day at one of the companies I worked for. • I was about to leave office but then sh*t hit the fan - production fell just before a crucial POC • I had no context • There was no deployment took place that day • There was no single person who could investigate by their own • R&D blamed DevOps, DevOps blamed R&D. Rings a bell? My (Human) Experience with Incident Response
Players • Context-Rich vs. AI-Wrapper • Chatbot vs. UI • Opinionated vs. Deterministic • Agent vs. Multi-Agent • Point Solution vs. Platform The AI SRE Landscape
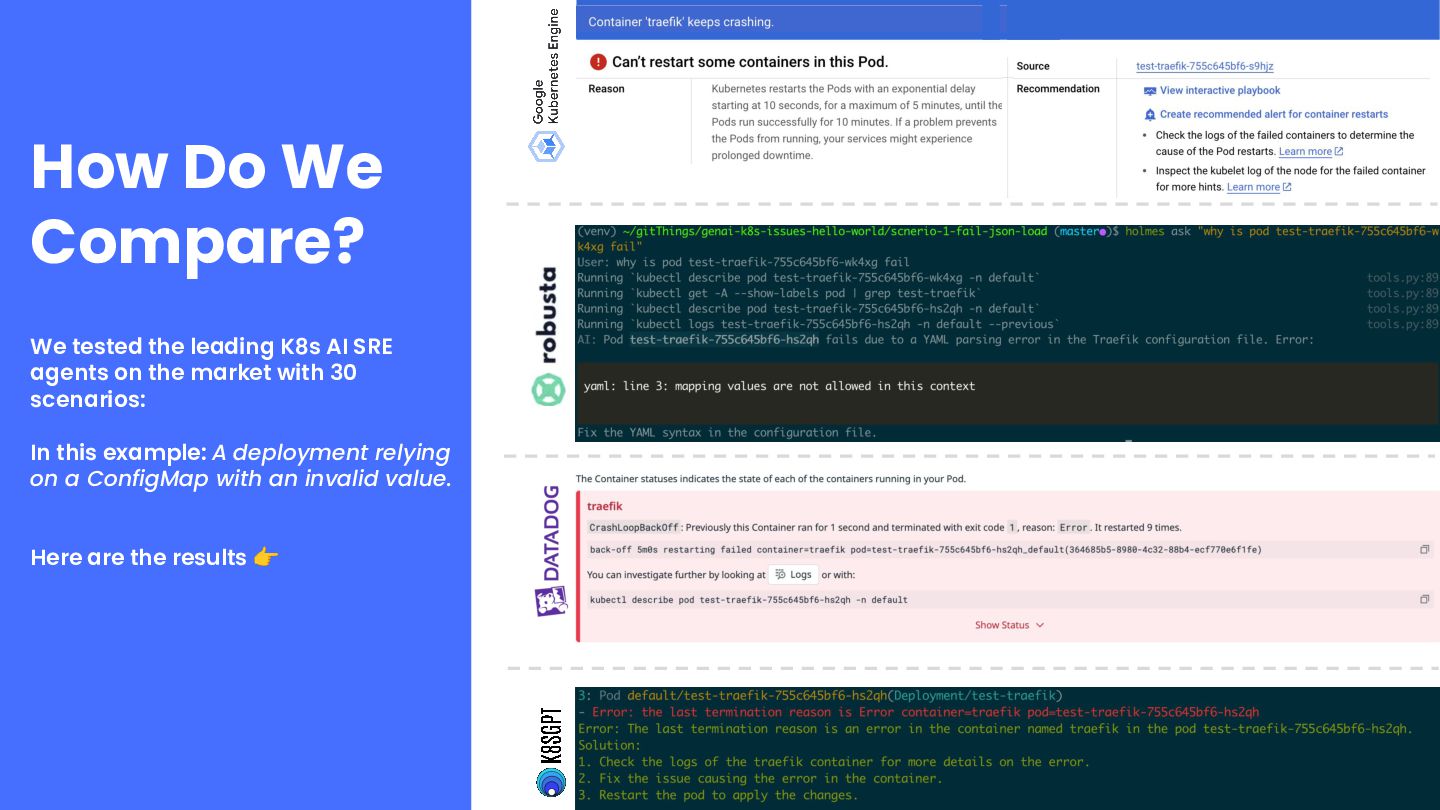
complicated • Lots of disparate data across the Cloud-Native stack • Hard to determine quality in a lab setting • Each infrastructure is uniquely intricate • Missing context & data quality • Many different LLMs and frameworks The Evaluation Challenge
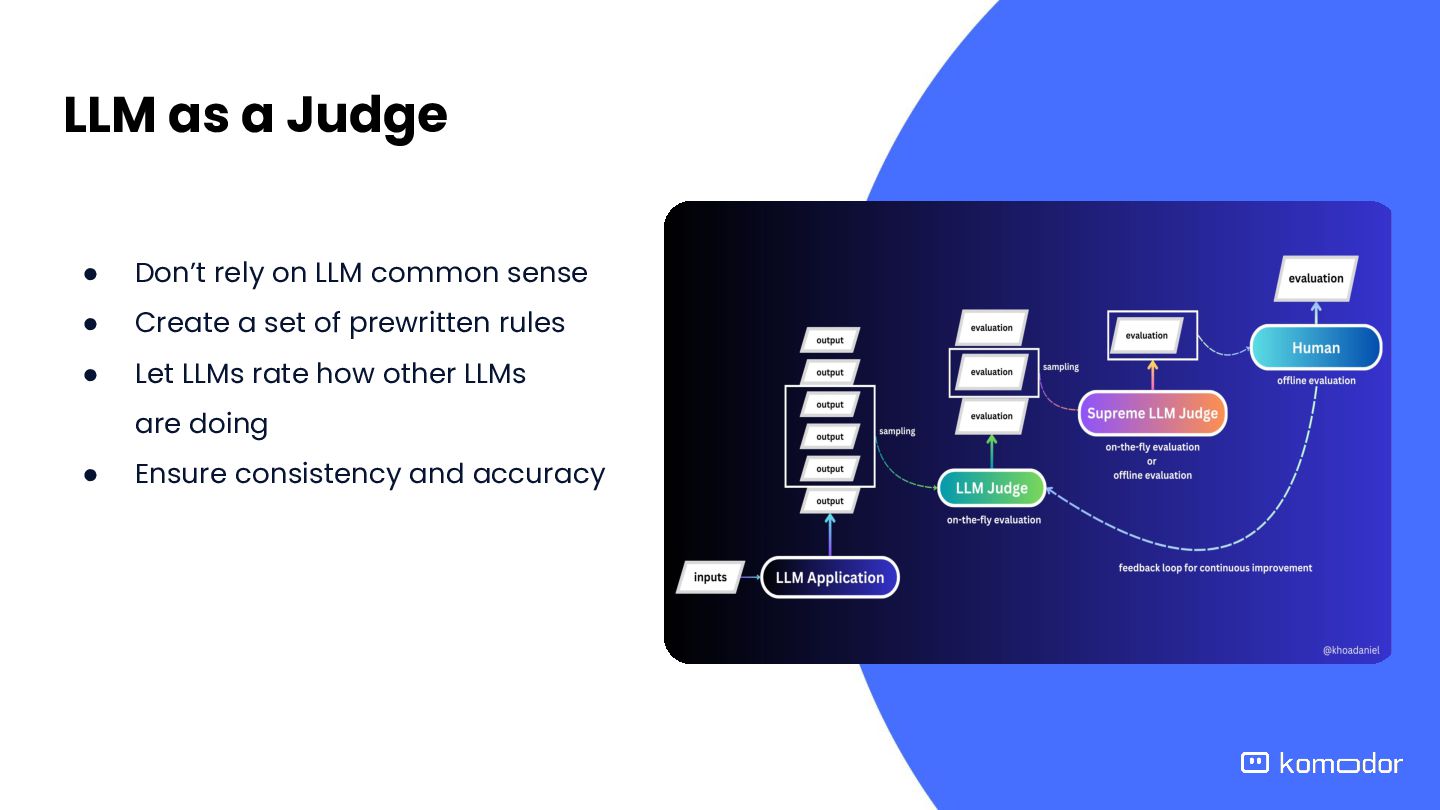
golden standards for instant model feedback against expert benchmarks. • Comprehensive test scenarios: Maintains dozens of real Kubernetes failure cases with detailed golden standard investigations defining what excellent root cause analysis should look like • Instant feedback loop: Enables immediate evaluation of new models and algorithm changes against established benchmarks, accelerating development cycles • Quality benchmarking: Provides objective measurement of investigation quality by comparing agent outputs against expert-crafted golden standards for each failure scenario
technical accuracy, investigation depth, reasoning quality, and actionability using standardized criteria • Objective comparison: Systematically compares agents to identify superior approaches, like detecting complete causal chains versus symptom-focused analysis • Scalable assessment: Enables rapid evaluation of multiple agent variants simultaneously, accelerating our development cycle without human bottlenecks
models fast • To stay ahead of the curve you need to quickly assess new models and new use-cases • Is Sonnet 3.7 better than 3.5? Is DeepSeek better than Claude?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}