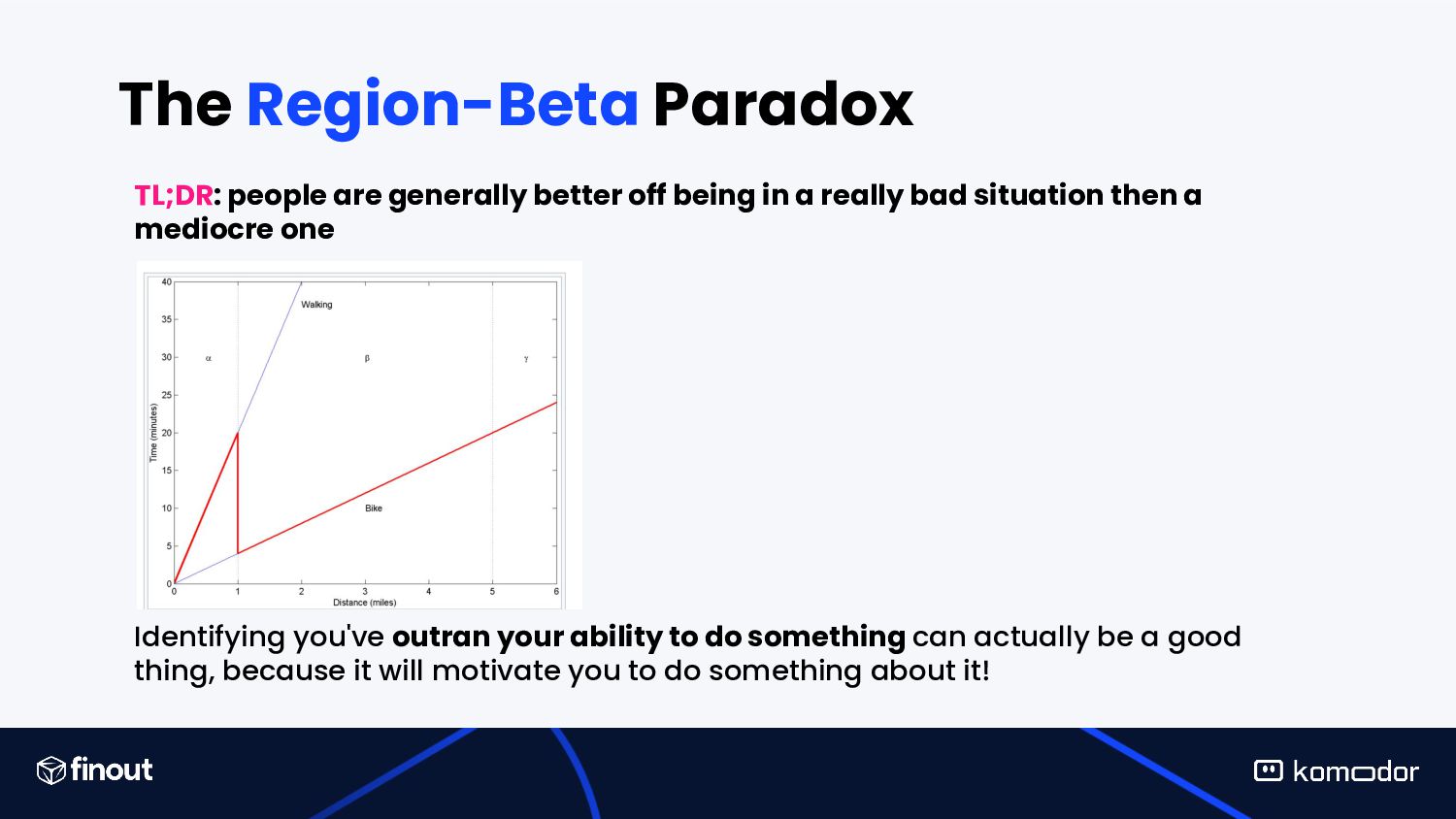
in a really bad situation then a mediocre one Identifying you've outran your ability to do something can actually be a good thing, because it will motivate you to do something about it!
from developers_who_can_solve_this; – 1 line returned timeouts in query(find_rootcause) is taking more than expected and affecting business locate `$$$`
down - what used to take us a fraction of the time now takes too long select * from developers_who_can_solve_this; – 1 line returned timeouts in query(find_rootcause) is taking more than expected and affecting business locate `$$$`
down - what used to take us a fraction of the time now takes too long We all have that one engineer that knows how to fix that one thing that keeps on happening and without him everything goes bananas timeouts in query(find_rootcause) is taking more than expected and affecting business locate `$$$`
down - what used to take us a fraction of the time now takes too long We all have that one engineer that knows how to fix that one thing that keeps on happening and without him everything goes bananas We spend too long trying to understand the root causes for production issues We can’t make sense of what’s draining our resources
engineering team solving critical bugs: how many people are actually solving the problem MTTR & MTTD: how long it takes to resolve an incident, once the RC is detected. How long to detect an incident in the first place? Onboarding to activation time: how long before a new dev becomes effective in the team and starts adding value (i.e ready to take on-call shifts) Costs: cloud providers, 3rd party integrations
increased in the last Quarter by 20% Question: Why does it take us longer to discover issues? 1. Lack of knowledge by the devs doing on-call duty? ◦ Train on-call engineers ◦ Document playbooks for what to do when such errors arise ◦ Use tools that democratize knowledge around that area 2. Lack of tooling to allow us to pinpoint the root cause quickly? ◦ Logs metrics and APMs for the win 3. Lack of processes to determine who should handle which errors? ◦ Are the right people looking at the issues?
next - look at the bigger picture! • IF the problem was mitigated by creating metrics and logs for the issues that we’re currently facing • THEN install a process that enforces APMs logs or metrics for new features as part of a DoD for any delivery
![The Fast [DEV] & The Furious [CFO] The true cost](https://files.speakerdeck.com/presentations/bbcc709566e94e4c96fc1741dbef44e0/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}