responsibility over a single part of the functionality provided by the software, and that responsibility should be entirely encapsulated by the class.” • Each class/function should do one thing for our model • In Data Science we have extra constraints
engineer new features ◦ How easy it is to modify / remove / add steps? 2. Tune hyperparameters ◦ 3. Train model ◦ 4. Generate predictions on new data ◦
engineer new features ◦ How easy it is to modify / remove / add steps? 2. Tune hyperparameters ◦ How easy it is to re-tune your model after the data has changed? 3. Train model ◦ 4. Generate predictions on new data ◦
engineer new features ◦ How easy it is to modify / remove / add steps? 2. Tune hyperparameters ◦ How easy it is to re-tune your model after the data has changed? 3. Train model ◦ How easy it is to re-train your model after the data has changed? 4. Generate predictions on new data ◦
engineer new features ◦ How easy it is to modify / remove / add steps? 2. Tune hyperparameters ◦ How easy it is to re-tune your model after the data has changed? 3. Train model ◦ How easy it is to re-train your model after the data has changed? 4. Generate predictions on new data ◦ Can you run all the same steps easily on any new data, without repeating code?
Splitting data into train/test set 3. Drop some features 4. “Clean” some features 5. “Engineer” some features from original ones 6. Apply One-Hot Encoding on categorical features 7. Scale/transform some features
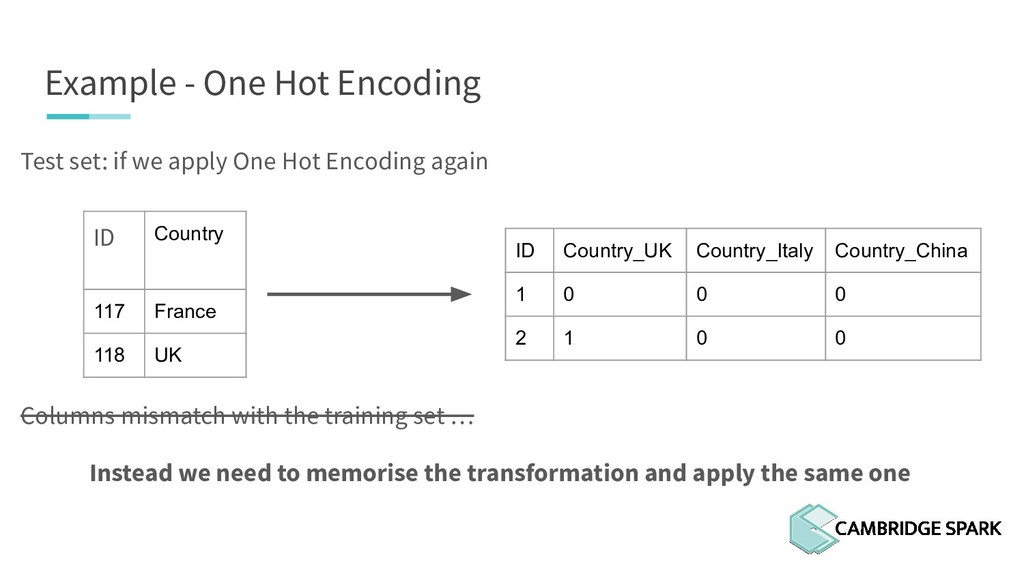
One Hot Encoding again ID Country 117 France 118 UK ID Country_France Country_UK 117 1 0 118 0 1 Columns mismatch with the training set: [ UK, Italy, China ] Instead we need to memorise the transformation and apply the same one
One Hot Encoding again ID Country 117 France 118 UK Columns mismatch with the training set … Instead we need to memorise the transformation and apply the same one ID Country_UK Country_Italy Country_China 1 0 0 0 2 1 0 0
data? Create a reusable function! What if transformation needs to remember a state? (one hot, scaler, etc…) Create a reusable class! Scikit-learn transformers are a way to facilitate this and keep it consistent.
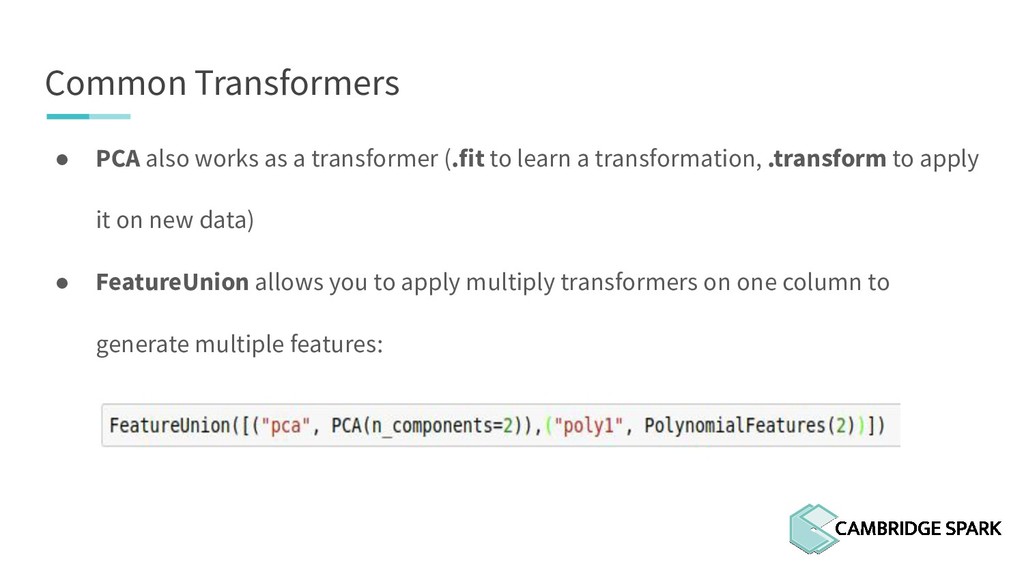
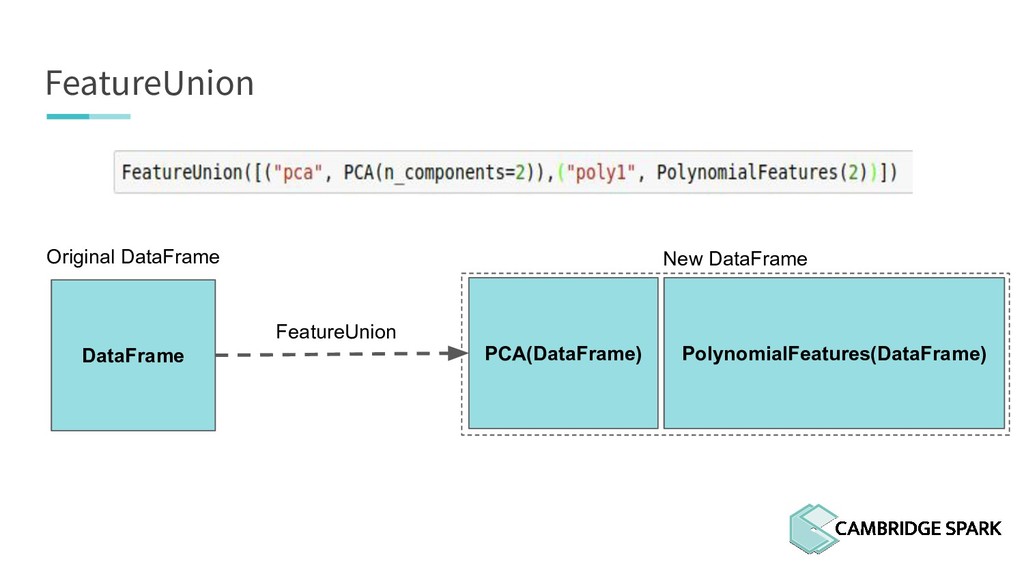
to learn a transformation, .transform to apply it on new data) • FeatureUnion allows you to apply multiply transformers on one column to generate multiple features:
and BaseEstimator • Implement a .fit with what needs to be saved from the training data • Implement a .transform which applies the actual transformation • If you need options, add parameters to an __init__
a set of columns and generate new features • ColumnTransformer is a higher level transformer used to apply different transformations on all your columns Example: Apply PCA on numerical features, One Hot Encoding on categorical ones.
can apply the same transformations everywhere: • preprocessor.fit(X_train) • preprocessor.transform(X_train) • preprocessor.transform(X_test) • preprocessor.transform(X_new) It keeps in memory all unique transformations applied to all columns.
"pca", PCA())]) # Calling .fit will “learn” both steps pipeline.fit(data) # Calling .transform will “apply” both steps sequentially pipeline.transform(data)
"scaler", StandardScaler()), ( "pca", PCA())]) # Use ColumnTransformer to apply different transformations to all columns preprocessor = ColumnTransformer([( "numerical", num_pipeline, num_cols), ( "one_hot", OneHotEncoder(), cat_cols)])
the model and .predict() to generate predictions. • Pipeline support the last step to be a predictive model object • When calling the pipeline: ◦ .fit(): fits all transformers and trains predictive model ◦ .predict(): calls .transform() on the transformers and then .predict()
steps + algorithm • Can use directly in GridSearch, Cross Validation, etc… ◦ Avoids data leakage • Can apply same pipeline to new data • More modular -> easier to test and maintain
to “serialise” objects: • Pickle • Joblib Those work with any Python object and are mostly equivalent. Joblib tends to be more efficient with larger arrays.
mode with open("model.pickle" , "wb") as f: pickle.dump(model_object, f) # Open our pickle model with open("model.pickle" , "rb") as f: new_model = pickle.load(f)
useful to save trained models, but keep in mind: • It does not save dependencies. ◦ To load your model, you need to import the code it relies on ▪ external libraries, your own classes definition, etc... • Data is not saved, so if you need to retrain the model make sure you keep a snapshot.
keep in mind: • Dependencies/versions are important. ◦ If a model is saved with a version of a library, make sure you load with the same version • You can pickle any python object, hence do not open a pickle that you do not trust ◦ It could contain anything
tune` ◦ This will use parameters defined in config.py • Train the model with `python run.py train` ◦ This use parameters defined in config.py • Test the model with `python run.py test`
same dtypes • Have a requirements.txt with versions of the libraries you use • If making incremental changes, make sure you check the tuning CV score ◦ Not the one on the test set • With modular code, you can more easily write tests! (and you should) • With all that, updating your models should be less stressful.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Column Transformer num_cols = ["age", "salary"] cat_cols = ["country", "gender"]](https://files.speakerdeck.com/presentations/9138746056024922bd28269008214cc3/slide_25.jpg){kind=link}
![Column Transformer ColumnTransformer([("pca", PCA(), num_cols),("one_hot", OneHotEncoder(), cat_cols)]) Numerical Columns PCA](https://files.speakerdeck.com/presentations/9138746056024922bd28269008214cc3/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Pipeline Pipeline([("scaler", StandardScaler()), ( "pca", PCA())]) Original DataFrame DataFrame Scaled](https://files.speakerdeck.com/presentations/9138746056024922bd28269008214cc3/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}