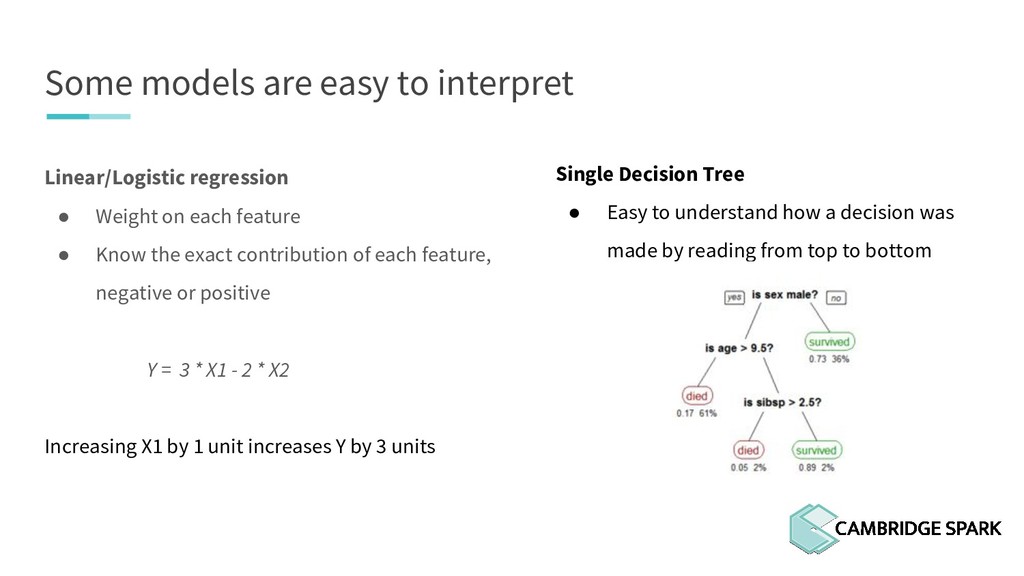
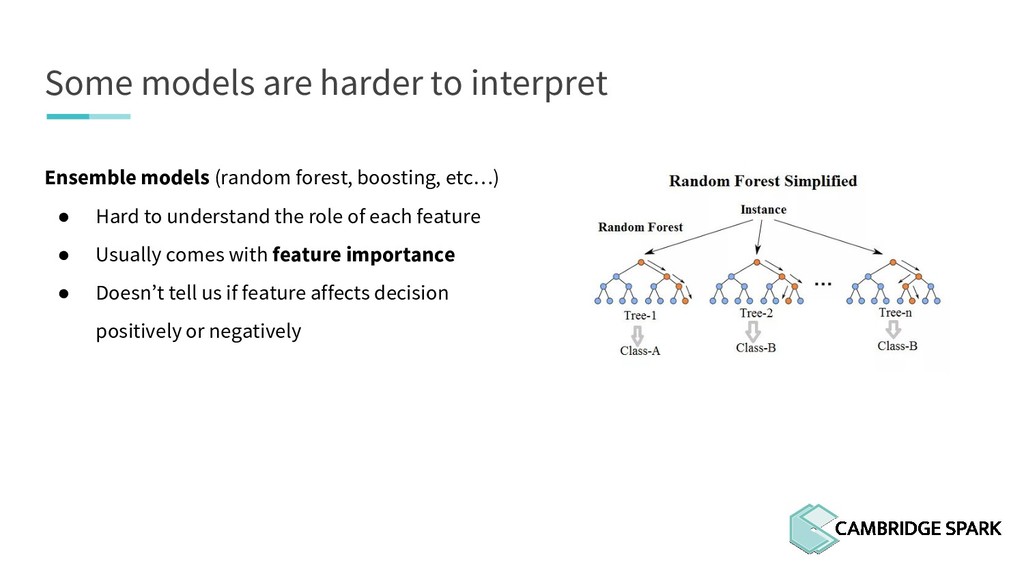
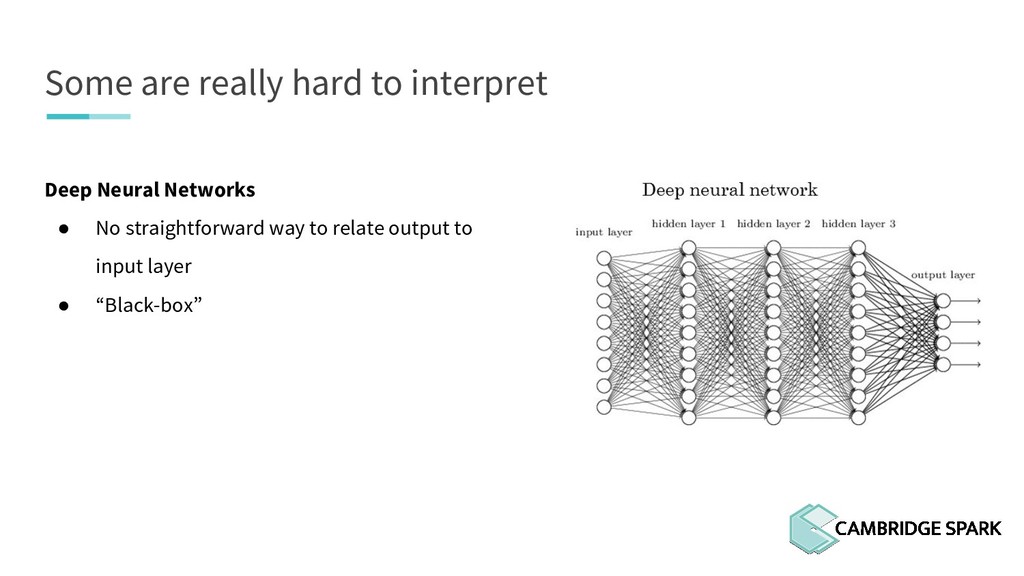
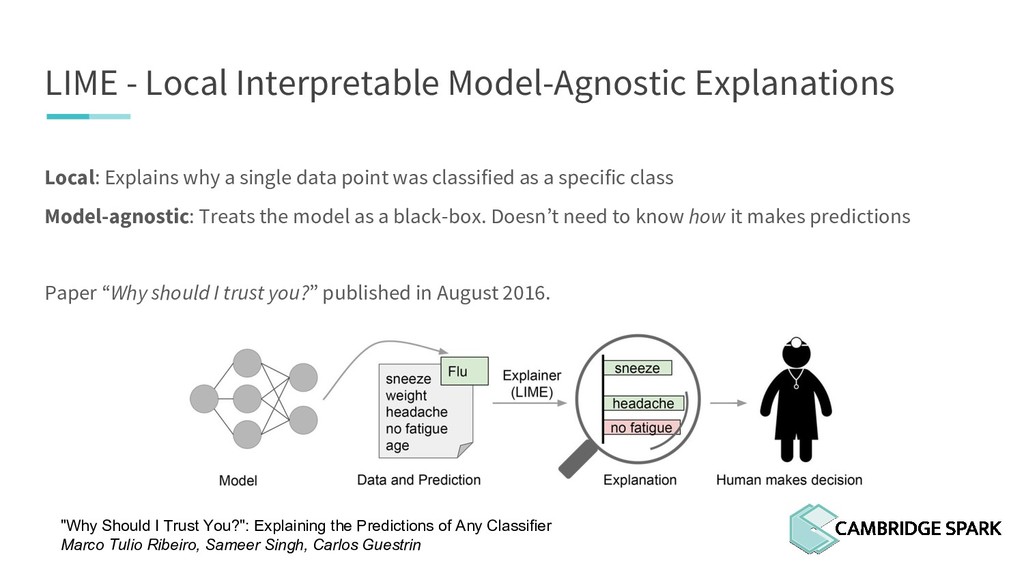
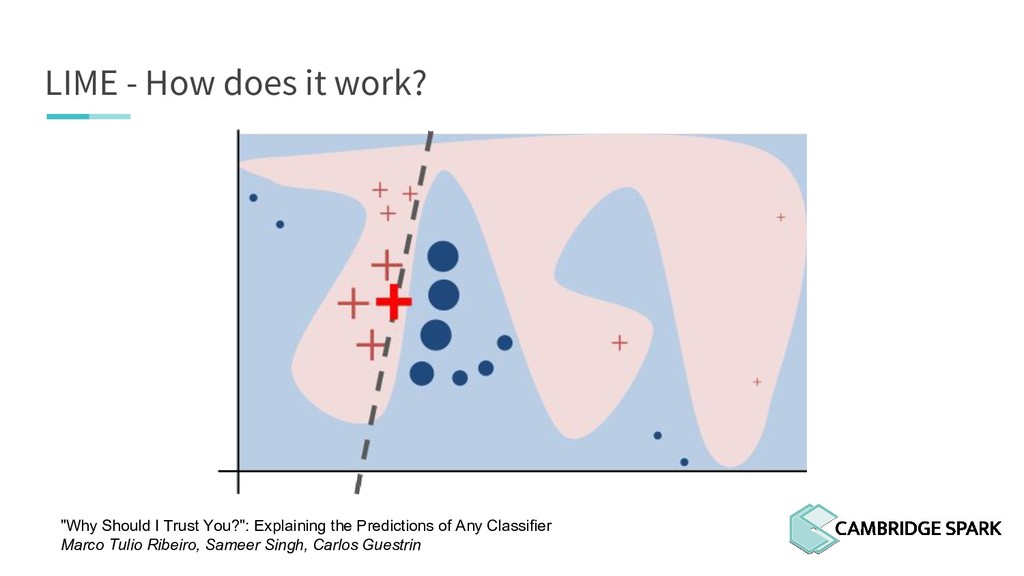
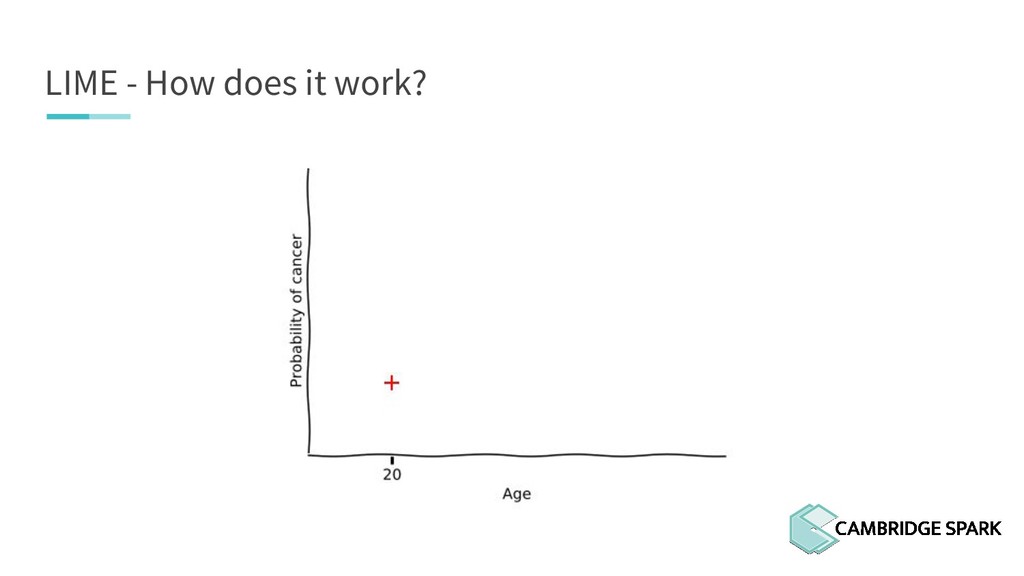
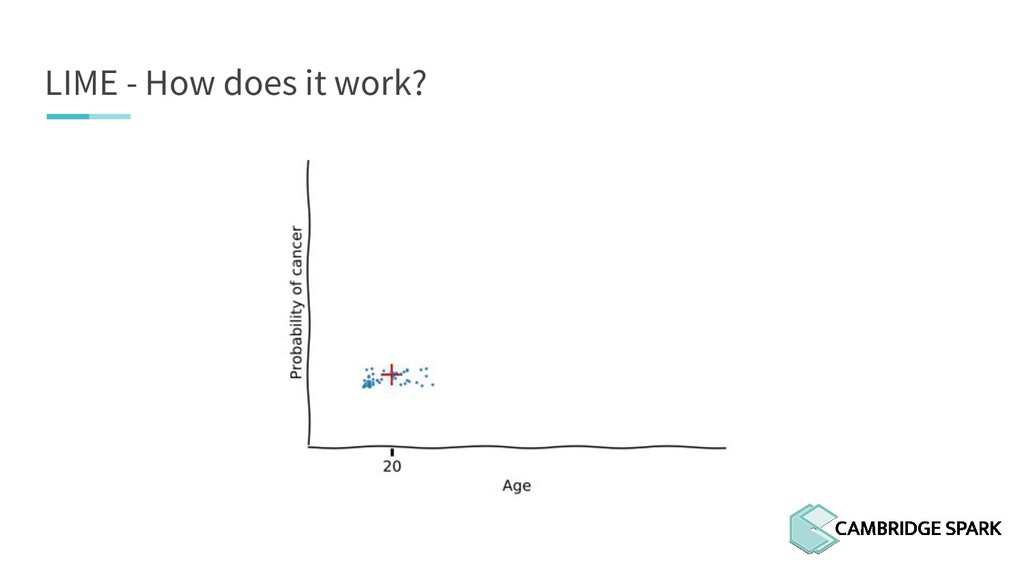
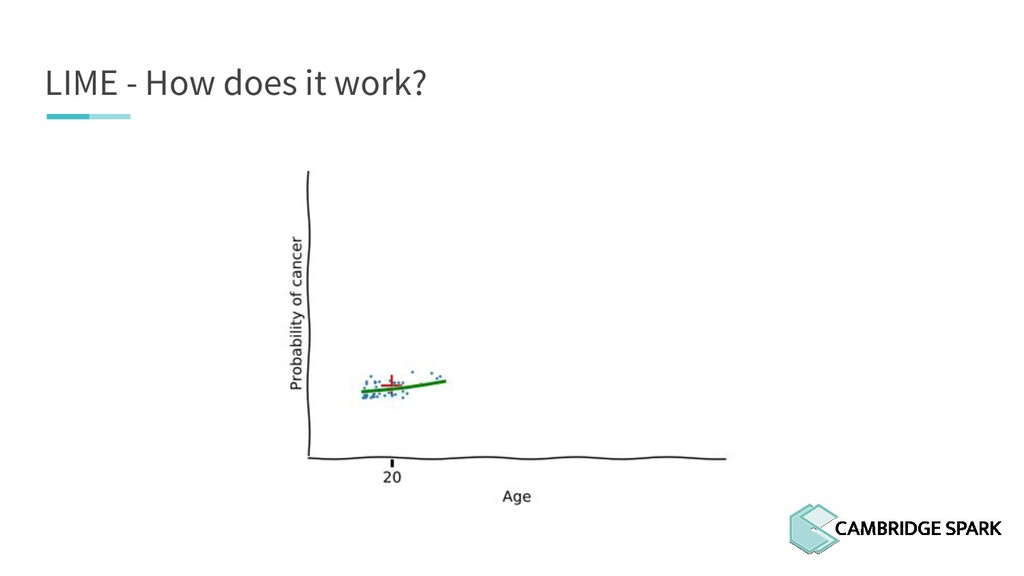
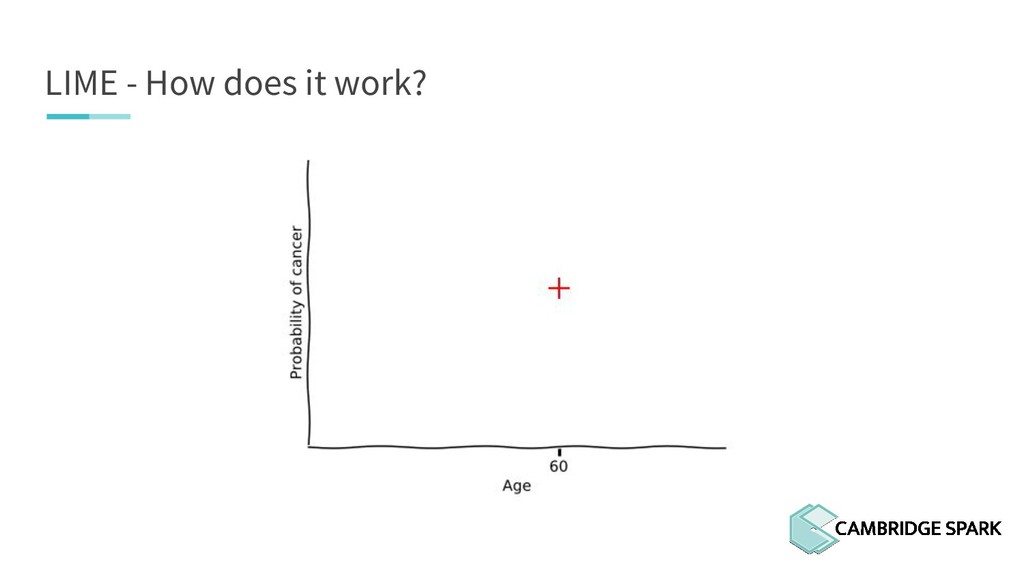
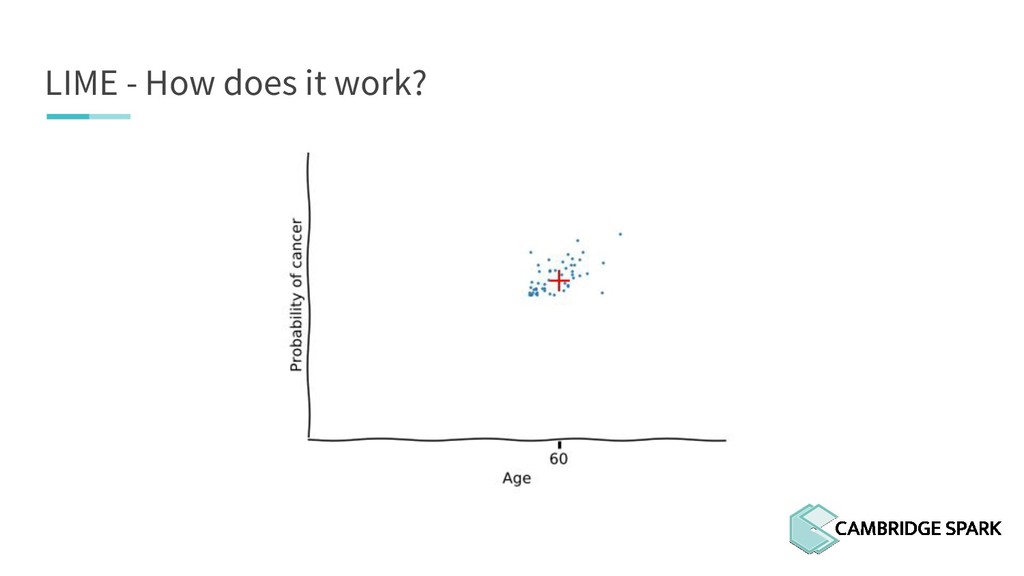
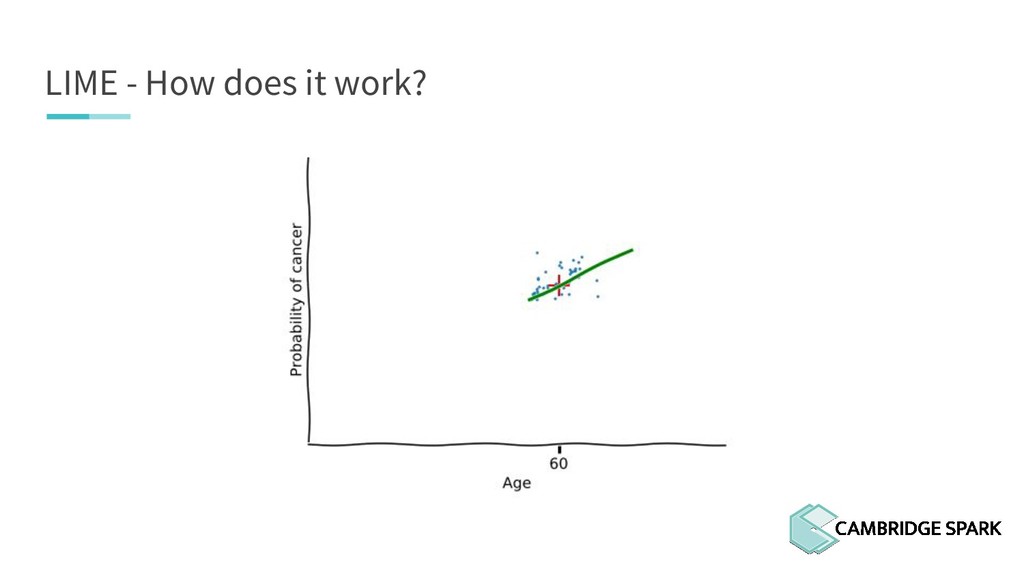
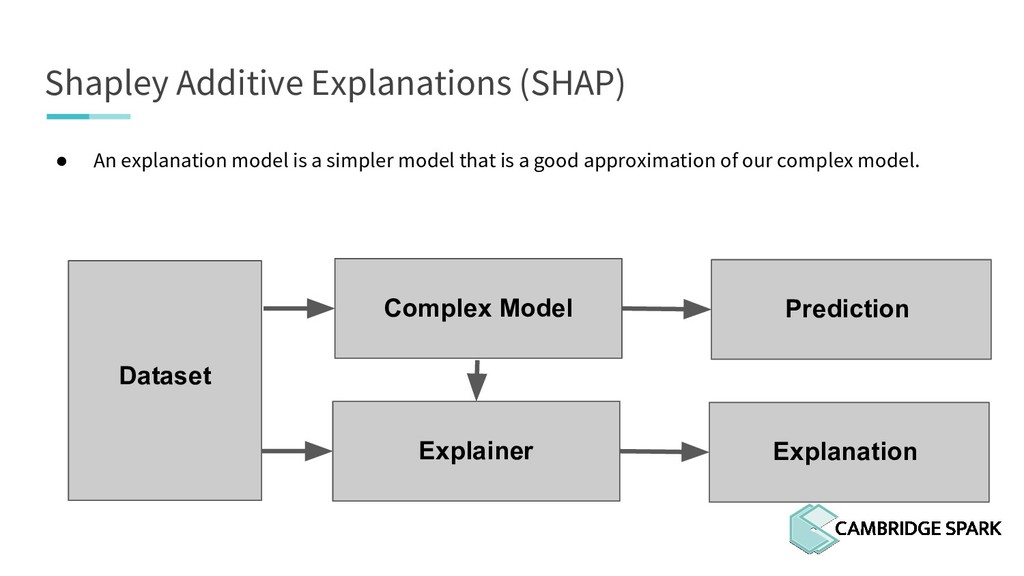
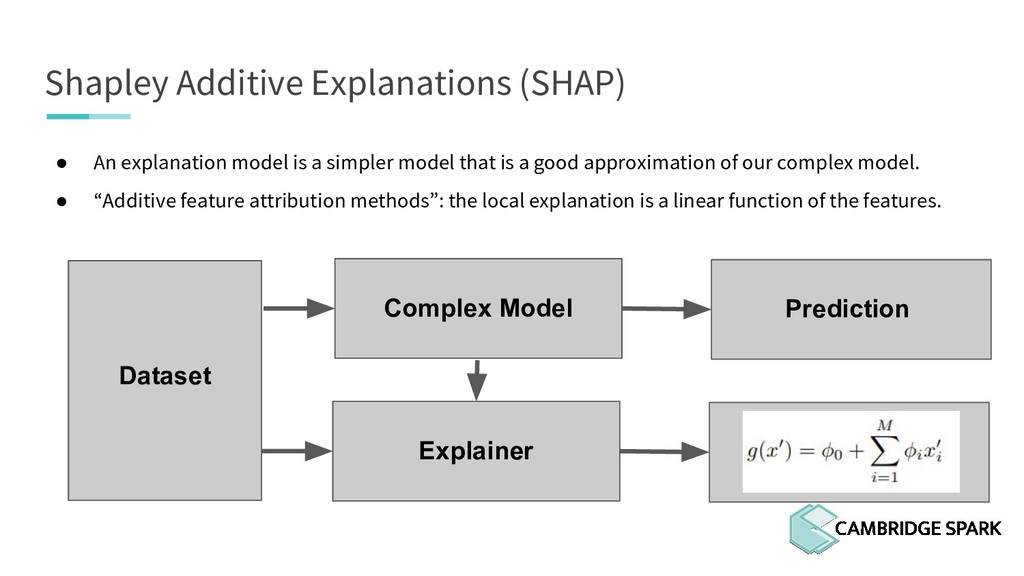
What's the use of sophisticated machine learning models if you can't interpret them? In fact, many industries including finance and healthcare require clear explanations of why a decision is made. This workshop covers two recent model interpretability techniques that are essentials in your data scientist toolbox: LIME (Local Interpretable Model-Agnostic Explanations) and SHAP (SHapley Additive exPlanations). You will learn how to apply these techniques in Python on a real-world data science problem. You will also learn the conceptual background behind these techniques so you can better understand when they are appropriate.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}