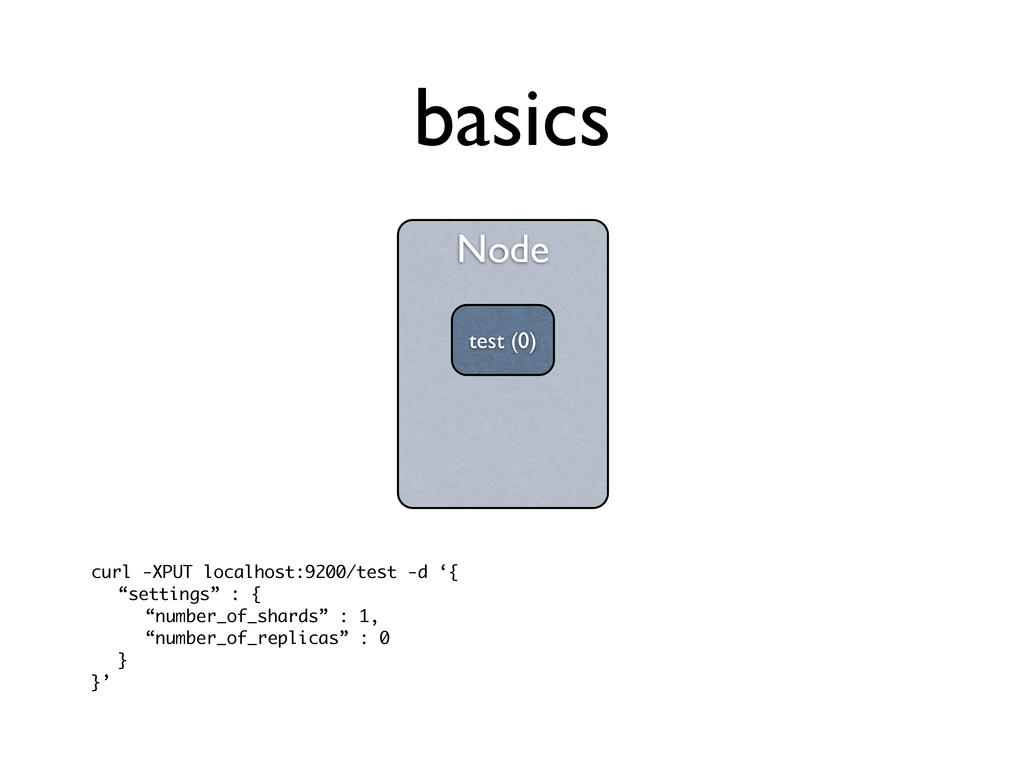
simple formula to it, depends on usage • usually a factor of hardware, #docs, #size, and type of searches (sort, faceting) • easy to test, just use one shard and start loading it
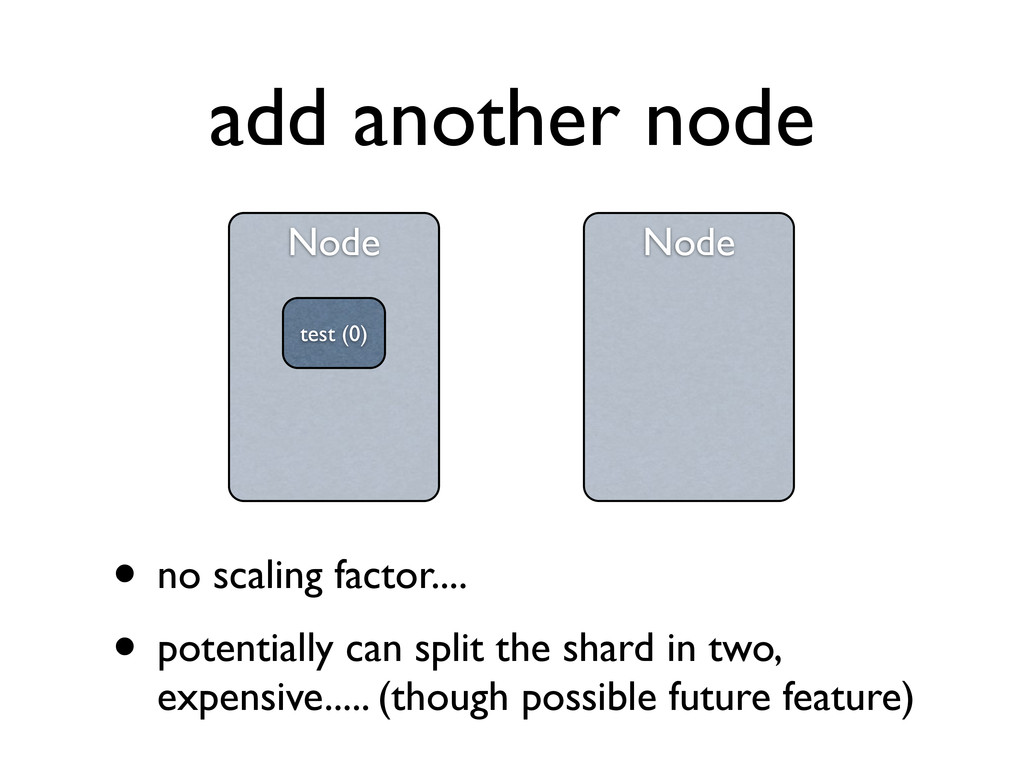
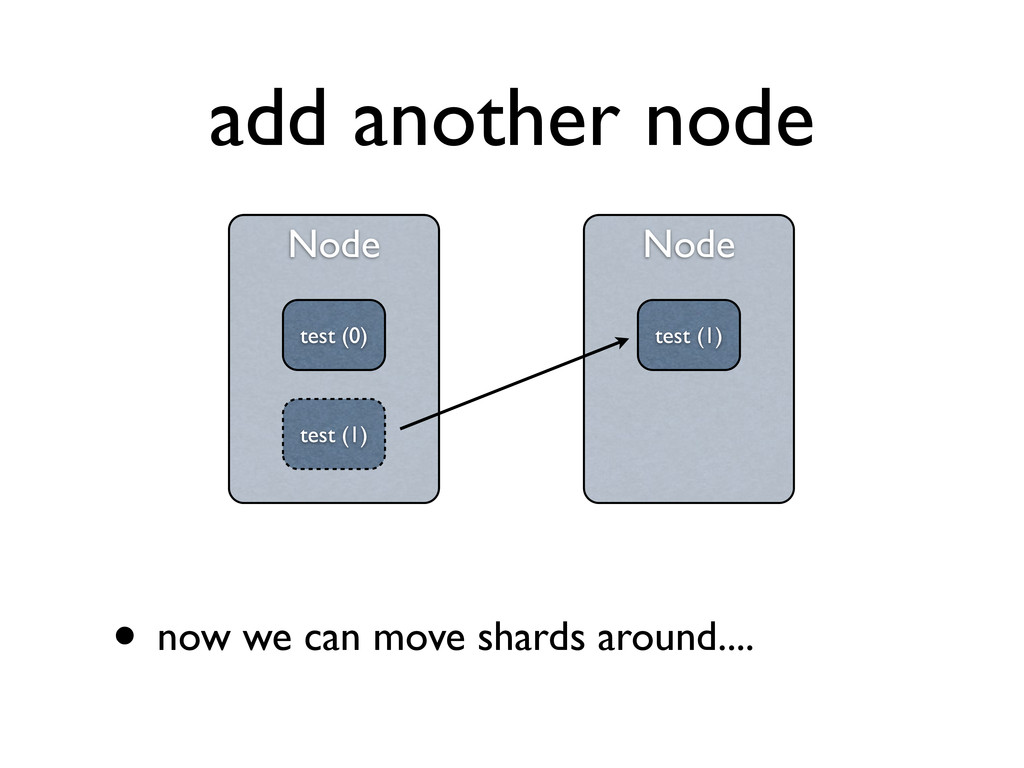
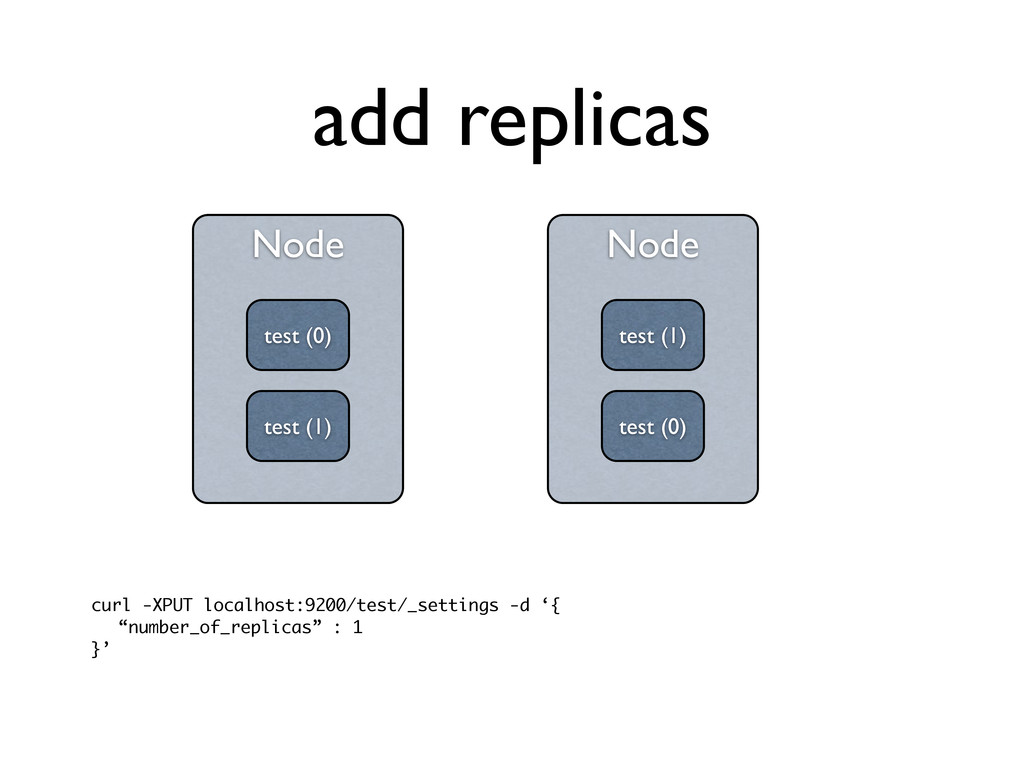
splitting) • #shards * max_shard_size • replicas play no part here, they are only additional copies of data • need to be taken into account with *cluster* sizing
Node test (...) test (...) test (1) test (0) Node test (1) Node test (...) test (...) test (1) test (0) Node test (1) Node test (...) test (...) test (1) test (0)
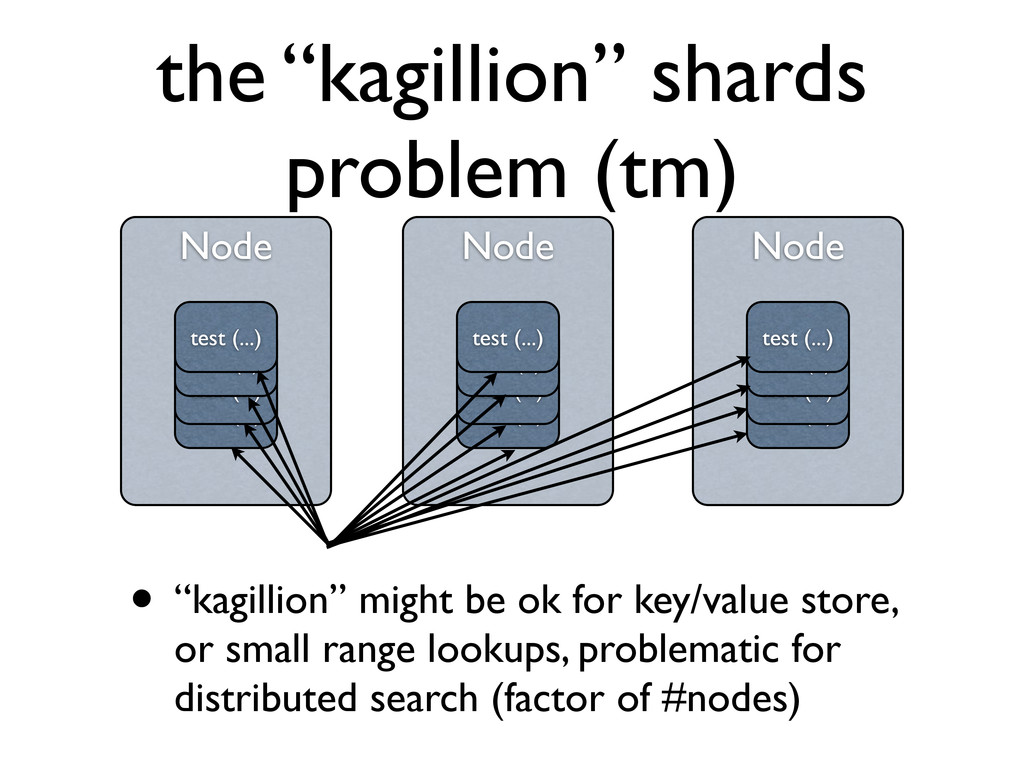
for key/value store, or small range lookups, problematic for distributed search (factor of #nodes) Node test (1) Node test (...) test (...) test (1) test (...) Node test (1) Node test (...) test (...) test (1) test (...) Node test (1) Node test (...) test (...) test (1) test (...)
Node Node user1 (0) user1 (1) user2 (0) Node user2 (2) user2 (1) user3 (0) • each user has his own index • possibly with different sharding • search is simple! (/user1/_search)
shard can hold a substantial amount of data (docs / size) • small users become “resource expensive” as they require at least 1 shard • more nodes to be able to support so many shards (remember, a shard requires system resources)
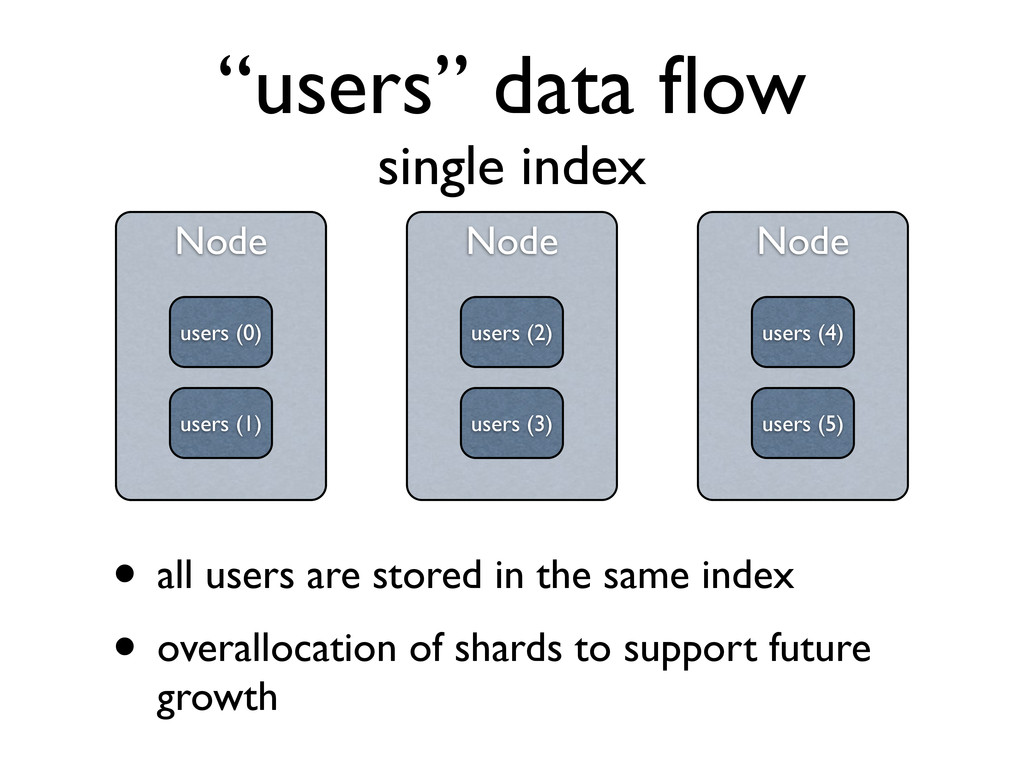
users (0) users (2) users (1) Node users (4) users (3) users (5) • all users are stored in the same index • overallocation of shards to support future growth
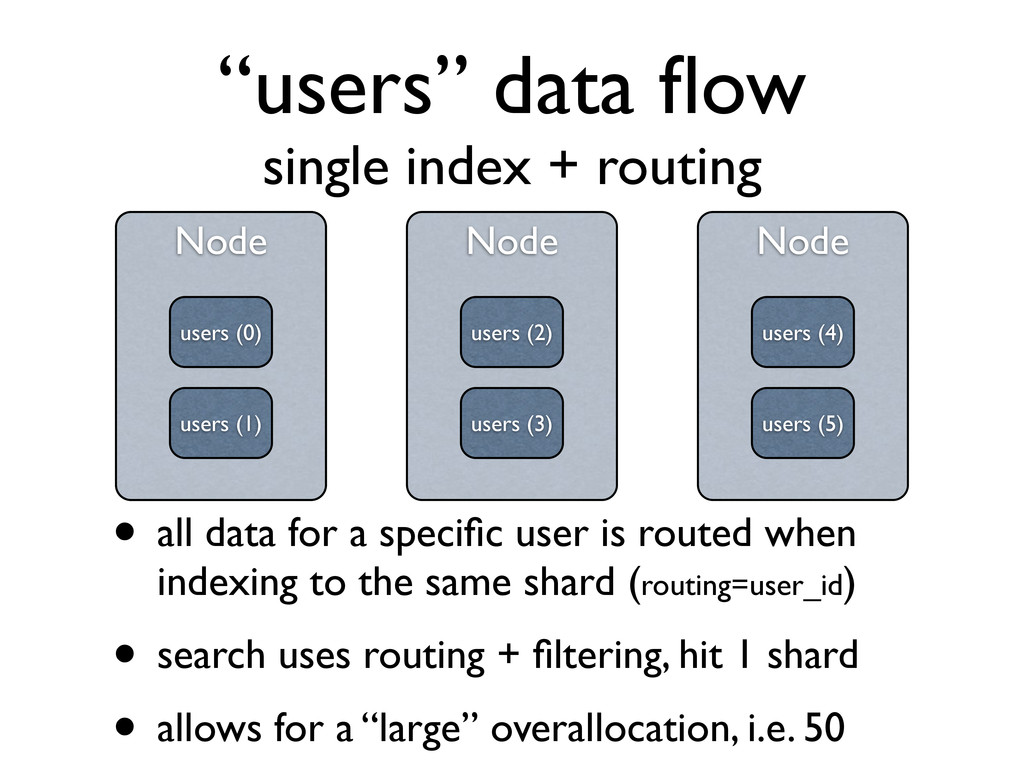
Node Node users (0) users (2) users (1) Node users (4) users (3) users (5) • all data for a specific user is routed when indexing to the same shard (routing=user_id) • search uses routing + filtering, hit 1 shard • allows for a “large” overallocation, i.e. 50
users can be migrated to their own respective indices • The “alias” of the user now points to its own index (no routing / filtering needed), with its own set of shards
Node Node 2012_01 (0) 2012_01 (1) 2012_02 (0) Node 2012_02 (1) 2012_03 (1) 2012_03 (0) • an index per “month”, “week”, “day”, ... • can adapt, change time range / #shards for “future” indices
can be optimized curl -XPOST ‘localhost:9200/2012_01/_optimize?max_num_segments=2’ • “old” indices can be moved curl -XPOST ‘localhost:9200/2012_01/_settings’ -d ‘{ “index.routing.allocation.exclude.tag” : “strong_box”, “index.routing.allocation.include.tag” : “not_so_strong_box” }’ # 5 nodes of these node.tag: strong_box # 20 nodes of these node.tag: not_so_strong_box
indices can be removed • much more lightweight compared to deleting docs, just delete a bunch of files compared to merging out deleted docs • or closed (no resources used except disk) curl -XDELETE ‘localhost:9200/2012_01’ curl -XPOST ‘localhost:9200/2012_01/_close’
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}