research that aims to mitigate the effects of unwarranted bias/discrimination on people in machine learning. • Primarily focused on mathematical formalisms of fairness and developing solutions for these formalisms. • IMPORTANT: Fairness is inherently a social and ethical concept. In battle practice, a mage knight data scientist must be equipped with more than just magic algorithms, my friend.
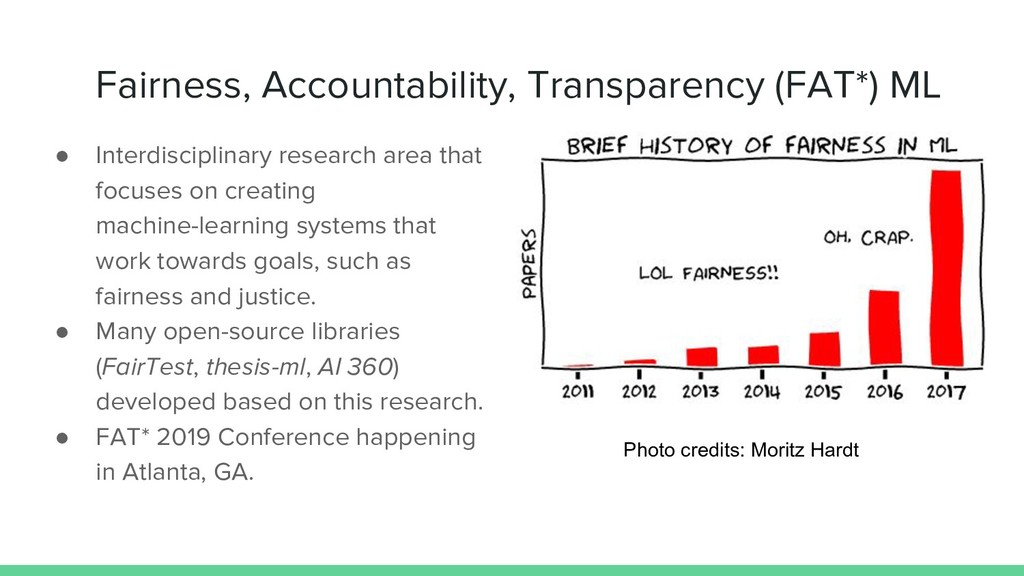
focuses on creating machine-learning systems that work towards goals, such as fairness and justice. • Many open-source libraries (FairTest, thesis-ml, AI 360) developed based on this research. • FAT* 2019 Conference happening in Atlanta, GA. Photo credits: Moritz Hardt
fairness problem (why we invented the math definitions). • Algorithmic Idea: How do models perform in binary classification problems across different groups? • Fundamental Idea: When allocating finite resources (credit loans, gainful employment), we often favor the privileged class over the more vulnerable. Source: Reuters News
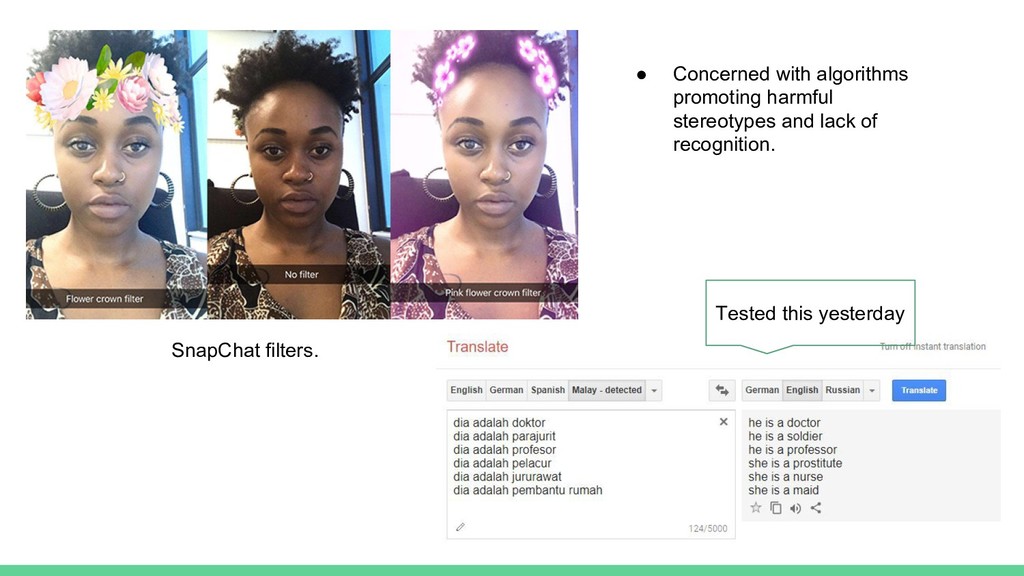
labels/representations are propagated. • Often related to language and computer vision problems. • Harder to quantify error compared to bias in allocation problems.
often not taught to think about how models could be used inappropriately. • With the increasing usage of AI in high-stakes situations, we must be careful not to harm or endanger vulnerable populations. Source: Why Stanford Researcher tried to Create A “Gaydar” Machine; New York Times
30 different mathematical definitions of fairness in the academic literature. • There isn’t a one, true definition of fairness. • These definitions can be grouped together into three families: ◦ Anti-Classification ◦ Classification Parity ◦ Calibration Arvind Narayanan
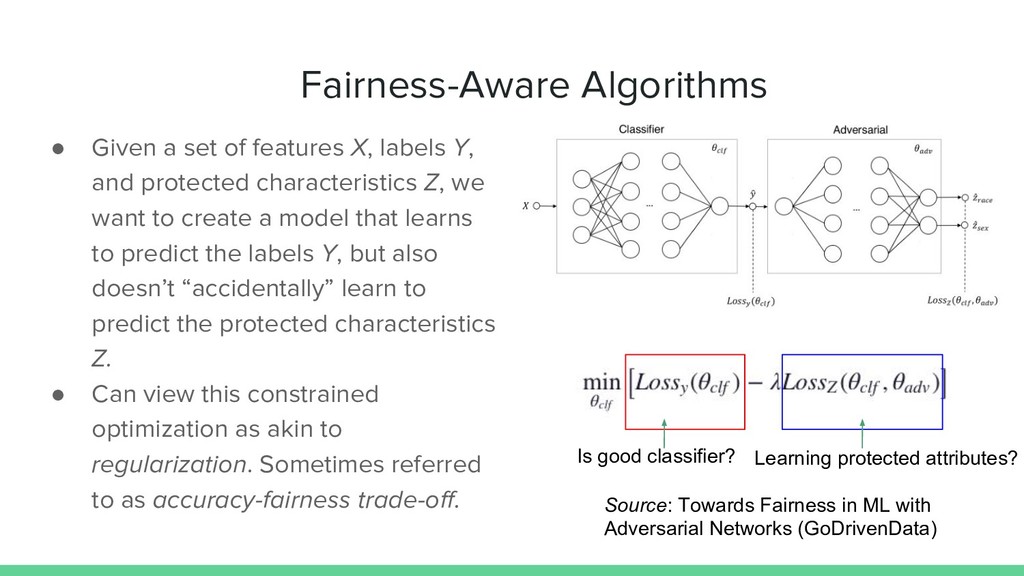
addition to excluding protected attributes, one must also be concerned about learning proxy features. • Useful for defining loss function of fairness-aware models.
Y, and protected characteristics Z, we want to create a model that learns to predict the labels Y, but also doesn’t “accidentally” learn to predict the protected characteristics Z. • Can view this constrained optimization as akin to regularization. Sometimes referred to as accuracy-fairness trade-off. Source: Towards Fairness in ML with Adversarial Networks (GoDrivenData) Is good classifier? Learning protected attributes?
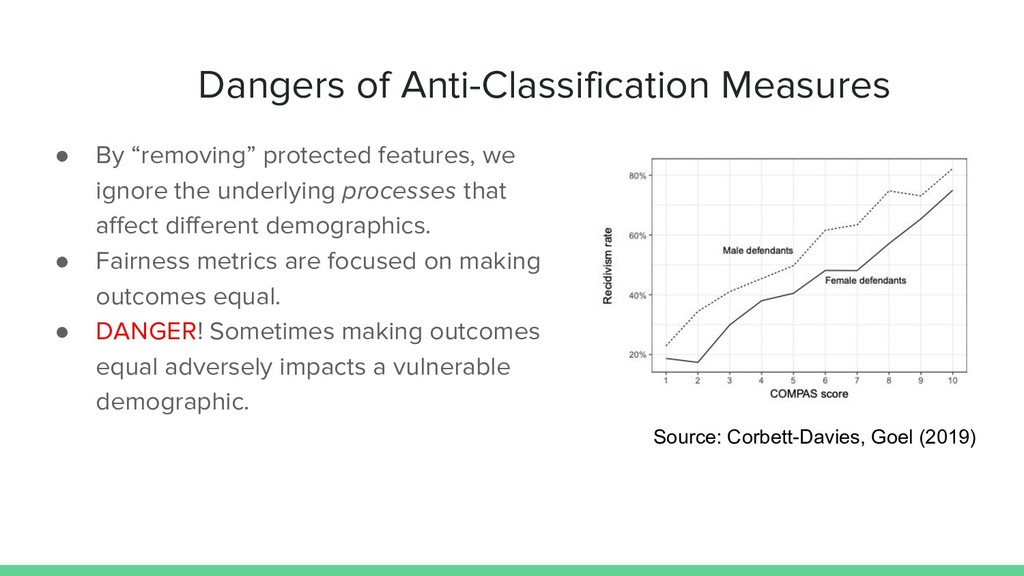
ignore the underlying processes that affect different demographics. • Fairness metrics are focused on making outcomes equal. • DANGER! Sometimes making outcomes equal adversely impacts a vulnerable demographic. Source: Corbett-Davies, Goel (2019)
positive rate), is our measure equal across different protected groups. • Most commonly used to audit algorithms from a legal perspective. Source: Gender Shades, Buolamwini et al. (2018)
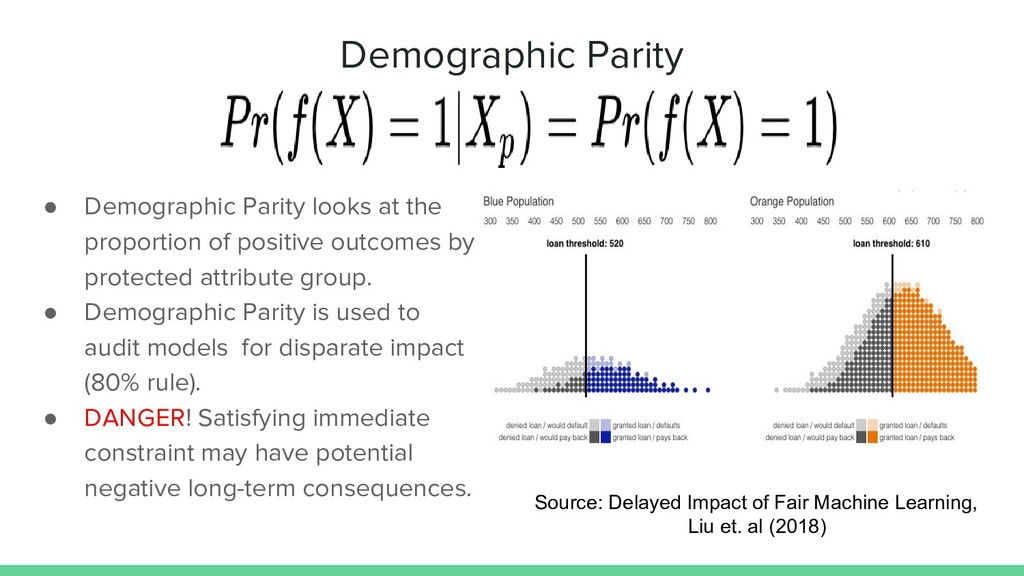
positive outcomes by protected attribute group. • Demographic Parity is used to audit models for disparate impact (80% rule). • DANGER! Satisfying immediate constraint may have potential negative long-term consequences. Source: Delayed Impact of Fair Machine Learning, Liu et. al (2018)
this measures looks at false positive rate across different protected groups. • Sometimes called “Equal Opportunity” • It’s possible to have improve false positive rate by increasing number of true negatives. • DANGER! If we don’t take into considerations societal factors, we may end up harming vulnerable populations. Ignore number of false positives, just increase this.
services), we use a scoring function s(x) to estimate the true risk to the individual. • We define some threshold t to make a decision when s(x) > t. • Example: Child Protective Services (CPS) assigns a risk score to child. CPS intervenes if the perceived risk to the child is high enough.
score s have the same likelihood of receiving the outcome. • A risk score of 10 should mean the same thing for a white individual as it does for a black individual.
recidivism risk score to prisoners. • ProPublica Claim: Black defendants have higher false positive rates. • Northpointe Defense: Risk scores are well-calibrated by groups.
in other industries, such as automobile testing and clinical drug trials, Gebru et. al (2017) propose standards for documenting datasets. • Documentation questions include: ◦ How was the data collection? What time frame? ◦ Why was the dataset created? Who funded its creation? ◦ Does the data contain any sensitive information? ◦ How was the dataset pre-processed/cleaned? ◦ If data relates to people, were they informed about the intended use of the data?
focuses on understanding the societal and cultural impact of AI and machine learning. • Recently hosted a symposium on Ethics, Organizing, and Accountability.
that brings together data scientist, NGO leaders, and policy makers. • Great combination of theoretical research, applied results, and best practices learned by policy-makers. Data 4 Good Exchange (D4GX)
Critical Review of Fair Machine Learning; https://5harad.com/papers/fair-ml.pdf 2. Delayed Impact of Fair Machine Learning; https://arxiv.org/pdf/1803.04383.pdf 3. Data Sheets for Datasets; https://arxiv.org/pdf/1803.09010.pdf 4. Model Cards for Model Reporting; https://arxiv.org/pdf/1810.03993.pdf 5. Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification; http://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf 6. Fairness and Abstraction in Sociotechnical Systems; https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3265913
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}