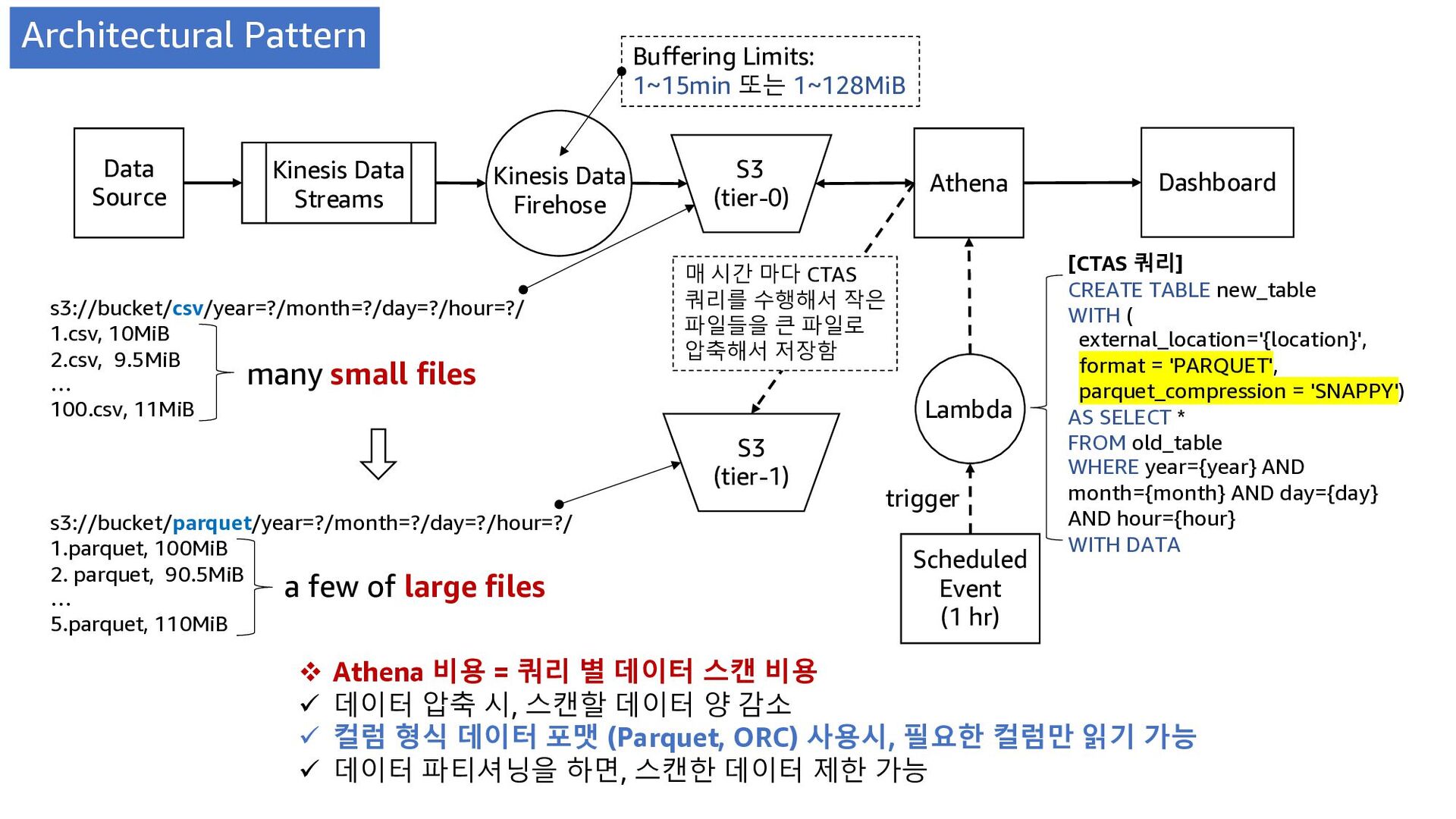
Limits: 1~15min 또는 1~128MiB v Athena 비용 = 쿼리 별 데이터 스캔 비용 ü 데이터 압축 시, 스캔할 데이터 양 감소 ü 컬럼 형식 데이터 포맷 (Parquet, ORC) 사용시, 필요한 컬럼만 읽기 가능 ü 데이터 파티셔닝을 하면, 스캔한 데이터 제한 가능 Lambda Scheduled Event (1 hr) s3://bucket/csv/year=?/month=?/day=?/hour=?/ 1.csv, 10MiB 2.csv, 9.5MiB … 100.csv, 11MiB many small files s3://bucket/parquet/year=?/month=?/day=?/hour=?/ 1.parquet, 100MiB 2. parquet, 90.5MiB … 5.parquet, 110MiB a few of large files Dashboard [CTAS 쿼리] CREATE TABLE new_table WITH ( external_location='{location}', format = 'PARQUET', parquet_compression = 'SNAPPY') AS SELECT * FROM old_table WHERE year={year} AND month={month} AND day={day} AND hour={hour} WITH DATA trigger S3 (tier-0) S3 (tier-1) Architectural Pattern 매 시간 마다 CTAS 쿼리를 수행해서 작은 파일들을 큰 파일로 압축해서 저장함
JSON 보다 Apache Parquet, ORC, Avro 사용 ü잘 모르겠으면, Apache Parquet을 사용하자 • 데이터를 Partitioning 하고, 압축해서 저장하자 • S3 데이터 tiering 하자 - CTAS 쿼리를 이용 ü원본 파일과 ETL(Extract Transform Load) 처리한 파일을 구분하기 ü크기가 작은 파일들을 하나로 합쳐서 큰 파일로 만들기 • 사용자를 workgroups 로 관리하자 ü쿼리 실행 제한 및 그룹별 모니터링 가능
향상 팁 • https://aws.amazon.com/ko/blogs/korea/top-10-performance-tuning-tips-for-amazon-athena/ • Extract, Transform and Load data into S3 data lake using CTAS and INSERT INTO statements in Amazon Athena • https://aws.amazon.com/ko/blogs/big-data/extract-transform-and-load-data-into-s3-data-lake-using-ctas- and-insert-into-statements-in-amazon-athena/ • Using Amazon Redshift Spectrum, Amazon Athena, and AWS Glue with Node.js in Production • https://aws.amazon.com/ko/blogs/big-data/using-amazon-redshift-spectrum-amazon-athena-and-aws-glue- with-node-js-in-production/ • Separate queries and managing costs using Amazon Athena workgroups • https://aws.amazon.com/ko/blogs/big-data/separating-queries-and-managing-costs-using-amazon-athena- workgroups/ • Use CTAS statements with Amazon Athena to reduce cost and improve performance • https://aws.amazon.com/ko/blogs/big-data/using-ctas-statements-with-amazon-athena-to-reduce-cost-and- improve-performance/ • Build a Schema-On-Read Analytics Pipeline Using Amazon Athena • https://aws.amazon.com/ko/blogs/big-data/build-a-schema-on-read-analytics-pipeline-using-amazon- athena/
{kind=link}
{kind=link}
{kind=link}
{kind=link}