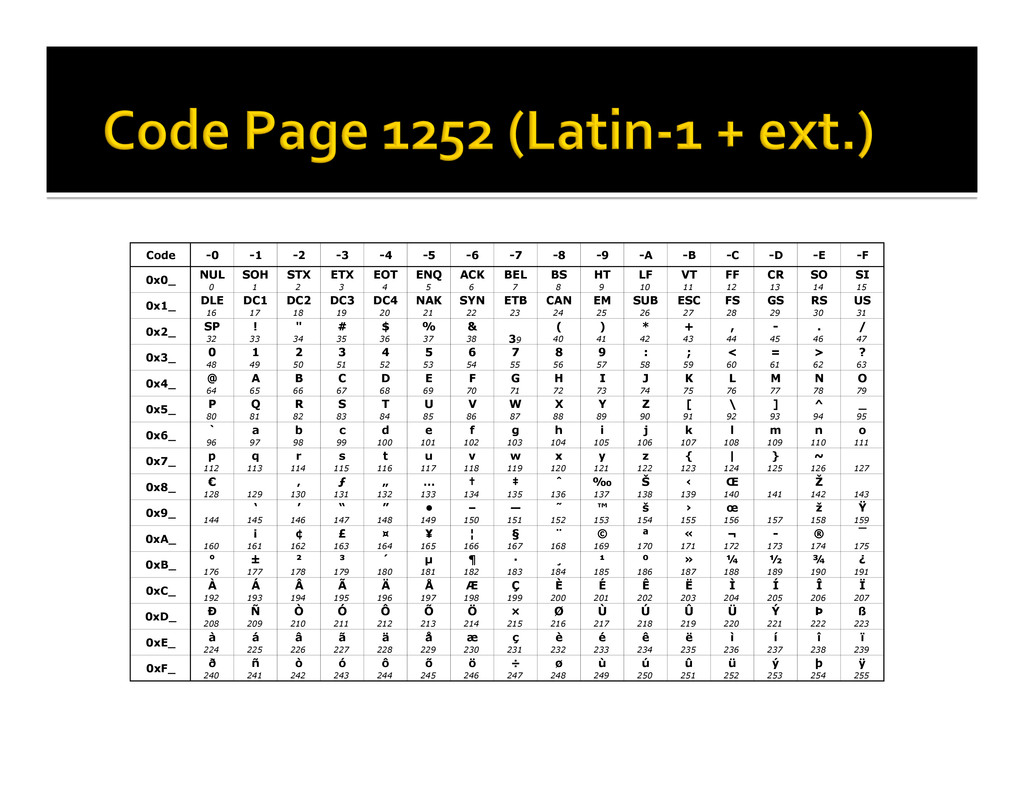
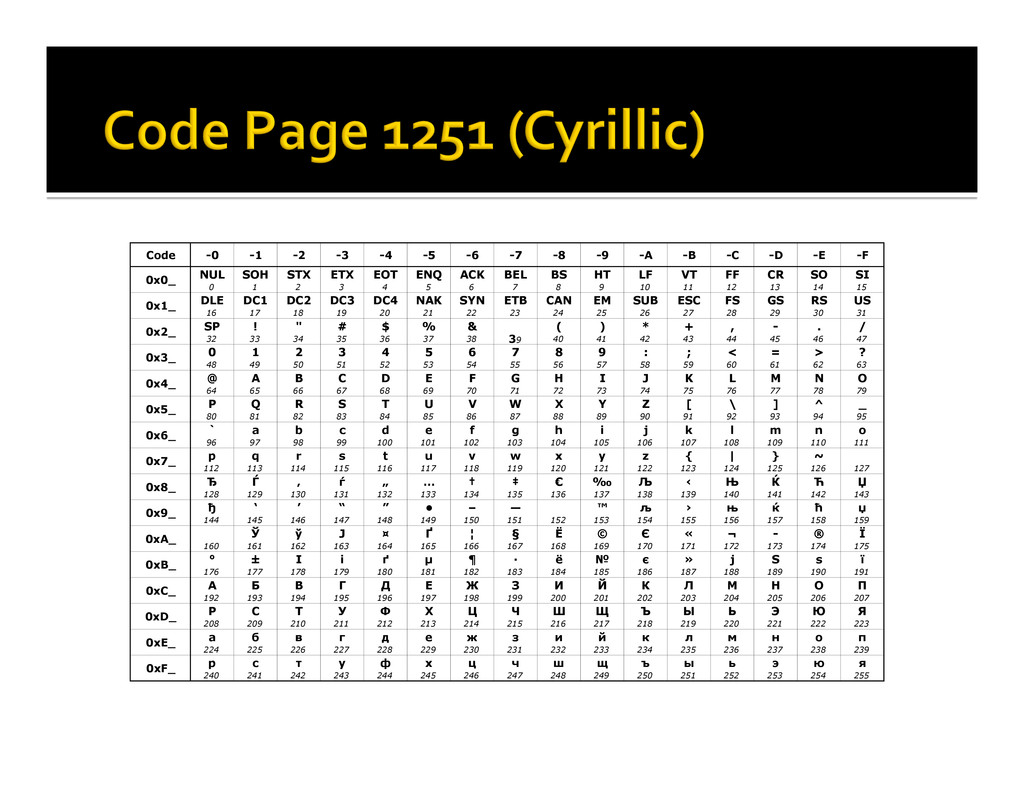
It’s now published electronically, for example ¡ But the basic idea is that you map a numeric code point to every character that you wish to represent in a computer system ¡ There are pages and pages mapping characters to a number (a Unicode code point) § I wonder where the term “code pages” came from? ¡ Each character also has properties, such as a name, its case (lower/upper), and more
(“16 bits”) § … back in 1991 § Only five years later, the Unicode Consortium realized this was insufficient and expanded the maximum number of Unicode characters § Yet the misconception remains ¡ Today, Unicode has space to encode 1,114,111 unique characters
since its original release in 1991 ¡ The latest version of Unicode, 6.2.0, will be released this month (October 2012) for basically one reason: ¡ A new currency symbol! This slide brought to you by U+20BA, TURKISH LIRA SYMBOL
character. Typically expressed as U+<hex number>. Even though Unicode covers more than 65k characters, this is typically written as a four digit hex number. ¡ For example U+0041 == LATIN CAPITAL LETTER A
point is simply an abstract construct… ¡ In order to actually physically represent a Unicode character in memory, on network, on disk, you must use an encoding ¡ Defined Unicode encoding schemes: § UTF-‐8 (“Unicode Transformation Format”) § UTF-‐16 § UTF-‐32
uses 4 bytes per Unicode character ¡ UTF-‐8 and UTF-‐16 are variable width encodings ¡ UTF-‐8 encodes all Unicode code points using one to four bytes § Backwards compatible with ASCII – 0-‐7f map directly to the ASCII equivalents § No embedded NULLs; compatible with C strings § Used when space/speed is at a premium
or four bytes § If a character cannot be encoded in two bytes (it is outside of the BMP), then a surrogate pair is used § The first surrogate, or high surrogate, falls within the byte range D800 – DBFF § The second surrogate, or low surrogate, falls within the byte range DC00 – DFFF § Used widely throughout Windows & Java
¡ UTF-‐32 is usually represented big-‐endian: § 00 00 26 03 ¡ UTF-‐16 can be represented little-‐ or big-‐ endian § Windows will use little-‐endian by default § The standard says big-‐endian by default § So… most applications will prepend the BOM (Byte Order Mark) – U+FEFF which is a reserved Unicode character
encoding § For example, create databases with UTF-‐8 encoding. The default is “Latin-‐1” ¡ Centralize your Unicode handling § If you’re handling files, for example, see if you can use the hash of the file as a surrogate identifier, with a table mapping hashes to file names § Simplifies handling when external scripts don’t “need” access to the original Unicode filename
Unicode features § Characters in the BMP (Basic Multilingual Plane) § Characters in planes 1-‐17 § Unicode “special” characters ¡ Use Unicode normalization, collation, and comparison libraries § If you’re sorting, comparing, or otherwise doing something other than storing and displaying Unicode text, don’t just sort by byte order
does one sort all these characters? § Normalization: more than one way to encode a character… § Advanced typography: initial, medial, final, isolated forms, bidirectional character layout, … § Date formats, decimal formats (punctuation), and other “locale” items
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}