Studio Tutorial, Part 2 https://developer.ibm.com/videos/introduction-to-machine- learning-and-artificial-intelligence-watson-studio-tutorial-part-2/ Introduction to Machine Learning and Artificial Intelligence – Watson Studio Tutorial, Part 3 https://developer.ibm.com/videos/introduction-to-machine- learning-and-artificial-intelligence-watson-studio-tutorial-part-3/ このセッションは IBM Developer https://developer.ibm.com/ の 動画を元に作成しています
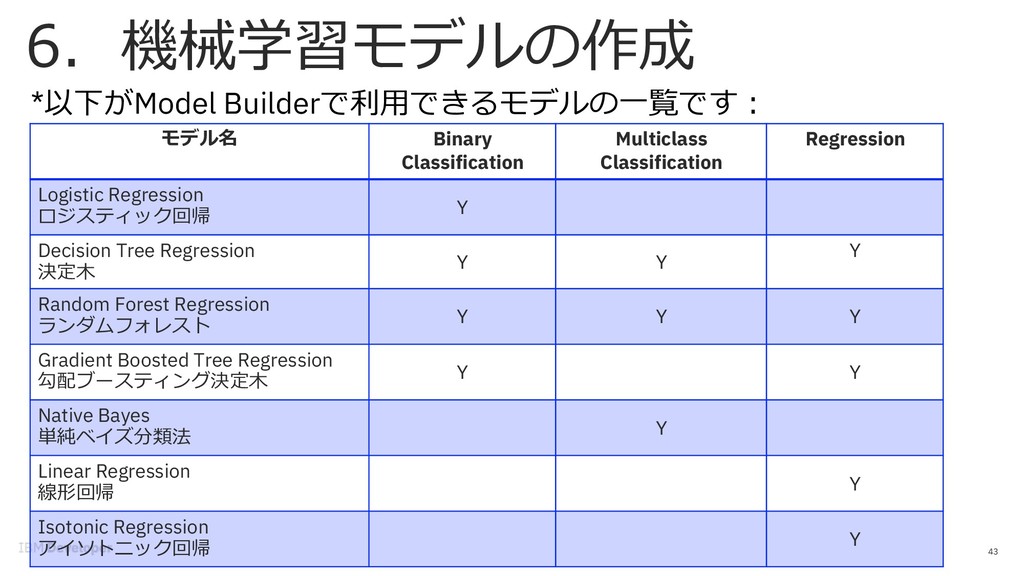
Regression Logistic Regression ロジスティック回帰 Y Decision Tree Regression 決定⽊ Y Y Y Random Forest Regression ランダムフォレスト Y Y Y Gradient Boosted Tree Regression 勾配ブースティング決定⽊ Y Y Native Bayes 単純ベイズ分類法 Y Linear Regression 線形回帰 Y Isotonic Regression アイソトニック回帰 Y
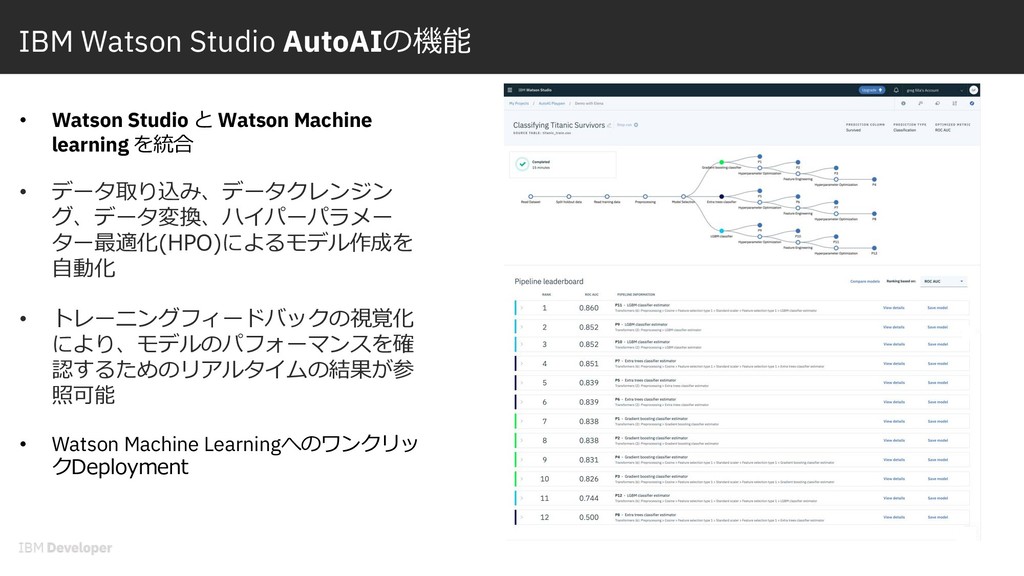
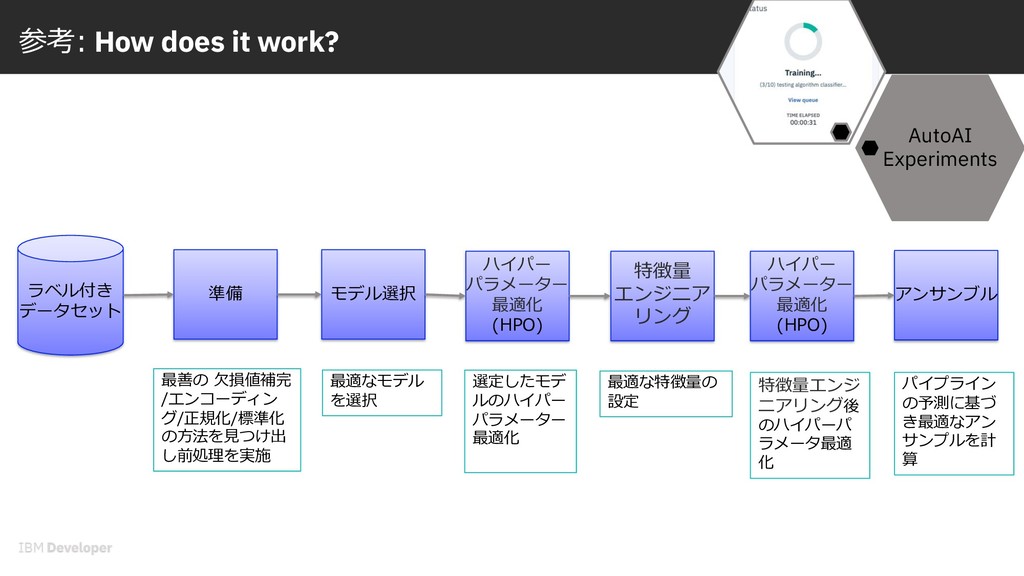
the rest of us チュートリアル: IBM Watson Studio AutoAI: これまでにない⼀般ユーザーのためのモデリング Published on July 15, 2019 AutoAIでBinary ClassificationとRegressionモデルを作成しテスト、さらに jupyter notebookを使⽤してpythonから呼び出すチュートリアルです。 このハンズオンと同じProjectを使⽤する場合は、Projectを開いた状態で 「Creating an AutoAI model for binary classification 」 から開始してください。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
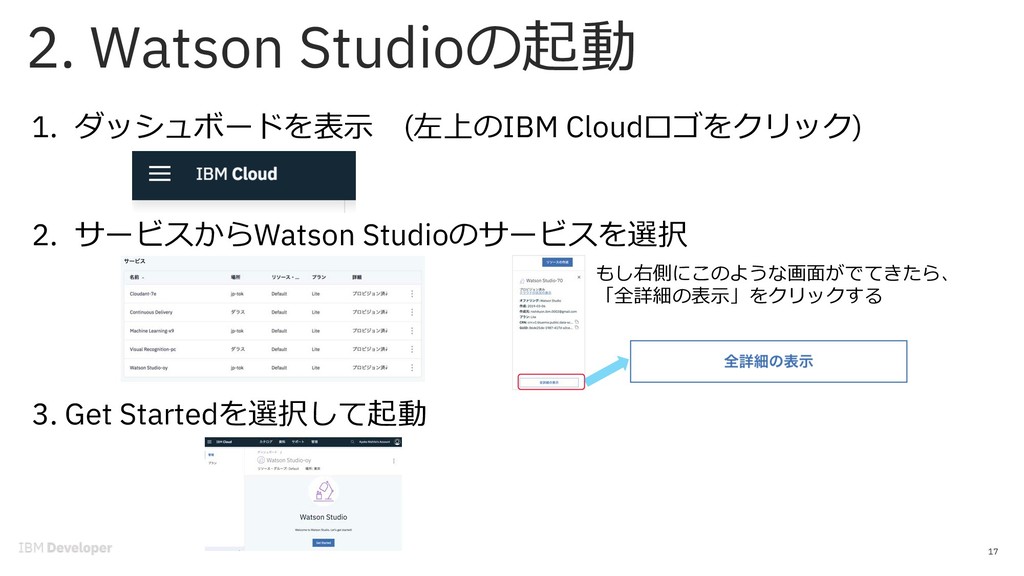{kind=link}
![18 1. [Create a Project]をクリックします。 2. [Create an empty project]をクリックします。](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_17.jpg){kind=link}
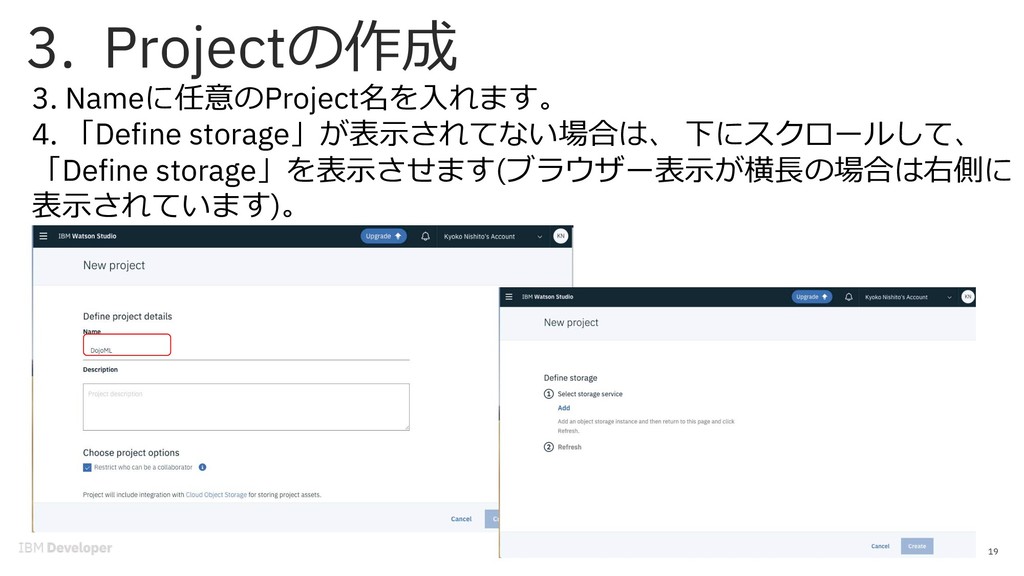{kind=link}
![20 5A. Object Storage未作成の場合: 5A-1. Define Storage の①Select storage serviceから[Add]をクリックしま](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_19.jpg){kind=link}
![21 5A-2. Cloud Object Storageの画⾯が表⽰されるので下にスクロールします。 5A-3. Liteが選択されていることを確認して[Create]をクリックします。 5A-4. Confirm Creationのダイアログはそのまま[Confirm]をクリックします。](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_20.jpg){kind=link}
{kind=link}
![23 5B. Object Storage作成済の場合: 5B-1. [Create]をクリック ただしObject Storageを複数作成している場合は、使⽤したいObject Storageを選択後に[Create]をクリック 3.](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_22.jpg){kind=link}
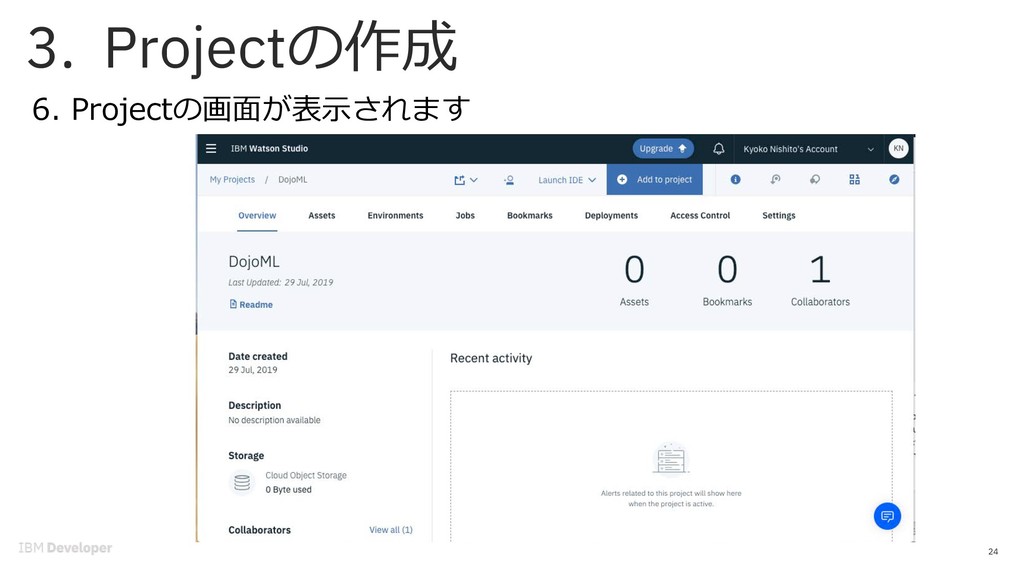{kind=link}
![25 1. [Settings]をクリックします。 2. Associated servicesから[+Add services]をクリックして [Watson]を選択 4. サービスの作成と追加](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_24.jpg){kind=link}
![3. Machine Learningの[Add]をクリック 4A: [New]のタブが選択された画⾯が表⽰された場合 1. スクロールしてPLANでLiteが選択されていることを確認して⼀番下 の[Create]をクリック 。 2.](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_25.jpg){kind=link}
![27 4B[Existing]のタブが選択された画⾯が表⽰された場合 Existing Service Instance のドロップダウンから、使⽤するMachine Learningのサービスを選択して[Select]をクリック 。 [Existing]のタブが選択された画⾯が表⽰されたにもかかわらず、「Existing Service](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_26.jpg){kind=link}
![4.サービスの作成と追加 28 6. [Settings] の画⾯に戻ります。 Associated servicesに追加したサービスのインスタンスが追加されている ことを確認します。](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_27.jpg){kind=link}
![5. データのアップロード 29 1. 右上にある[0100]アイコンをクリック 2. ダウンロートしたpatientdataV6.csvを右上の点線の四⾓エリアにド ロップ patientdataV6.csv](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_28.jpg){kind=link}
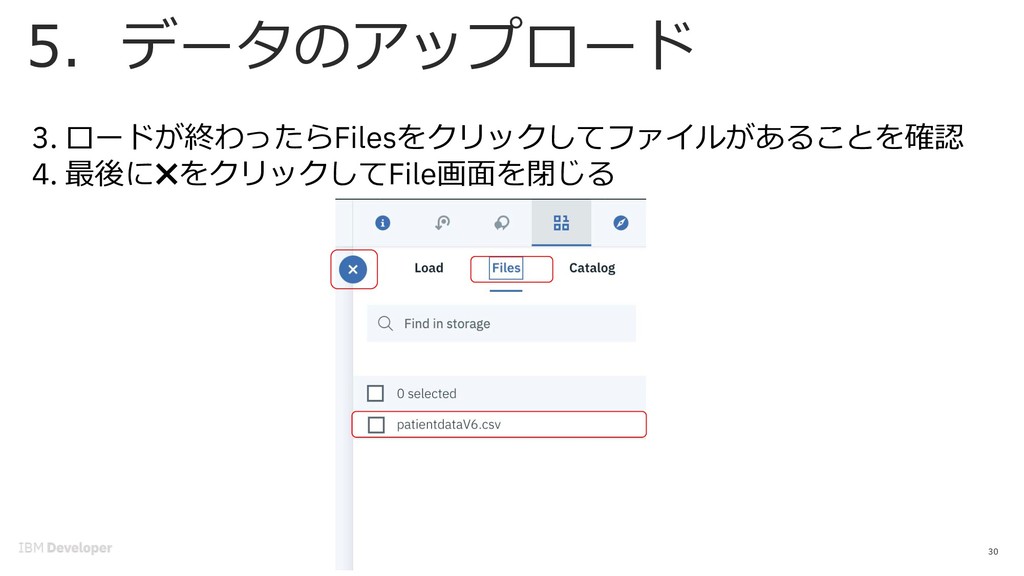{kind=link}
![6. 機械学習モデルの作成 31 1. 上にスクロールし[Assets] をクリックしAsset画⾯を表⽰します。](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_30.jpg){kind=link}
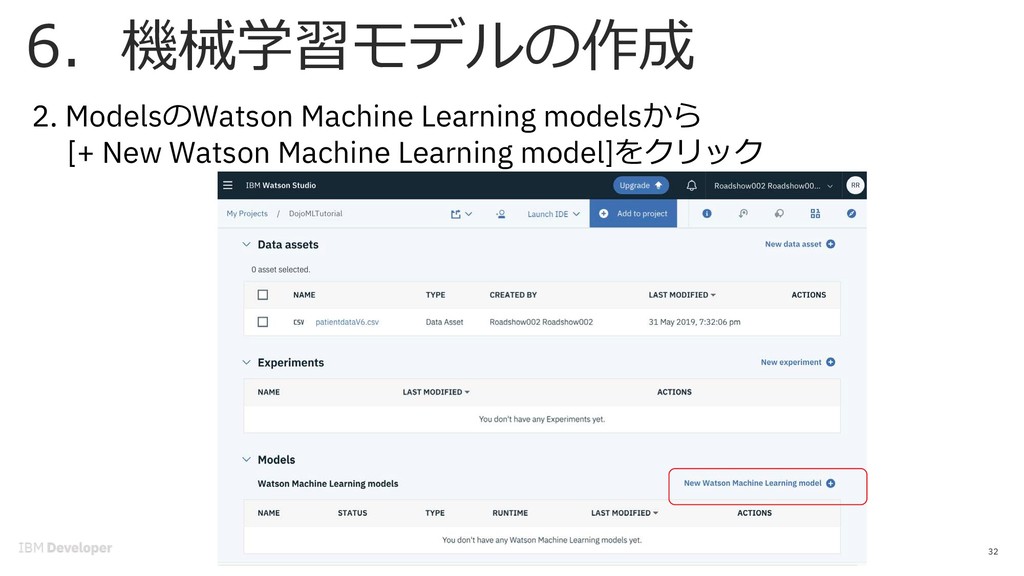{kind=link}
![6. 機械学習モデルの作成 33 3. [Name]にモデルの名前を記⼊ 4. Machine Learning Service にMachine](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_32.jpg){kind=link}
![6. 機械学習モデルの作成 34 9. Select data assetからpatientdataV6.csv を選択し、[Next]をクリック](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_33.jpg){kind=link}
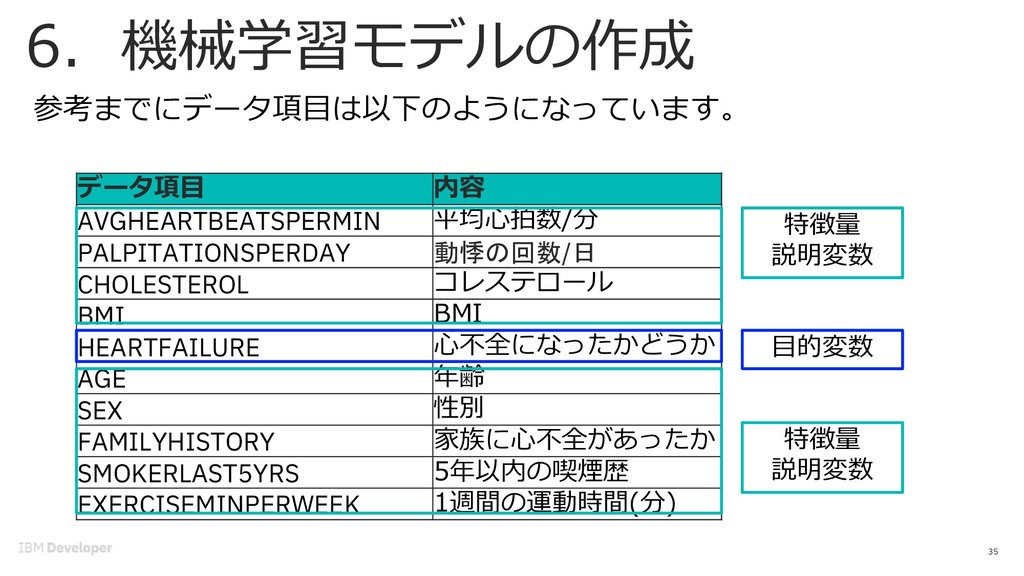{kind=link}
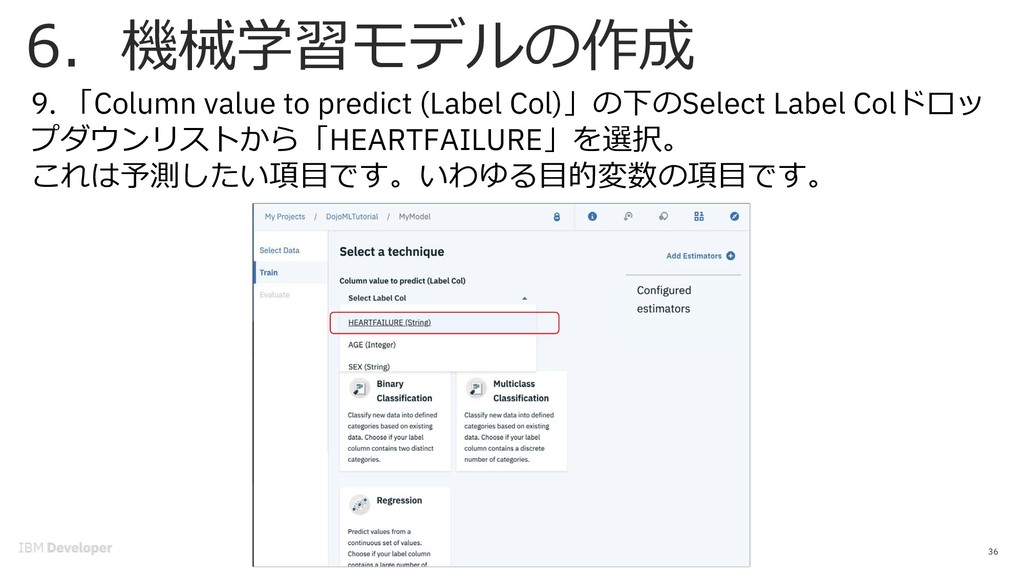{kind=link}
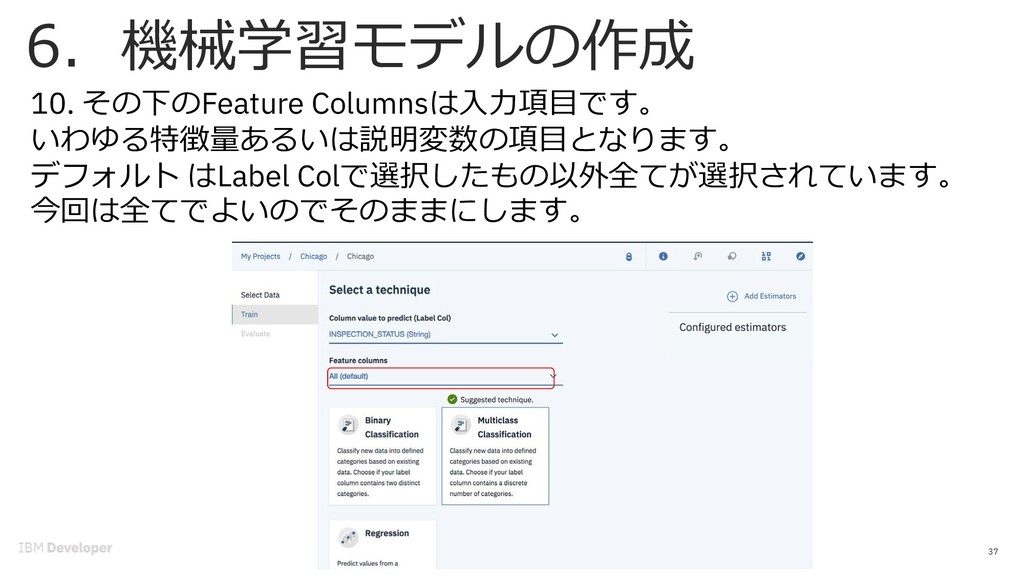{kind=link}
{kind=link}
{kind=link}
{kind=link}
![6. 機械学習モデルの作成 41 12. 最後に学習に使⽤するモデルを設定します。 右上の[+ Add Estimators]をクリックします。](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_40.jpg){kind=link}
![6. 機械学習モデルの作成 42 13. 使⽤できるモデルとその説明が表⽰されます。 ここでは複数選択が可能です。4つ全てをクリックして選択し最後に [Add]をクリックします。](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_41.jpg){kind=link}
{kind=link}
{kind=link}
![6. 機械学習モデルの作成 45 14. [Next]をクリックして次に進みます。](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
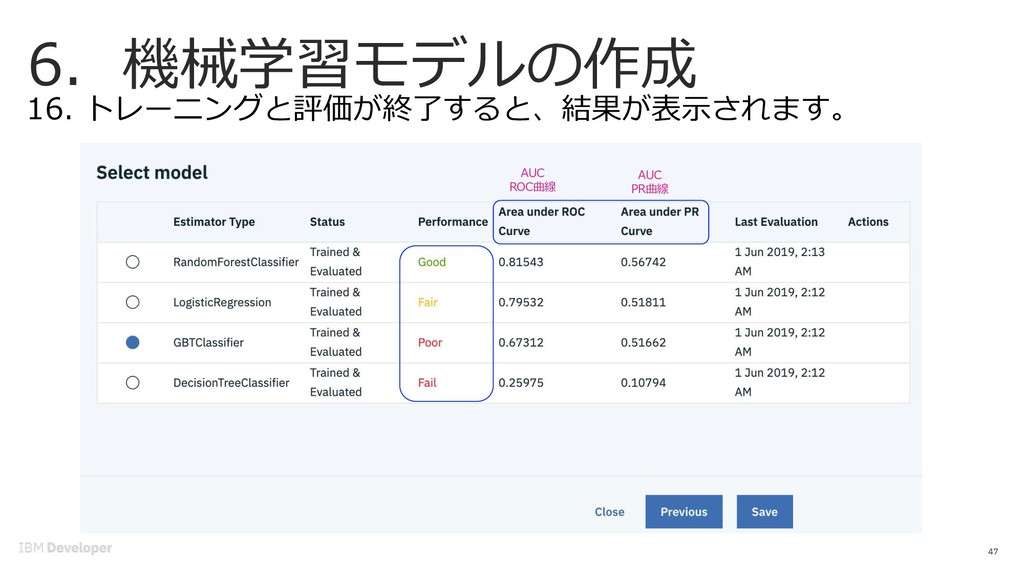
![6. 機械学習モデルの作成 48 17. とりあえずPERFORMANCEが⼀番よいものを選択し、 [Save]をクリック(2回)](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_47.jpg){kind=link}
{kind=link}
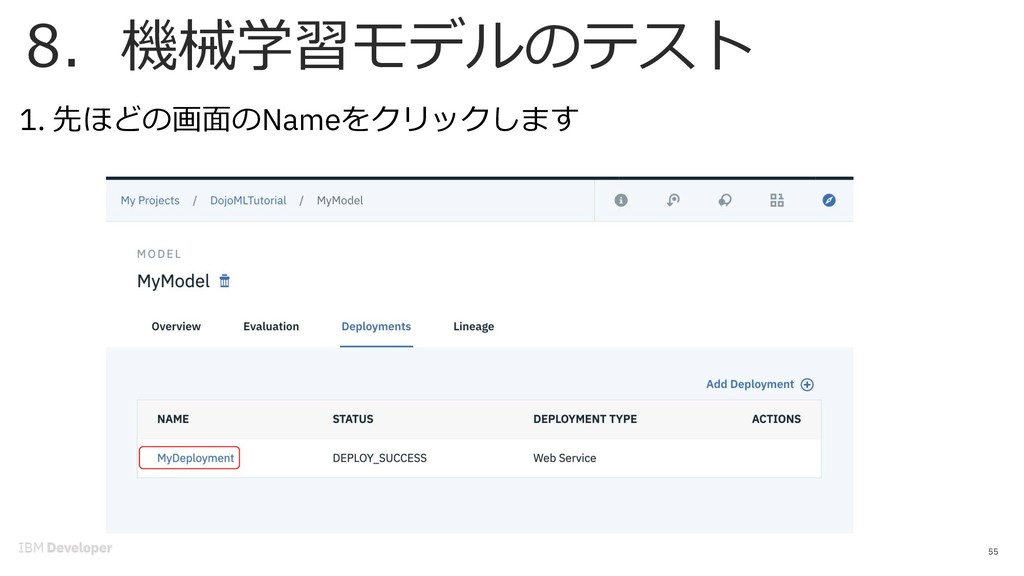
![7. 機械学習モデルのデプロイ 50 1. 保存したモデルをWebサービスとしてデプロイします。 [Deployments]をクリックします。](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_49.jpg){kind=link}
![7. 機械学習モデルのデプロイ 51 2. [Add Deployment]をクリックします。](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_50.jpg){kind=link}
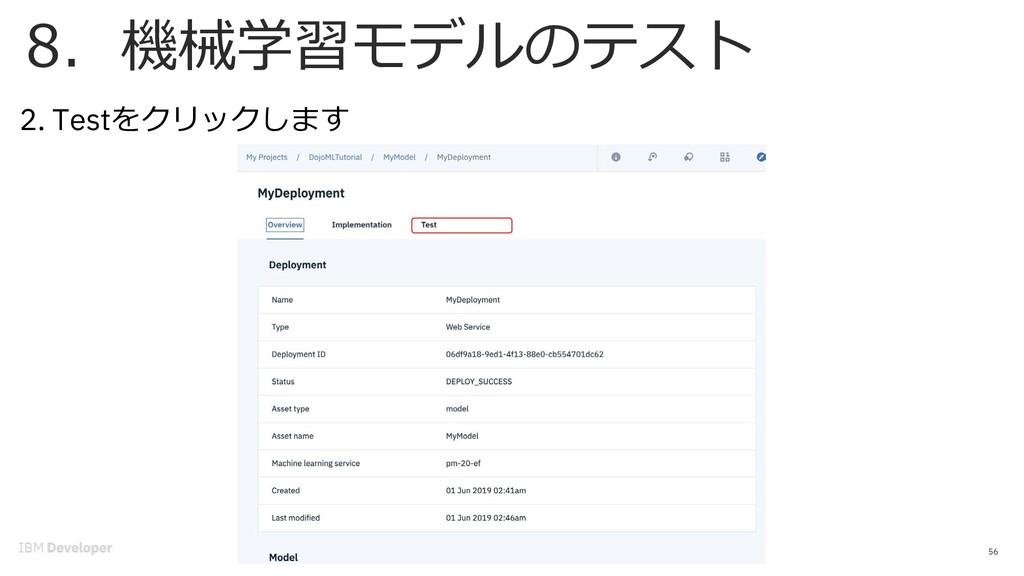
![7. 機械学習モデルのデプロイ 52 3. Nameを⼊⼒し、Deployment typeはWeb serviceを選択し、 [Save]をクリック](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_51.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
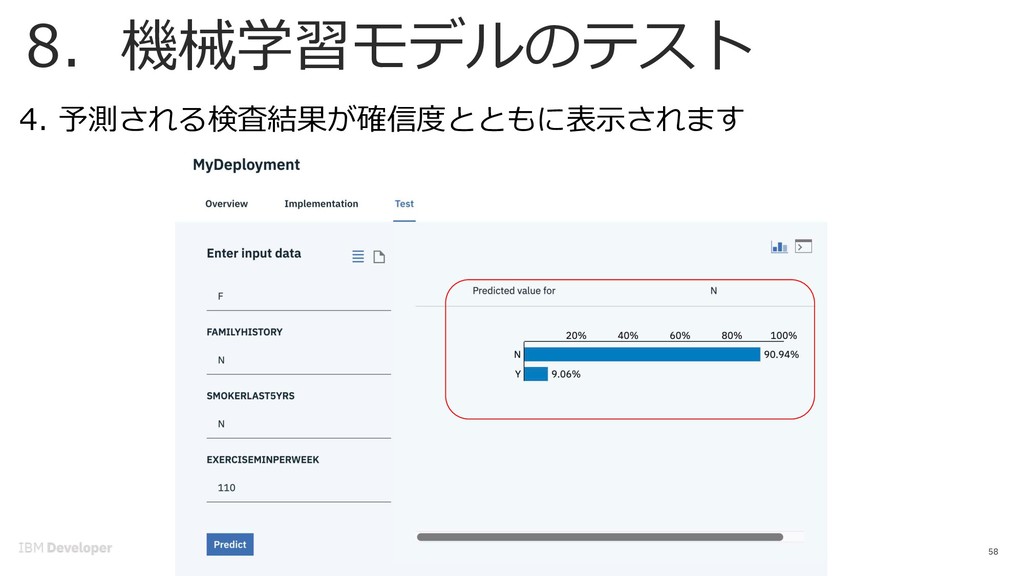
![8. 機械学習モデルのテスト 57 3. 各値を⼊れて、[Predict]をクリックします。 テストする値はtest_patientdataV6.csvの値をを 使ってみましょう。 データ項⽬ 内容 AVGHEARTBEATSPERMIN](https://files.speakerdeck.com/presentations/fd1d9194ee344a61b8430d5ee6e7f646/slide_56.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}