A high-level discussion on what clustering and classification are, similarities and differences between them, and applications to cyber crime investigations.
• U.S. Department of Justice • Now work for Kyrus • Applied Computer Forensics Research • Tools I've written – Memory forensics – md5deep/hashdeep – fuzzy hashing (ssdeep) – Foremost
five minutes per sample • Which of them are similar to each other? • Which of them fit into existing categories? – Variant of Zeus – Written by $person? – Relevant to this investigation 5
a good hamburger • Both like dogs • Conclusion: Similar • President Obama is 7 cm taller • Jesse does not have gray hair • Work in different career fields • Conclusion: Not similar 13
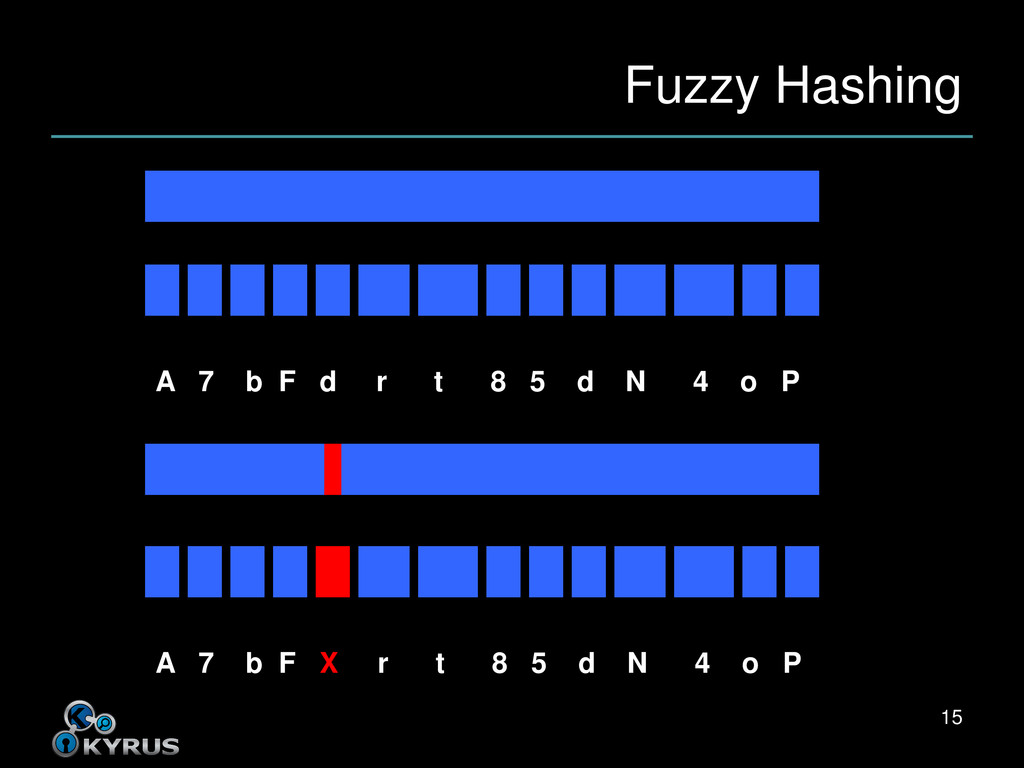
d r t 8 5 d N 4 o P – A 7 b F X r t 8 5 d N 4 o P • Compute the edit distance between the signatures – Edit distance is number of changes necessary to turn one string into the other • Small edit distance means more similar • In this example, the edit distance is one 16
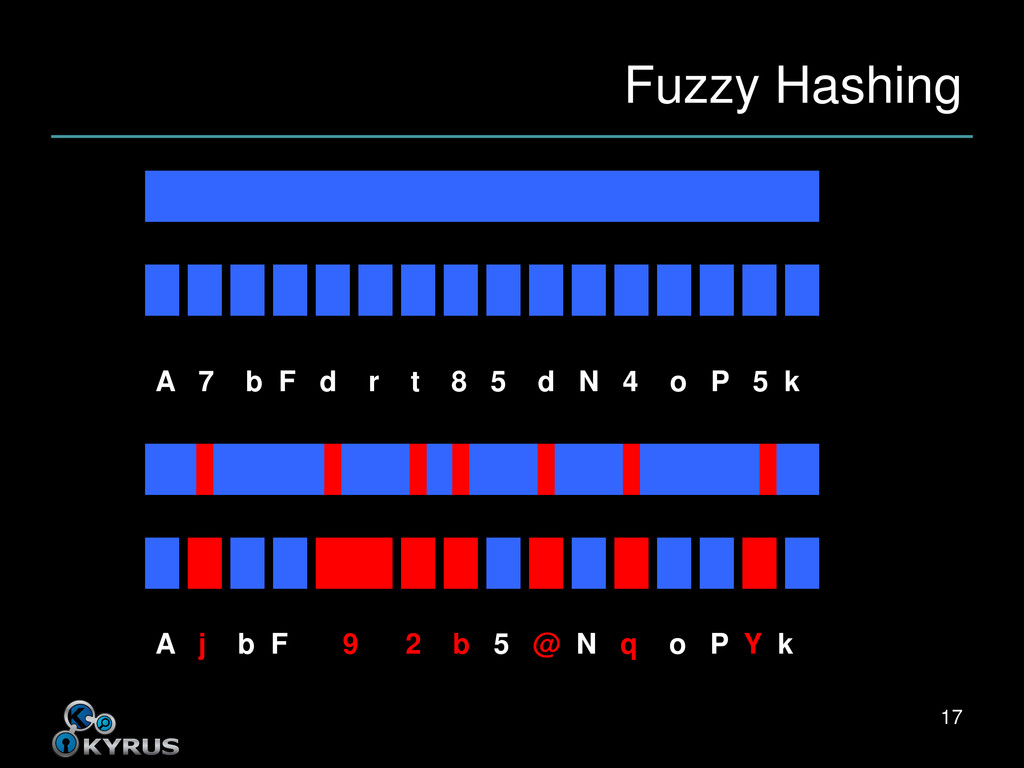
Compare the features mathematically • The result of the comparison is a similarity score • With fuzzy hashing, the features are the hashes of the blocks of raw bytes 18
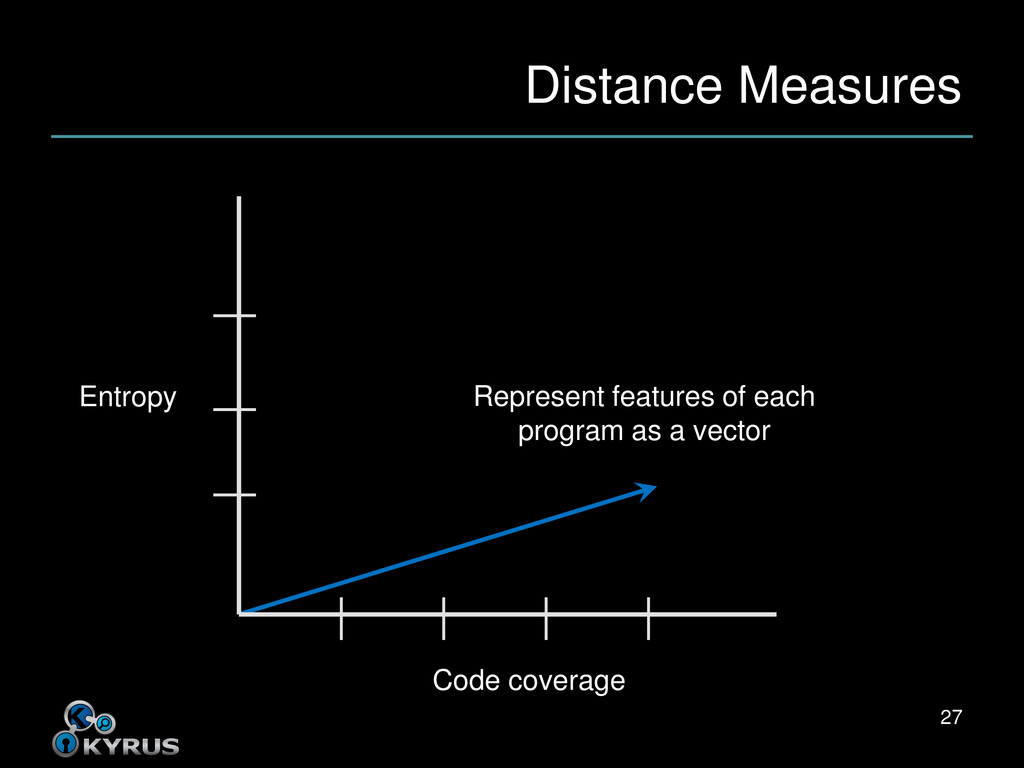
How often APIs are called • Order in which APIs are called • Entropy • DLLs used • Percentage of code coverage • Magic strings • N-grams of instructions • Control-flow graph • IP addresses accessed • … 22 Image courtesy of Flickr user doctor_keats and used under Create Commons license.
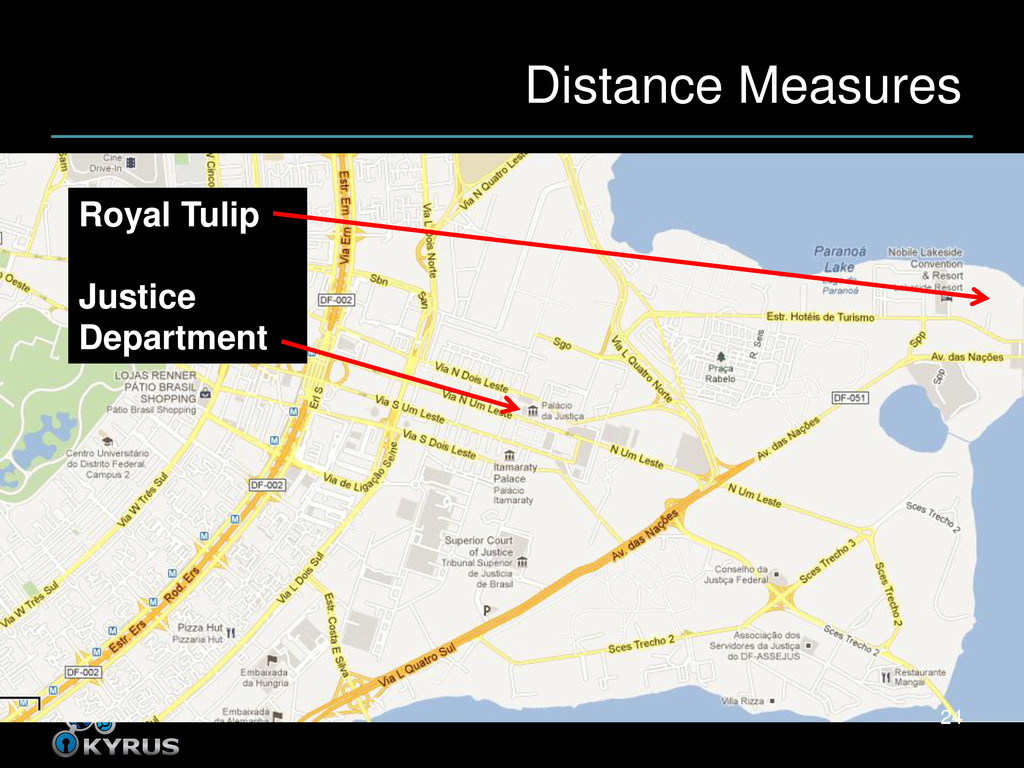
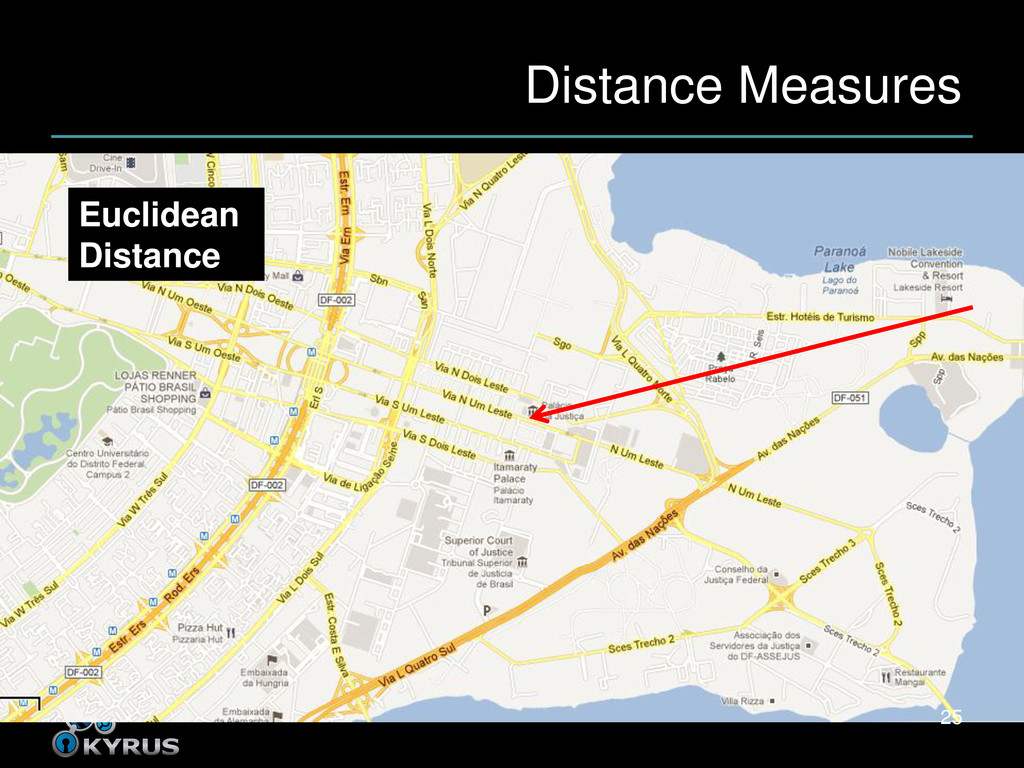
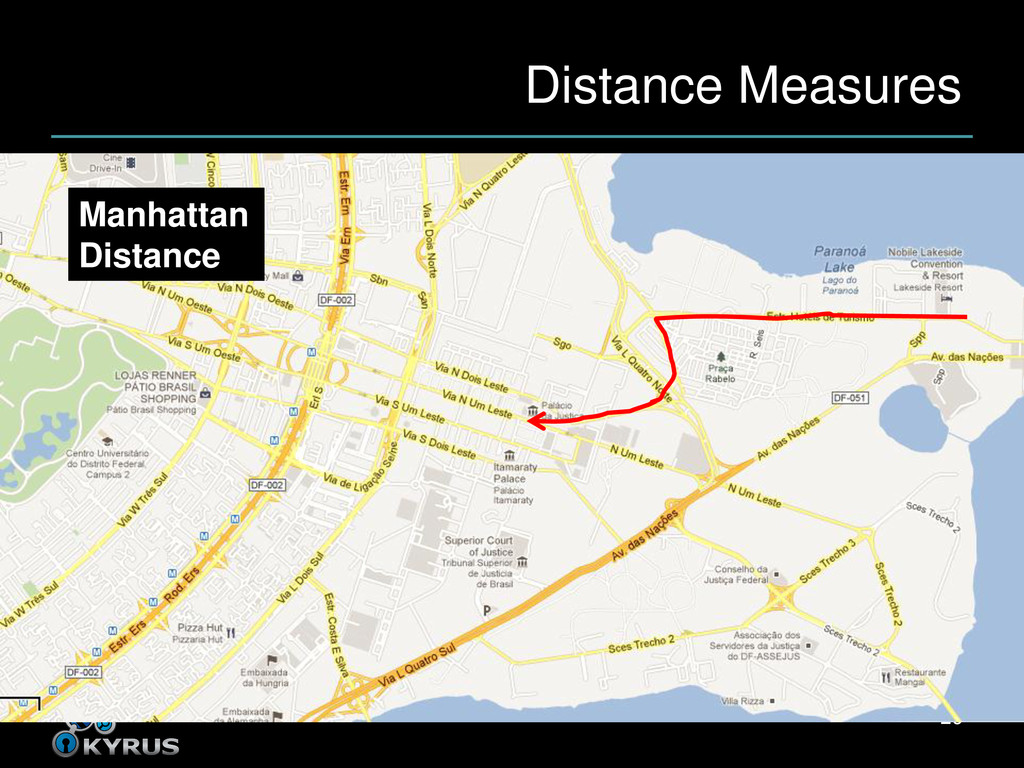
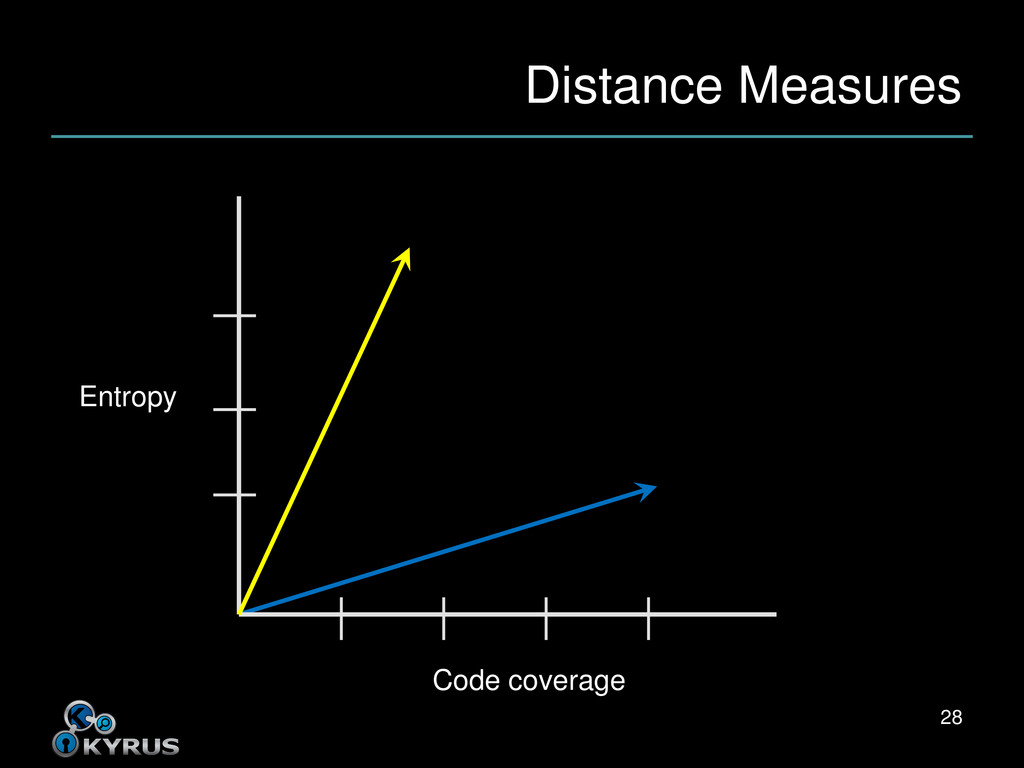
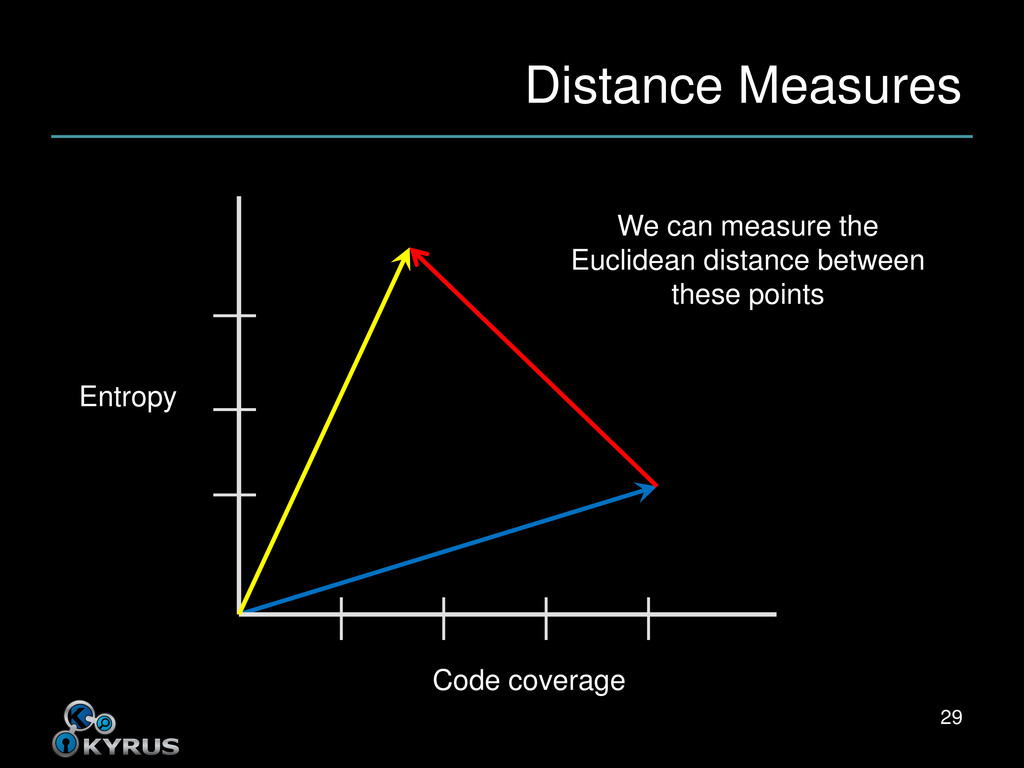
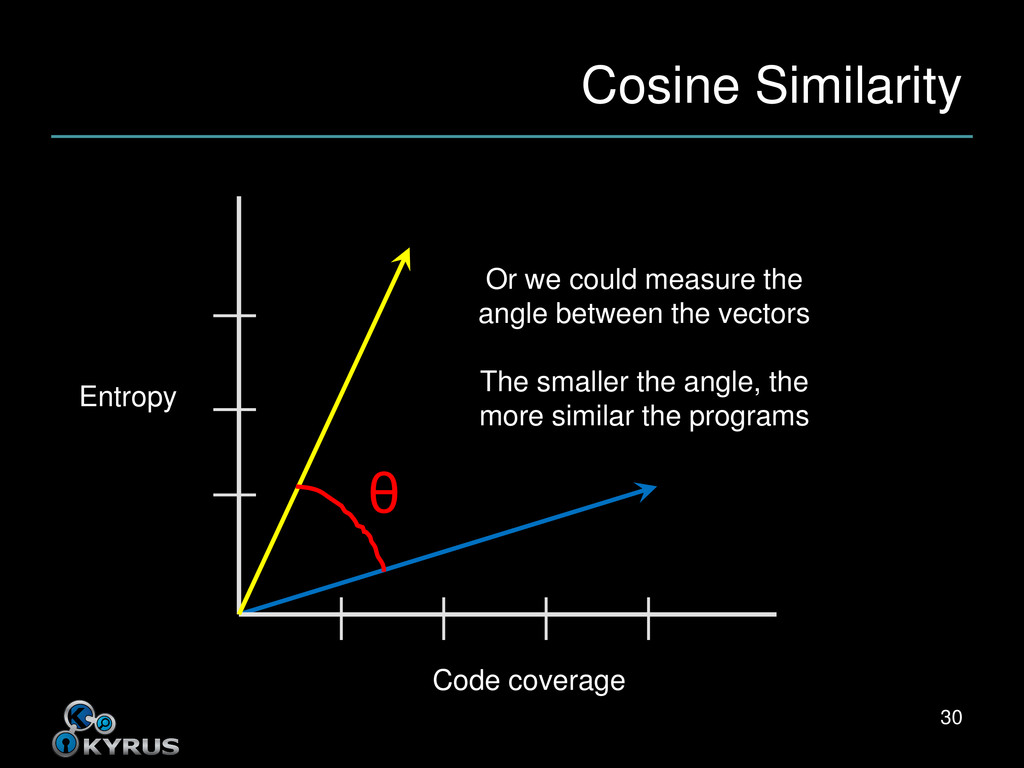
close to each other • Closeness depends on distance measure • What it sounds like – How far apart are the input programs? – As measured by our features • Alternatively, how similar are they? 23
dimensions (features) that comparisons become too time consuming or too complex • No problem • Select the “important” features – (Insert mathy stuff here) • Example: – Presence of crypto constants – Depends on context 31
distance metric for all pairs of inputs For all inputs a and b: if distance(a,b) < threshold add_cluster(a,b) • Exclusive vs. Non-Exclusive clustering – Assume A~B and B~C – Exclusive: {A,B,C} – Non-Exclusive: {A,B} {B,C} 33
Machine Learning • Put inputs into a category – Zeus variant or Not Zeus variant – Written by Microsoft, $person, Other – Relevant to this case or not 36
• Must identify some documents for each possible outcome • Train the algorithm on this data • "Knowledge" is stored by the algorithm • Which can then be applied to new inputs 38 Image courtesy Flickr user dhillan and used under a Creative Commons license, http://www.flickr.com/photos/dhillan/3848315549/
How your spam detector works • Determine which is greater – Probability message is spam? Or ham? – P(spam) or P(ham) – P(spam given features) or P(ham given features) 39
labels which are spam, which are ham 40 From: [email protected] To: [email protected] Subject: V1agra!! T0p quailikty V1aagra delieverd direct to you! http://sales.v1agara.biz/ From: [email protected] To: [email protected] Subject: Wear a jacket It will be cold while you are in Brazil. Please wear a jacket so that I do not worry about you. Love, Mom SPAM HAM
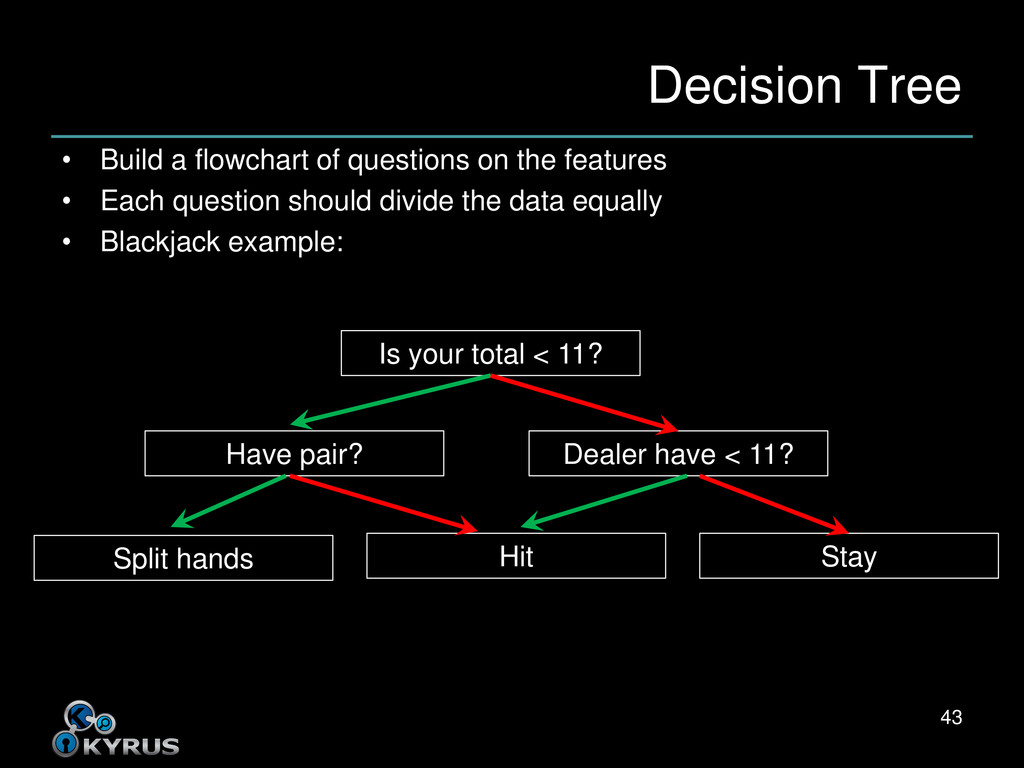
• What questions are best at which point in the tree? • [Insert mathy stuff here] • You could make a career out of efficient decision tree generation – And people do 44
at false positives and false negatives – Run the classifier on the training set • When building, reserve some known values for a test set – Not used in training the classifier • There is a problem of over-fitting – Classifier "knows" the training data too well 47
numbers of inputs for each category 48 Image courtesy Flickr user andyg and used under a Creative Commons license, http://www.flickr.com/photos/andyg/2642257588/
five minutes per sample – Computer time is cheap • Which of them are similar to each other? – Build clusters of programs and documents • Which of them fit into existing categories? – Variant of Zeus – Written by $person? – Relevant to this investigation – Build classifiers for these categories 50
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? Jesse Kornblum [email protected] 52](https://files.speakerdeck.com/presentations/5069c0447979370002001c2e/slide_51.jpg){kind=link}