& Organization: Location: AI Researcher NVIDIA AI Research & Development Center Bioinformatics & Data Science Research Center Bina Nusantara (BINUS) University @Anggrek Campus University Ambassador & Certified Instructor NVIDIA Deep Learning Institute – Platinum Tier Instructor Jakarta 11530, Indonesia ksnugroho26{at}gmail.com | kuncahyo.nugroho{at}binus.edu ksnugroho.id
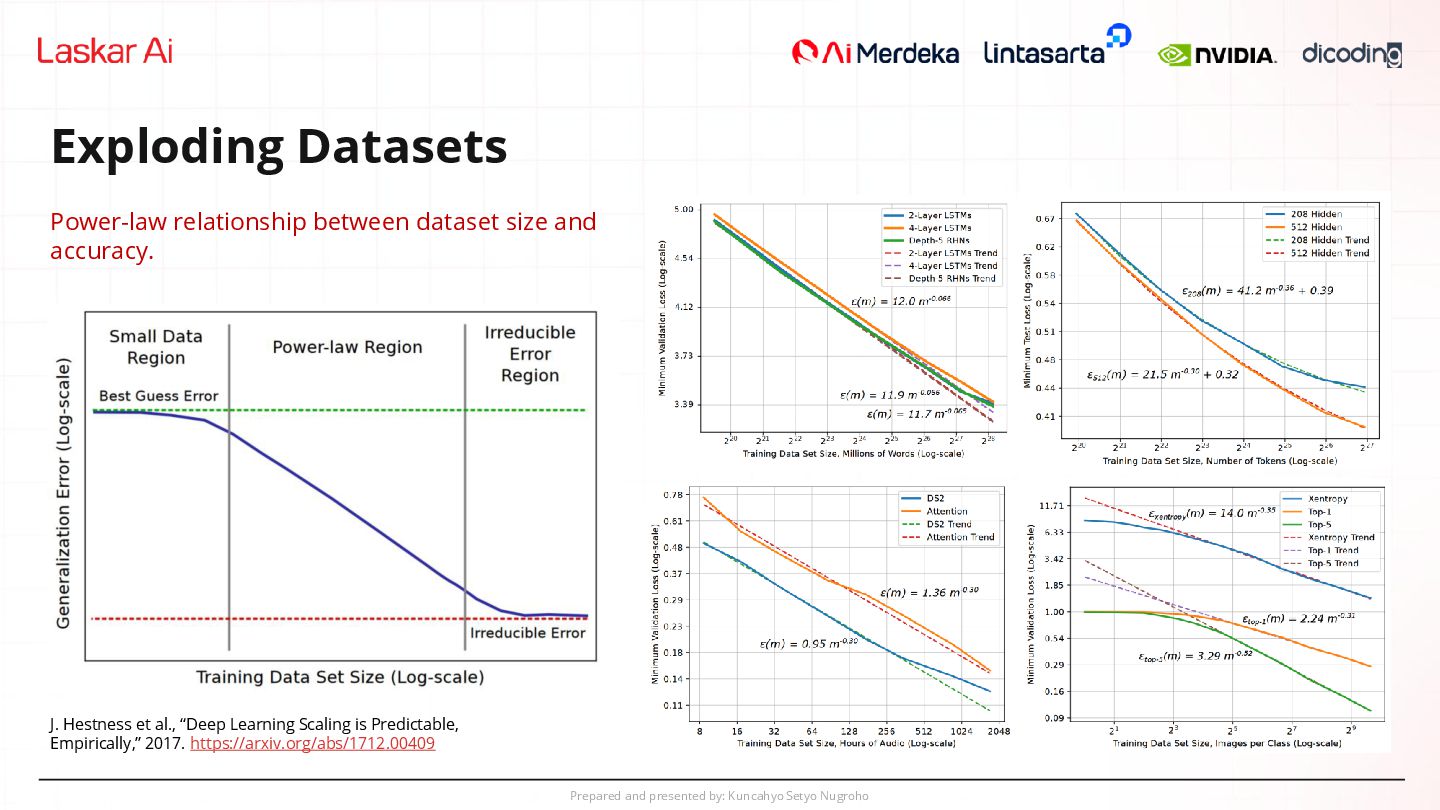
relationship between dataset size and accuracy. J. Hestness et al., “Deep Learning Scaling is Predictable, Empirically,” 2017. https://arxiv.org/abs/1712.00409
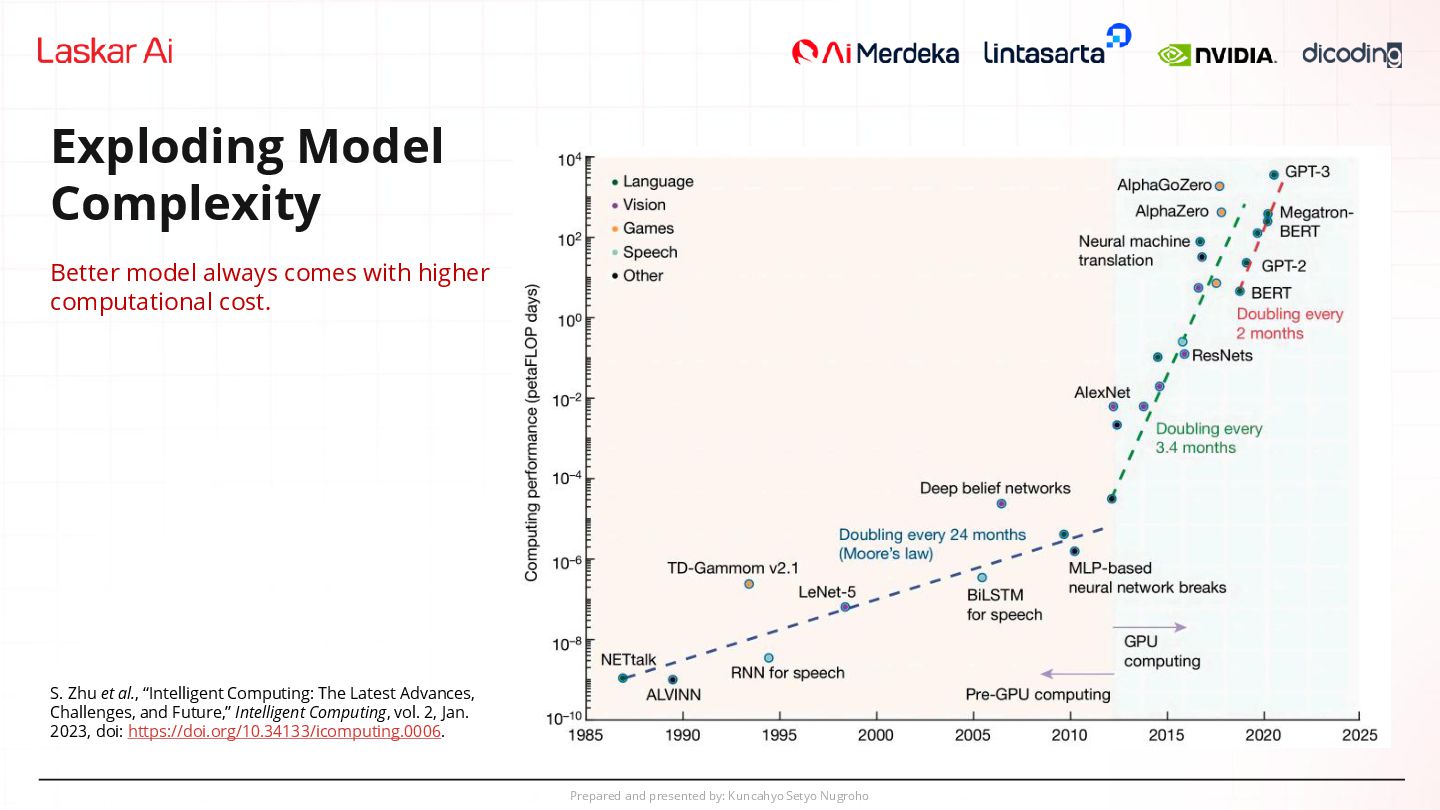
Better model always comes with higher computational cost. S. Zhu et al., “Intelligent Computing: The Latest Advances, Challenges, and Future,” Intelligent Computing, vol. 2, Jan. 2023, doi: https://doi.org/10.34133/icomputing.0006.
Bad News Good News: Requirements are predictable Bad News: The numbers can be massive We can estimate the amount of data needed to improve performance. Training large models often requires thousands of GPU-hours We can predict the compute resources required as models scale. The cost of compute and data curation can be prohibitive. Scaling laws give us a roadmap — we know what to expect. Deep learning has turned impossible problems into merely expensive ones.
Necessary! ▪ Developers / researchers’ time are more valuable than hardware. ▪ If a training take 10 GPU days ▪ Parallelize with distributed training. ▪ 1024 GPUs can finish in 14 minutes (ideally)! ▪ Deep learning is experimental; we need to train quickly to iterate. The develop and research cycle will be greatly boosted. ▪ Short iteration time is fundamental for success! Idea Code Experiment
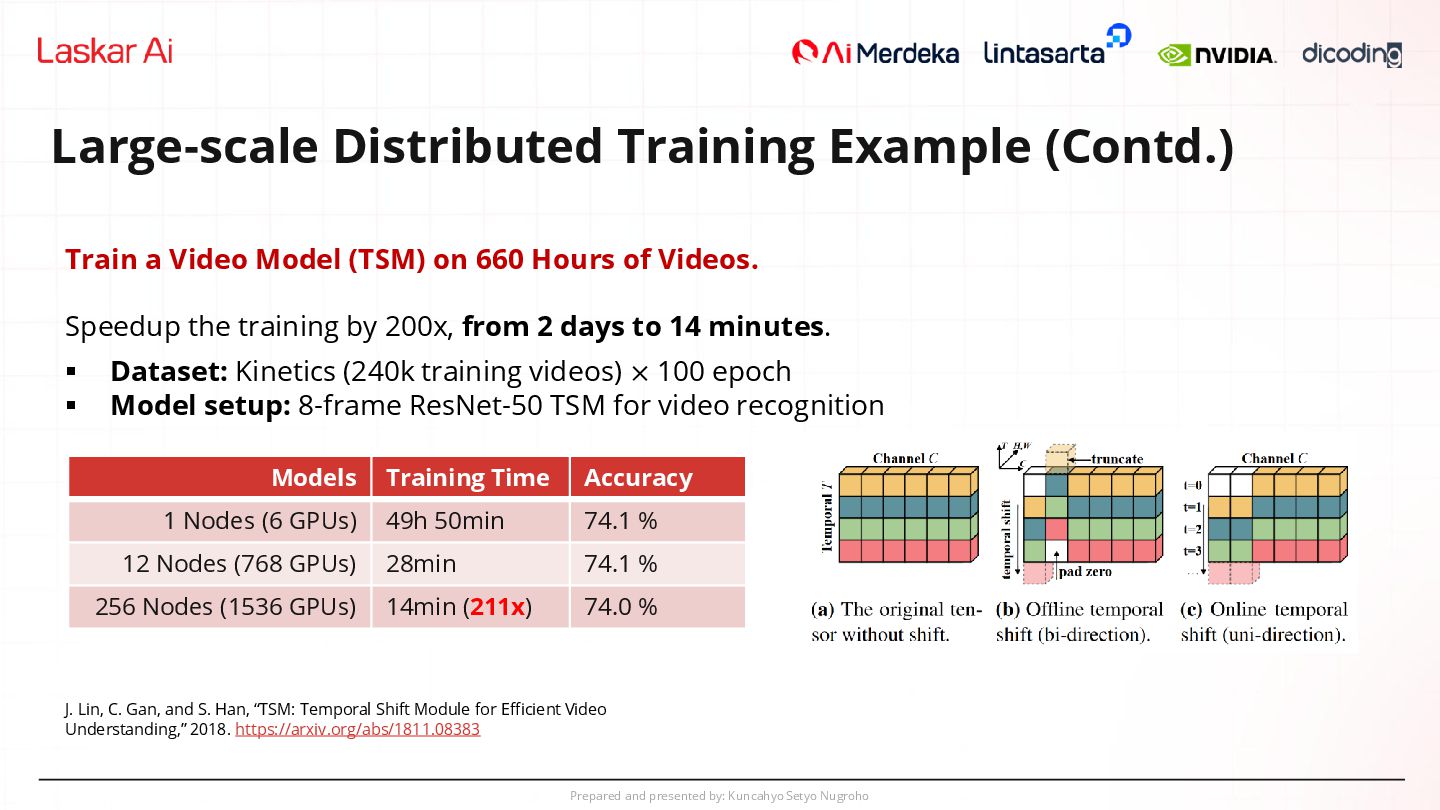
Example (Contd.) J. Lin, C. Gan, and S. Han, “TSM: Temporal Shift Module for Efficient Video Understanding,” 2018. https://arxiv.org/abs/1811.08383 Models Training Time Accuracy 1 Nodes (6 GPUs) 49h 50min 74.1 % 12 Nodes (768 GPUs) 28min 74.1 % 256 Nodes (1536 GPUs) 14min (211x) 74.0 % Train a Video Model (TSM) on 660 Hours of Videos. Speedup the training by 200x, from 2 days to 14 minutes. ▪ Dataset: Kinetics (240k training videos) × 100 epoch ▪ Model setup: 8-frame ResNet-50 TSM for video recognition
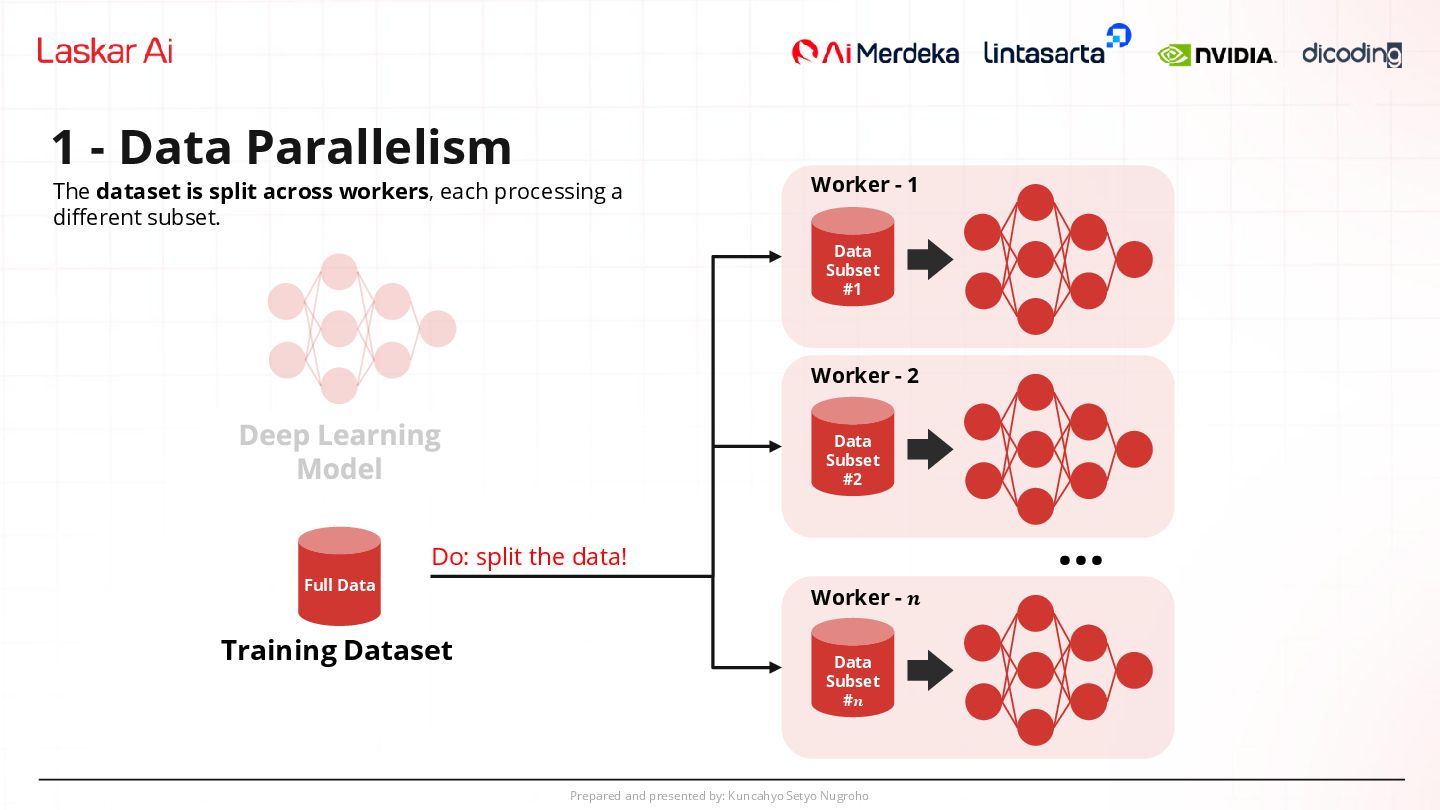
Parallelism Training Dataset ... Do: split the data! Worker - 1 Worker - 2 Worker - 𝒏 Data Subset #1 Data Subset #2 Data Subset #𝒏 Full Data The dataset is split across workers, each processing a different subset.
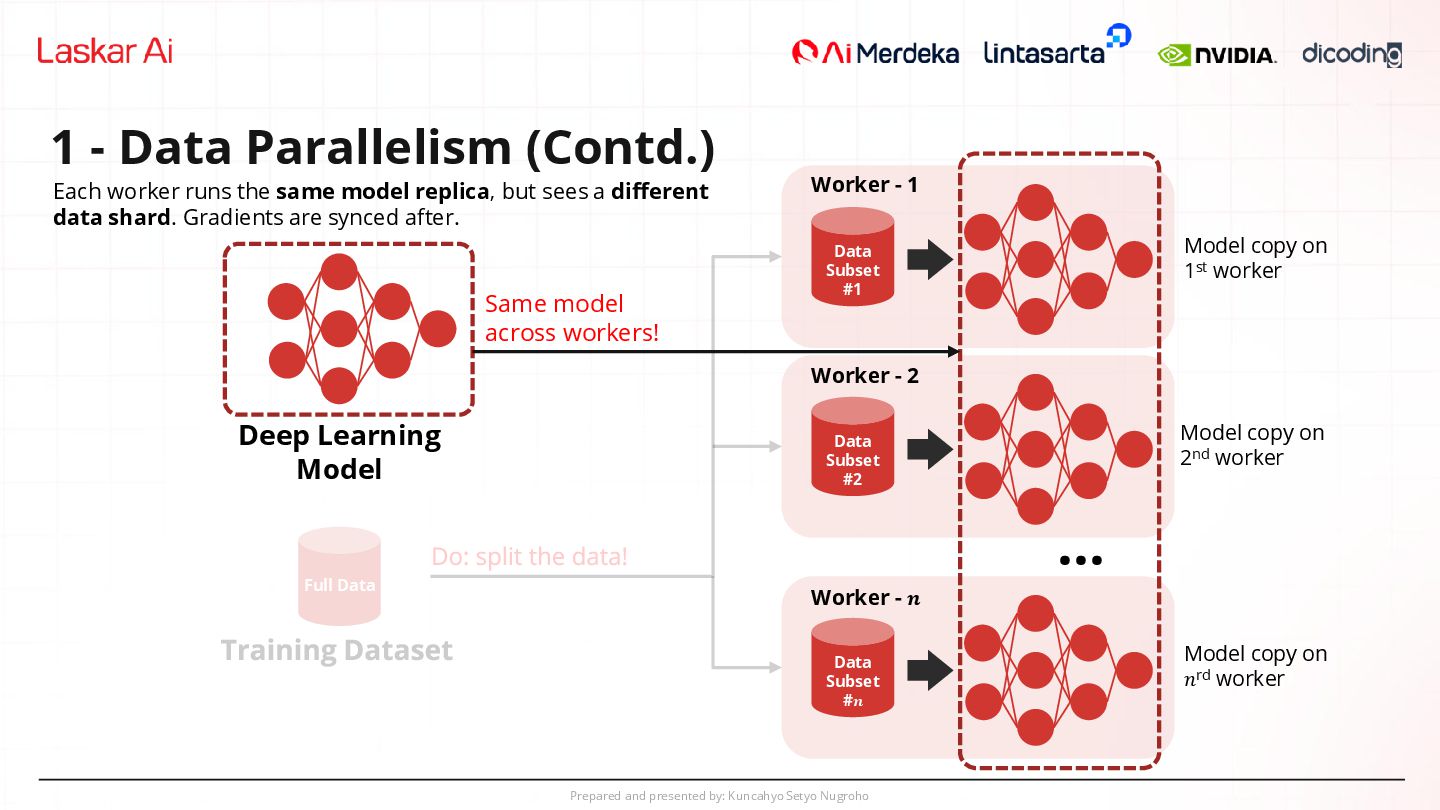
Parallelism (Contd.) Deep Learning Model Worker - 1 ... Worker - 2 Worker - 𝒏 Same model across workers! Data Subset #1 Data Subset #2 Data Subset #𝒏 Each worker runs the same model replica, but sees a different data shard. Gradients are synced after. Full Data Model copy on 1st worker Model copy on 2nd worker Model copy on 𝑛rd worker
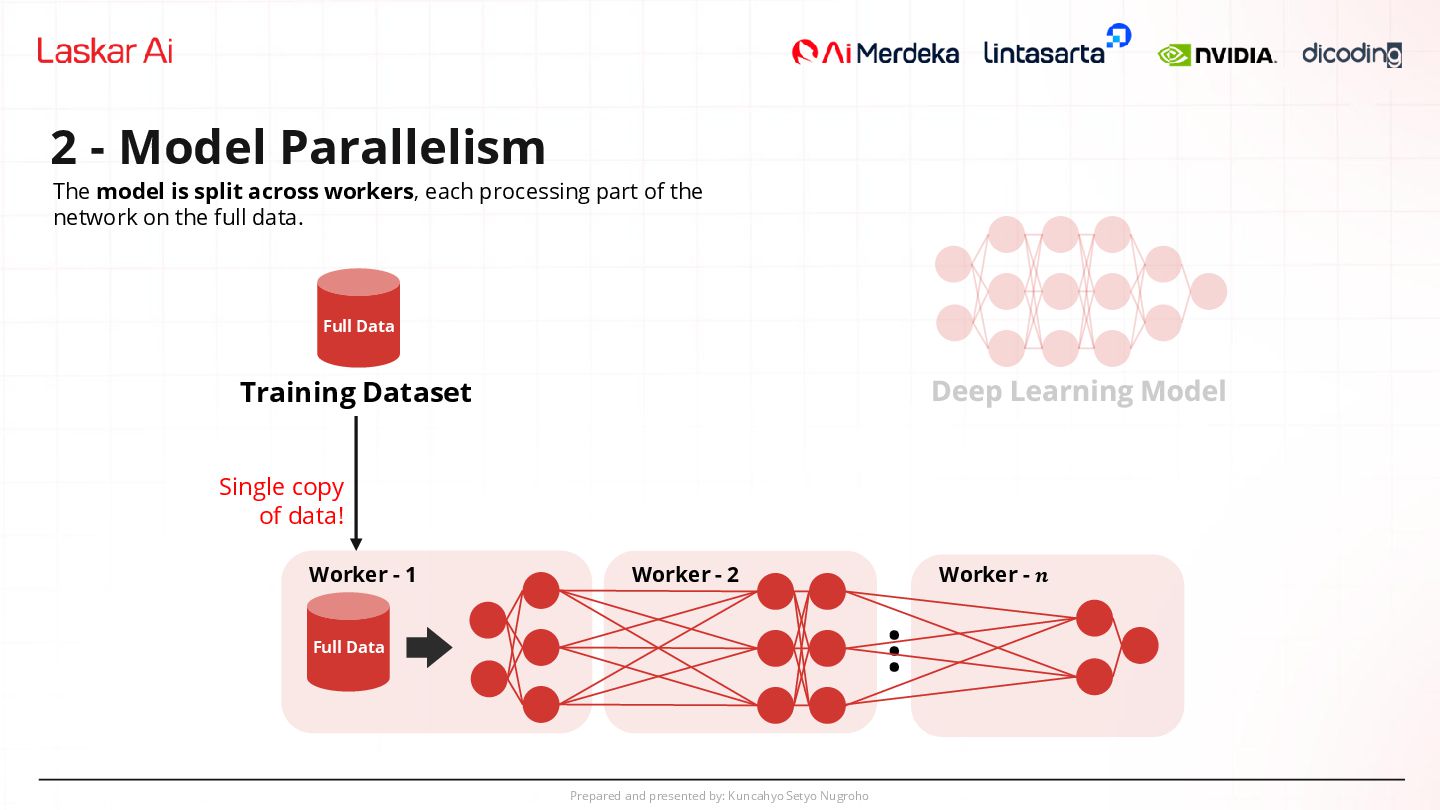
Parallelism Training Dataset Full Data Worker - 1 Full Data Worker - 2 Single copy of data! ... Worker - 𝒏 The model is split across workers, each processing part of the network on the full data.
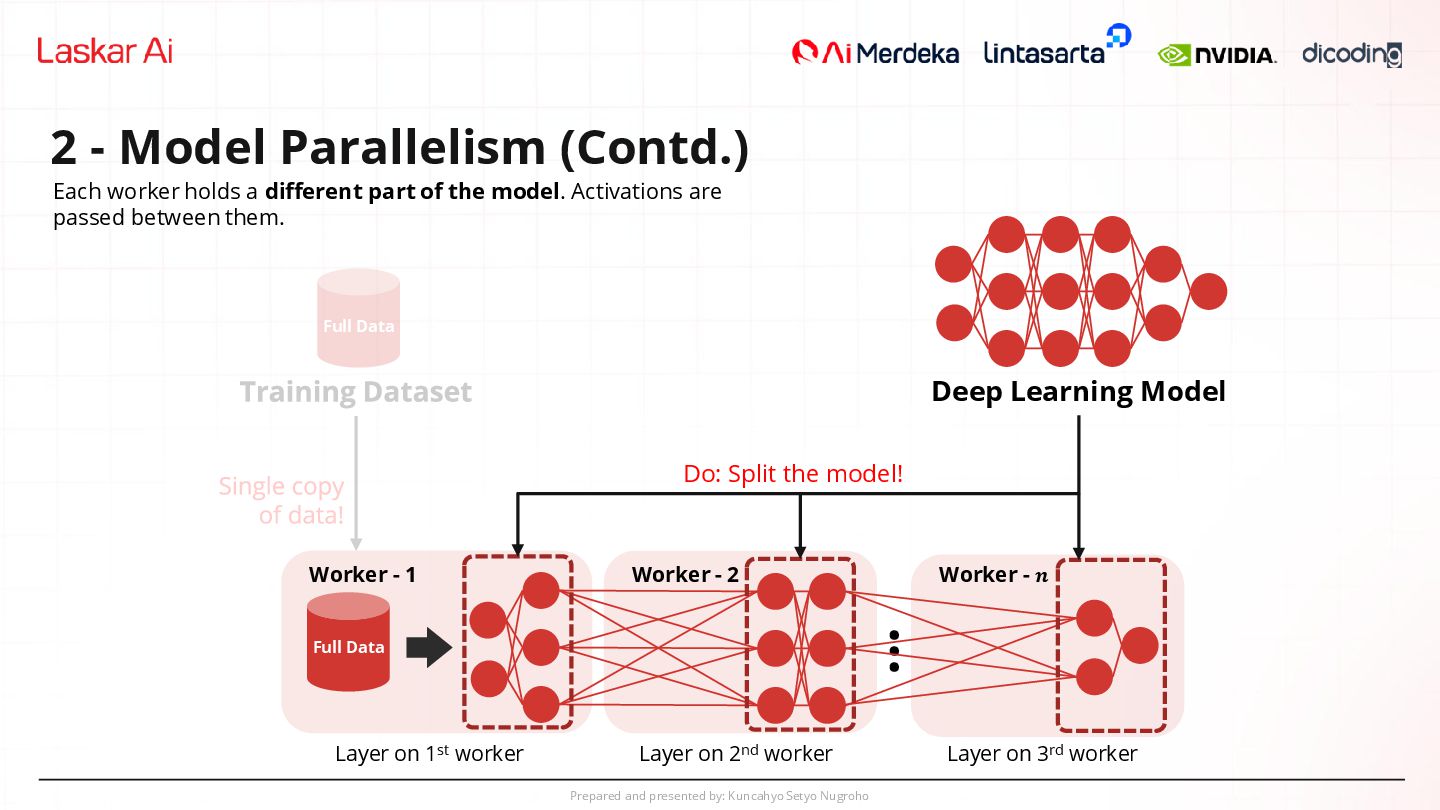
Parallelism (Contd.) Full Data Worker - 1 Full Data Worker - 2 ... Worker - 𝒏 Do: Split the model! Deep Learning Model Layer on 1st worker Layer on 2nd worker Layer on 3rd worker Each worker holds a different part of the model. Activations are passed between them.
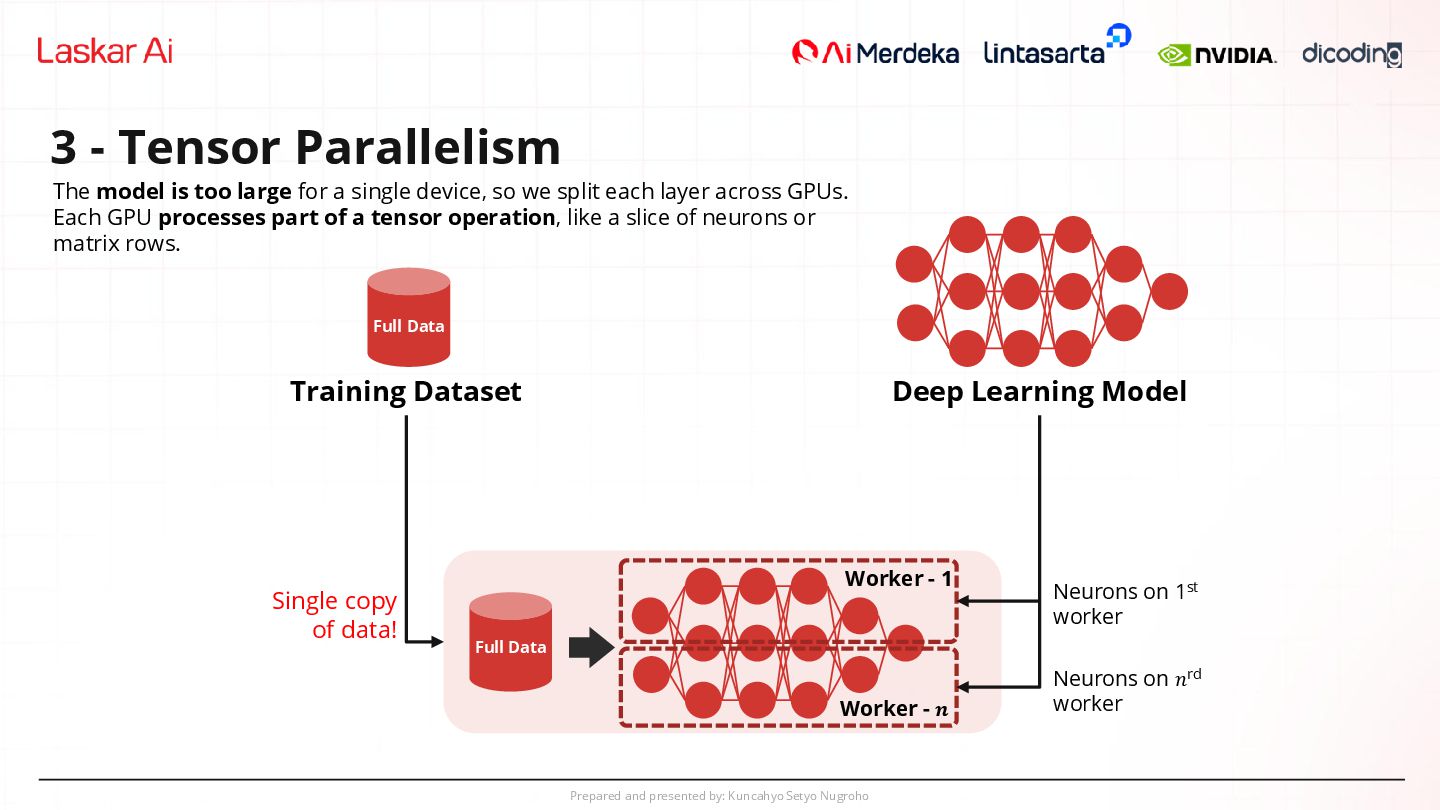
Parallelism Full Data Worker - 1 Worker - 𝒏 Deep Learning Model Neurons on 1st worker Neurons on 𝑛rd worker Training Dataset Full Data Single copy of data! The model is too large for a single device, so we split each layer across GPUs. Each GPU processes part of a tensor operation, like a slice of neurons or matrix rows.
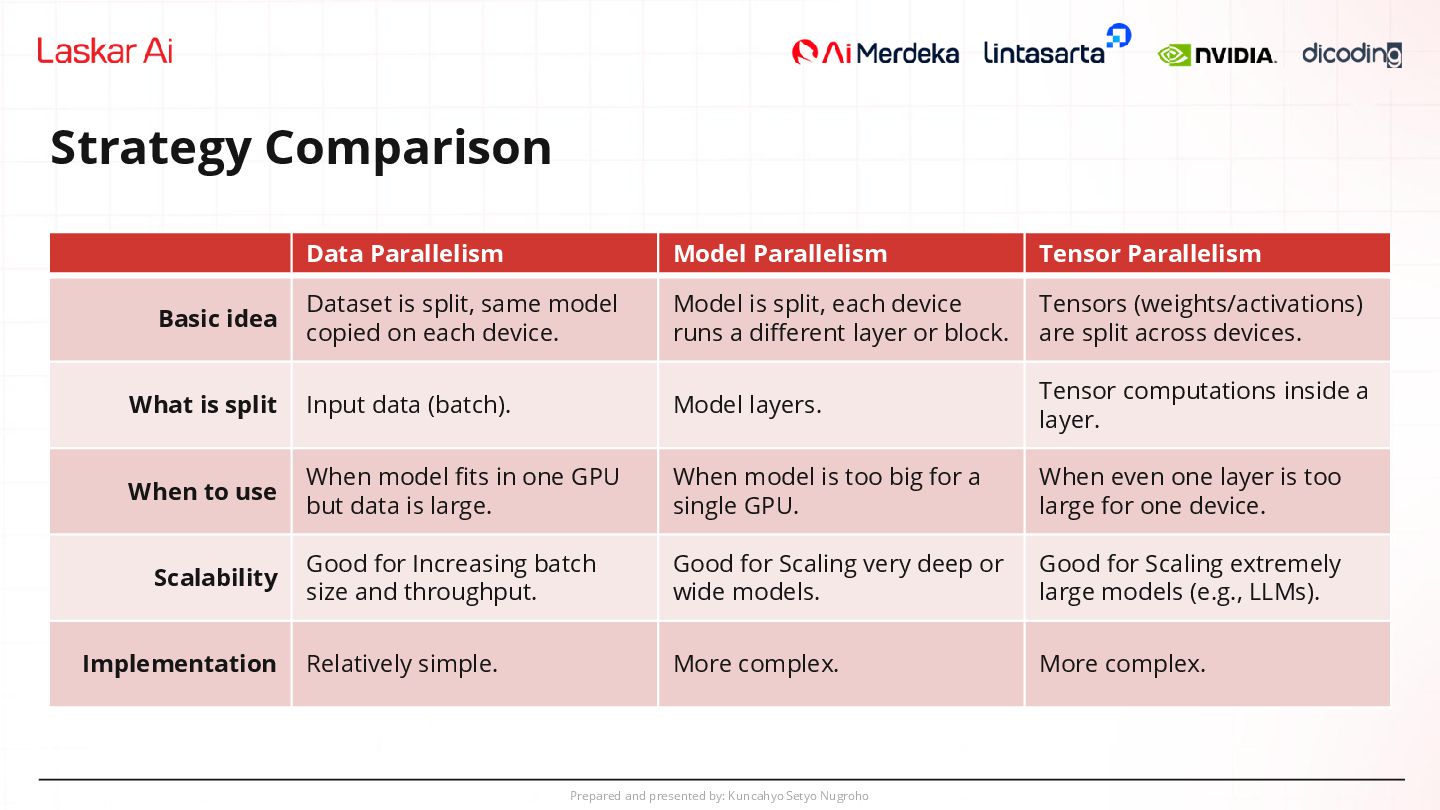
Parallelism Model Parallelism Tensor Parallelism Basic idea Dataset is split, same model copied on each device. Model is split, each device runs a different layer or block. Tensors (weights/activations) are split across devices. What is split Input data (batch). Model layers. Tensor computations inside a layer. When to use When model fits in one GPU but data is large. When model is too big for a single GPU. When even one layer is too large for one device. Scalability Good for Increasing batch size and throughput. Good for Scaling very deep or wide models. Good for Scaling extremely large models (e.g., LLMs). Implementation Relatively simple. More complex. More complex.
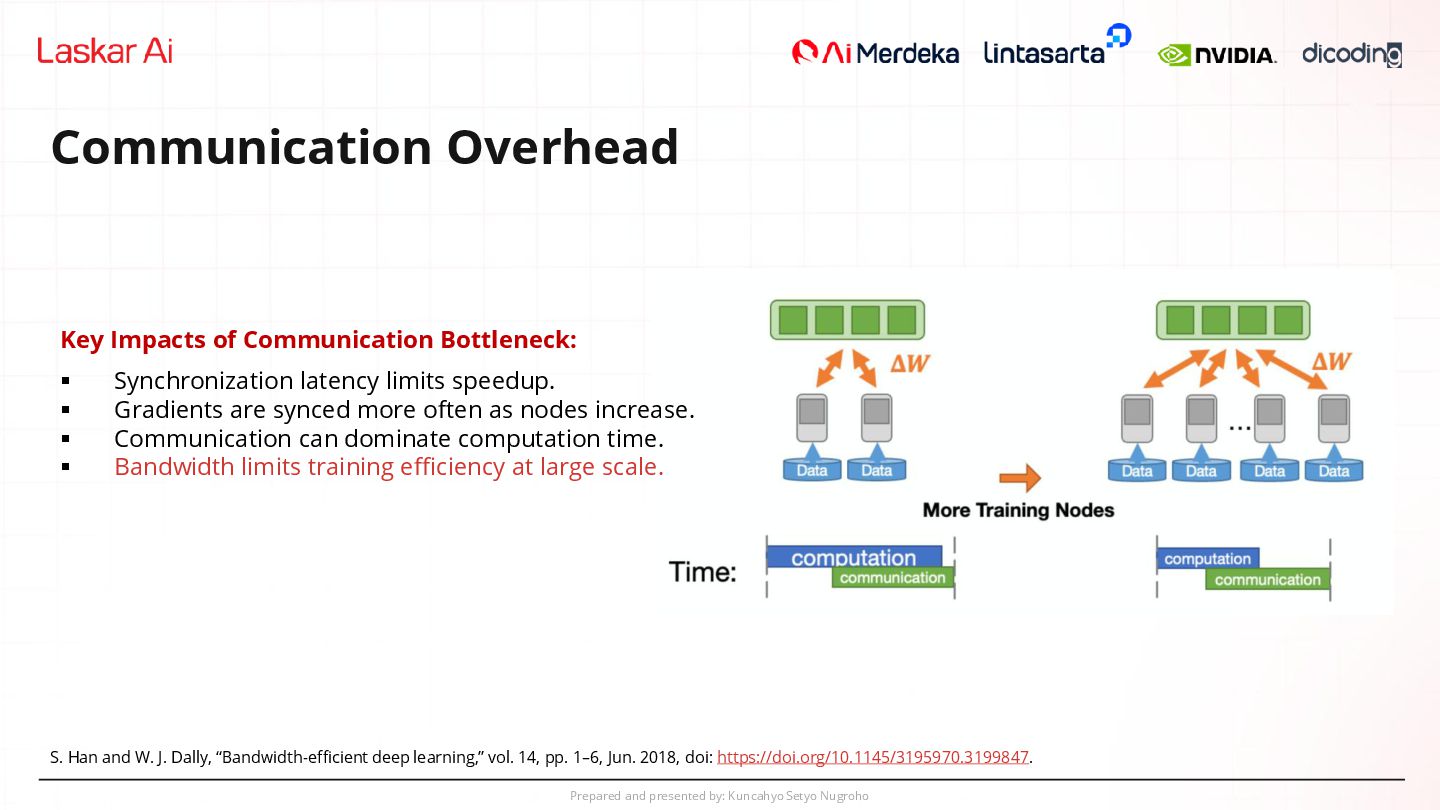
Impacts of Communication Bottleneck: ▪ Synchronization latency limits speedup. ▪ Gradients are synced more often as nodes increase. ▪ Communication can dominate computation time. ▪ Bandwidth limits training efficiency at large scale. S. Han and W. J. Dally, “Bandwidth-efficient deep learning,” vol. 14, pp. 1–6, Jun. 2018, doi: https://doi.org/10.1145/3195970.3199847.
Slows Training L. Zhu, H. Lin, Y. Lu, Y. Lin, and S. Han, “Delayed Gradient Averaging: Tolerate the Communication Latency for Federated Learning,” Advances in Neural Information Processing Systems, vol. 34, pp. 29995–30007, Dec. 2021 (Link)
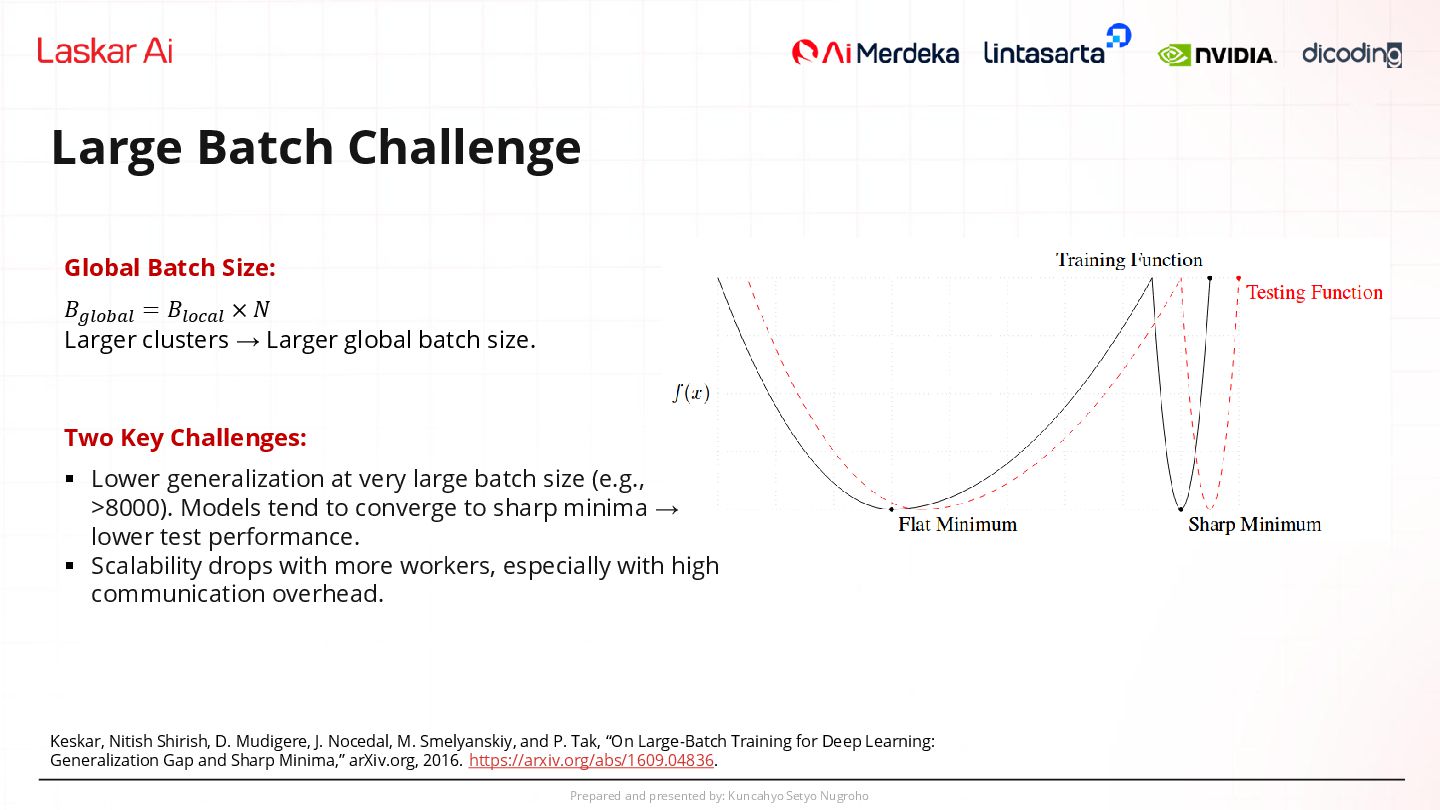
Keskar, Nitish Shirish, D. Mudigere, J. Nocedal, M. Smelyanskiy, and P. Tak, “On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima,” arXiv.org, 2016. https://arxiv.org/abs/1609.04836. Global Batch Size: 𝐵𝑔𝑙𝑜𝑏𝑎𝑙 = 𝐵𝑙𝑜𝑐𝑎𝑙 × 𝑁 Larger clusters → Larger global batch size. Two Key Challenges: ▪ Lower generalization at very large batch size (e.g., >8000). Models tend to converge to sharp minima → lower test performance. ▪ Scalability drops with more workers, especially with high communication overhead.
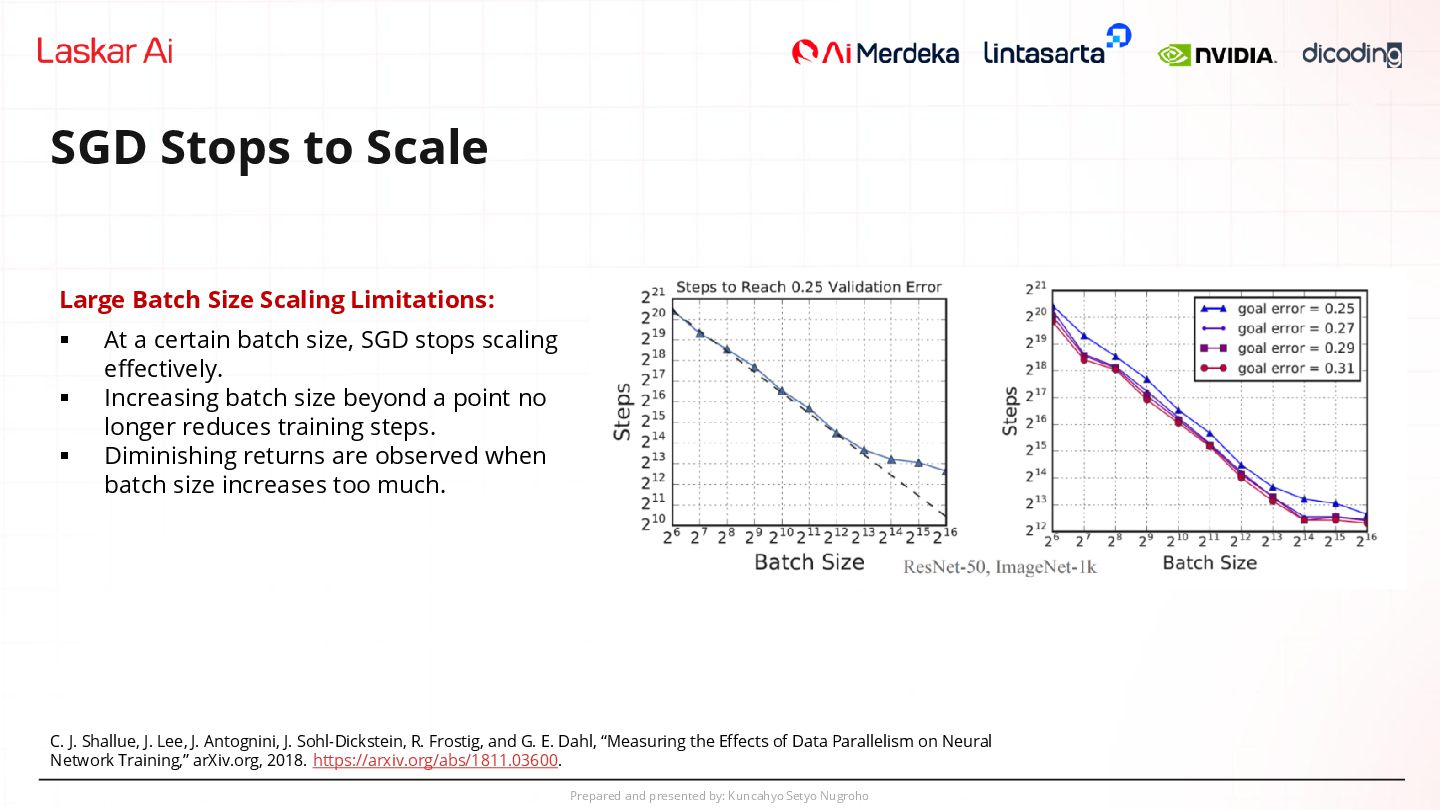
Scale Large Batch Size Scaling Limitations: ▪ At a certain batch size, SGD stops scaling effectively. ▪ Increasing batch size beyond a point no longer reduces training steps. ▪ Diminishing returns are observed when batch size increases too much. C. J. Shallue, J. Lee, J. Antognini, J. Sohl-Dickstein, R. Frostig, and G. E. Dahl, “Measuring the Effects of Data Parallelism on Neural Network Training,” arXiv.org, 2018. https://arxiv.org/abs/1811.03600.
Challenges Level Main Issues Effects System (Infrastructure) Level Communication overhead, bandwidth bottlenecks. ▪ Slower training due to gradient sync. ▪ Network latency limits scalability. Algorithmic- Level Poor generalization, SGD scaling limitations. ▪ Sharp minima with large batches. ▪ Diminishing performance with bigger batch sizes. *Balancing hardware efficiency and model performance requires addressing both communication constraints and optimization behavior.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You https://www.linkedin.com/in/ksnugroho [email protected] [email protected]](https://files.speakerdeck.com/presentations/5c99b80684824e338e02bca6a5f492ec/slide_29.jpg){kind=link}