Deep Learning is all the rage, but ensemble models are still in the game. With libraries such as the recent and performant LightGBM, the Kaggle superstar XGboost or the classic Random Forest from scikit-learn, ensembles models are a must-have in a data scientist’s toolbox. They’ve been proven to provide good performance on a wide range of problems, and are usually simpler to tune and interpret.
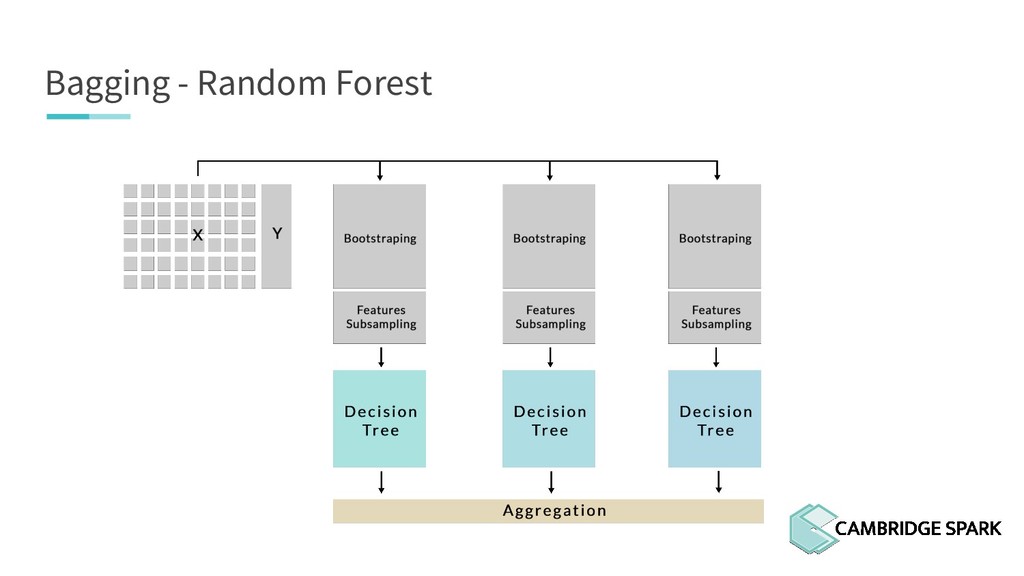
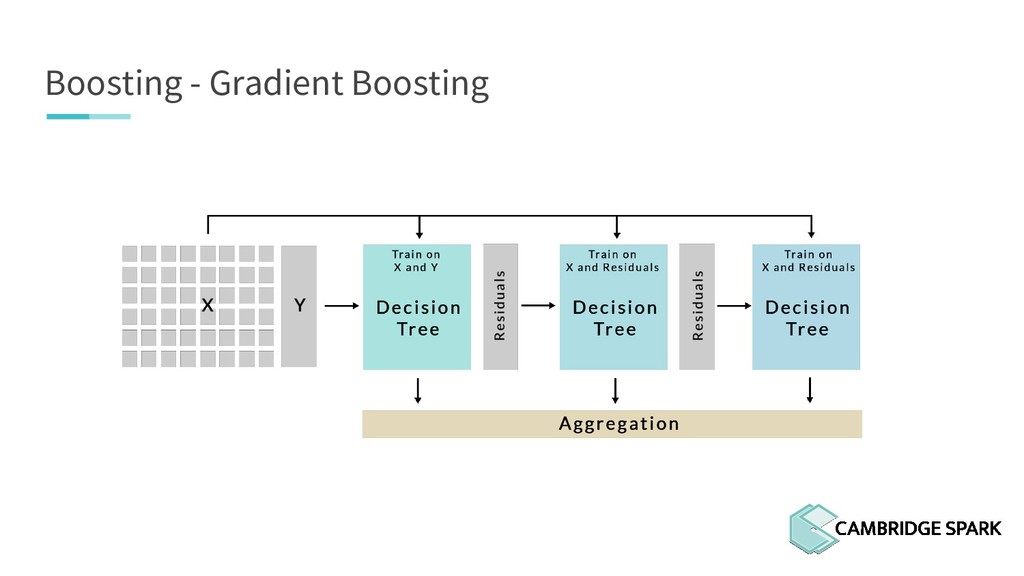
This talk focuses on two of the most popular tree-based ensemble models. You will learn about Random Forest and Gradient Boosting, relying respectively on bagging and boosting. This talk will attempt to build a bridge between the theory of ensemble models and their implementation in Python.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}