popular, yet its complexity often leave users struggling when issues arise. At Komodor, we saw an opportunity to leverage the wealth of data already existing within clusters to help users identify and resolve complex problems. Our journey wasn’t straightforward. Kubernetes is a dynamic system with numerous moving parts, generating an enormous amount of data. Through our “Reliability Insights” project, we aimed to analyze raw data from hundreds of Kubernetes clusters and transform it into actionable intelligence. Extensive research and experimentation led us to develop methods to clean and process this data, uncovering remarkable findings. We identified multiple types of reliability-related insights, each offering a unique perspective on cluster health and performance. In this talk, we’ll share our journey of discovery. We’ll explore how we combined various data points to reveal hidden issues, discuss the challenges we faced in making sense of Kubernetes’ vast data landscape, and demonstrate how these insights can level up one’s cluster reliability management. Join us to learn how extracting meaningful patterns from the complex world of Kubernetes can transform your understanding of what is going on in your infrastructure.
much like a living organism: pods spawn and terminate like a heartbeat, nodes scale up and down like breaths, and events trigger like nerve impulses. While biological organisms are flawless, technical systems always have room for improvement. By observing these systems closely over time, one can figure out the ways to enhance them. However, due to human limitations in processing vast amounts of data manually, we have to use tools to analyze raw data and provide actionable insights for k8s users. Within the Komodor platform, data from hundreds of Kubernetes clusters flows continuously, placing us in a unique position to analyze this data for the benefit of our customers. This led to the initiation of the "Reliability Insights" project, which, after extensive research and experimentation, has become an integral part of our main platform. During our research, we identified a dozen of types of reliability-related insights. While only two-thirds of these insights made it into the final product, all of them were valuable, and some of the unreleased ones were particularly cool. In this talk, we will share our observations and findings from the insights research, providing a deeper understanding of each type of insight and explaining the importance of analyzing the life of clusters from a higher-level perspective.
popularity and complexity mean that while many organizations eagerly adopt it, they often find themselves at a loss when issues arise. We saw an opportunity to leverage the wealth of data already existing within clusters to help users identify and resolve complex problems. Our journey wasn’t straightforward. Kubernetes is a living, breathing entity with numerous moving parts. Pods spawn and terminate like heartbeats, nodes scale up and down like breaths, and events trigger like nerve impulses. This constant flux generates an enormous amount of data, which, if properly harnessed, can provide invaluable insights. At Komodor, we’re in a unique position. Data from hundreds of Kubernetes clusters flows through our platform continuously. This led us to initiate the “Reliability Insights” project, aiming to analyze this raw data and transform it into actionable intelligence for our users. Through extensive research and experimentation, we developed methods to clean and process this data, uncovering some truly remarkable findings. We identified a dozen types of reliability-related insights, each offering a unique perspective on cluster health and performance. In this talk, we’ll share our journey of discovery. We’ll explore how we combined various data points to reveal hidden issues, discuss the challenges we faced in making sense of Kubernetes’ vast data landscape, and demonstrate how these insights can revolutionize the way teams approach cluster reliability. Join us as we delve into the art and science of extracting meaningful patterns from the seemingly chaotic world of Kubernetes, and learn how this approach can transform your ability to maintain and optimize your infrastructure.
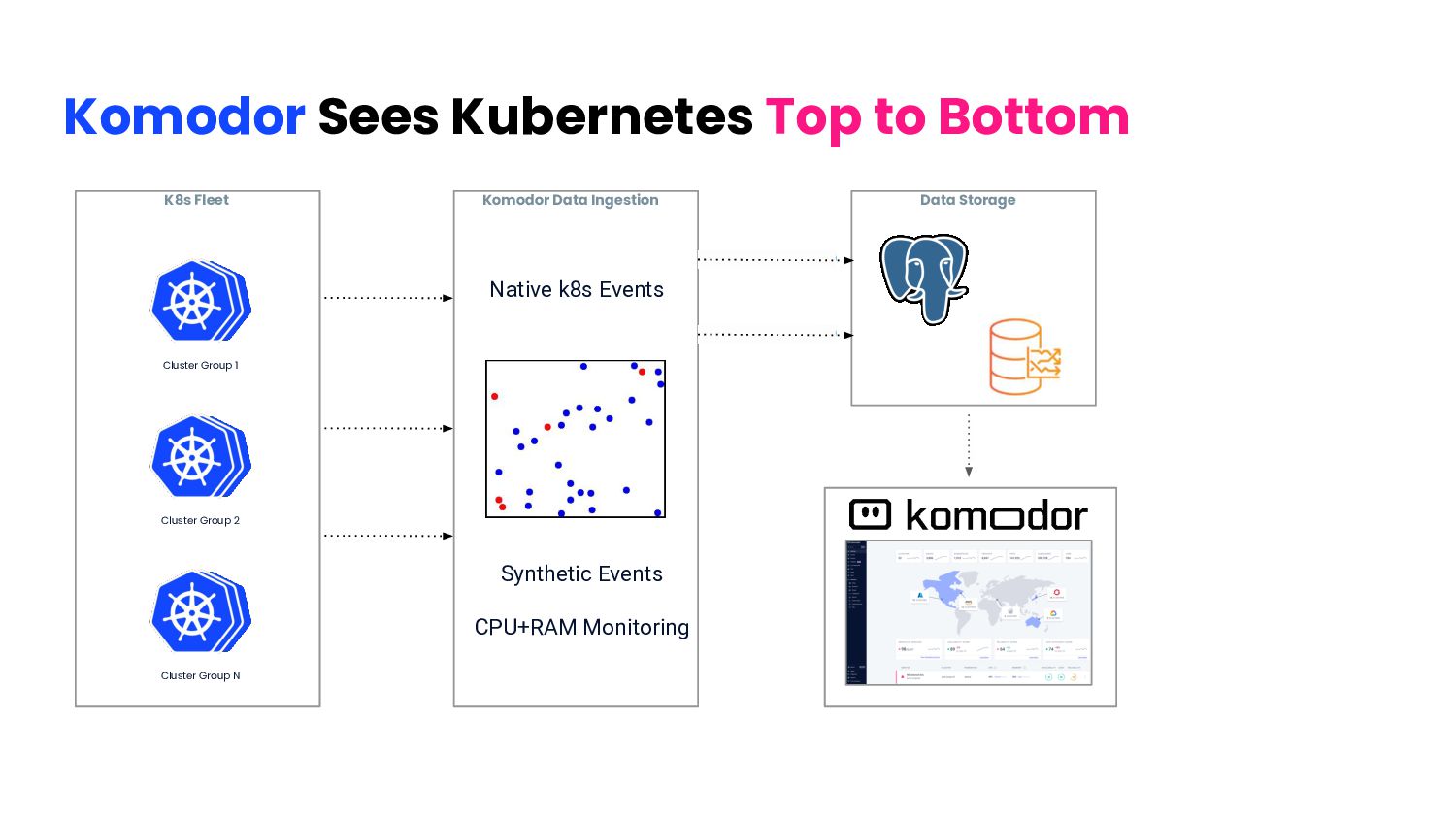
infrastructure layer on top of apps Simple signals everyone can see: statuses, events That information: + over time + inter-correlated Reliability Insights + cross-cluster
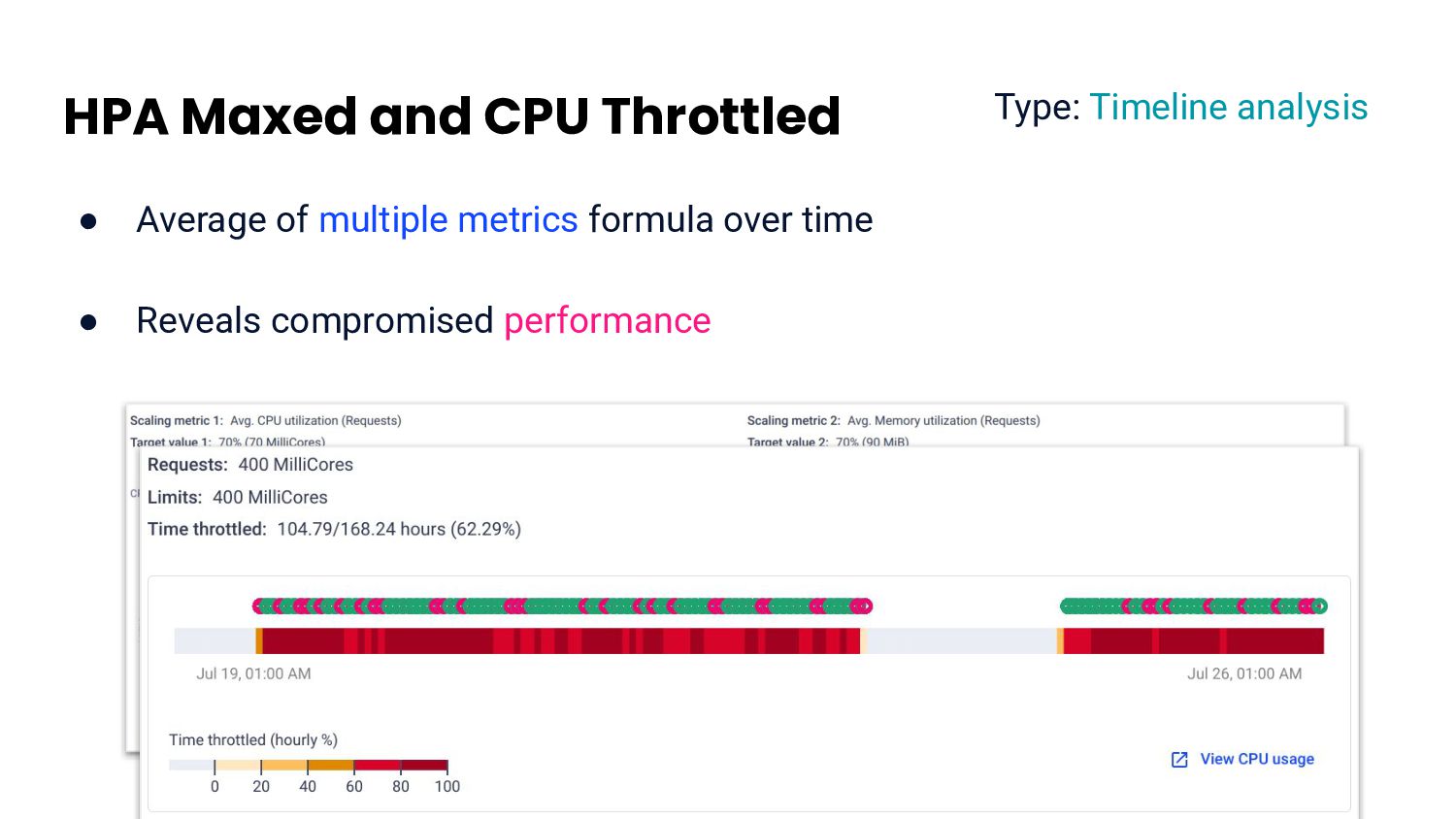
resource usage • Phase 2: k8s evicts workload B from nodes • Above situation happens statistically over time • Expensive and tricky to calculate Type: Timeline and correlation analysis
• For the SPOT instance lovers, also node autoscaling • Pod termination statistics • Resulting reliability issues • Expensive to calculate Type: Correlation analysis
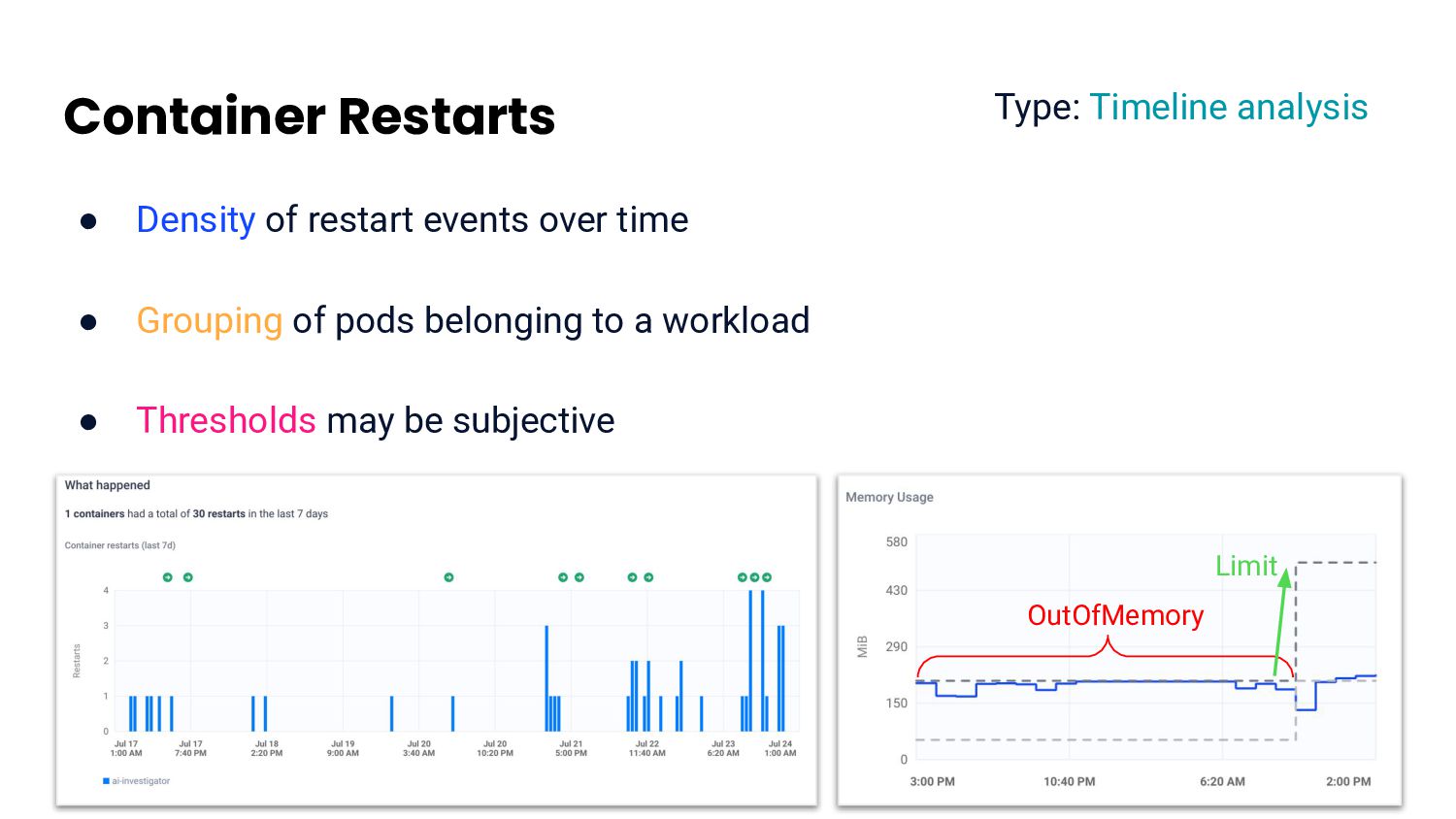
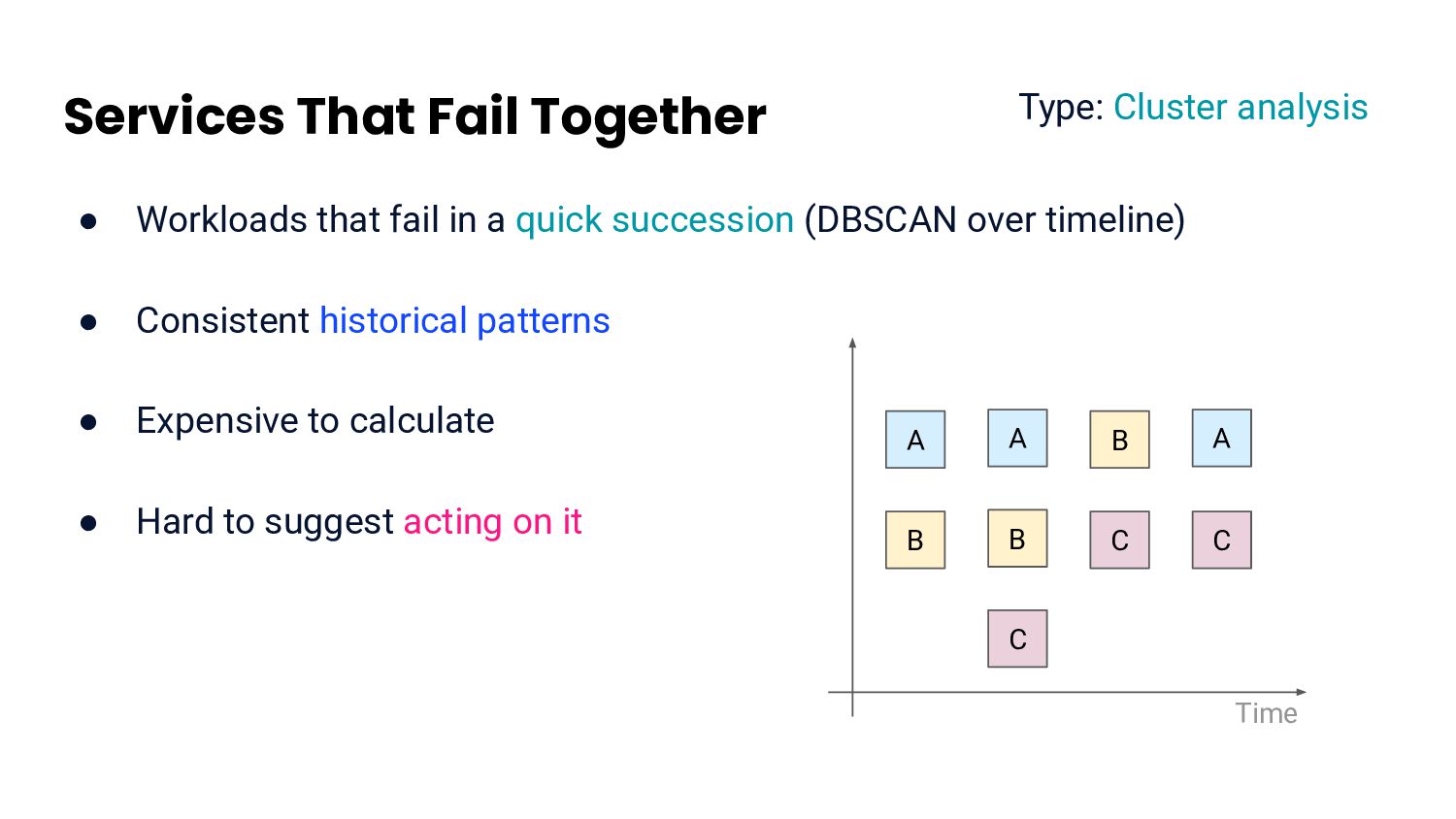
quick succession (DBSCAN over timeline) • Consistent historical patterns • Expensive to calculate • Hard to suggest acting on it Type: Cluster analysis A B A B C B C A C Time
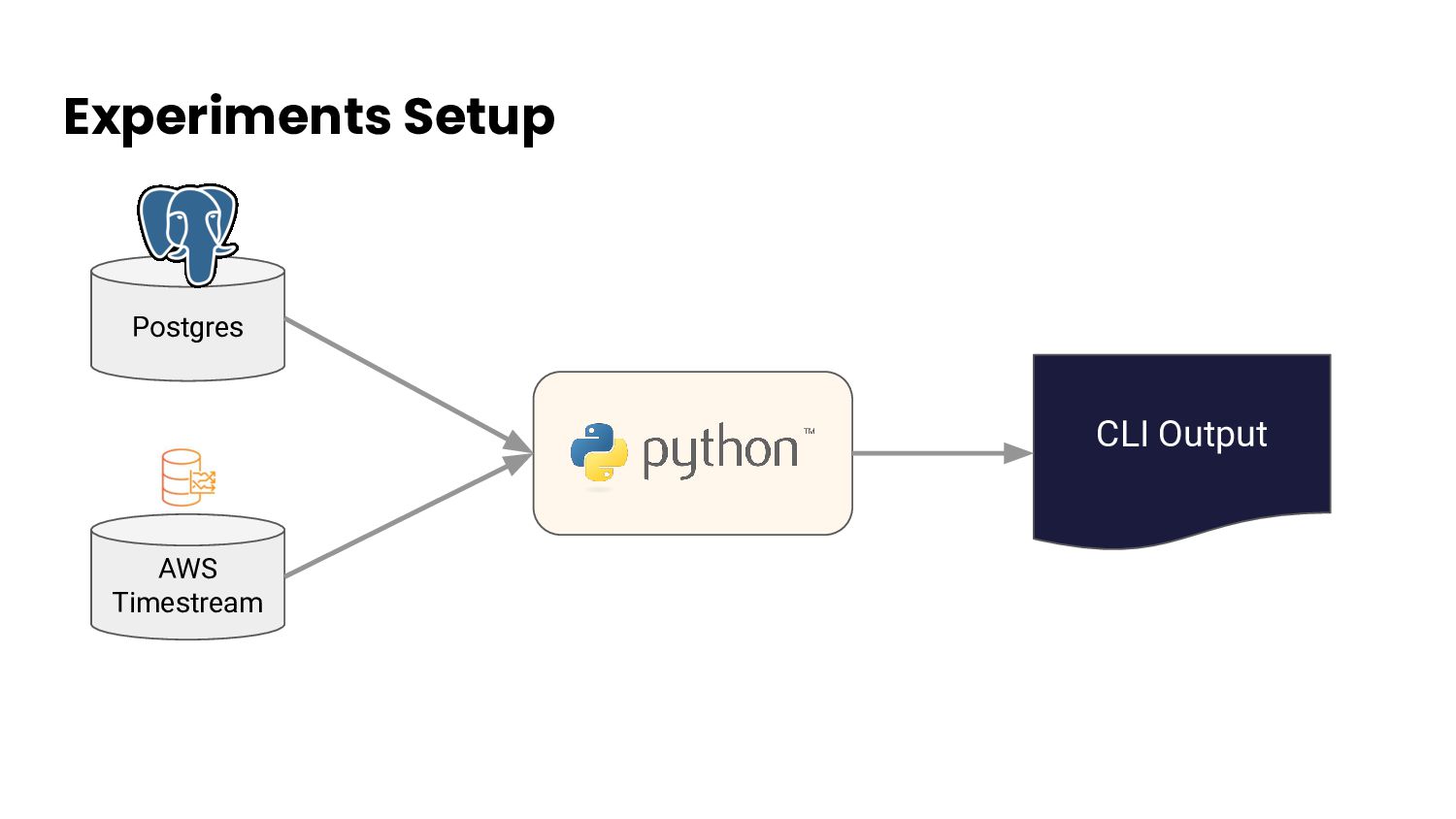
from basic Kubernetes info • Implementation is challenging and resource-intensive • Some insights are viable, others are not • Komodor Platform provides good examples
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}