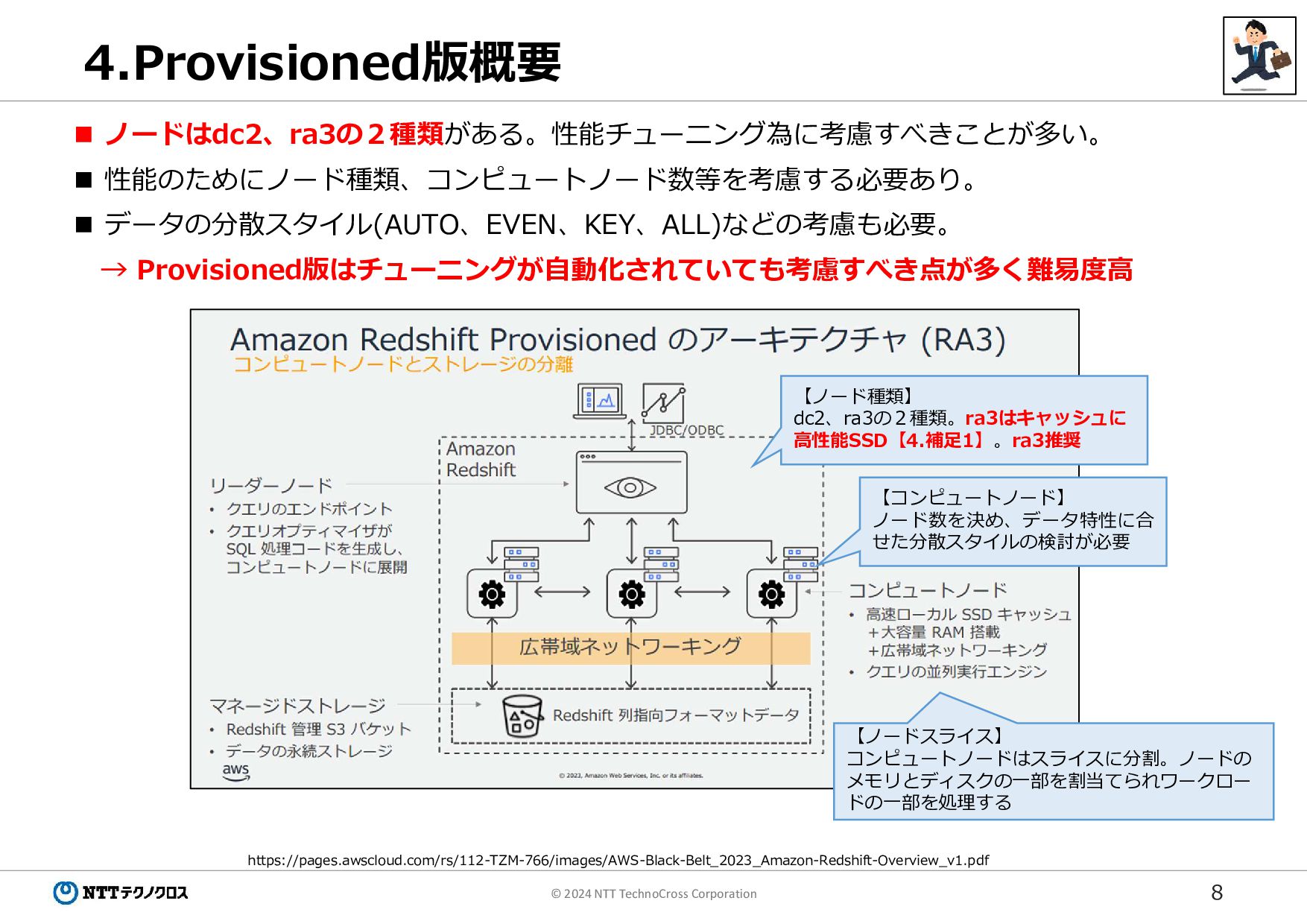
8 © 2024 NTT TechnoCross Corporation 4.Provisioned版概要 ノードはdc2、ra3の2種類がある。性能チューニング為に考慮すべきことが多い。
性能のためにノード種類、コンピュートノード数等を考慮する必要あり。 データの分散スタイル(AUTO、EVEN、KEY、ALL)などの考慮も必要。 → Provisioned版はチューニングが自動化されていても考慮すべき点が多く難易度高 https://pages.awscloud.com/rs/112-TZM-766/images/AWS-Black-Belt_2023_Amazon-Redshift-Overview_v1.pdf 【ノード種類】 dc2、ra3の2種類。ra3はキャッシュに 高性能SSD【4.補足1】。ra3推奨 【コンピュートノード】 ノード数を決め、データ特性に合 せた分散スタイルの検討が必要 【ノードスライス】 コンピュートノードはスライスに分割。ノードの メモリとディスクの一部を割当てられワークロー ドの一部を処理する
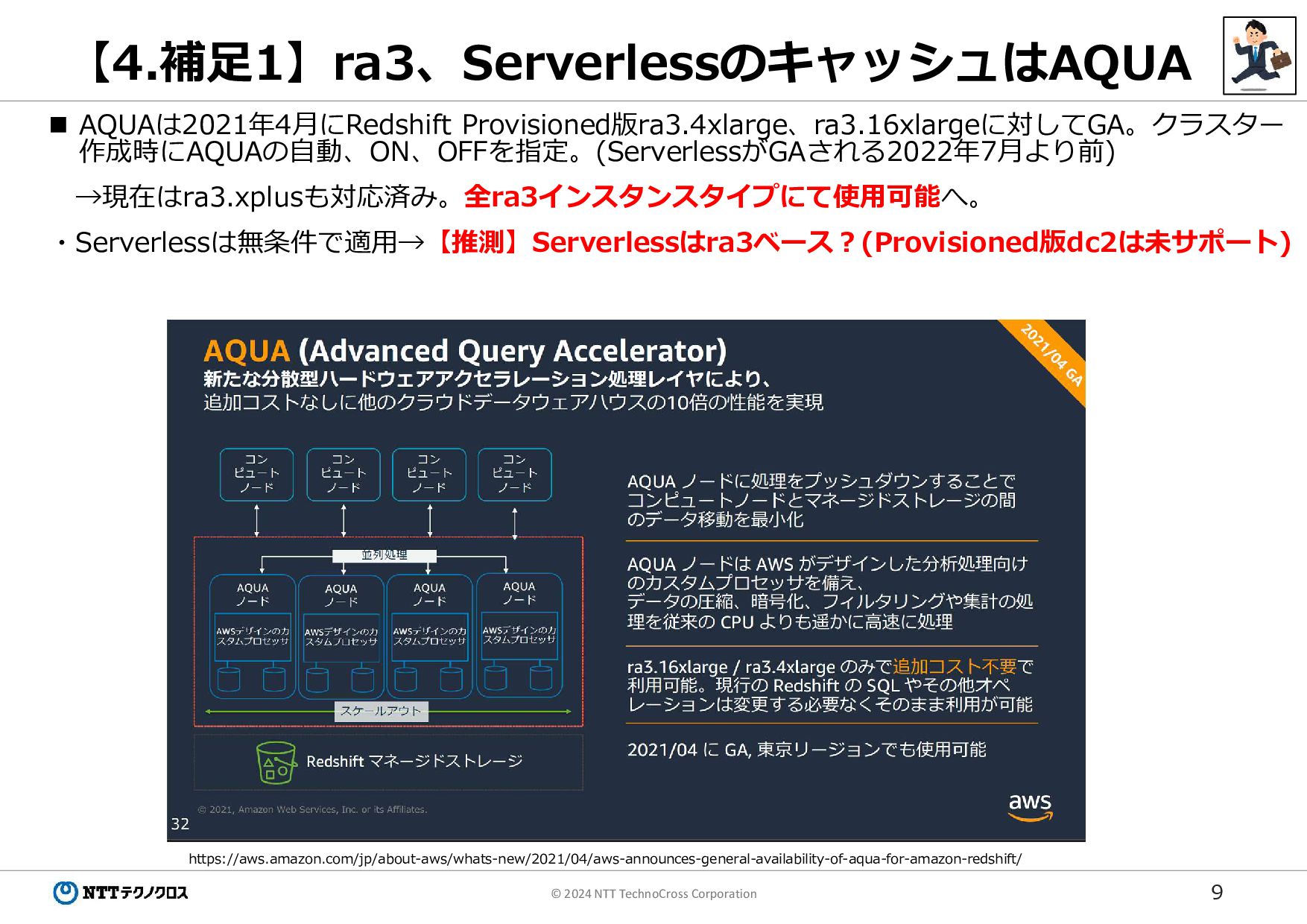
9 © 2024 NTT TechnoCross Corporation 【4.補足1】ra3、ServerlessのキャッシュはAQUA https://aws.amazon.com/jp/about-aws/whats-new/2021/04/aws-announces-general-availability-of-aqua-for-amazon-redshift/ AQUAは2021年4月にRedshift
Provisioned版ra3.4xlarge、ra3.16xlargeに対してGA。クラスター 作成時にAQUAの自動、ON、OFFを指定。(ServerlessがGAされる2022年7月より前) →現在はra3.xplusも対応済み。全ra3インスタンスタイプにて使用可能へ。 ・Serverlessは無条件で適用→【推測】Serverlessはra3ベース?(Provisioned版dc2は未サポート)
10 © 2024 NTT TechnoCross Corporation 5.Serverless版でデータ分析に専念 Redshift Serverless! インフラはあまり考えないで
データ分析に専念したい! それなら
11 © 2024 NTT TechnoCross Corporation 6.Redshift Serverless版概要(その1) Serverlessのシステム構成はブラックボックス。チューニング可能なのは基本RPU
(Redshift Processing Unit)値だけ。使った分だけ時間課金(秒単位。最低料金時間は60秒) 1RPUあたり16GBのメモリが提供される。 (※16GBのメモリがシステム構成的にどこに割り当てられかの説明はマニュアル上記載無し) RPU値を大きく設定することで、特に大量のリソースを消費するデータ処理ジョブでは、クエリ のパフォーマンスが向上する。 Redshift Serverless https://pages.awscloud.com/rs/112-TZM-766/images/AWS-Black-Belt_2023_Amazon-Redshift-Overview_v1.pdf アーキテクチャは ブラックボックス
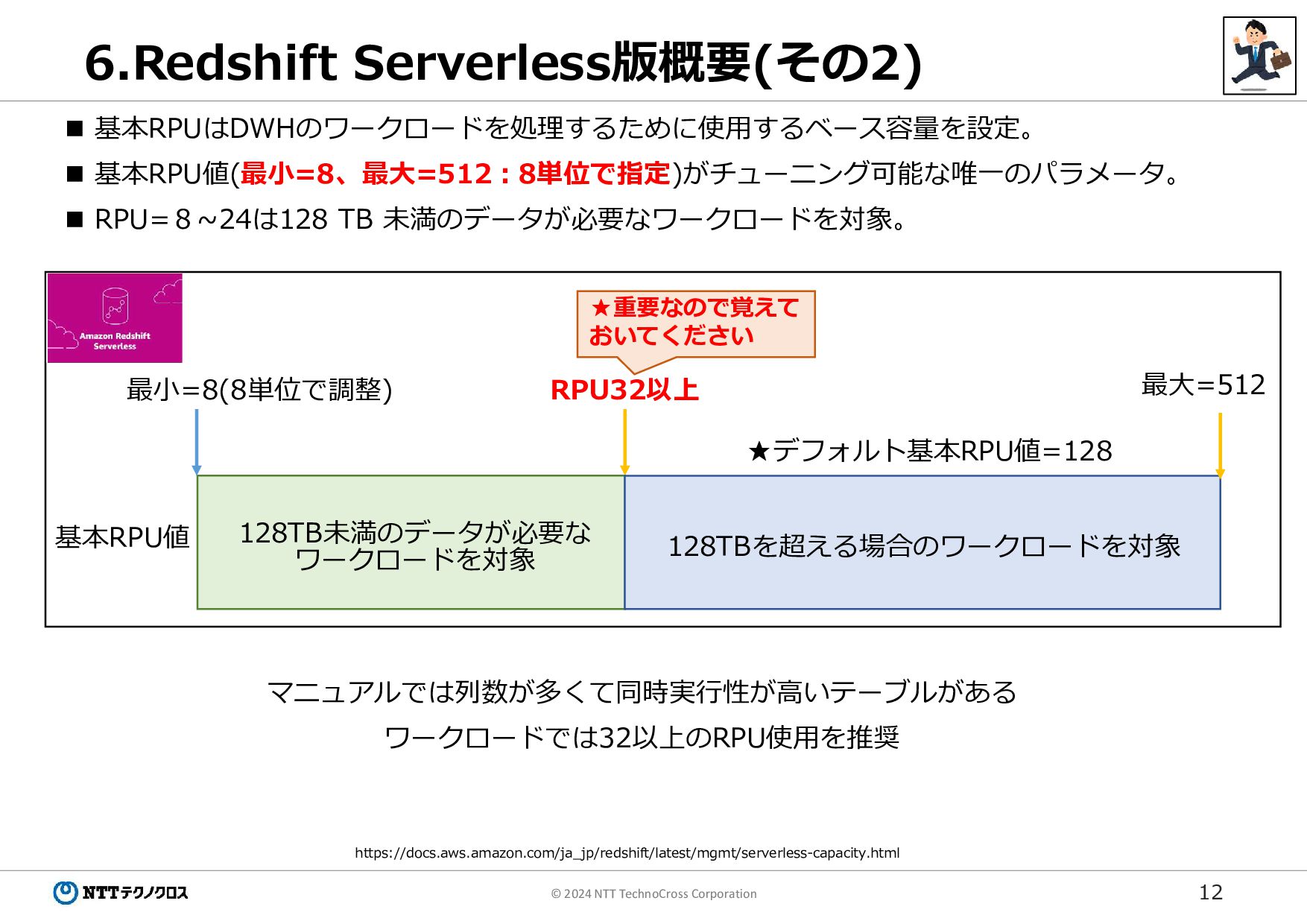
12 © 2024 NTT TechnoCross Corporation 6.Redshift Serverless版概要(その2) 基本RPUはDWHのワークロードを処理するために使用するベース容量を設定。
基本RPU値(最小=8、最大=512:8単位で指定)がチューニング可能な唯一のパラメータ。 RPU=8~24は128 TB 未満のデータが必要なワークロードを対象。 https://docs.aws.amazon.com/ja_jp/redshift/latest/mgmt/serverless-capacity.html 最小=8(8単位で調整) 最大=512 ★デフォルト基本RPU値=128 基本RPU値 128TB未満のデータが必要な ワークロードを対象 128TBを超える場合のワークロードを対象 RPU32以上 マニュアルでは列数が多くて同時実行性が高いテーブルがある ワークロードでは32以上のRPU使用を推奨 ★重要なので覚えて おいてください
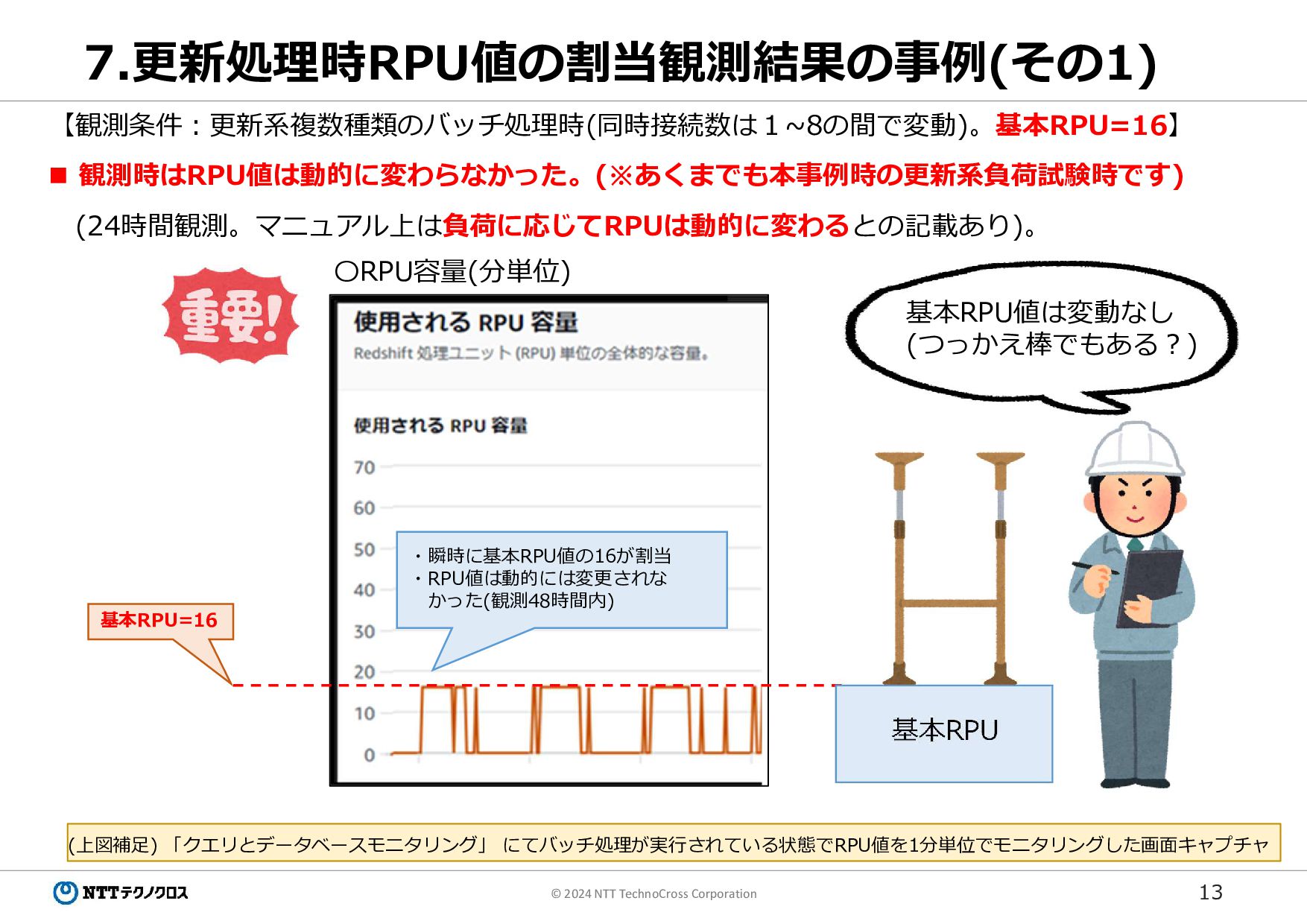
13 © 2024 NTT TechnoCross Corporation 7.更新処理時RPU値の割当観測結果の事例(その1) 【観測条件:更新系複数種類のバッチ処理時(同時接続数は1~8の間で変動)。基本RPU=16】 観測時はRPU値は動的に変わらなかった。(※あくまでも本事例時の更新系負荷試験時です)
(24時間観測。マニュアル上は負荷に応じてRPUは動的に変わるとの記載あり)。 (上図補足) 「クエリとデータベースモニタリング」 にてバッチ処理が実行されている状態でRPU値を1分単位でモニタリングした画面キャプチャ ・瞬時に基本RPU値の16が割当 ・RPU値は動的には変更されな かった(観測48時間内) 〇RPU容量(分単位) 基本RPU=16 基本RPU 基本RPU値は変動なし (つっかえ棒でもある?)
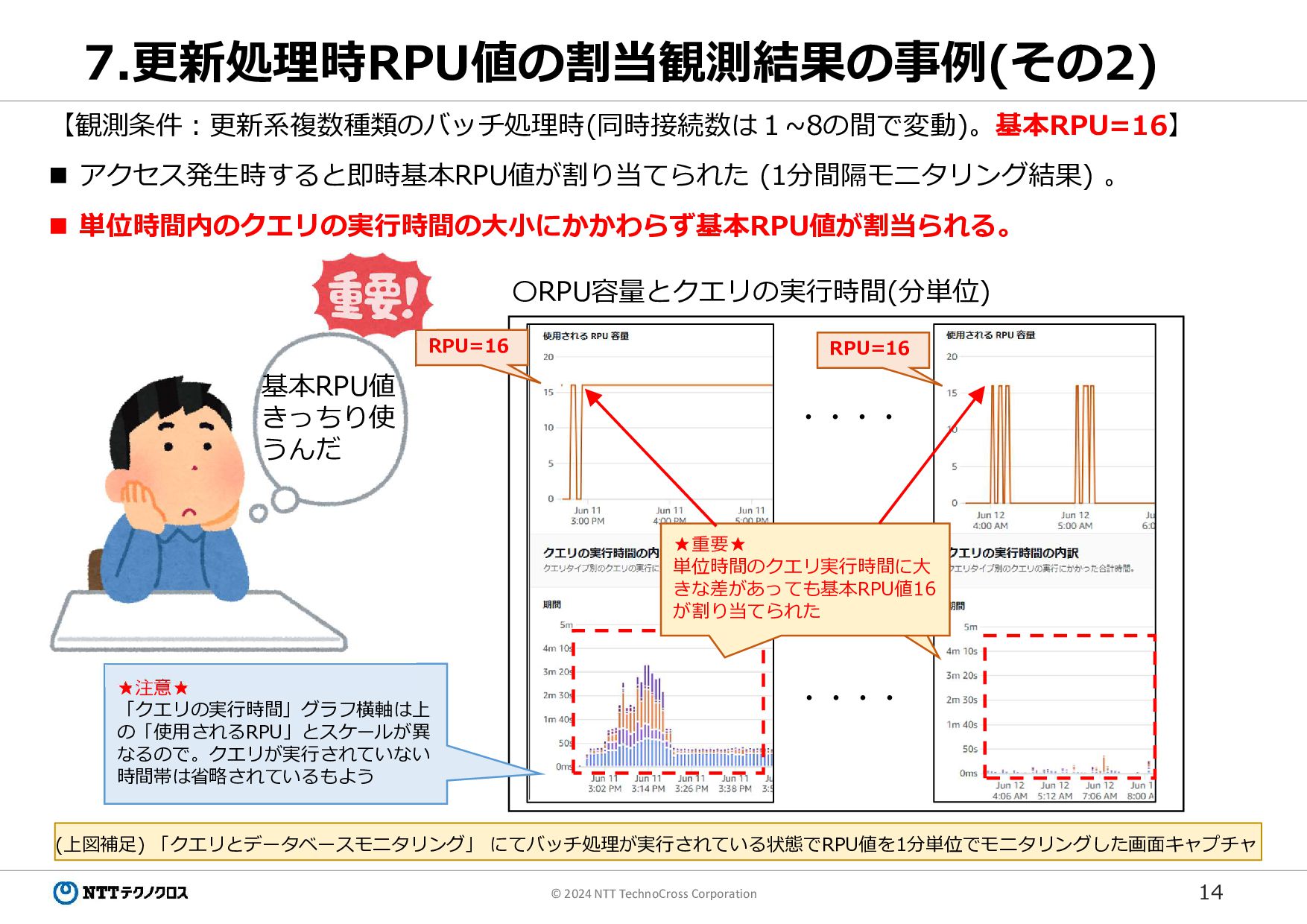
14 © 2024 NTT TechnoCross Corporation 7.更新処理時RPU値の割当観測結果の事例(その2) 【観測条件:更新系複数種類のバッチ処理時(同時接続数は1~8の間で変動)。基本RPU=16】 アクセス発生時すると即時基本RPU値が割り当てられた
(1分間隔モニタリング結果) 。 単位時間内のクエリの実行時間の大小にかかわらず基本RPU値が割当られる。 〇RPU容量とクエリの実行時間(分単位) ・・・・ ・・・・ ★重要★ 単位時間のクエリ実行時間に大 きな差があっても基本RPU値16 が割り当てられた RPU=16 RPU=16 ★注意★ 「クエリの実行時間」グラフ横軸は上 の「使用されるRPU」とスケールが異 なるので。クエリが実行されていない 時間帯は省略されているもよう (上図補足) 「クエリとデータベースモニタリング」 にてバッチ処理が実行されている状態でRPU値を1分単位でモニタリングした画面キャプチャ 基本RPU値 きっちり使 うんだ
15 © 2024 NTT TechnoCross Corporation 8.Serverless版サブネットの必要な空きIPアドレス AWSマニュアル(容量計算):https://docs.aws.amazon.com/ja_jp/redshift/latest/mgmt/serverless-capacity.html AWS マニュアル資料抜粋:https://docs.aws.amazon.com/ja_jp/redshift/latest/mgmt/serverless-usage-considerations.html
〇マニュアル抜粋 VPC endpointとは別にRedshiftNetworkInterface(ENI)が基本RPU値に合わせて自動作成される。 (★CIDR設計時は要注意) 本事例ではENIは1AZにまとめて作成された。またその数は動的に変わった。 (初期構築後アクセスが無い時は1まで減少。定常的アクセスがある場合はある程度の値で固定) 〇RPU16での実際の構築後のendpoint、ENIの例 必要な空きIPアドレスが無 いと構築時にエラー発生 ・構築後にアクセスが無いとENIの数は減少。 ・単一AZに配置。 RPU値に合せ て増えていく
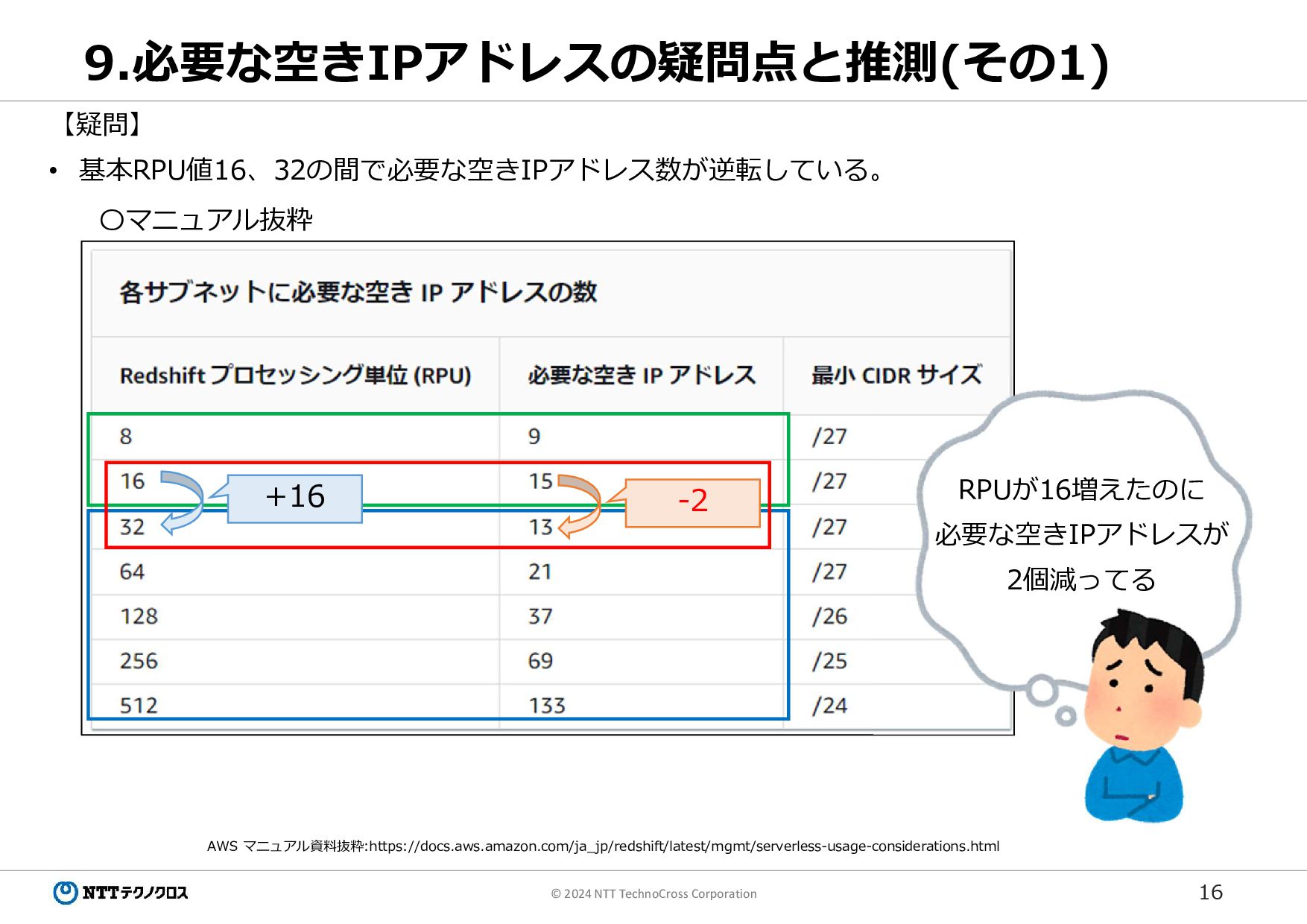
16 © 2024 NTT TechnoCross Corporation 9.必要な空きIPアドレスの疑問点と推測(その1) AWS マニュアル資料抜粋:https://docs.aws.amazon.com/ja_jp/redshift/latest/mgmt/serverless-usage-considerations.html 【疑問】
• 基本RPU値16、32の間で必要な空きIPアドレス数が逆転している。 〇マニュアル抜粋 RPUが16増えたのに 必要な空きIPアドレスが 2個減ってる +16 -2
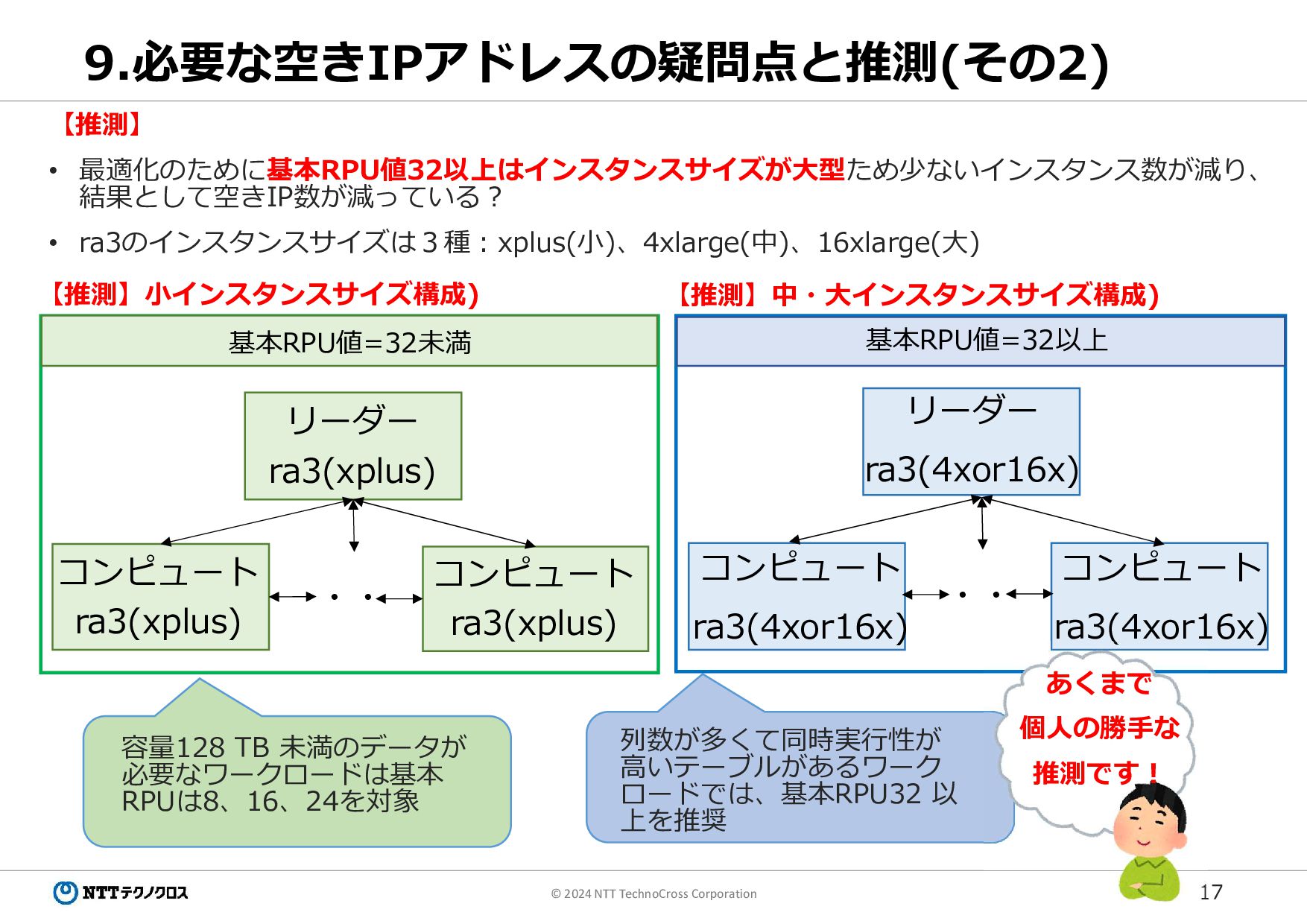
17 © 2024 NTT TechnoCross Corporation 9.必要な空きIPアドレスの疑問点と推測(その2) 【推測】 • 最適化のために基本RPU値32以上はインスタンスサイズが大型ため少ないインスタンス数が減り、
結果として空きIP数が減っている? • ra3のインスタンスサイズは3種:xplus(小)、4xlarge(中)、16xlarge(大) 【推測】小インスタンスサイズ構成) 【推測】中・大インスタンスサイズ構成) ・・ コンピュート ra3(xplus) リーダー ra3(xplus) リーダー ra3(4xor16x) コンピュート ra3(xplus) コンピュート ra3(4xor16x) コンピュート ra3(4xor16x) あくまで 個人の勝手な 推測です! ・・ 容量128 TB 未満のデータが 必要なワークロードは基本 RPUは8、16、24を対象 列数が多くて同時実行性が 高いテーブルがあるワーク ロードでは、基本RPU32 以 上を推奨 基本RPU値=32未満 基本RPU値=32以上
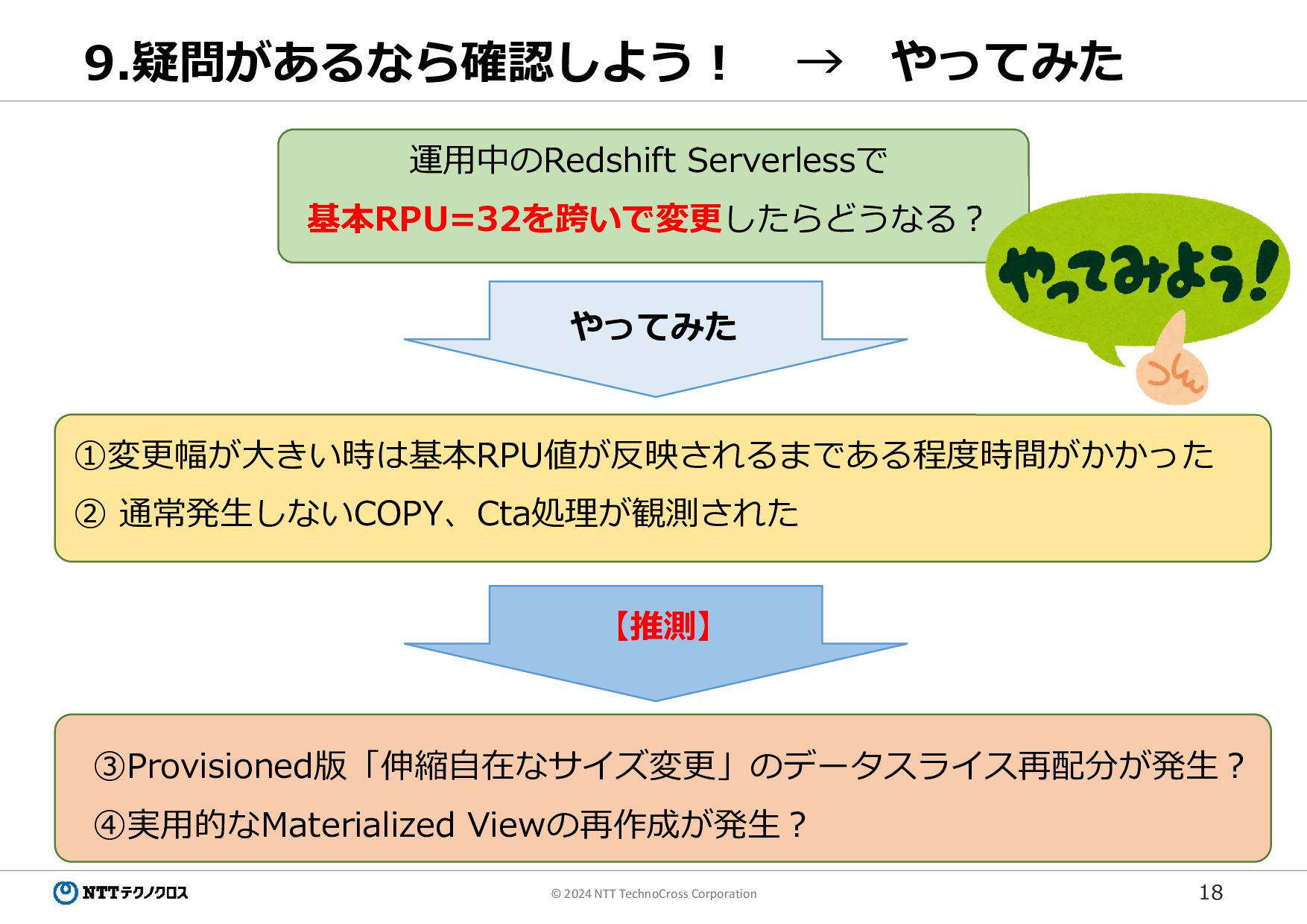
18 © 2024 NTT TechnoCross Corporation 9.疑問があるなら確認しよう! 運用中のRedshift Serverlessで 基本RPU=32を跨いで変更したらどうなる?
やってみた ①変更幅が大きい時は基本RPU値が反映されるまである程度時間がかかった ② 通常発生しないCOPY、Cta処理が観測された ③Provisioned版「伸縮自在なサイズ変更」のデータスライス再配分が発生? ④実用的なMaterialized Viewの再作成が発生? 【推測】 → やってみた
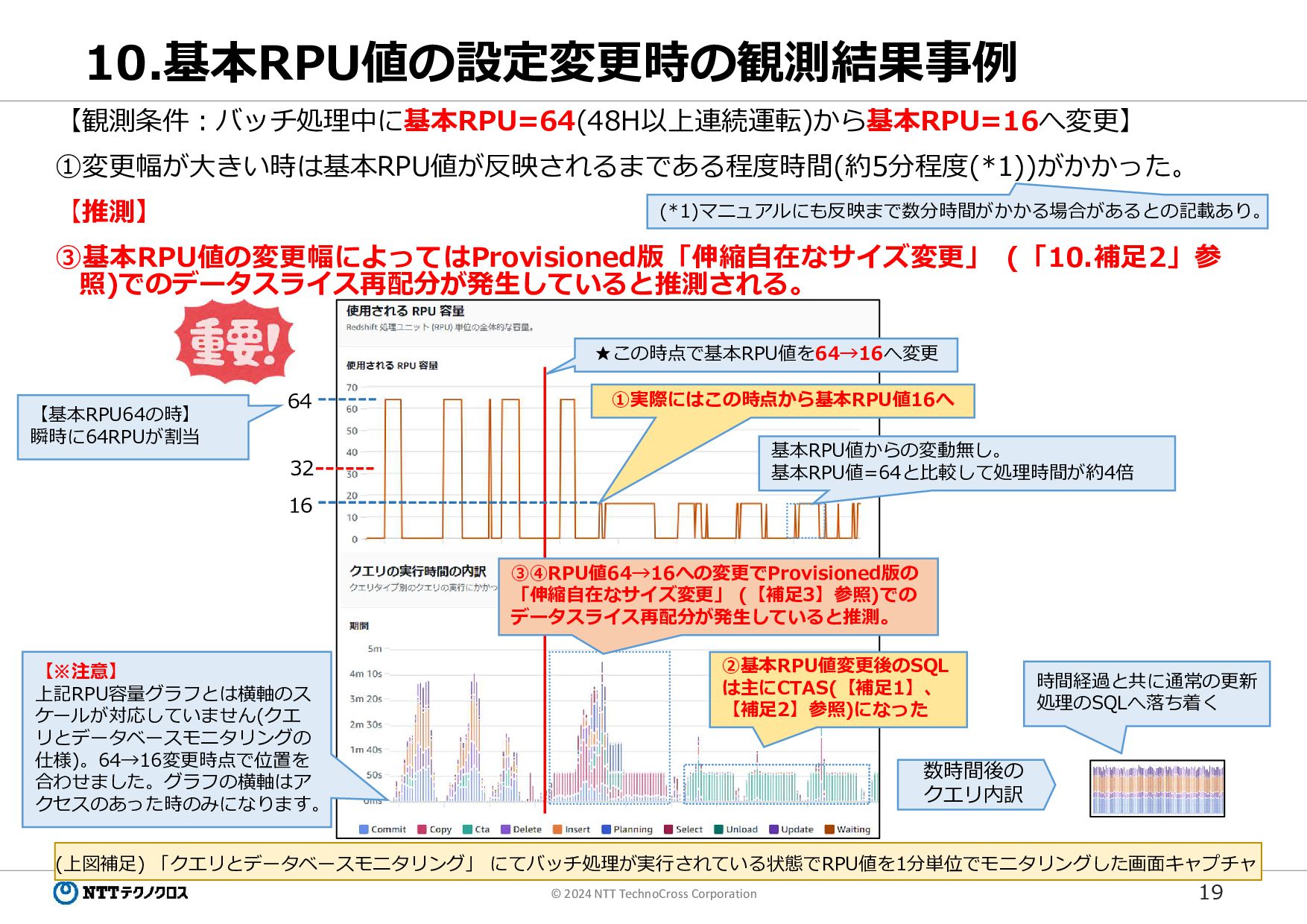
19 © 2024 NTT TechnoCross Corporation 10.基本RPU値の設定変更時の観測結果事例 【観測条件:バッチ処理中に基本RPU=64(48H以上連続運転)から基本RPU=16へ変更】 ①変更幅が大きい時は基本RPU値が反映されるまである程度時間(約5分程度(*1))がかかった。 【推測】
③基本RPU値の変更幅によってはProvisioned版「伸縮自在なサイズ変更」 (「10.補足2」参 照)でのデータスライス再配分が発生していると推測される。 ★この時点で基本RPU値を64→16へ変更 ①実際にはこの時点から基本RPU値16へ 基本RPU値からの変動無し。 基本RPU値=64と比較して処理時間が約4倍 ③④RPU値64→16への変更でProvisioned版の 「伸縮自在なサイズ変更」 (【補足3】参照)での データスライス再配分が発生していると推測。 ②基本RPU値変更後のSQL は主にCTAS(【補足1】、 【補足2】参照)になった 【※注意】 上記RPU容量グラフとは横軸のス ケールが対応していません(クエ リとデータベースモニタリングの 仕様)。64→16変更時点で位置を 合わせました。グラフの横軸はア クセスのあった時のみになります。 数時間後の クエリ内訳 時間経過と共に通常の更新 処理のSQLへ落ち着く 【基本RPU64の時】 瞬時に64RPUが割当 (*1)マニュアルにも反映まで数分時間がかかる場合があるとの記載あり。 (上図補足) 「クエリとデータベースモニタリング」 にてバッチ処理が実行されている状態でRPU値を1分単位でモニタリングした画面キャプチャ 32 16 64
20 © 2024 NTT TechnoCross Corporation 【10.補足1】CTAS(Create Table As Select)
AthenaでのCTAS説明:https://pages.awscloud.com/rs/112-TZM-766/images/20200617_BlackBelt_Amazon_Athena.pdf RPU値変更直後に行われているCtaとは、クエリ結果をもとに新しいテーブルを作成する処理。 【推測】 本事例では更新時の検索ベースにMaterialized View (「10.補足2」参照)を作成と推測。
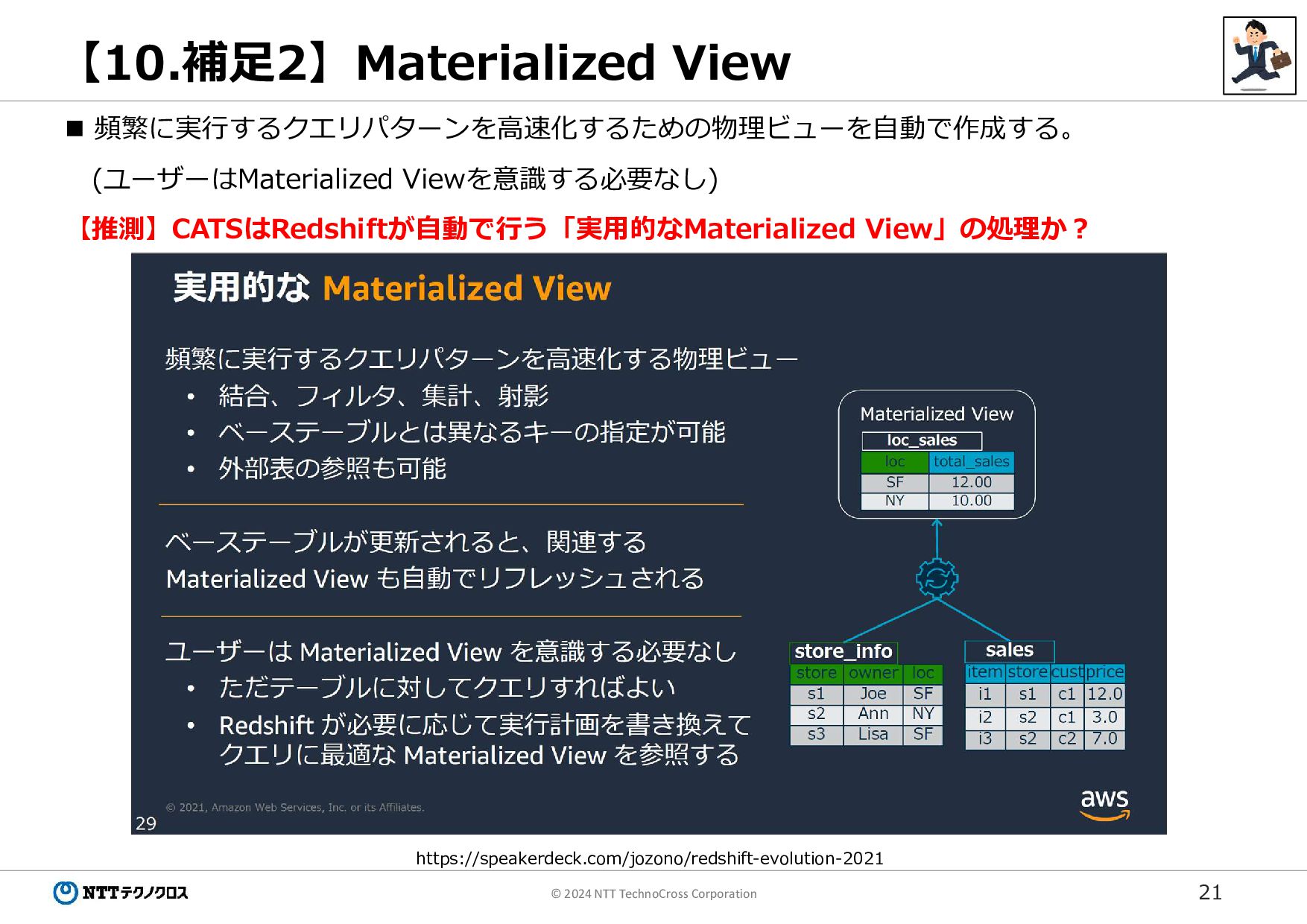
21 © 2024 NTT TechnoCross Corporation 【10.補足2】Materialized View https://speakerdeck.com/jozono/redshift-evolution-2021
頻繁に実行するクエリパターンを高速化するための物理ビューを自動で作成する。 (ユーザーはMaterialized Viewを意識する必要なし) 【推測】CATSはRedshiftが自動で行う「実用的なMaterialized View」の処理か?
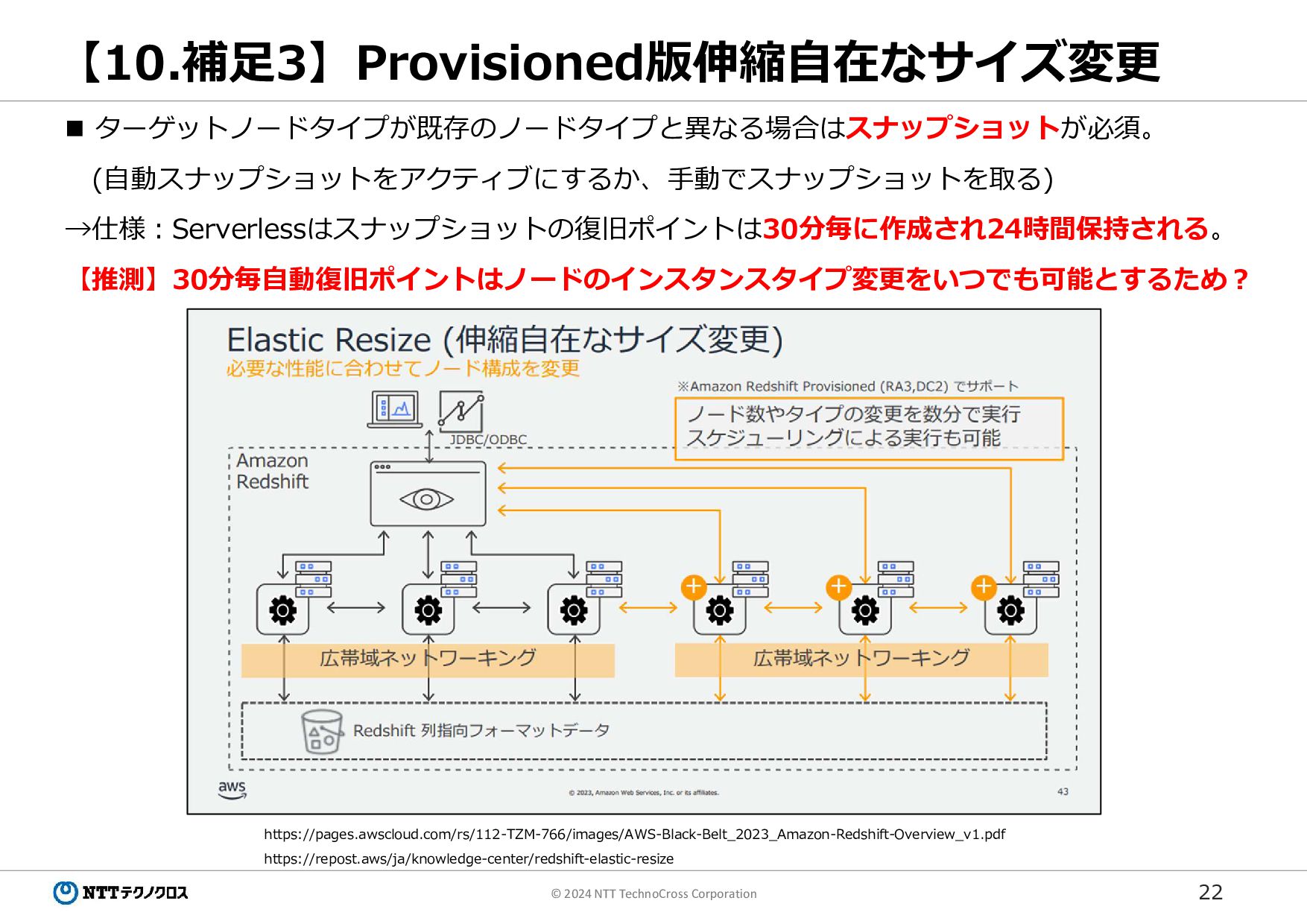
22 © 2024 NTT TechnoCross Corporation 【10.補足3】Provisioned版伸縮自在なサイズ変更 https://pages.awscloud.com/rs/112-TZM-766/images/AWS-Black-Belt_2023_Amazon-Redshift-Overview_v1.pdf https://repost.aws/ja/knowledge-center/redshift-elastic-resize
ターゲットノードタイプが既存のノードタイプと異なる場合はスナップショットが必須。 (自動スナップショットをアクティブにするか、手動でスナップショットを取る) →仕様:Serverlessはスナップショットの復旧ポイントは30分毎に作成され24時間保持される。 【推測】30分毎自動復旧ポイントはノードのインスタンスタイプ変更をいつでも可能とするため?
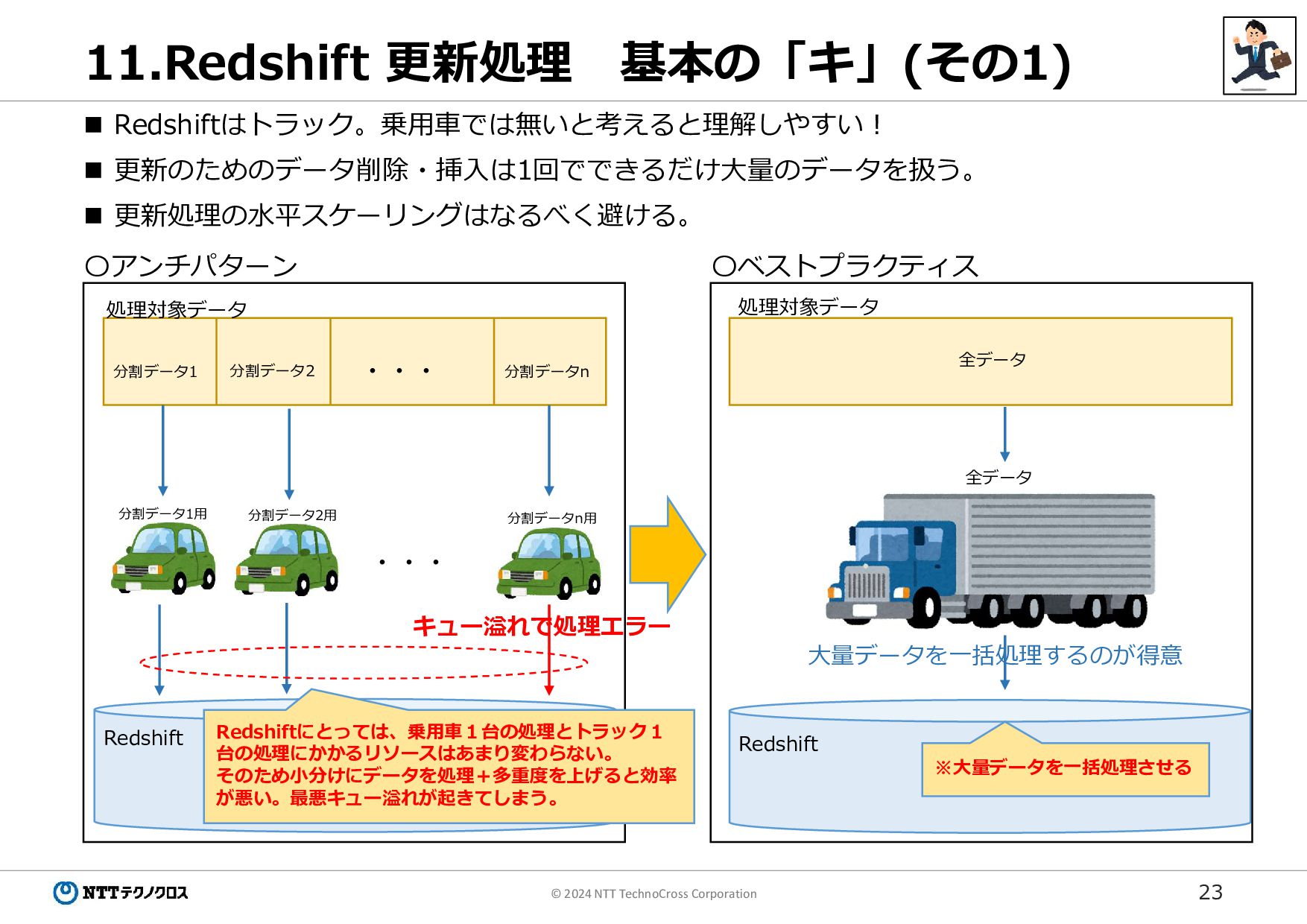
23 © 2024 NTT TechnoCross Corporation 11.Redshift 更新処理 基本の「キ」(その1)
Redshiftはトラック。乗用車では無いと考えると理解しやすい! 更新のためのデータ削除・挿入は1回でできるだけ大量のデータを扱う。 更新処理の水平スケーリングはなるべく避ける。 ・・・ ・・・ 処理対象データ 処理対象データ 分割データ1 分割データ2 分割データn Redshift Redshift 〇アンチパターン 〇ベストプラクティス Redshiftにとっては、乗用車1台の処理とトラック1 台の処理にかかるリソースはあまり変わらない。 そのため小分けにデータを処理+多重度を上げると効率 が悪い。最悪キュー溢れが起きてしまう。 キュー溢れで処理エラー 大量データを一括処理するのが得意 分割データn用 分割データ2用 分割データ1用 全データ ※大量データを一括処理させる 全データ
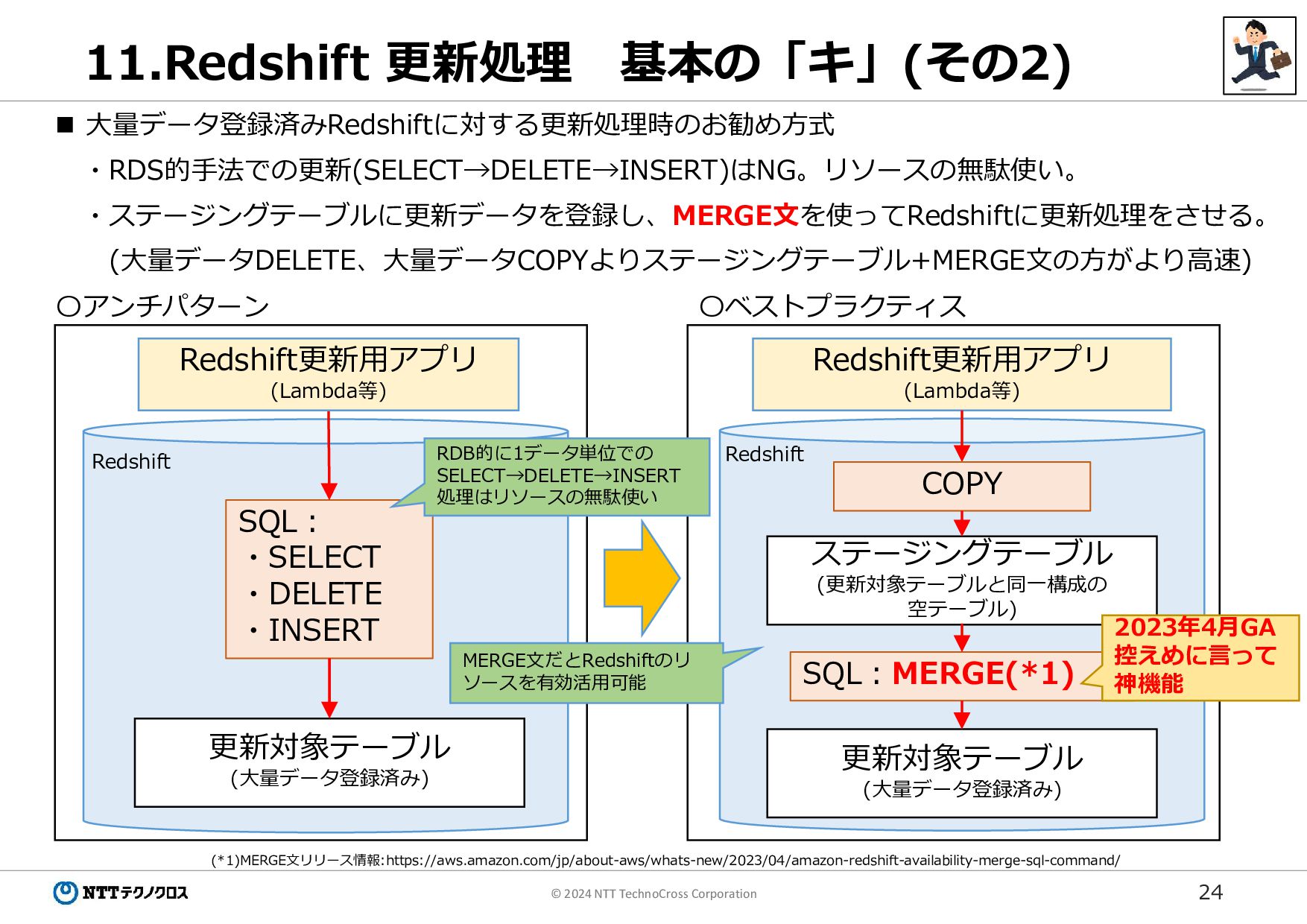
24 © 2024 NTT TechnoCross Corporation 11.Redshift 更新処理 基本の「キ」(その2)
大量データ登録済みRedshiftに対する更新処理時のお勧め方式 ・RDS的手法での更新(SELECT→DELETE→INSERT)はNG。リソースの無駄使い。 ・ステージングテーブルに更新データを登録し、MERGE文を使ってRedshiftに更新処理をさせる。 (大量データDELETE、大量データCOPYよりステージングテーブル+MERGE文の方がより高速) 更新対象テーブル (大量データ登録済み) SQL: ・SELECT ・DELETE ・INSERT ステージングテーブル (更新対象テーブルと同一構成の 空テーブル) 更新対象テーブル (大量データ登録済み) Redshift更新用アプリ (Lambda等) SQL:MERGE(*1) Redshift更新用アプリ (Lambda等) COPY 〇アンチパターン 〇ベストプラクティス RDB的に1データ単位での SELECT→DELETE→INSERT 処理はリソースの無駄使い MERGE文だとRedshiftのリ ソースを有効活用可能 Redshift Redshift (*1)MERGE文リリース情報:https://aws.amazon.com/jp/about-aws/whats-new/2023/04/amazon-redshift-availability-merge-sql-command/ 2023年4月GA 控えめに言って 神機能
25 © 2024 NTT TechnoCross Corporation 12.さいごに 【結論の再確認】Redshift Serverlessの更新処理は基本RPU値が命!
性能向上、コスト削減のため基本RPU値のチューニングは必須。 チューニング時は最初に基本RPU値32未満、以上にするかを検討する。 更新処理はSELECT→DELETE→INSERTではなくはMERGE文を使う! 【結論の補足】 理論上は基本RPU16x4時間と基本RPU値64x1時間は同一処理量でかつ同一料金のはず。 しかし本事例では24時間の課金額は基本RPU値16の方が64より廉価であった。 【推測】 本事例では更新処理開始から終了まで基本RPU値で固定されたままだった。そのため負荷が 低い時には実際には使われないRPUに対しても課金が発生していると推測される。基本RPU 値が大きい方が使われないRPUが大きくなり結果として課金額も高くなっているのでは? 【全体の補足】 今回は検索処理に対する検証は出来ていません。検索時はショート、ミディアム、ロングク エリなどの負荷状況応じてRPU値は動的に変動するのでは?
26 © 2024 NTT TechnoCross Corporation 13.【告知】はみ出し分は8月末頃にQiitaに書きます 大阪リージョンへのディザスタリカバリ環境構築で痛い目見ました
大阪リージョンではServerless版はGAされていない(2024年8月時点) Provisioned版はServerless版スナップショットからリストア可能 ★東京リージョンから大阪リージョンへServerlessスナップショットを直接 コピーすることはでないことが判明!どうする? 大阪リージョンはProvisioned版で対応すればOKだな 机上検討 実環境で検証
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}