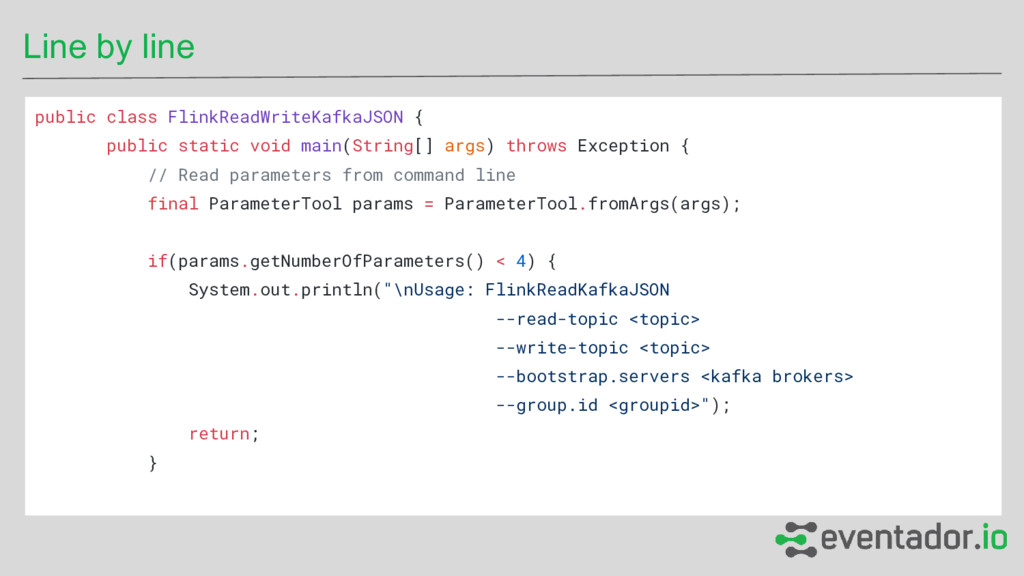
Getting started with Apache Flink (and Apache Kafka). An introduction to Flink using the Table API in JAVA and SQL using ADSB streaming data as an example.
on 25 years. Sybase, Oracle DBA, PostgreSQL DBA, MySQL aficionado, MongoDB early adopter, founded two companies based on data technologies Streaming data is a game changer. Fell in love with Apache Kafka and Apache Flink. We went ‘all in’. I am a data nerd ‘02 had hair ^ Now… lol
a batch execution environment. Born from Apache Hadoop ecosystem. Good streaming API with micro-batch streaming model. Mature. Apache Storm True boundless stream processing, based around concept of “topologies”, “spouts”, and “bolts”. Open sourced by Twitter (who are now working on Heron). Apache Kafka Traditionally a transport mechanism for data, now has API’s for streaming (KStreams, KSQL). Popular, management req’d. Just went 1.0. Apache Flink Pure streaming execution environment, exactly once semantics, checkpointing, high availability, source/sink connectors, powerful APIs with higher order functionality for windowing, recoverability, state ... The landscape is evolving fast
by the Apache Software Foundation. The core of Apache Flink is a distributed streaming dataflow engine written in Java and Scala. Flink provides a high-throughput, low-latency streaming engine[7] as well as support for event-time processing and state management. Flink applications are fault-tolerant in the event of machine failure and support exactly-once semantics.[8]Programs can be written in Java, Scala,[9] Python,[10] and SQL[11] and are automatically compiled and optimized[12] into dataflow programs that are executed in a cluster or cloud environment. Apache Flink
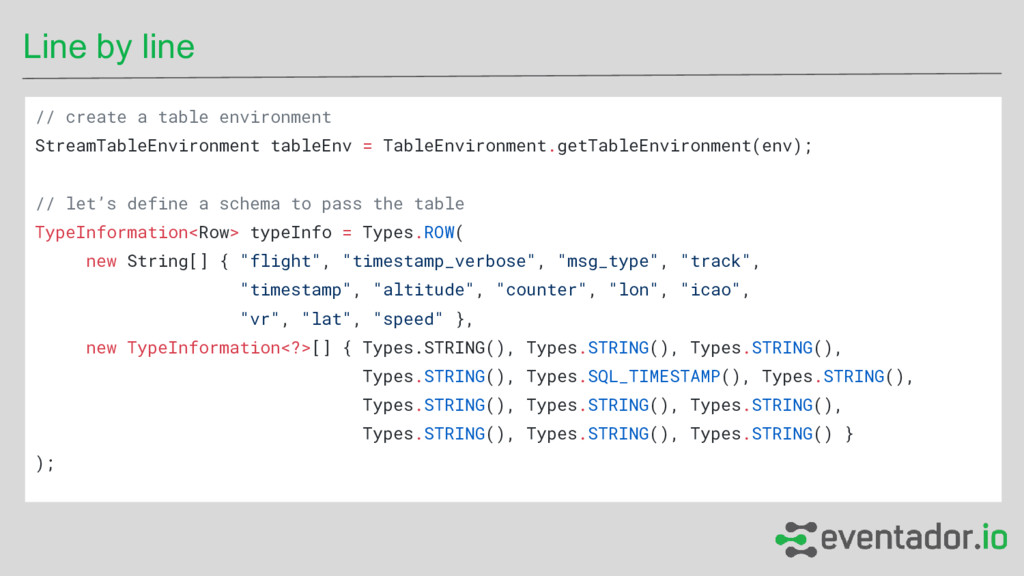
DSL centered around the concept of a dynamic table - Follows an extended relational model - What logical operation should be performed on the data - Table API + SQL FTW - Sources and Sinks ←!!!!!!! - Kafka, CSV, roll your own..
// register a table source Table orders = tableEnv.scan("Orders"); Table result = orders.groupBy("a").select("a, b.sum as d"); // Table API + SQL // register a table source Table result = tableEnv.sql("SELECT a, b.sum as d FROM orders GROUP BY a");
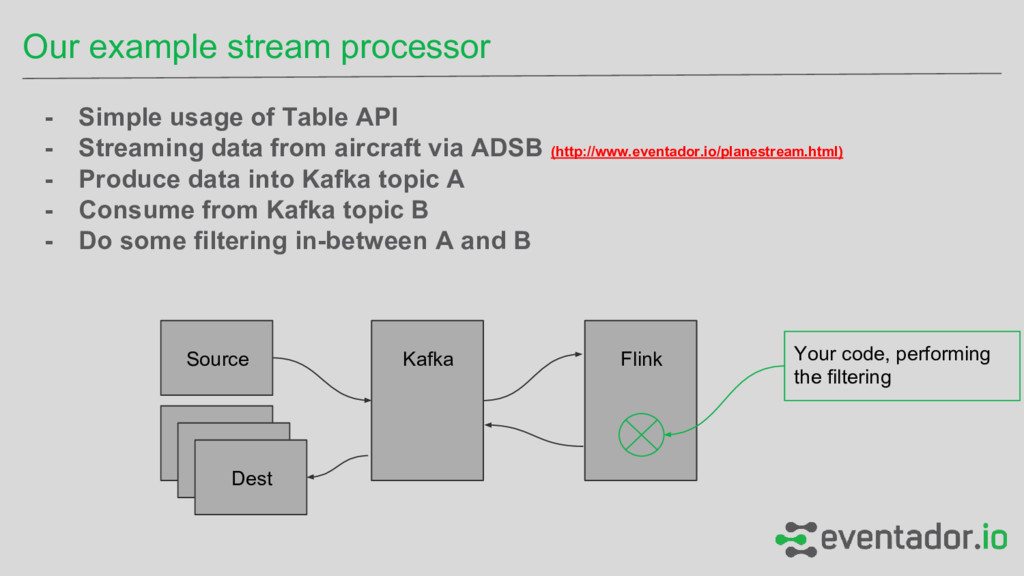
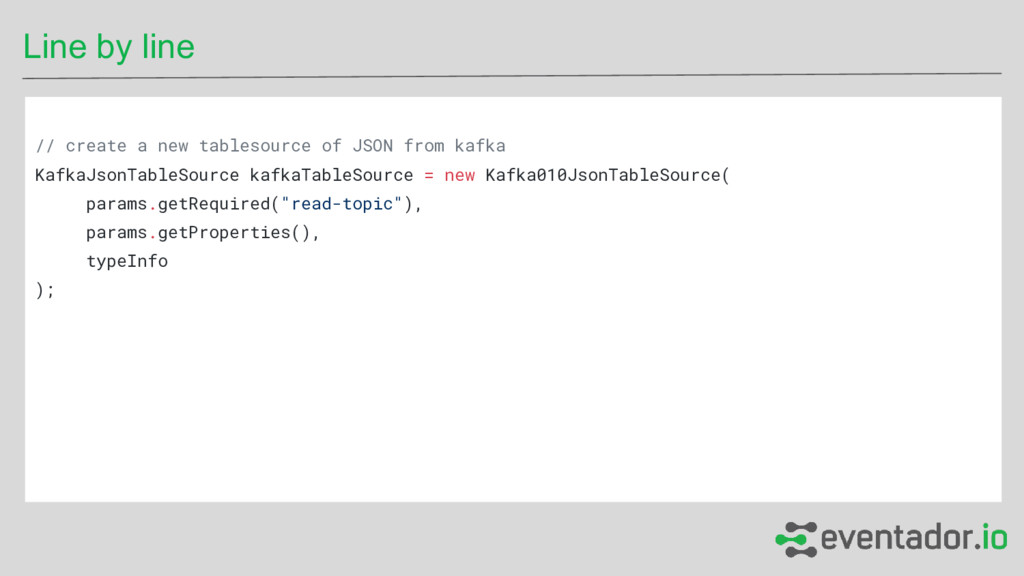
- Streaming data from aircraft via ADSB (http://www.eventador.io/planestream.html) - Produce data into Kafka topic A - Consume from Kafka topic B - Do some filtering in-between A and B Kafka Source Flink Dest Dest Dest Your code, performing the filtering
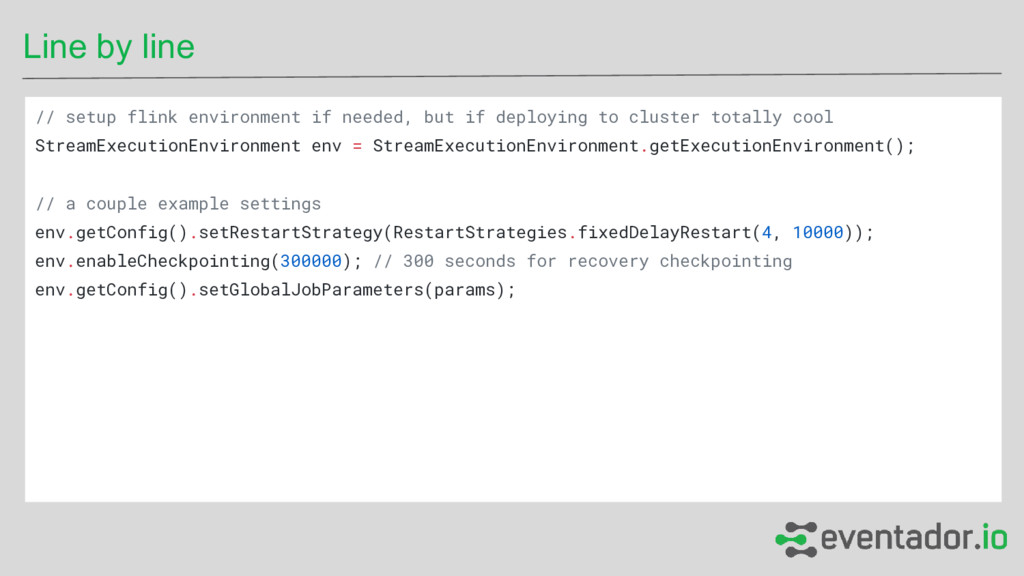
if deploying to cluster totally cool StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // a couple example settings env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(4, 10000)); env.enableCheckpointing(300000); // 300 seconds for recovery checkpointing env.getConfig().setGlobalJobParameters(params);
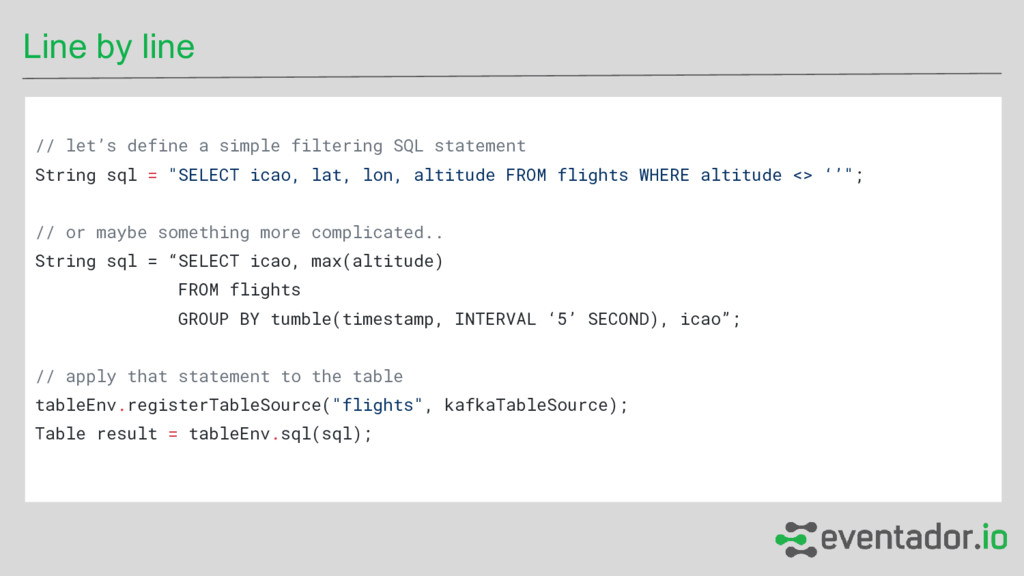
statement String sql = "SELECT icao, lat, lon, altitude FROM flights WHERE altitude <> ‘’"; // or maybe something more complicated.. String sql = “SELECT icao, max(altitude) FROM flights GROUP BY tumble(timestamp, INTERVAL ‘5’ SECOND), icao”; // apply that statement to the table tableEnv.registerTableSource("flights", kafkaTableSource); Table result = tableEnv.sql(sql);
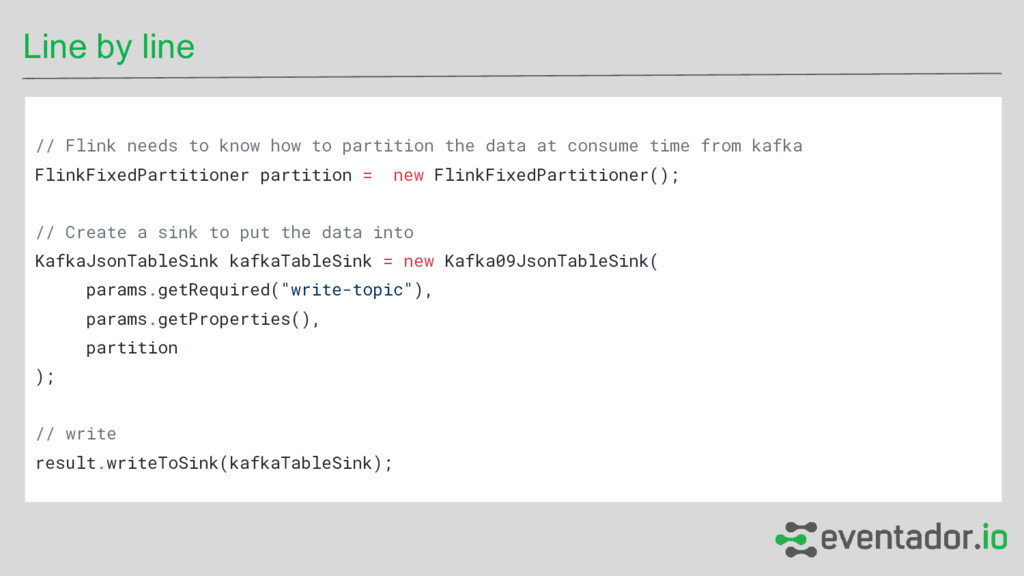
partition the data at consume time from kafka FlinkFixedPartitioner partition = new FlinkFixedPartitioner(); // Create a sink to put the data into KafkaJsonTableSink kafkaTableSink = new Kafka09JsonTableSink( params.getRequired("write-topic"), params.getProperties(), partition ); // write result.writeToSink(kafkaTableSink);
- Calcite supports loads of SQL operations - At some level of complexity, choose the lower level datastream API - Growing amount of development on Table API/SQL by community https://github.com/kgorman/TrafficAnalyzer https://github.com/kgorman/TrafficAnalyzer/blob/master/src/main/java/io/eventador/FlinkReadWriteKafkaJSON.java https://github.com/kgorman/TrafficAnalyzer/blob/master/src/main/java/io/eventador/FlinkReadWriteKafkaSinker.java https://ci.apache.org/projects/flink/flink-docs-release-1.3/ https://calcite.apache.org/docs/reference.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] www.eventador.io @eventadorlabs Contact](https://files.speakerdeck.com/presentations/ee269c69da28469a934feb46b28abed9/slide_18.jpg){kind=link}