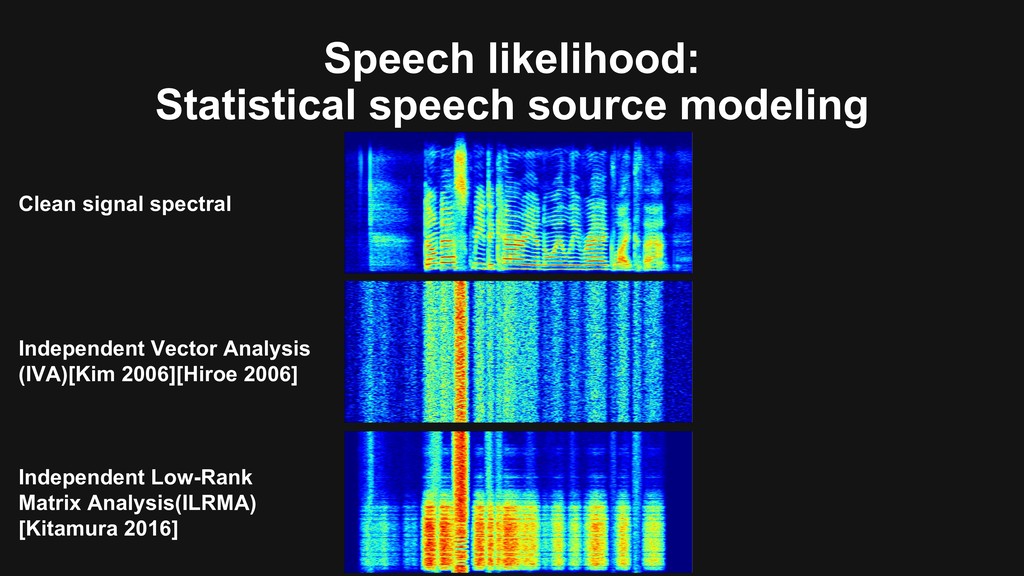
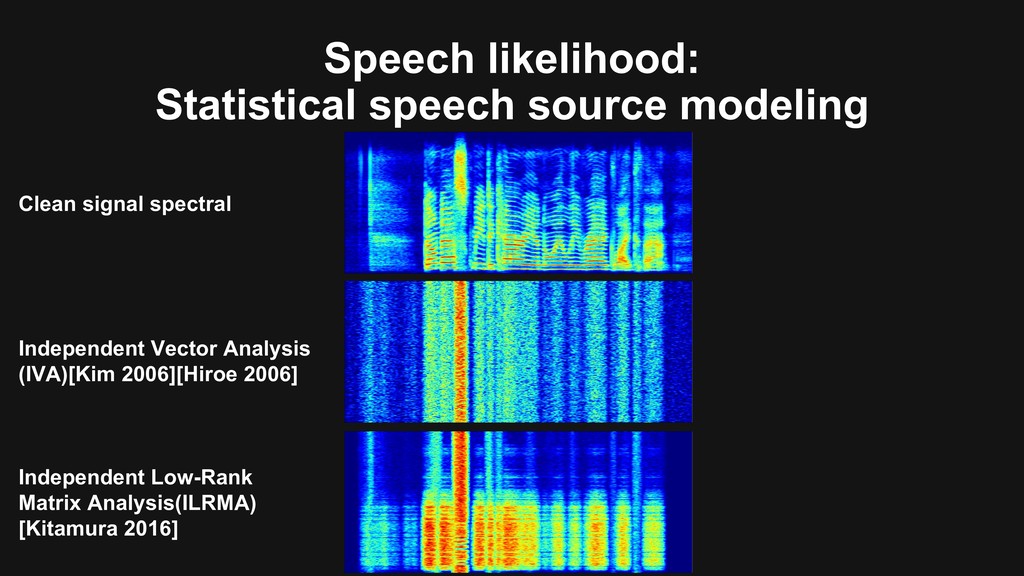
an extension of ica to multivariate components,” in ICA, pp. 165–172, Mar. 2006. [Hiroe 2006] A. Hiroe, “Solution of permutation problem in frequency domain ica using multivariate probability density functions,” in ICA, pp. 601–608, Mar. 2006. [Kitamura 2016] D. Kitamura, et al., “Determined blind source separation unifying independent vector analysis and nonnegative matrix factorization,” IEEE/ACM TASLP., vol. 24, no. 9, pp. 1626-1641, 2016. [Scheibler 2018] R. Scheibler, et al., “Pyroomacoustics: A Python Package for Audio Room Simulation and Array Processing Algorithms,” in ICASSP, 2018, pp. 351-355 [Heymann 2016] J. Heymann, et al., “Neural network based spectral mask estimation for acoustic beamforming,” in ICASSP, 2016, pp. 196-200. [Yoshioka 2018] T. Yoshioka, et al., “Multi-Microphone Neural Speech Separation for Far-Field Multi-Talker Speech Recognition,” in ICASSP, 2018, pp. 5739-5743. [Togami ICASSP2019 (1)] M. Togami, “Multi-channel Itakura Saito Distance Minimization with deep neural network,” in ICASSP, 2019, pp. 536-540. [Masuyama INTERSPEECH2019] Y. Masuyama, et al., “Multichannel Loss Function for Supervised Speech Source Separation by Mask-based Beamforming,” in INTERSPEECH, Sep. 2019. [Togami ICASSP2019 (2)] M. Togami, “Spatial Constraint on Multi-channel Deep Clustering,” in ICASSP, 2019, pp. 531-535. [Togami arxiv2019] M. Togami, et al., “Unsupervised Training for Deep Speech Source Separation with Kullback-Leibler Divergence Based Probabilistic Loss Function,” in arxiv1911.04228, 2019.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
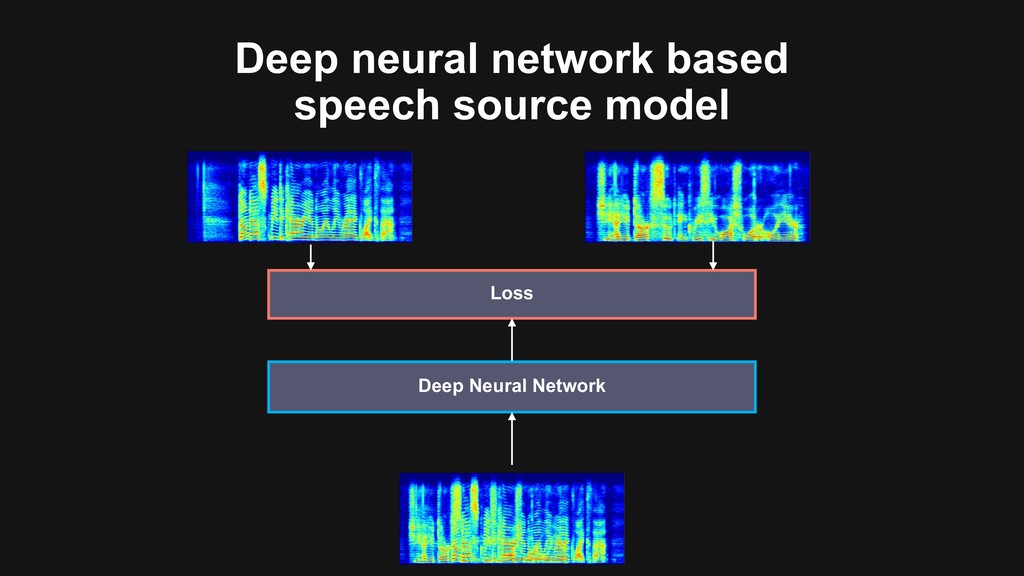{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
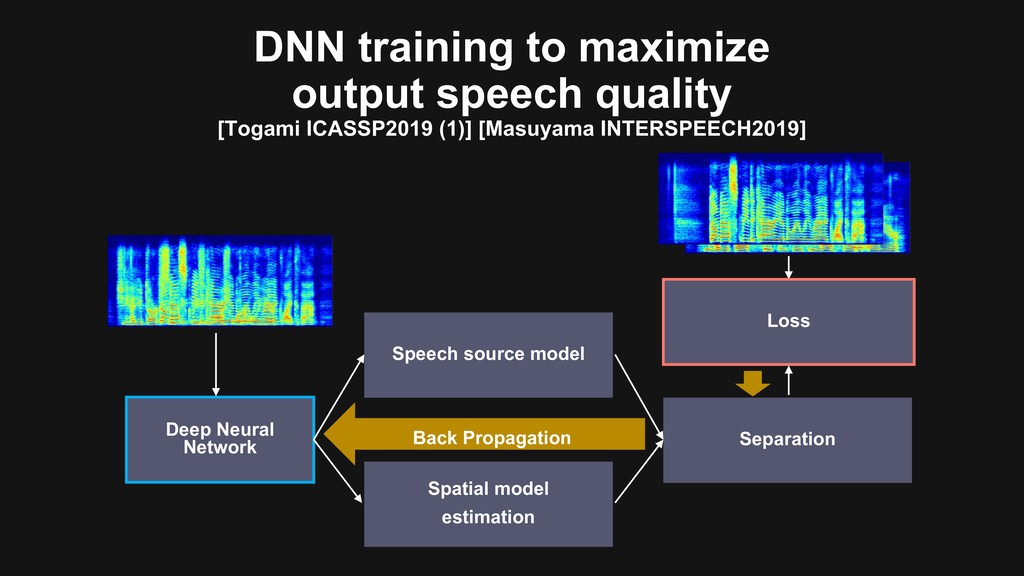{kind=link}
![DNN training to maximize output speech quality [Togami ICASSP2019 (1)]](https://files.speakerdeck.com/presentations/fb7c5291d5d945f89c5d7e9b0b0b9dfb/slide_28.jpg){kind=link}
![DNN training to maximize output speech quality [Togami ICASSP2019 (1)]](https://files.speakerdeck.com/presentations/fb7c5291d5d945f89c5d7e9b0b0b9dfb/slide_29.jpg){kind=link}
![DNN training to maximize output speech quality [Togami ICASSP2019 (1)]](https://files.speakerdeck.com/presentations/fb7c5291d5d945f89c5d7e9b0b0b9dfb/slide_30.jpg){kind=link}
![DNN training to maximize output speech quality [Togami ICASSP2019 (1)]](https://files.speakerdeck.com/presentations/fb7c5291d5d945f89c5d7e9b0b0b9dfb/slide_31.jpg){kind=link}
![DNN training to maximize output speech quality [Masuyama INTERSPEECH2019] SIR](https://files.speakerdeck.com/presentations/fb7c5291d5d945f89c5d7e9b0b0b9dfb/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Unsupervised DNN training [Togami arxiv2019] It is hard to obtain](https://files.speakerdeck.com/presentations/fb7c5291d5d945f89c5d7e9b0b0b9dfb/slide_41.jpg){kind=link}
![Unsupervised DNN training [Togami arxiv2019] It is hard to obtain](https://files.speakerdeck.com/presentations/fb7c5291d5d945f89c5d7e9b0b0b9dfb/slide_42.jpg){kind=link}
![Deep Neural Network Unsupervised DNN training [Togami arxiv2019] Speech source](https://files.speakerdeck.com/presentations/fb7c5291d5d945f89c5d7e9b0b0b9dfb/slide_43.jpg){kind=link}
![Deep Neural Network Unsupervised DNN training [Togami arxiv2019] Speech source](https://files.speakerdeck.com/presentations/fb7c5291d5d945f89c5d7e9b0b0b9dfb/slide_44.jpg){kind=link}
![Deep Neural Network Unsupervised DNN training [Togami arxiv2019] Speech source](https://files.speakerdeck.com/presentations/fb7c5291d5d945f89c5d7e9b0b0b9dfb/slide_45.jpg){kind=link}
![Unsupervised DNN training [Togami arxiv2019] Speech source model Spatial model](https://files.speakerdeck.com/presentations/fb7c5291d5d945f89c5d7e9b0b0b9dfb/slide_46.jpg){kind=link}
![Unsupervised DNN training [Togami arxiv2019] Speech source model Spatial model](https://files.speakerdeck.com/presentations/fb7c5291d5d945f89c5d7e9b0b0b9dfb/slide_47.jpg){kind=link}
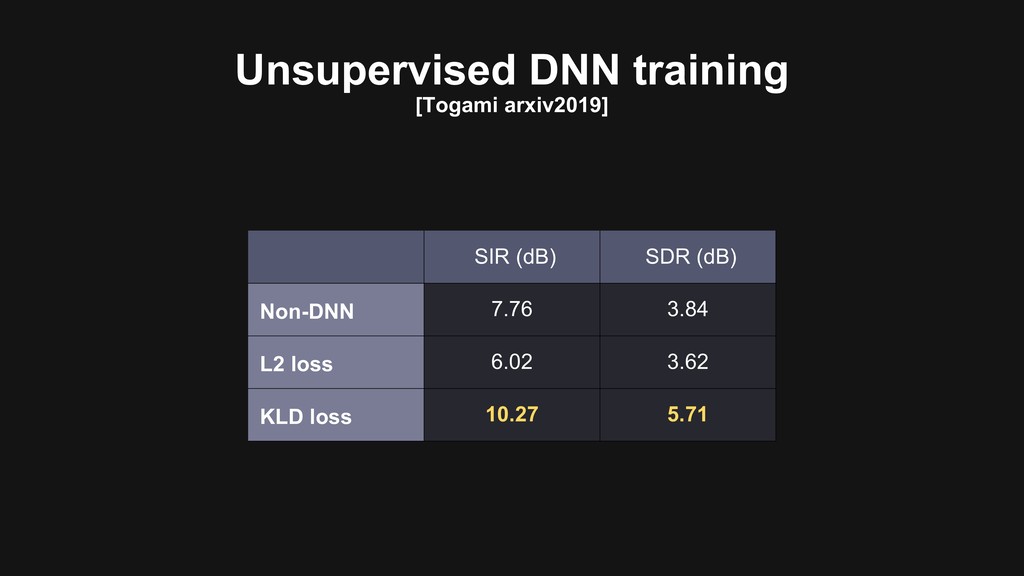{kind=link}
![Unsupervised DNN training [Togami arxiv2019] Oracle clean Noisy microphone input](https://files.speakerdeck.com/presentations/fb7c5291d5d945f89c5d7e9b0b0b9dfb/slide_49.jpg){kind=link}
![Unsupervised DNN training [Togami arxiv2019] Oracle clean Noisy microphone input](https://files.speakerdeck.com/presentations/fb7c5291d5d945f89c5d7e9b0b0b9dfb/slide_50.jpg){kind=link}
![Unsupervised DNN training [Togami arxiv2019] Oracle clean Noisy microphone input](https://files.speakerdeck.com/presentations/fb7c5291d5d945f89c5d7e9b0b0b9dfb/slide_51.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References [Kim 2006] T. Kim, et al., “Independent vector analysis:](https://files.speakerdeck.com/presentations/fb7c5291d5d945f89c5d7e9b0b0b9dfb/slide_57.jpg){kind=link}
{kind=link}