2020. • Chris Donahue, 他2名: “The NES Music Database: A Multi-Instrumental Dataset with Expressive Performance Attributes”, 2018. • Chuang Gan, 他4名: “Foley Music: Learning to Generate Music from Videos”, 2020. • 根本さくら, 他10名: “物語のシーンにおける登場人物の感情状態とBGMの関係性抽出”, 2020. • 藤原優花, 他3名: “眼鏡型計測端末を用いたゲームプレイにおける重要なシーン抽出手法の検討”, 2019. • 獅々堀正幹, 他3名: “Earth Mover’s Distanceを用いたハミングによる類似音楽検索手法”, 2007. • Ali C. Gedik, Barış Bozkurt: “Pitch-frequency histogram-based music information retrieval for Turkish music”, Signal Processing, 2010. • Nivethitha Somu, 他2名: “A deep learning framework for building energy consumption forecast”, 2021. • Rial A. Rajagukguk, 他2名: “A Review on Deep Learning Models for Forecasting Time Series Data of Solar Irradiance and Photovoltaic Power”, 2019. • Y. Lecun, L. Bottou, Y. Bengio, P. Haffner: “Gradient-based learning applied to document recognition”, 1998. • Sepp Hochreiter, Jürgen Schmidhuber: “Short-Term Memory”, 1997. • Diederik P. Kingma, Jimmy Ba: “Adam: A Method for Stochastic Optimization”, 2015. • Sashank J. Reddi, 他2名: “On the Convergence of Adam and Beyond”, 2018. はじめに > 関連研究
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
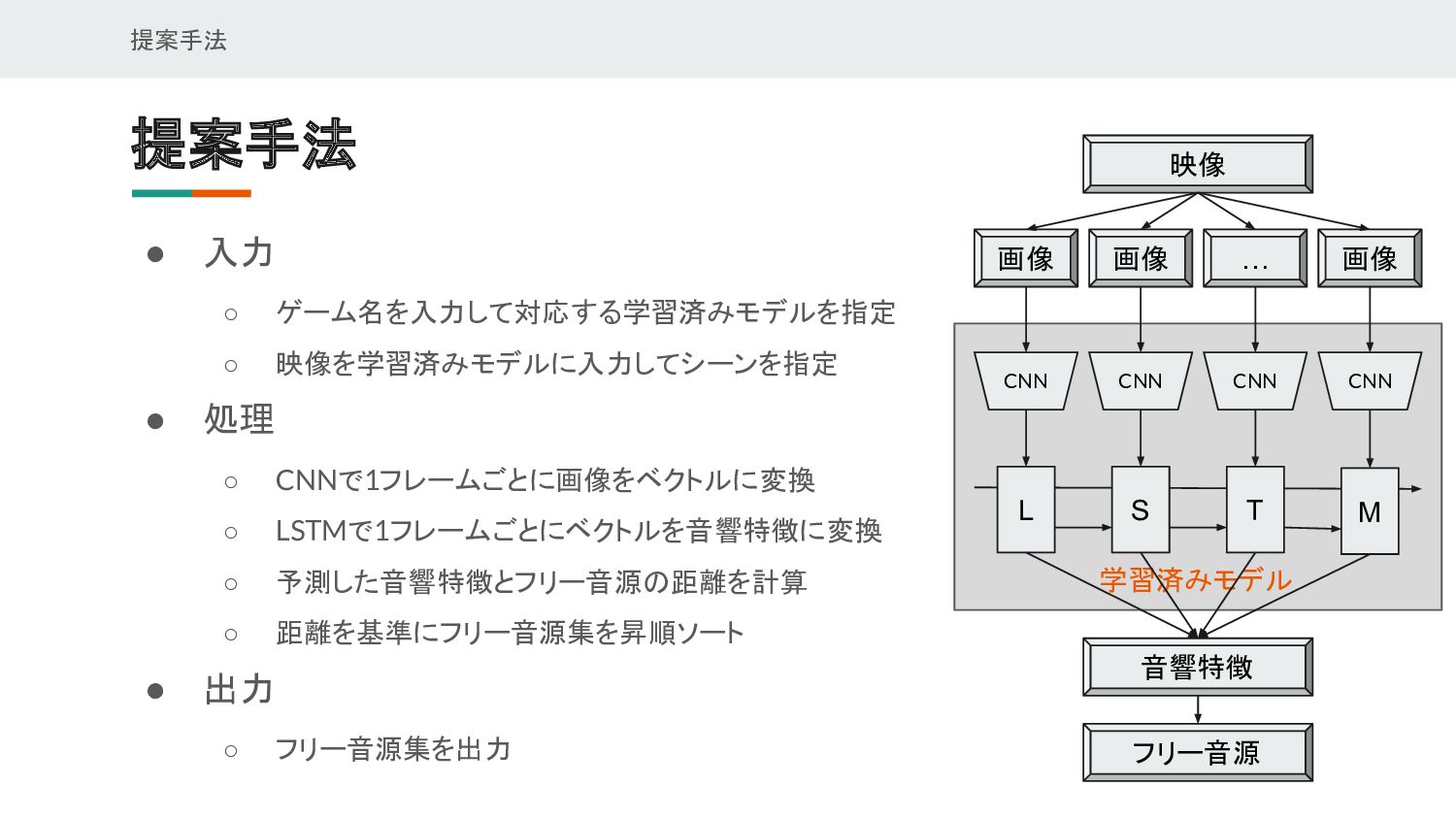{kind=link}
{kind=link}
{kind=link}
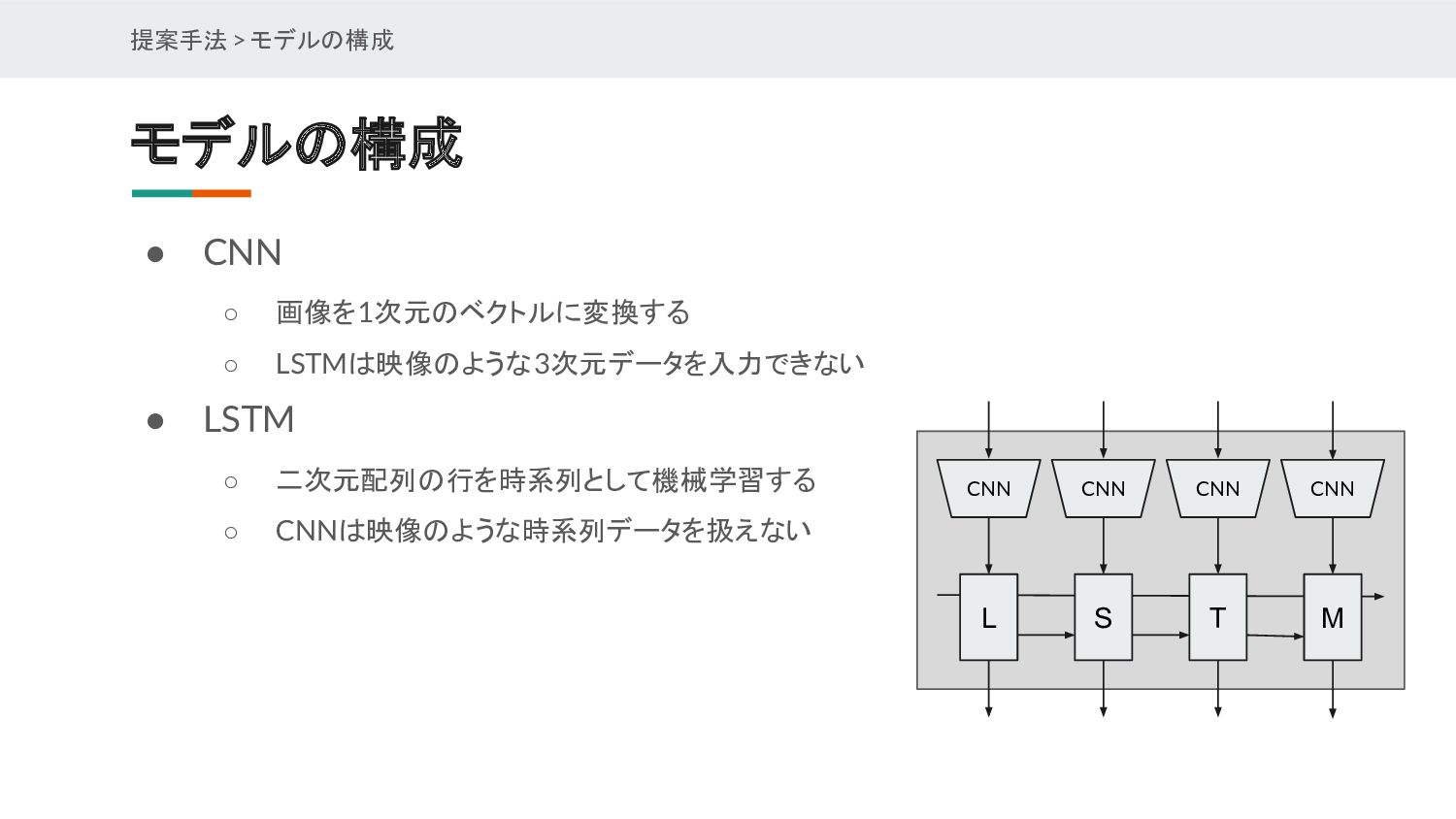{kind=link}
{kind=link}
{kind=link}
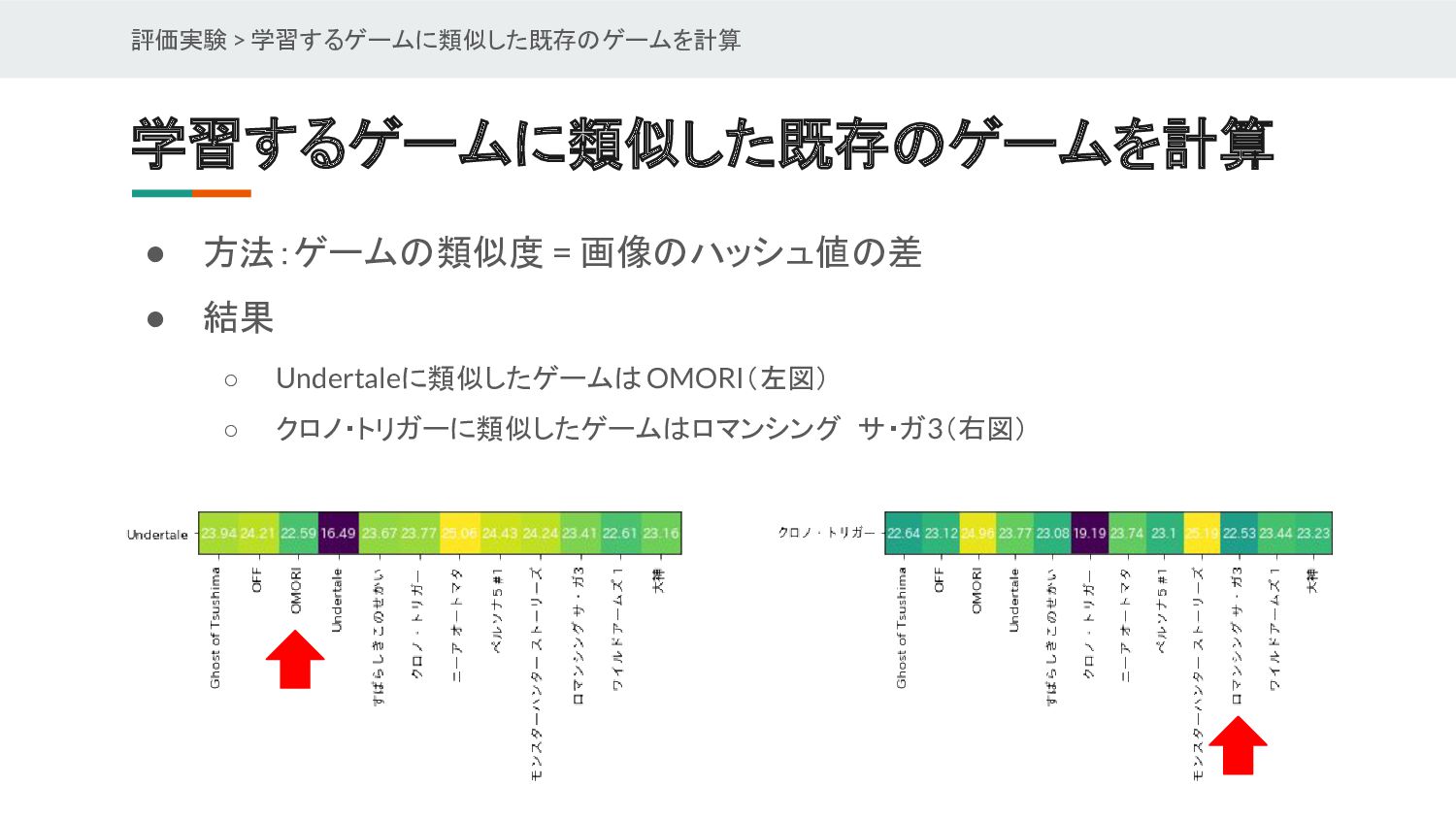{kind=link}
{kind=link}
{kind=link}
{kind=link}
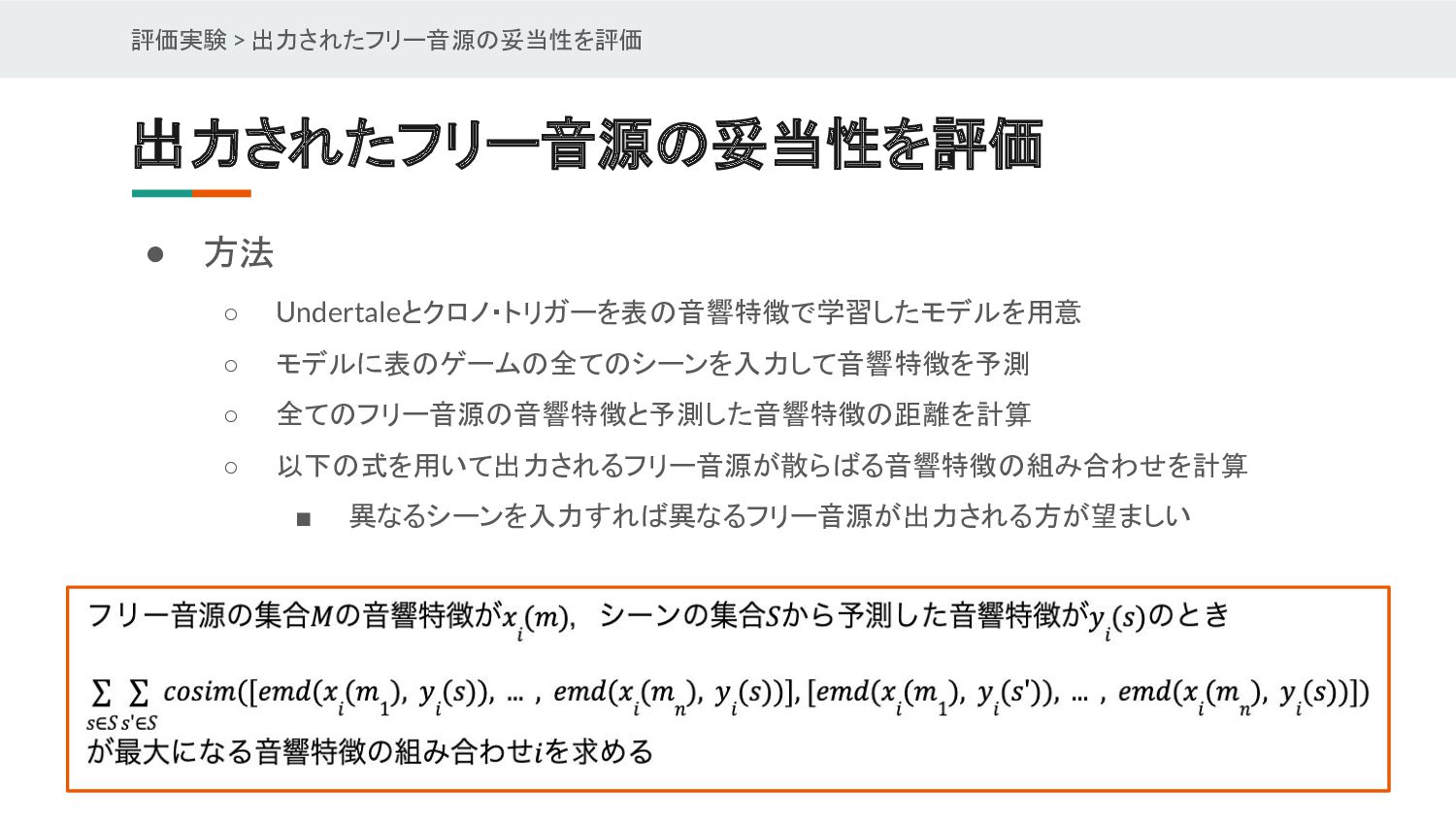{kind=link}
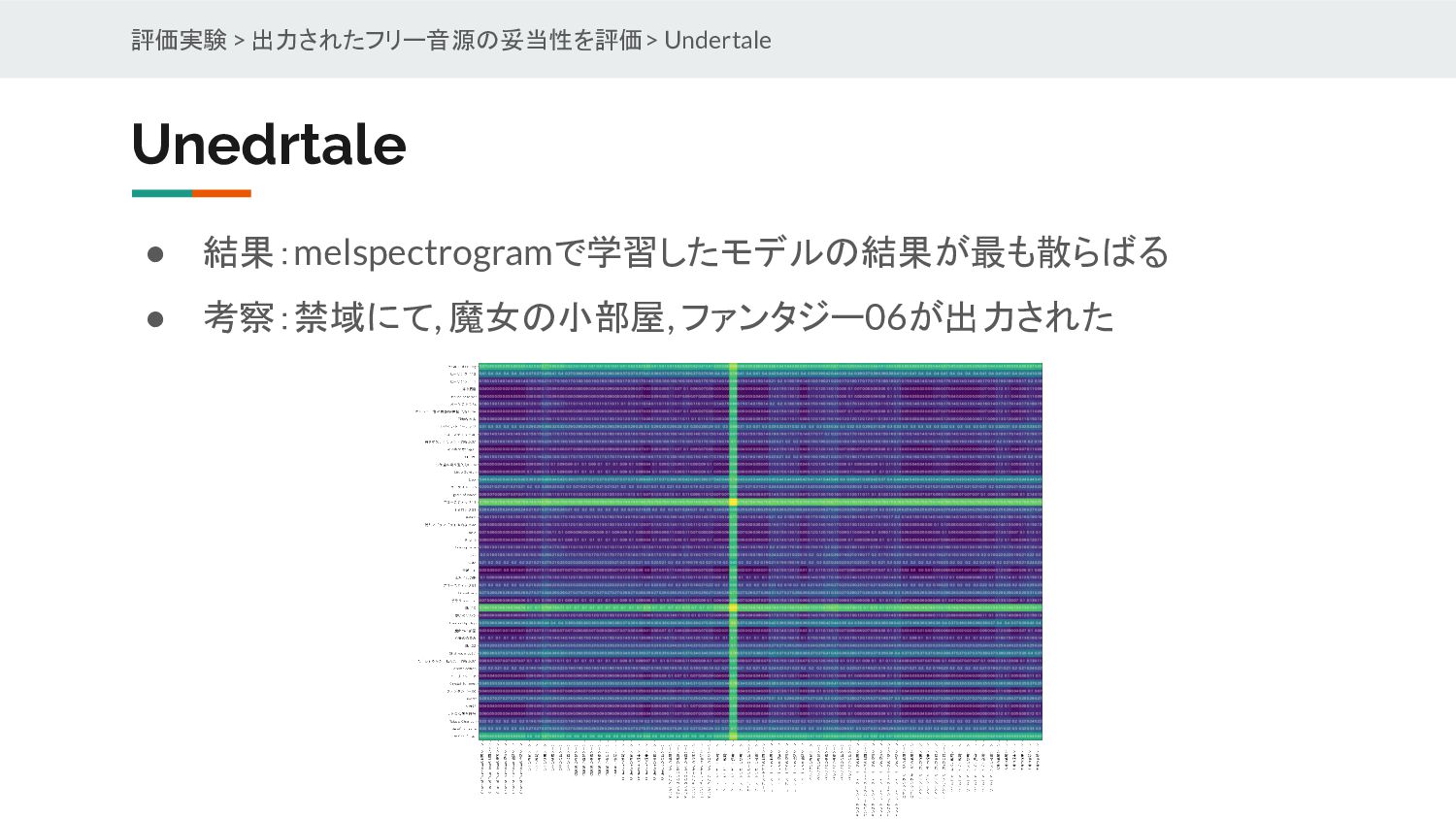{kind=link}
{kind=link}
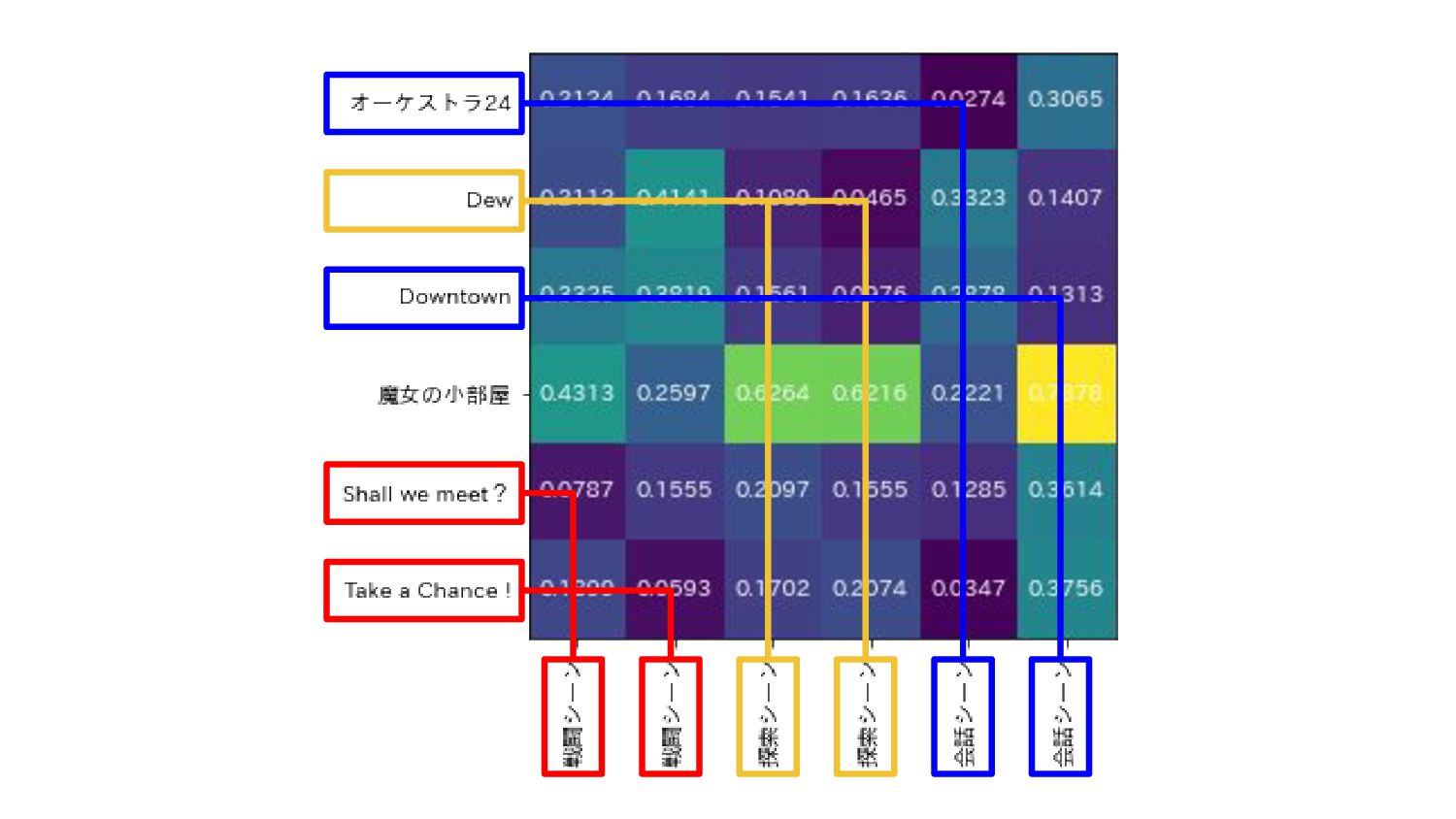{kind=link}
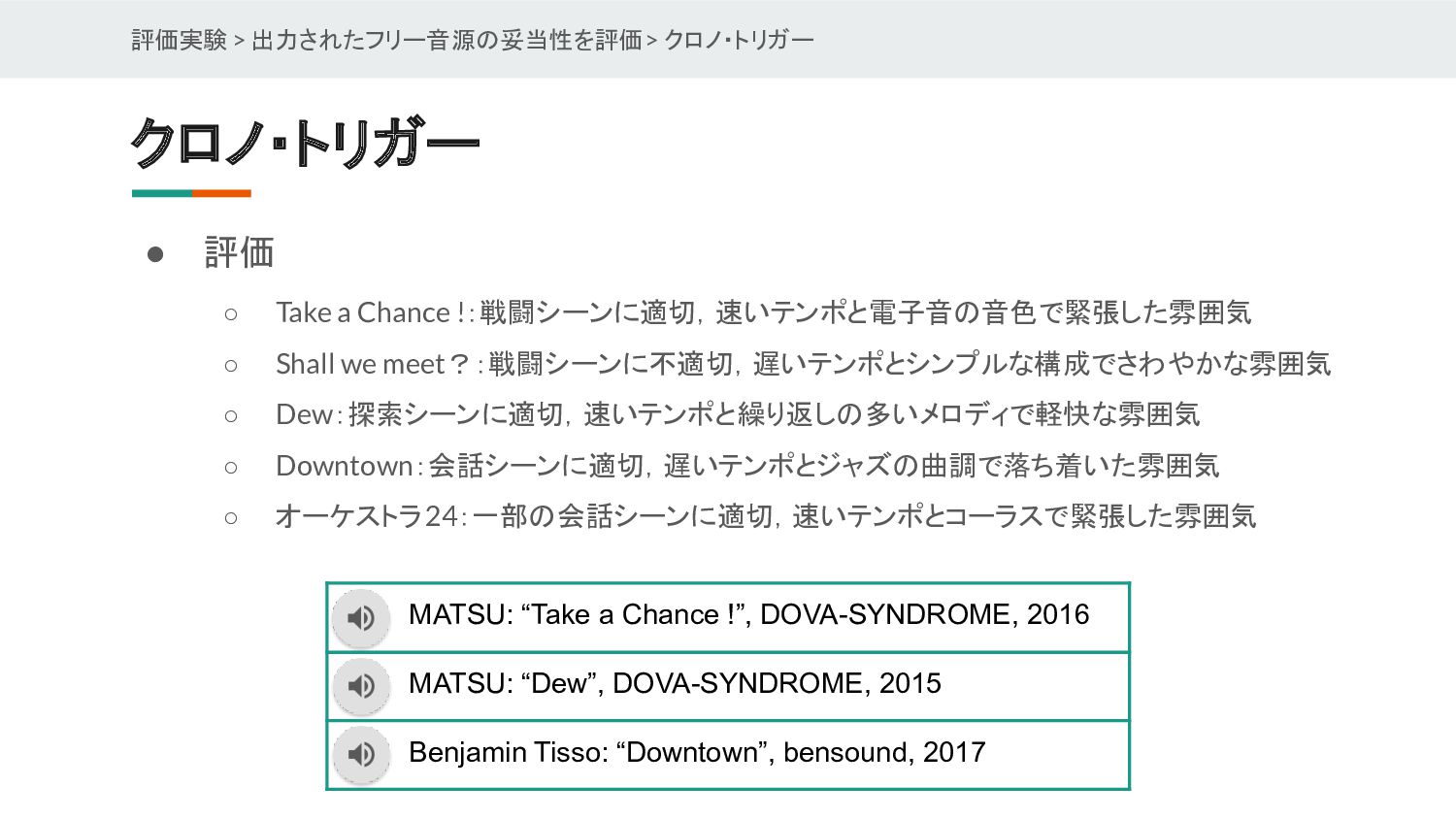{kind=link}
{kind=link}
{kind=link}
{kind=link}