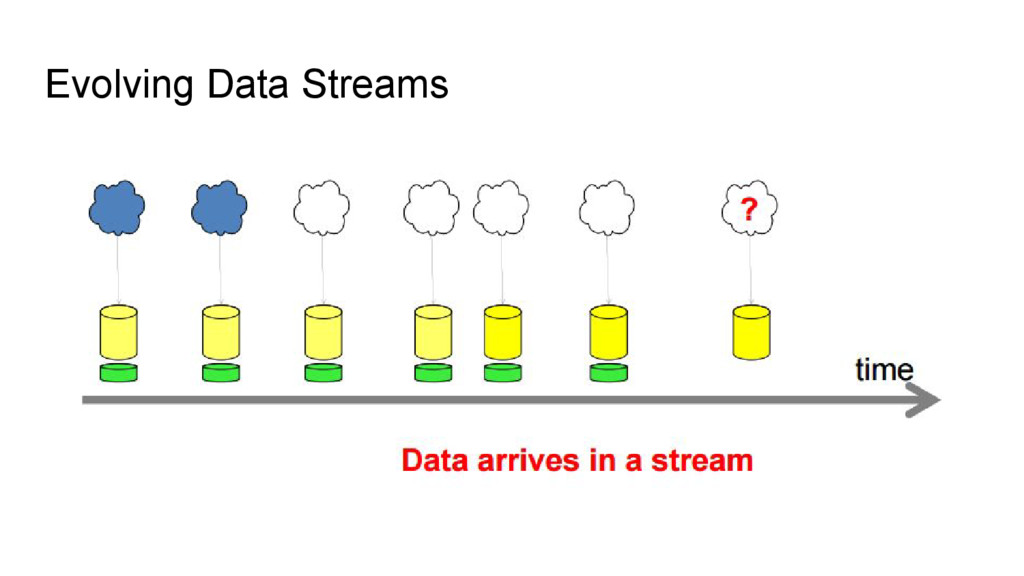
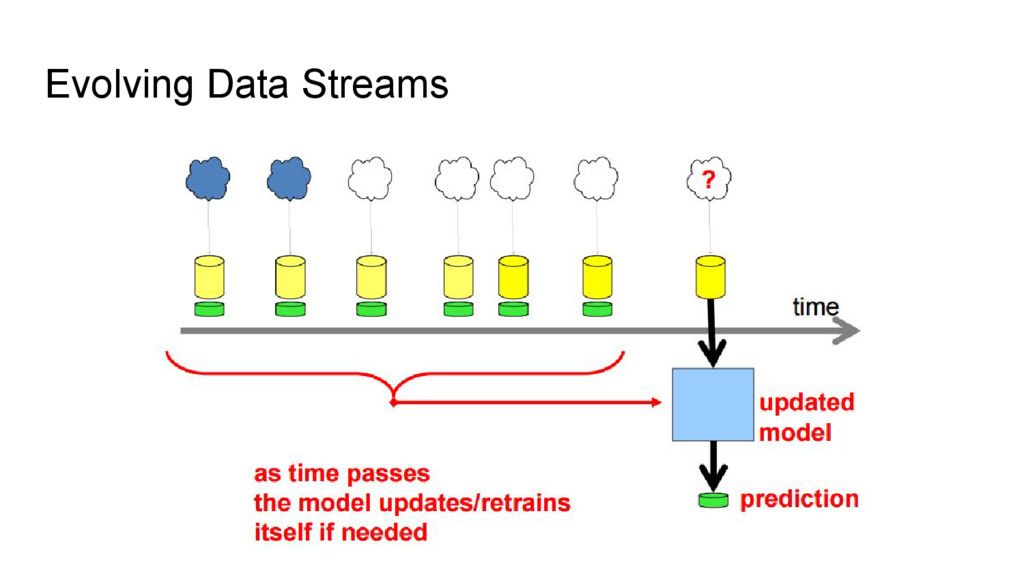
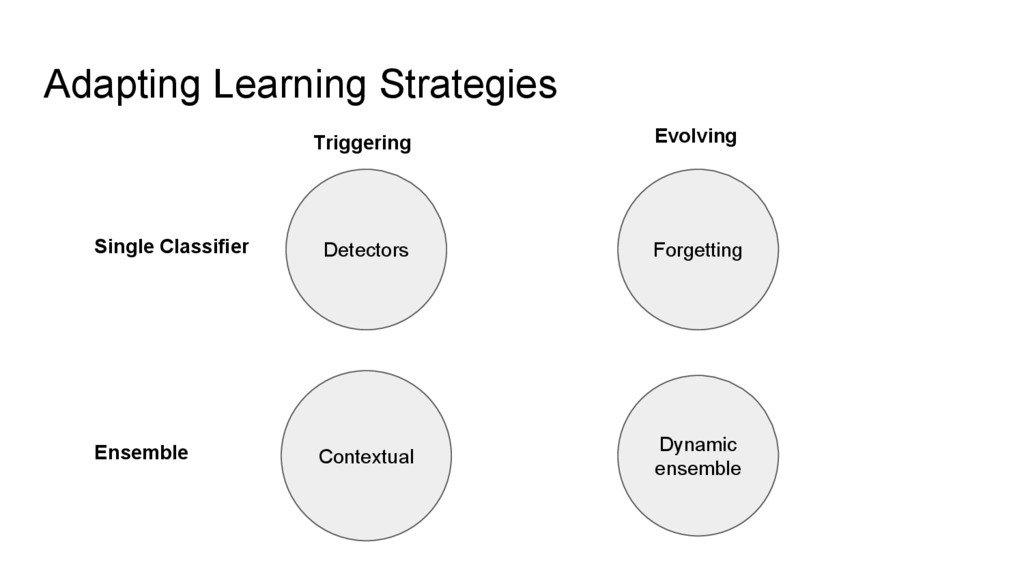
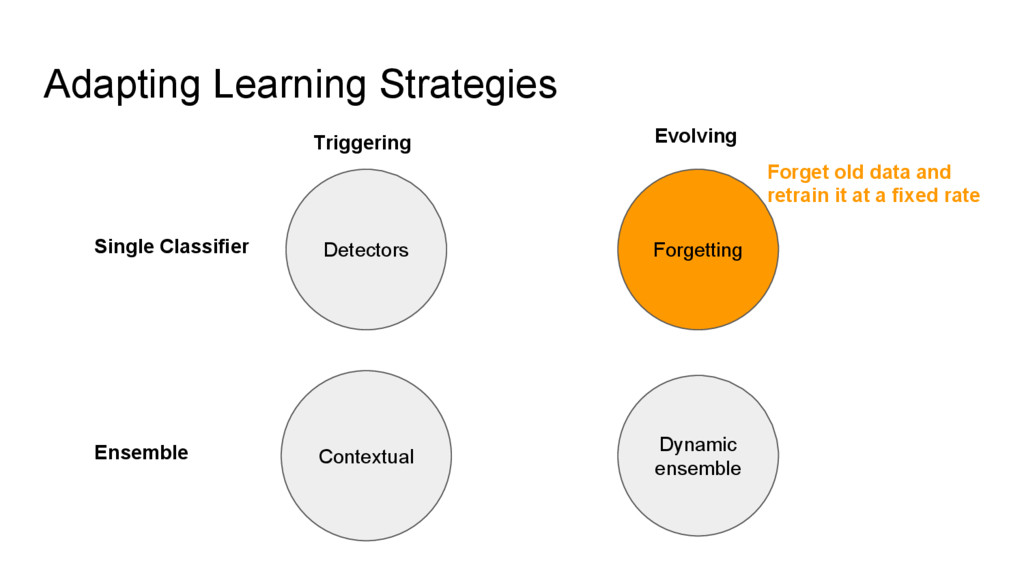
WEKA dan MOA adalah kakas untuk melakukan data mining. Kakas ini tersedia sebagai library java dan sebagai aplikasi desktop. Pada techtalk kali ini dibahas mengenai MOA, WEKA, perbedaan di antara keduanya, serta sedikit penjelasan mengenai penanganan data stream yang merupakan latar belakang dibuatnya MOA.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
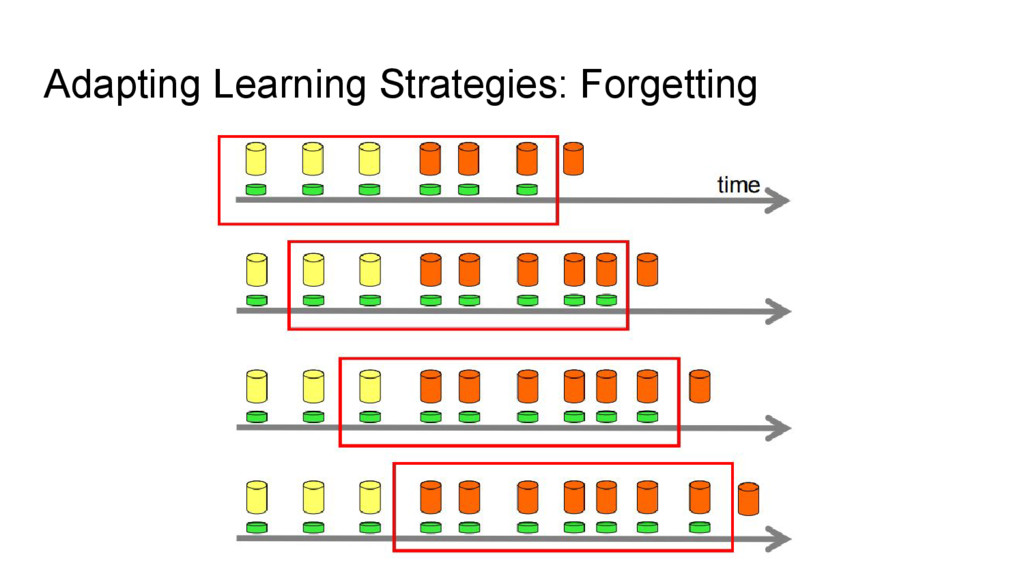{kind=link}
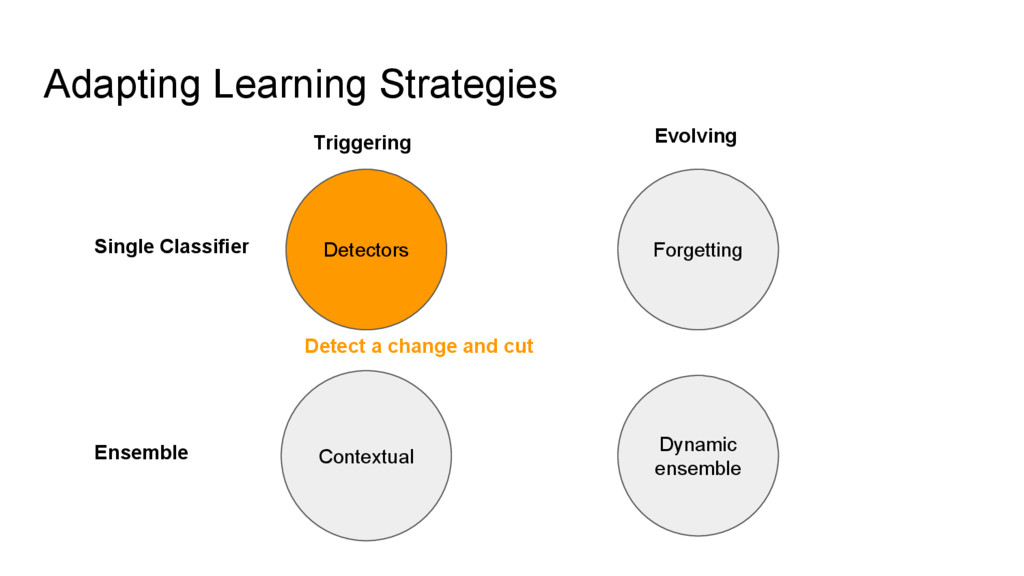{kind=link}
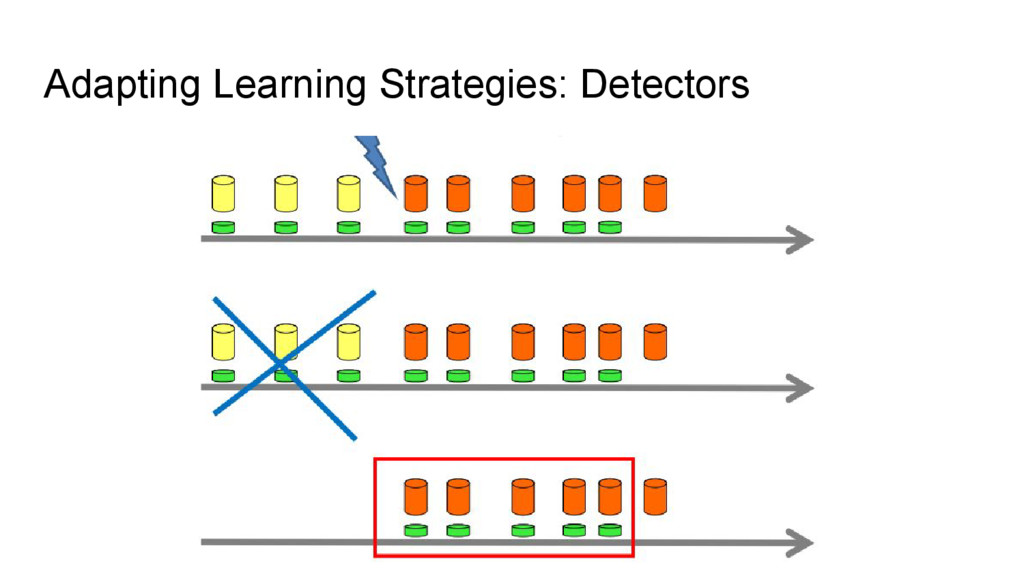{kind=link}
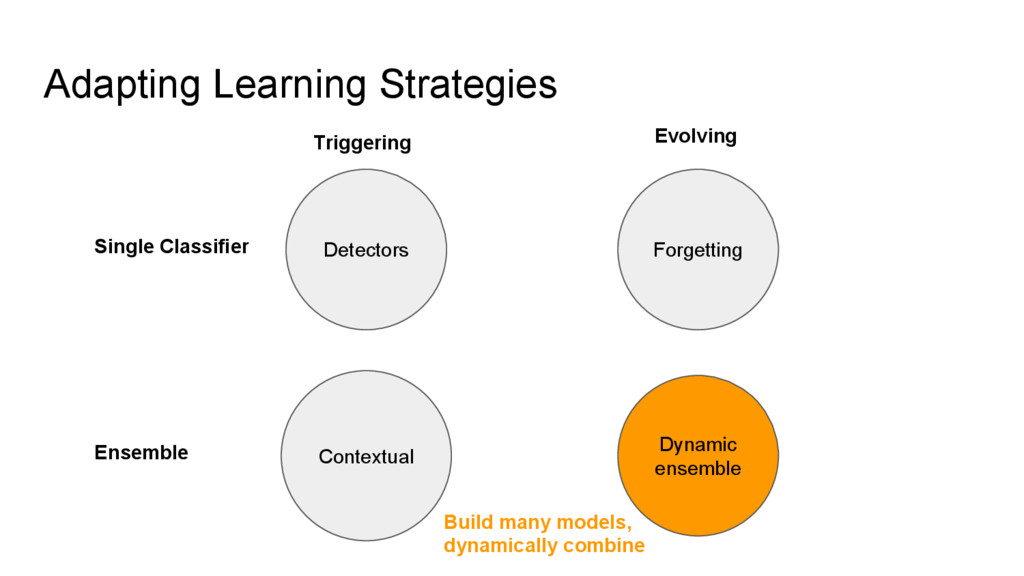{kind=link}
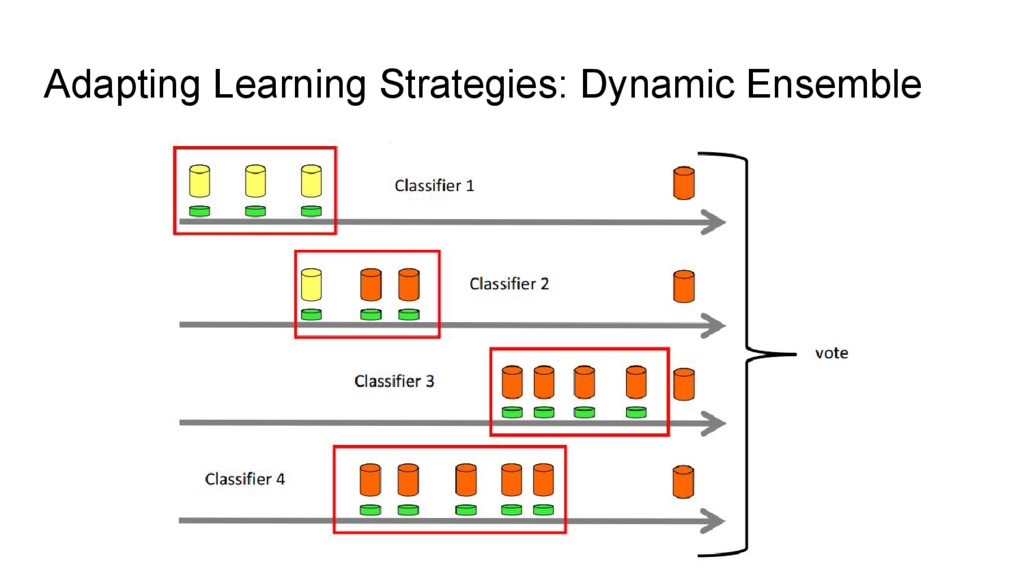{kind=link}
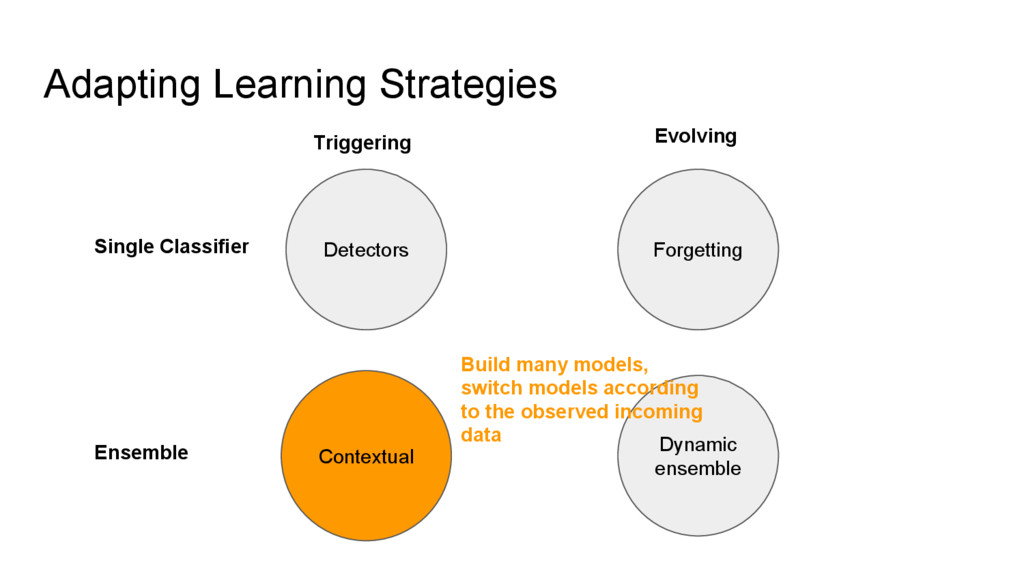{kind=link}
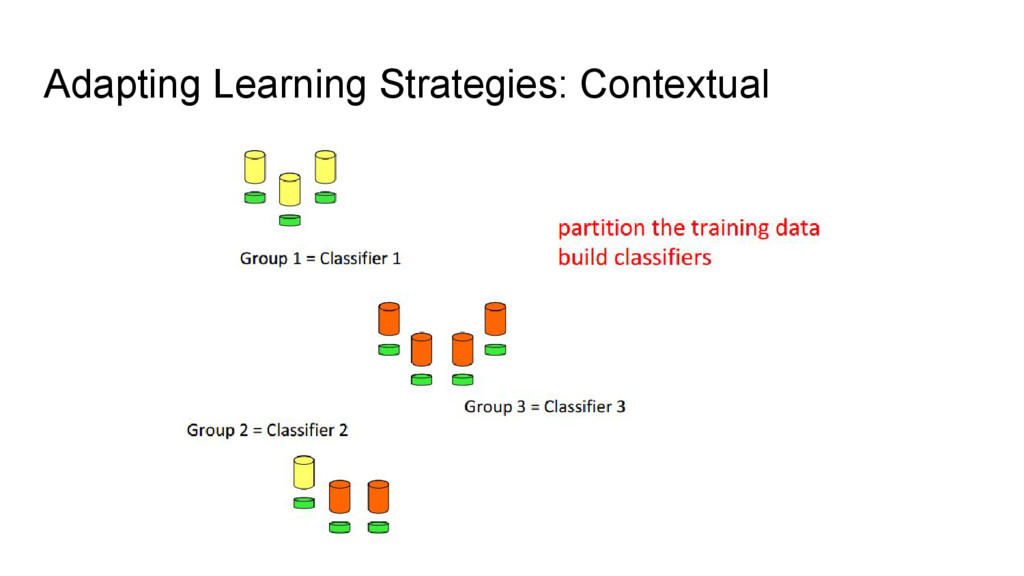{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}