engineer new features ◦ How easy it is to modify / remove / add steps? 2. Tune hyperparameters ◦ How easy it is to update parameters after the data has changed?
engineer new features ◦ How easy it is to modify / remove / add steps? 2. Tune hyperparameters ◦ How easy it is to update parameters after the data has changed? 3. Train model ◦ How easy it is to re-train your model after the data has changed?
engineer new features ◦ How easy it is to modify / remove / add steps? 2. Tune hyperparameters ◦ How easy it is to update parameters after the data has changed? 3. Train model ◦ How easy it is to re-train your model after the data has changed? 4. Generate predictions on new data ◦ Can you run all the same steps easily on any new data, without repeating code?
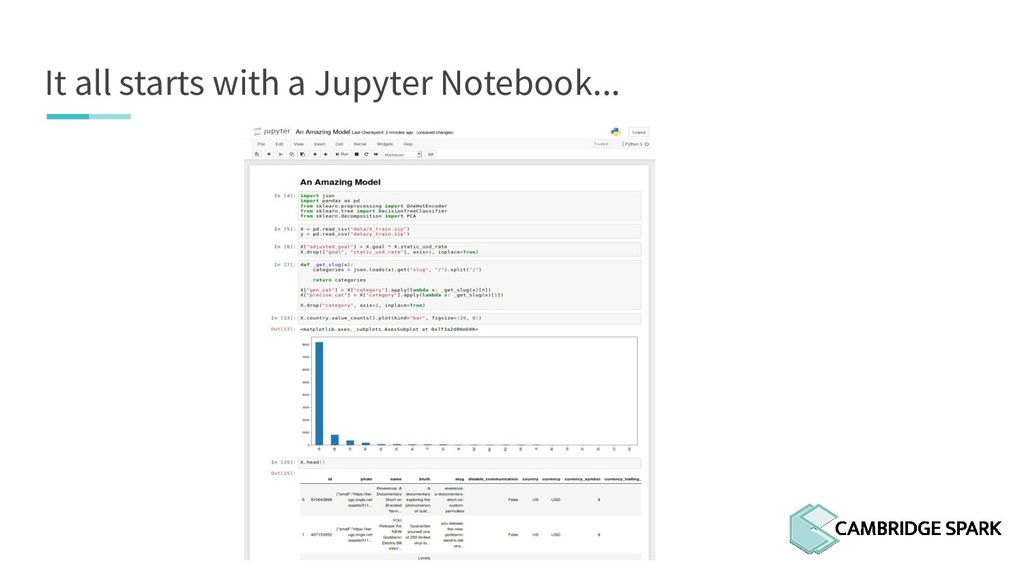
some features 3. “Clean” some features 4. “Engineer” some features from original ones 5. Apply One-Hot Encoding on categorical features 6. Scale/transform some features
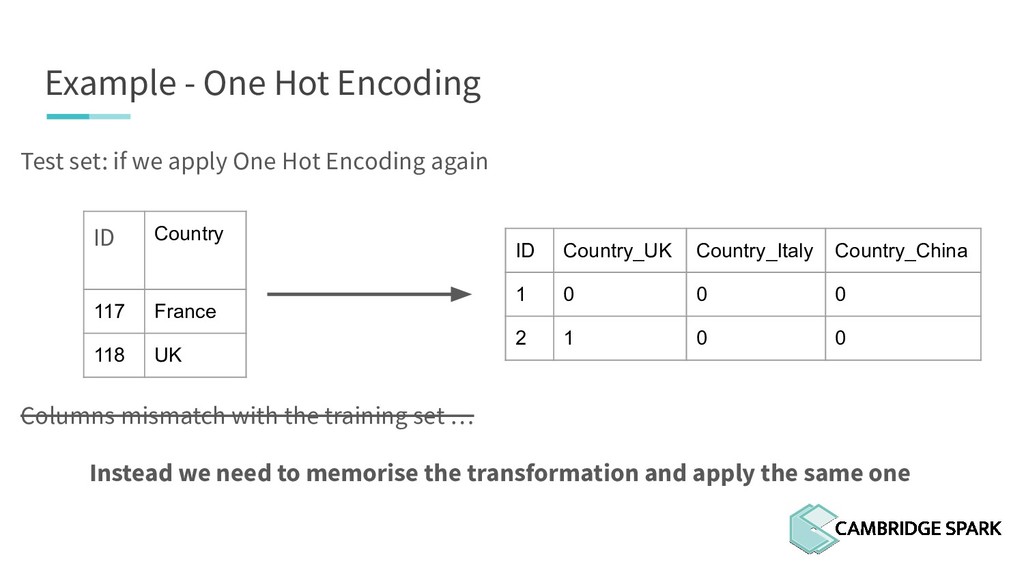
One Hot Encoding again ID Country 117 France 118 UK ID Country_France Country_UK 117 1 0 118 0 1 Columns mismatch with the training set: [ UK, Italy, China ] Instead we need to memorise the transformation and apply the same one
One Hot Encoding again ID Country 117 France 118 UK Columns mismatch with the training set … Instead we need to memorise the transformation and apply the same one ID Country_UK Country_Italy Country_China 1 0 0 0 2 1 0 0
Create a reusable function! What if transformation needs to remember a state? (one hot, scaler, etc…) Create a reusable class! Scikit-learn transformers are a way to facilitate this and keep it consistent.
and BaseEstimator • Implement a .fit with what needs to be saved from the training data • Implement a .transform which applies the actual transformation • If you need options, add parameters to an __init__
a set of columns and generate new features • ColumnTransformer is a higher level transformer used to apply different transformations on all your columns Example: Apply PCA on numerical features, One Hot Encoding on categorical ones.
can apply the same transformations everywhere: • preprocessor.fit(X_train) • preprocessor.transform(X_train) • preprocessor.transform(X_test) • preprocessor.transform(X_new) It keeps in memory all unique transformations applied to all columns.
"pca", PCA())]) # Calling .fit will “learn” both steps pipeline.fit(data) # Calling .transform will “apply” both steps sequentially pipeline.transform(data)
"scaler", StandardScaler()), ( "pca", PCA())]) # Use ColumnTransformer to apply different transformations to all columns preprocessor = ColumnTransformer([( "numerical", num_pipeline, num_cols), ( "one_hot", OneHotEncoder(), cat_cols)])
the model and .predict() to generate predictions. • Pipeline support the last step to be an Estimator object • When calling the pipeline: ◦ .fit(): fits all transformers and trains predictive model ◦ .predict(): calls .transform() on the transformers and then .predict()
preprocessing steps + algorithm • Can use directly in GridSearch, Cross Validation, etc… ◦ Avoids data leakage (all steps run on the right folds only) • Can apply same pipeline to new data • More modular -> easier to test and maintain
file ◦ Includes params of estimator AND preprocessing • We can train the model and dump the whole object to disk • Once the model is trained, you can efficiently load use it in production
to “serialise” objects: • Pickle • Joblib Those work with any Python object and are mostly equivalent. Joblib tends to be more efficient with larger arrays.
useful to save trained models, but keep in mind: • It does not save dependencies. ◦ To load your model, you need to import the code it relies on ▪ external libraries, your own classes definition, etc... • Data is not saved, so if you need to retrain the model make sure you keep a snapshot.
`python run.py crossval` ◦ This will use parameters defined in config.py • Train the model with `python run.py train` ◦ This use parameters defined in config.py • Test the model with `python run.py test`
same dtypes • Have a requirements.txt with versions of the libraries you use • When updating code, check the crossval score to confirm it improved performance • With modular code, you can more easily write tests! (and you should) • With all that, updating your models should be less stressful.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Column Transformer num_cols = ["age", "salary"] cat_cols = ["country", "gender"]](https://files.speakerdeck.com/presentations/f223b012cbc64f00984bb885281e197d/slide_21.jpg){kind=link}
![Column Transformer ColumnTransformer([("pca", PCA(), num_cols),("one_hot", OneHotEncoder(), cat_cols)]) Numerical Columns PCA](https://files.speakerdeck.com/presentations/f223b012cbc64f00984bb885281e197d/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Pipeline Pipeline([("scaler", StandardScaler()), ( "pca", PCA())]) Original DataFrame DataFrame Scaled](https://files.speakerdeck.com/presentations/f223b012cbc64f00984bb885281e197d/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}