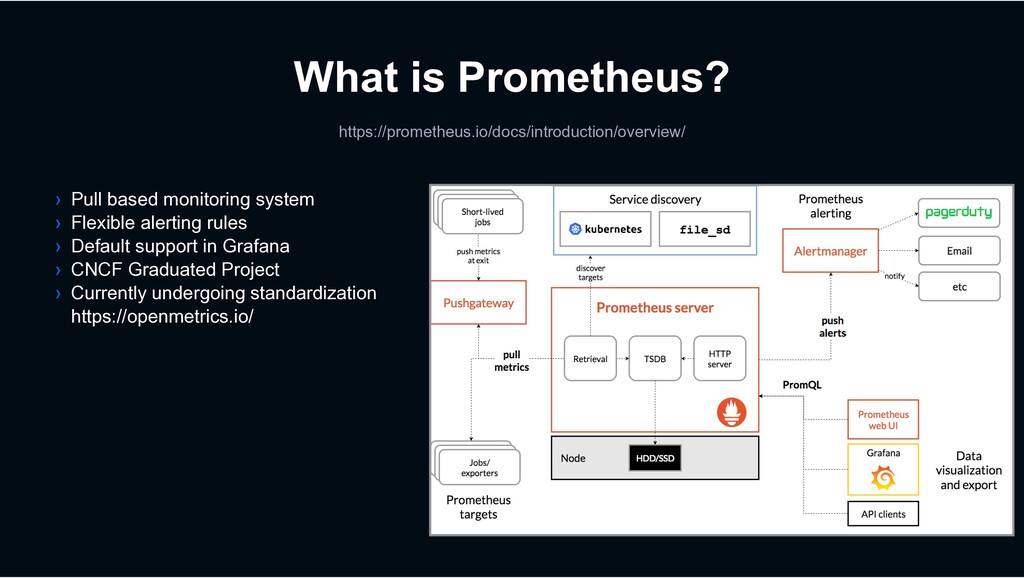
in San Francisco, California › LINE Fukuoka ~4 years › Primarily focused on Monitoring as a Service › Dabbles in Swift and iOS development Introduction - Paul Traylor
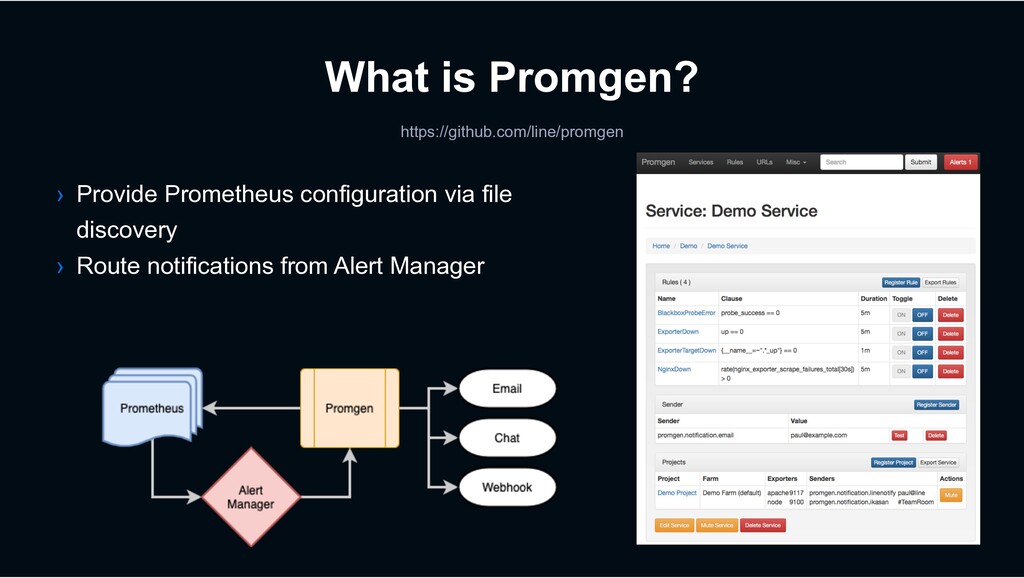
to manually write configurations • Prometheus scrape configs • Alert rules • Alertmanager routing › Want a web ui to quickly configure things › Custom Prometheus discovery is via files https://github.com/line/promgen
• Mostly VMs ~10 › Beta Cluster • Integration Testing • Monitoring for Development and Staging services • Several default rules disabled for noise › Release Cluster • Monitoring for live services
for any developer to register on › Example team specific shards • LINE Shop • Spring Boot + Armeria • Large number of samples / Target • Data Analysis • Hadoop + Fluentd + Kafka • Fewer samples per target / more targets • Ads platform • Many microservices in Go • Tendency to include many campaign ids in labels • Securities (ূ݊) • Separate environment for security reasons
have various default rules • Memory • Disk › Users are free to register custom rules for their service › We also support overriding with custom thresholds
children # Uses Promgen <exclude> tag internally example_rule{<exclude>} example_rule{service!~"A|B",} # Service A override includes self - example_rule{service="A",} # Service B override includes self, but excludes children - example_rule{service="B", project!~"C"}: # Project Override - example_rule{project="C"}
Authed against internal GHE instance • Manual login for project managers and other users › Custom organizations • custom dashbords • datasources › Contractor organizations • Separate instances in docker containers • Authed against specific GHE orgs • Should only be able to see their data
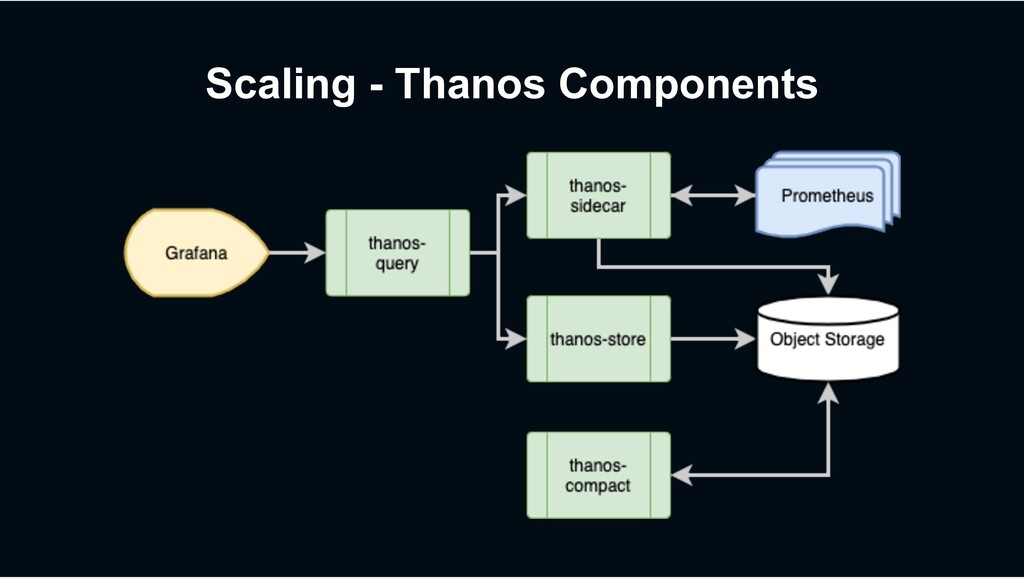
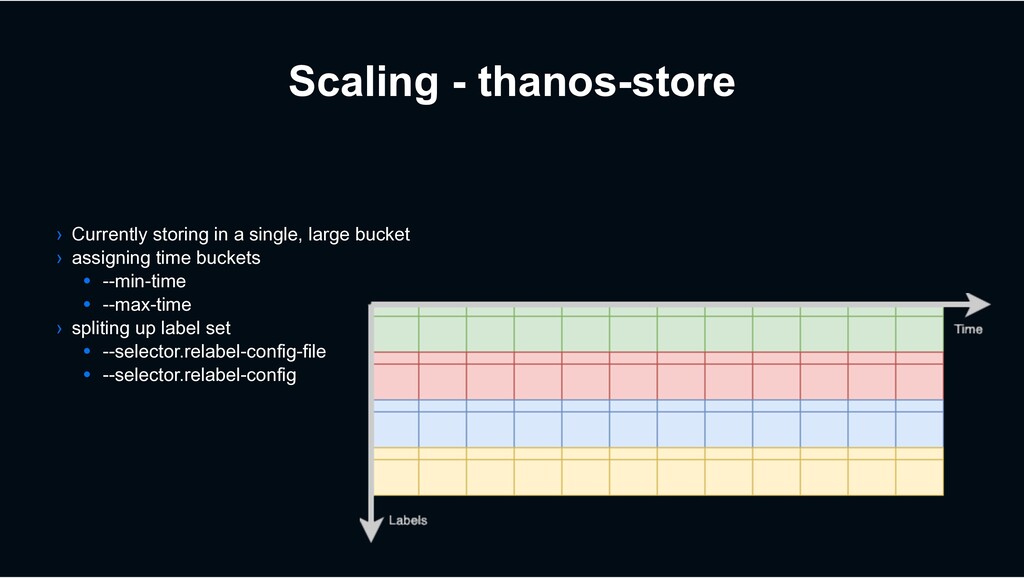
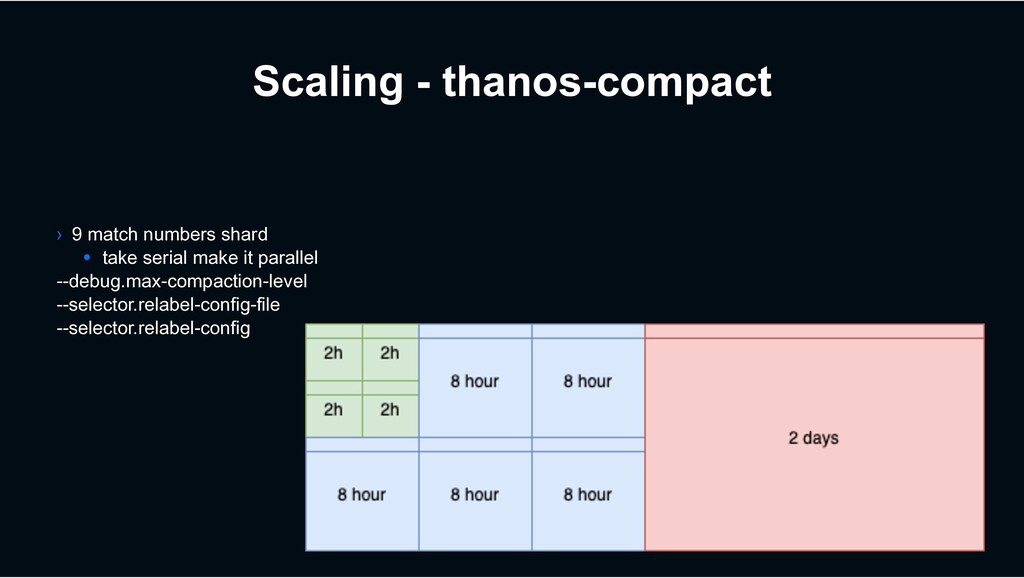
S3, Minio, etc) • 150+ Tb in Object Storage • 600,000 + Objects • Over 1 year data in release enviornment • Over 2 years data in beta environment › Use Prometheus block format • 2h, 8h, 2d, 2w • Some 2w blocks are 500+ GB
Needs lots of disk to rewrite blocks • Some 2w blocks are 500+ GB • Sometimes have to order “custom” Verda servers › 5 thanos-store nodes • Needs disk for blocks • Needs memory for index
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
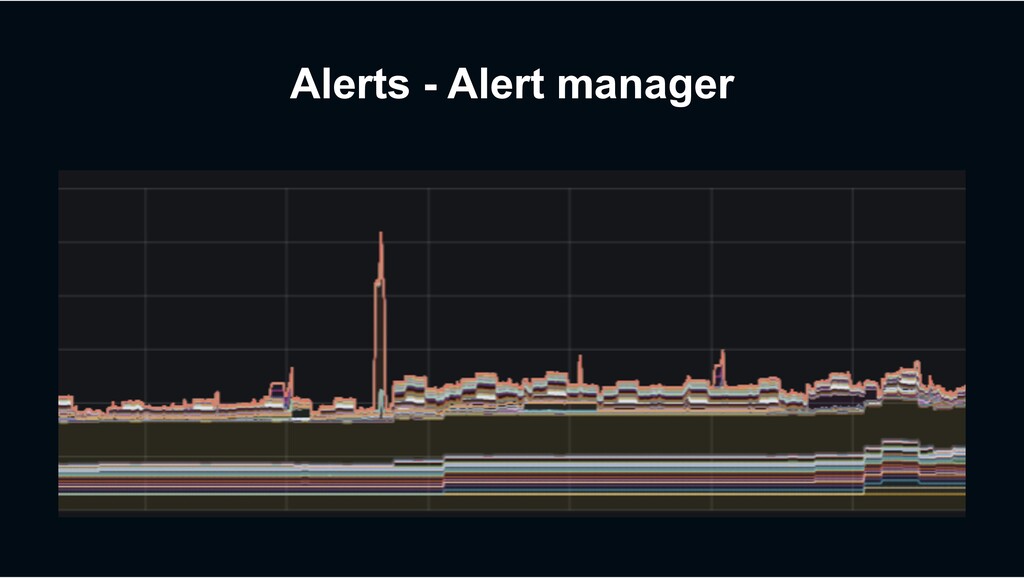
![Alerts - Internal AlertDeliveryError rate(alertmanager_notifications_failed_total[5m]) > 0 PrometheusNotificationDelivery rate(prometheus_notifications_errors_total[5m]) >](https://files.speakerdeck.com/presentations/17cc2cf338704183998f2a98b28b3b33/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}