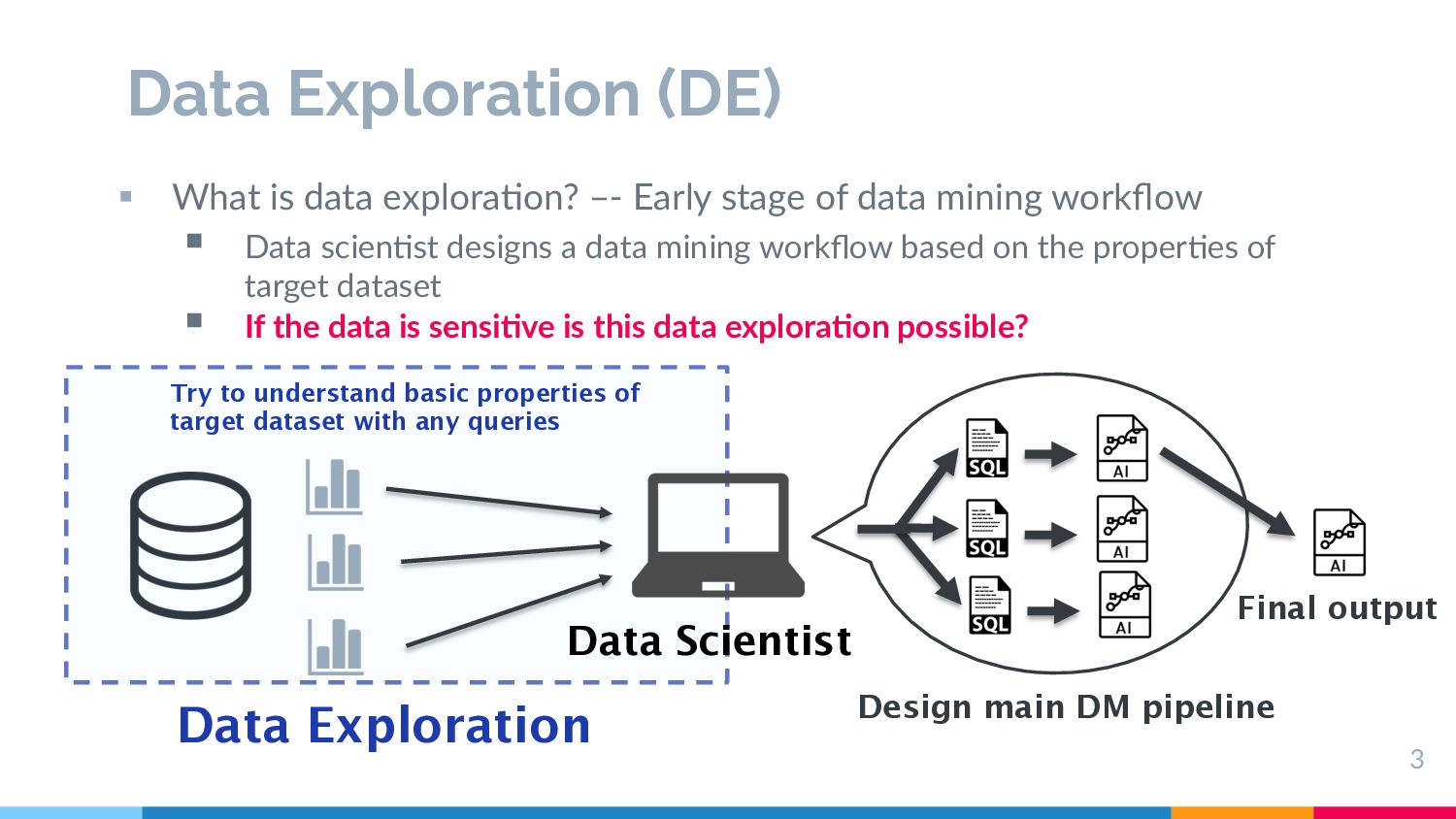
stage of data mining workflow § Data scien/st designs a data mining workflow based on the proper/es of target dataset § If the data is sensi,ve is this data explora,on possible? 3 Design main DM pipeline Try to understand basic properties of target dataset with any queries Data Exploration Data Scientist Final output
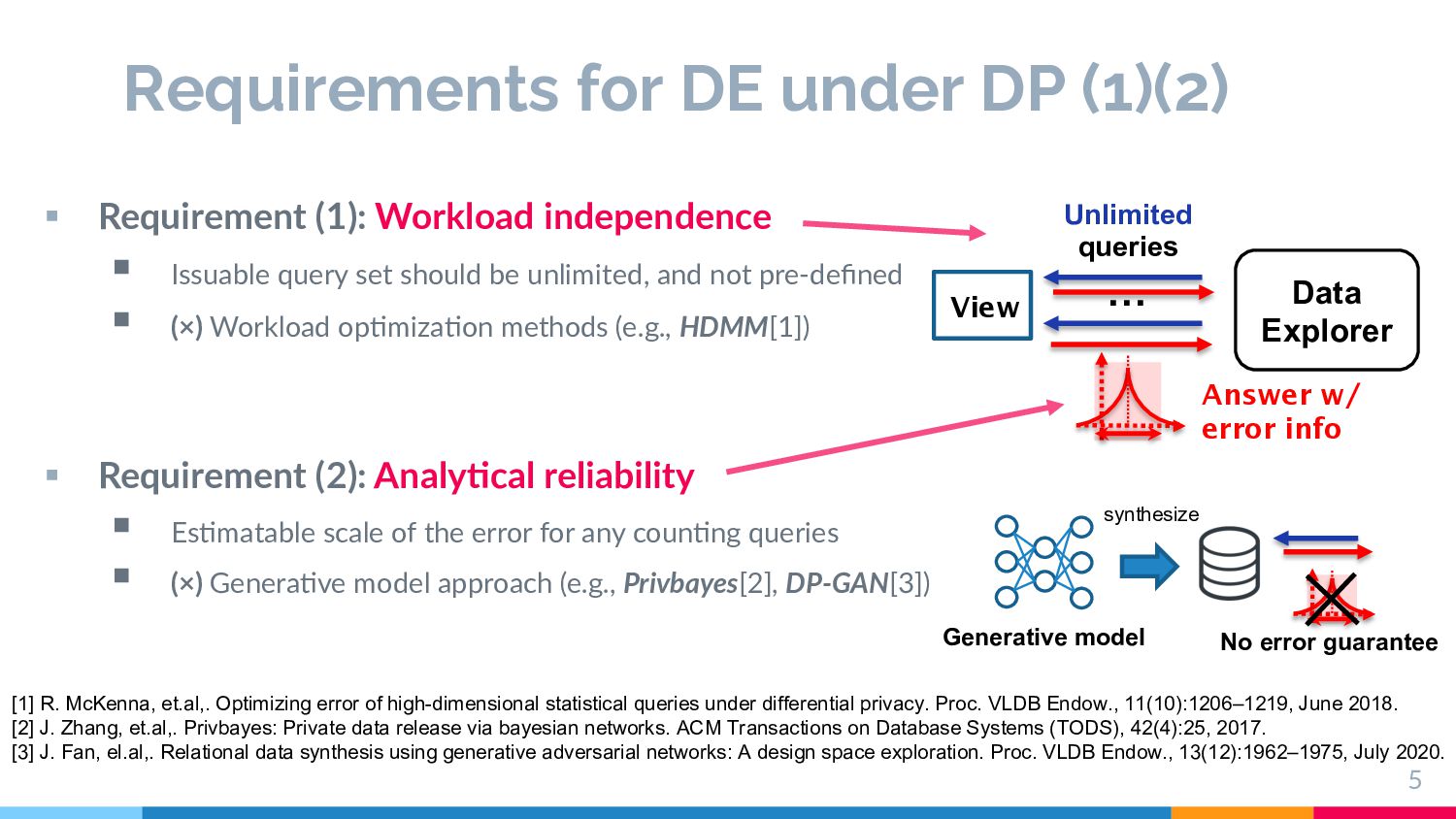
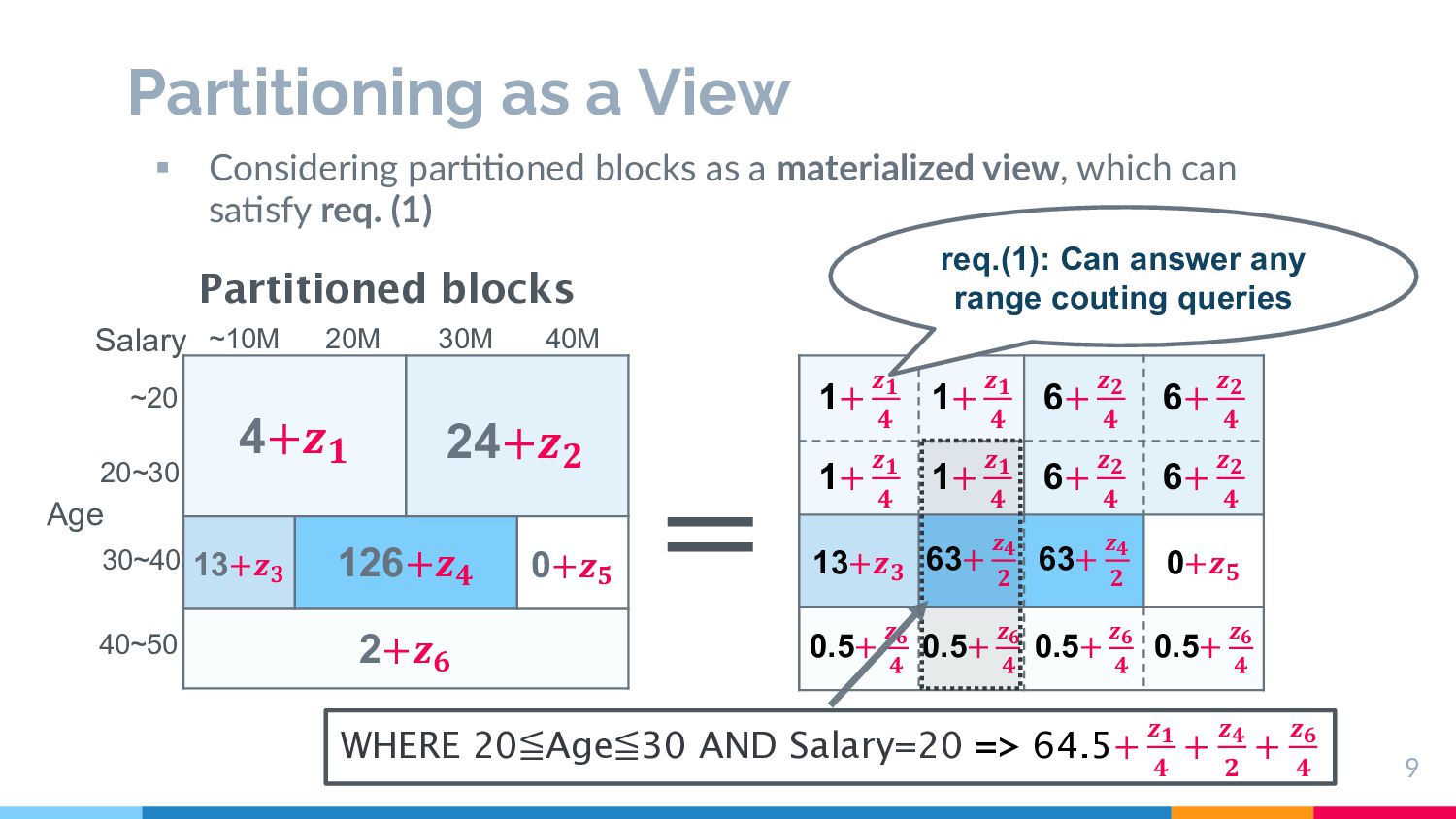
independence § Issuable query set should be unlimited, and not pre-defined § (×) Workload op9miza9on methods (e.g., HDMM[1]) § Requirement (2): Analy;cal reliability § Es9matable scale of the error for any coun9ng queries § (×) Genera9ve model approach (e.g., Privbayes[2], DP-GAN[3]) 5 [1] R. McKenna, et.al,. Optimizing error of high-dimensional statistical queries under differential privacy. Proc. VLDB Endow., 11(10):1206–1219, June 2018. [2] J. Zhang, et.al,. Privbayes: Private data release via bayesian networks. ACM Transactions on Database Systems (TODS), 42(4):25, 2017. [3] J. Fan, el.al,. Relational data synthesis using generative adversarial networks: A design space exploration. Proc. VLDB Endow., 13(12):1962–1975, July 2020. Data Explorer Unlimited queries … Answer w/ error info No error guarantee View Generative model synthesize
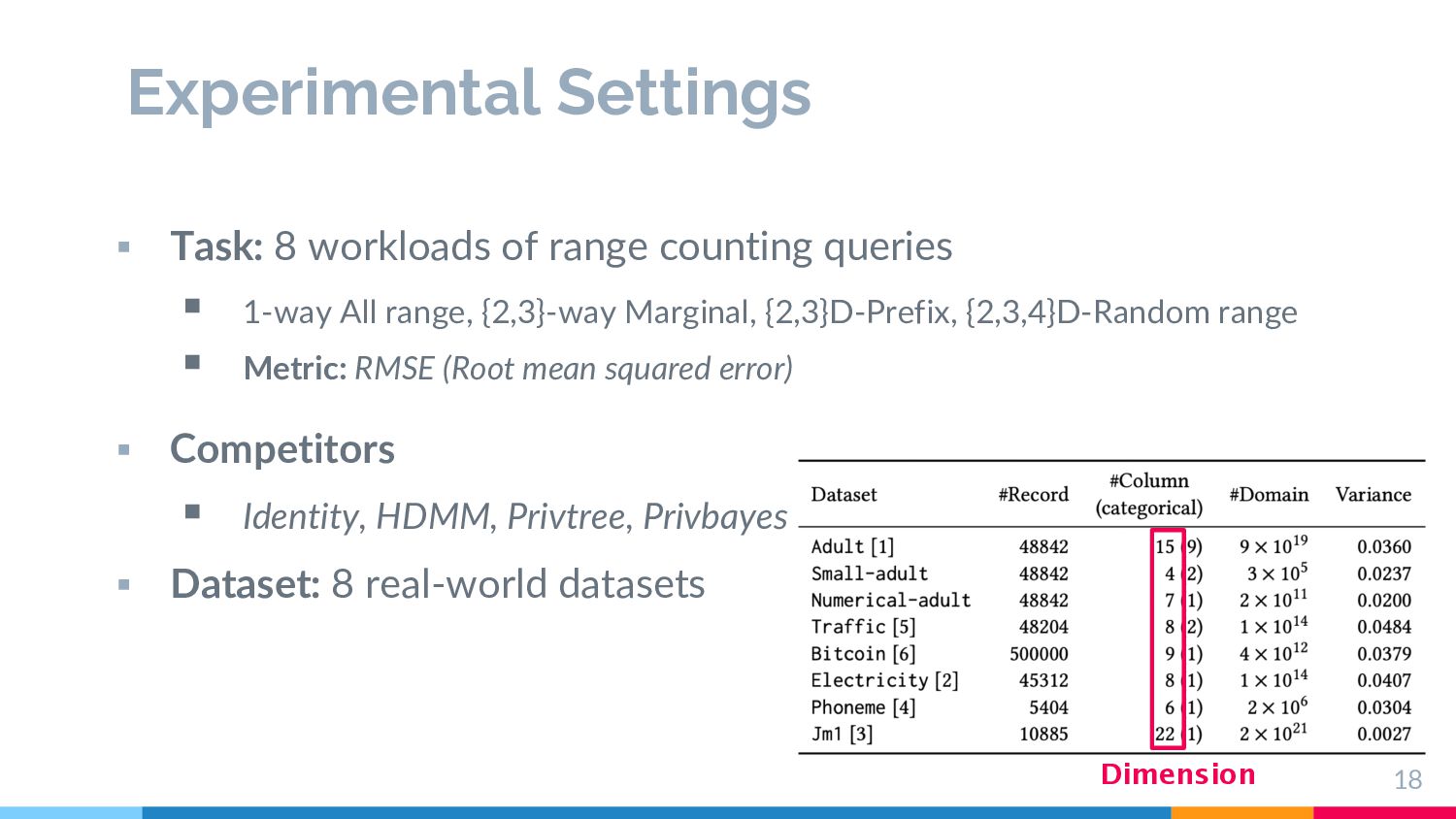
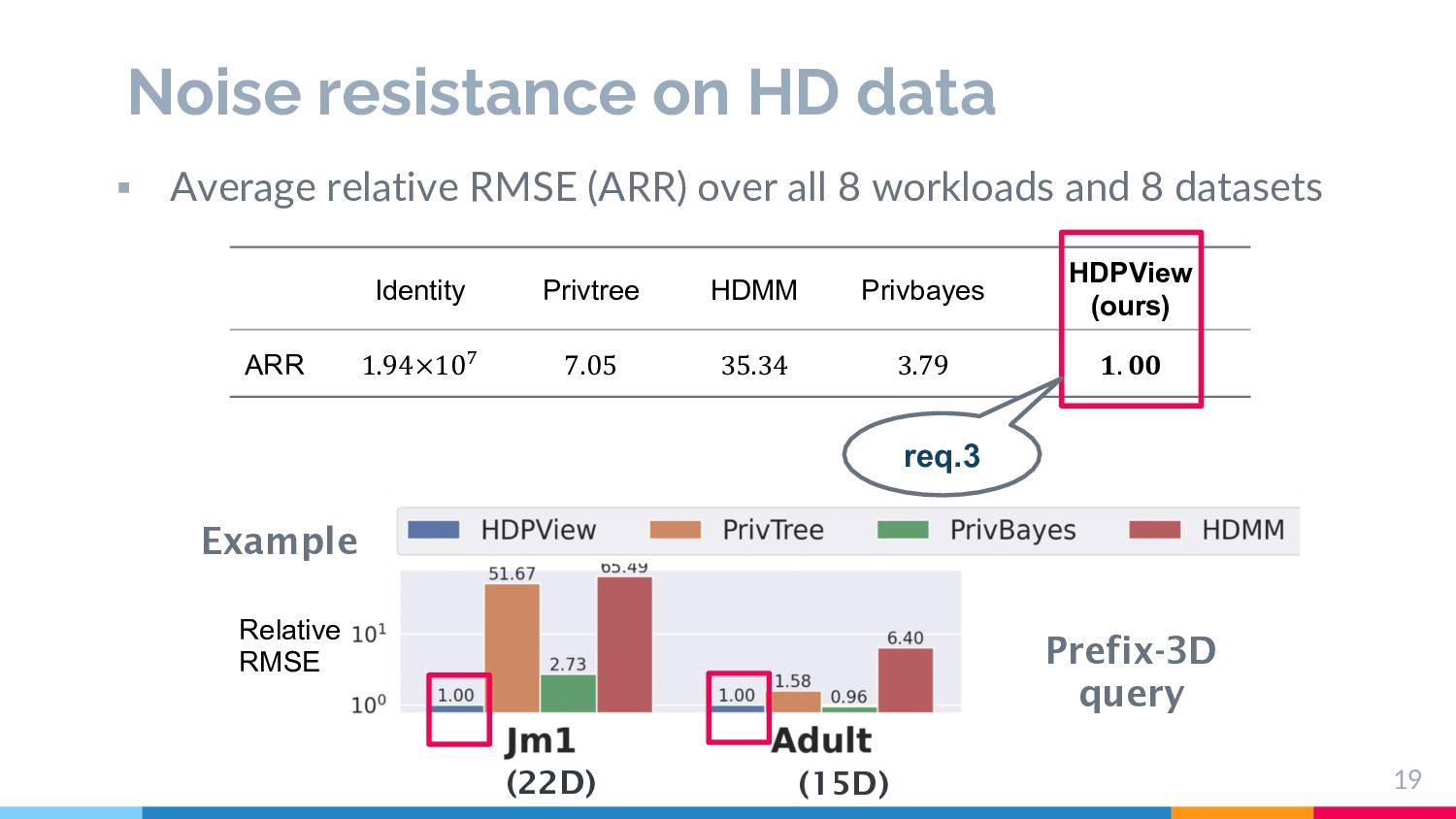
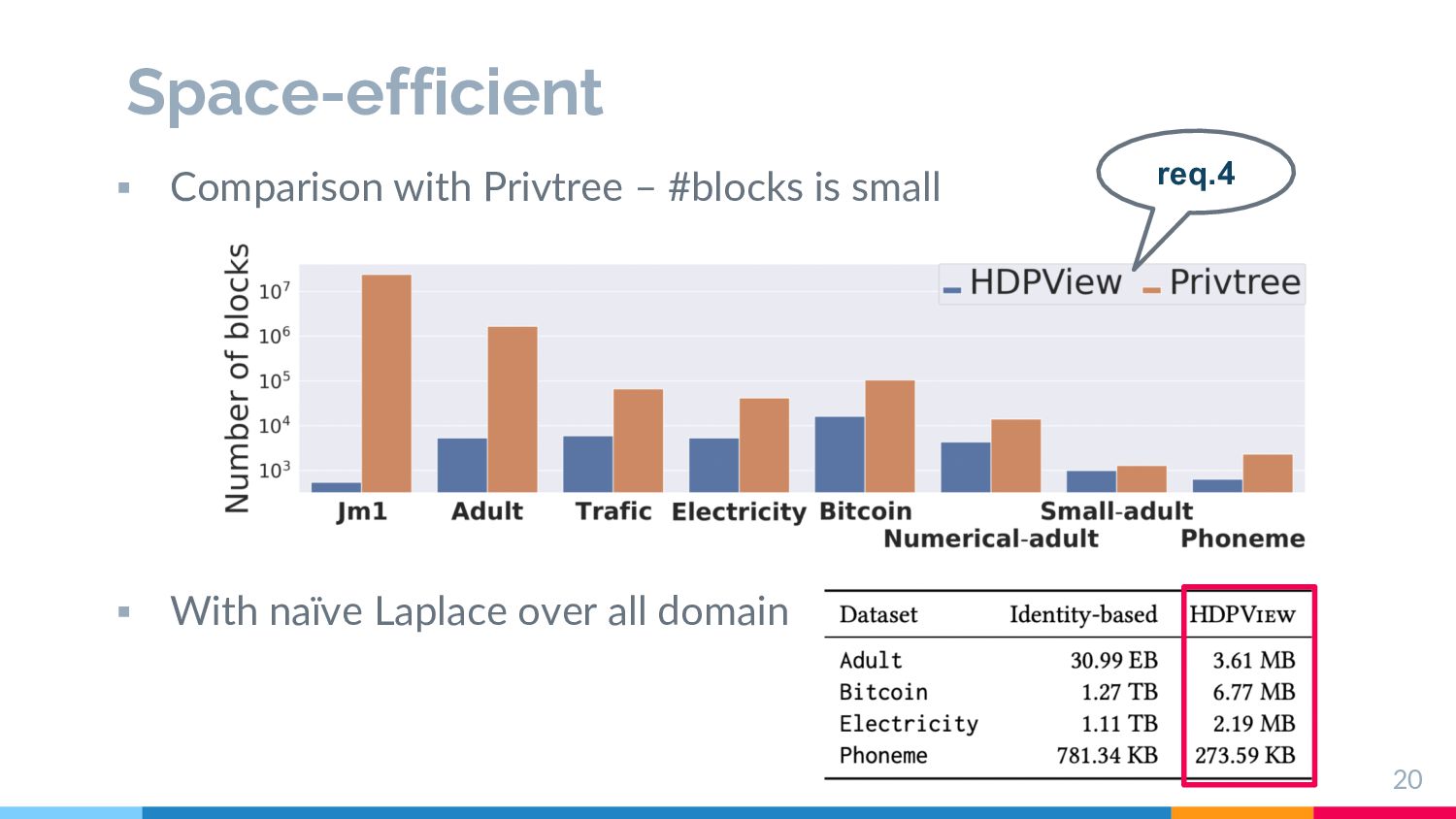
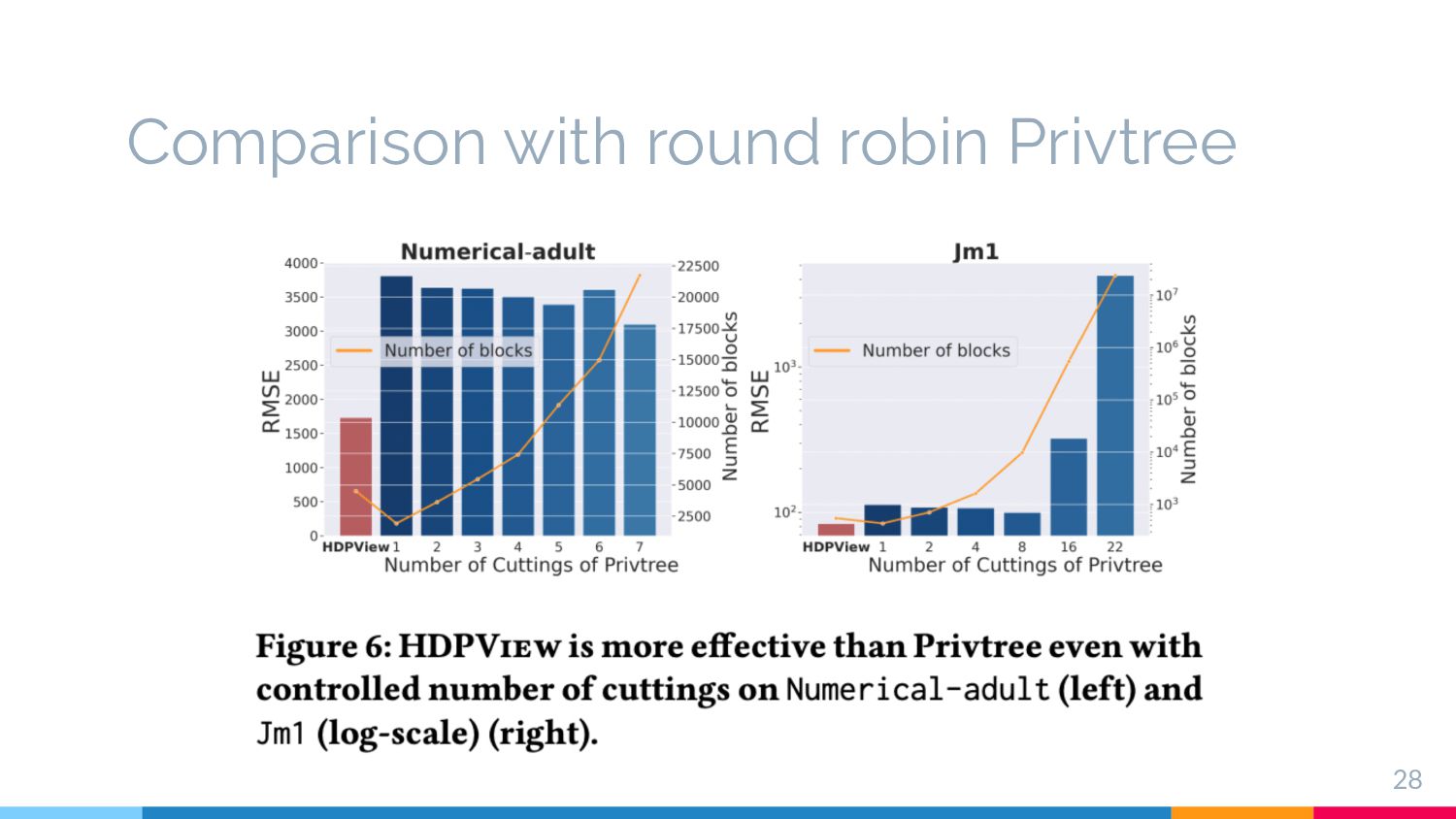
resistance on high-dimensional data § Explore high-dimensional rela2onal data with less noise § (×) Exis2ng par22oning based methods (e.g., Privtree[4], DAWA’s par22on[5]) § Requirement (4): Space efficient view § View to be explored should be space-efficient 6 [4] Zhang, Jun, et.al,. Privtree: A differentially private algorithm for hierarchical decompositions. Proceedings of the 2016 SIGMOD. 2016. [5] C. Li, et.al,. A data-and workload-aware algorithm for range queries under differential privacy. Proceedings of the VLDB Endowment, 7(5):341–352, 2014. e.g., 20 columns
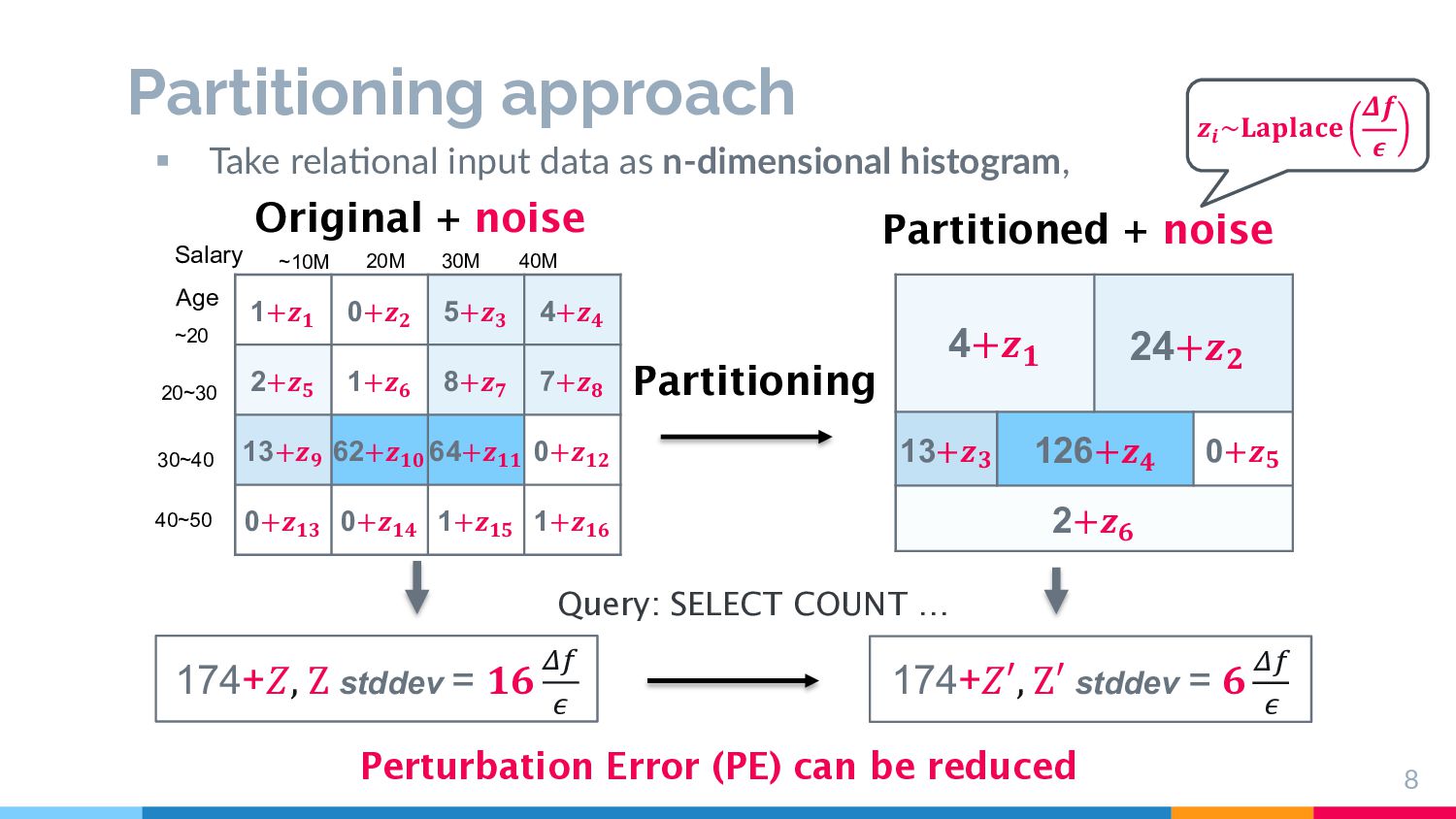
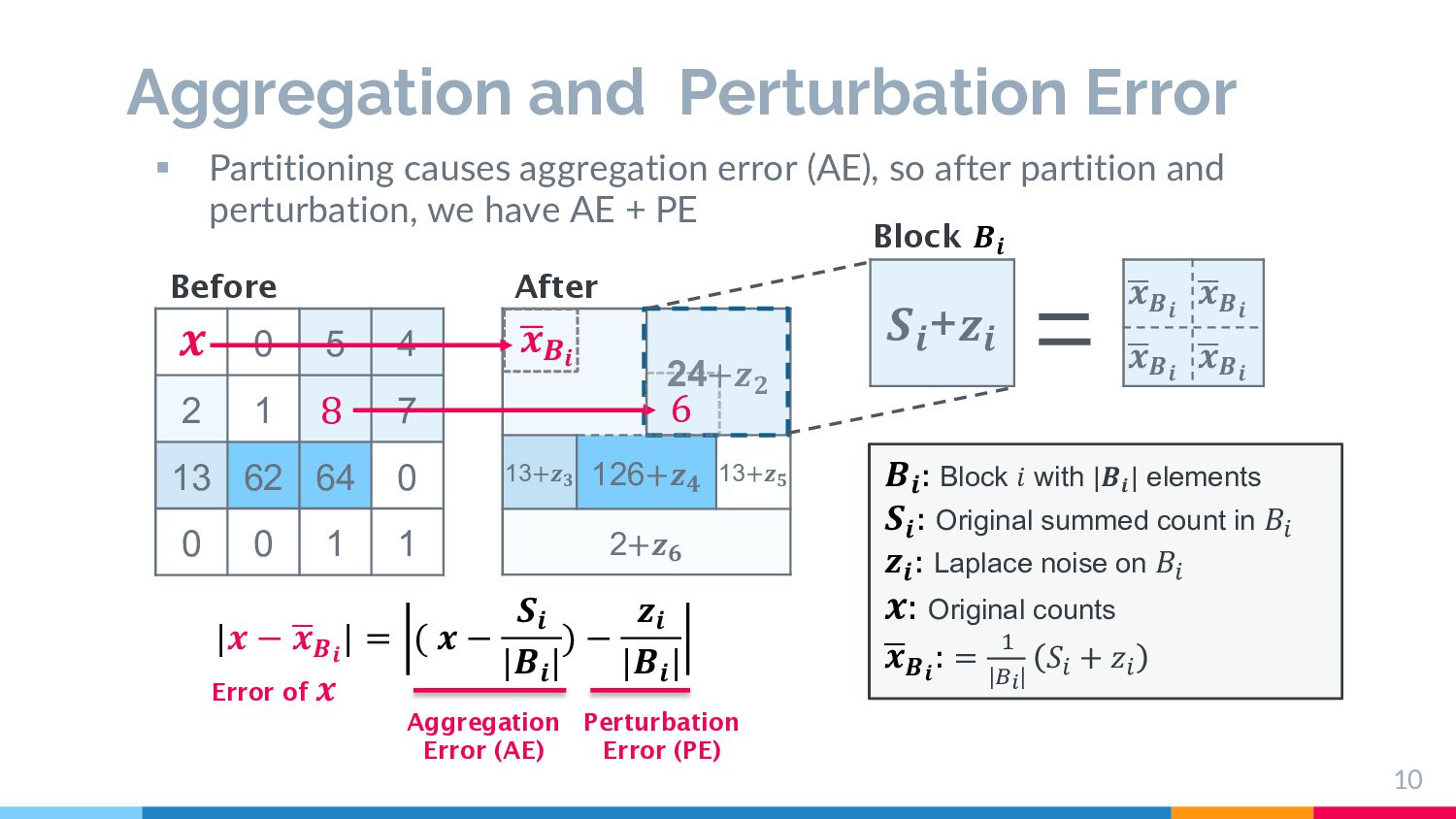
optimization problem ! " #∈ % " &∈'# |& − * &'# | ≤ ! " #∈ % ,-('# ) + ! " #∈ % 1-('# ) ≤ " #∈ % ,- '# + % ⋅ 3 4 Goal: Minimization § An instance of the set partitioning problem: NP-Hard § Search algorithm for the optimal partitioning must satisfy DP We need to consider heuristic solutions to obtain better partitioning, and it must be simple enough to allow DP analysis.
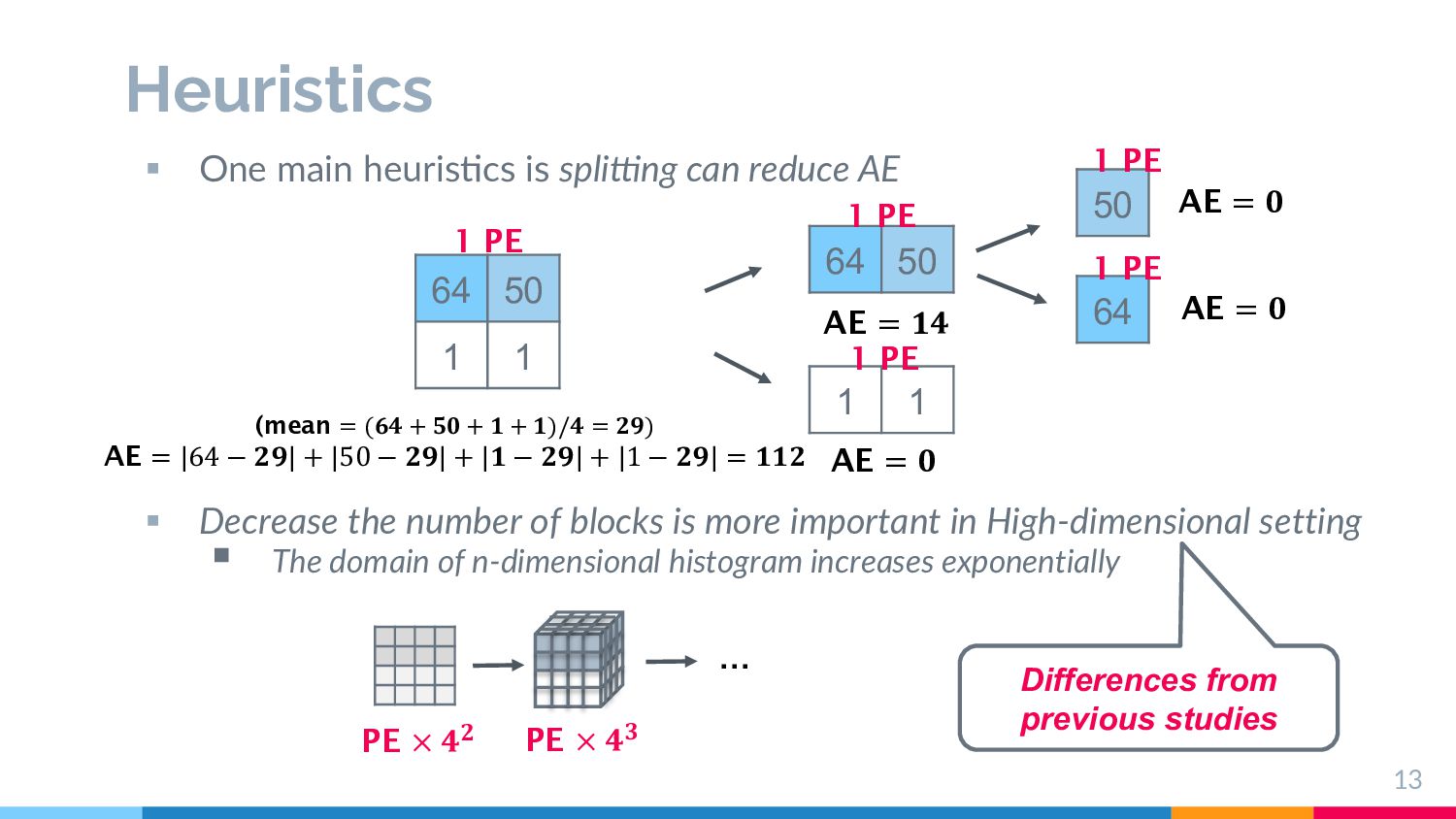
for efficient and fine partitioning Quadtree-based recursive splitting until count is small enough Split in fixed way 2 1 1 3 3 1 1 Too fine-grained in High dimension → Too large PE (3) and space- inefficient (4) Problem More careful splitting strategy is necessary Stop Stop Stop Stop Stop Stop Stop if count is small enough
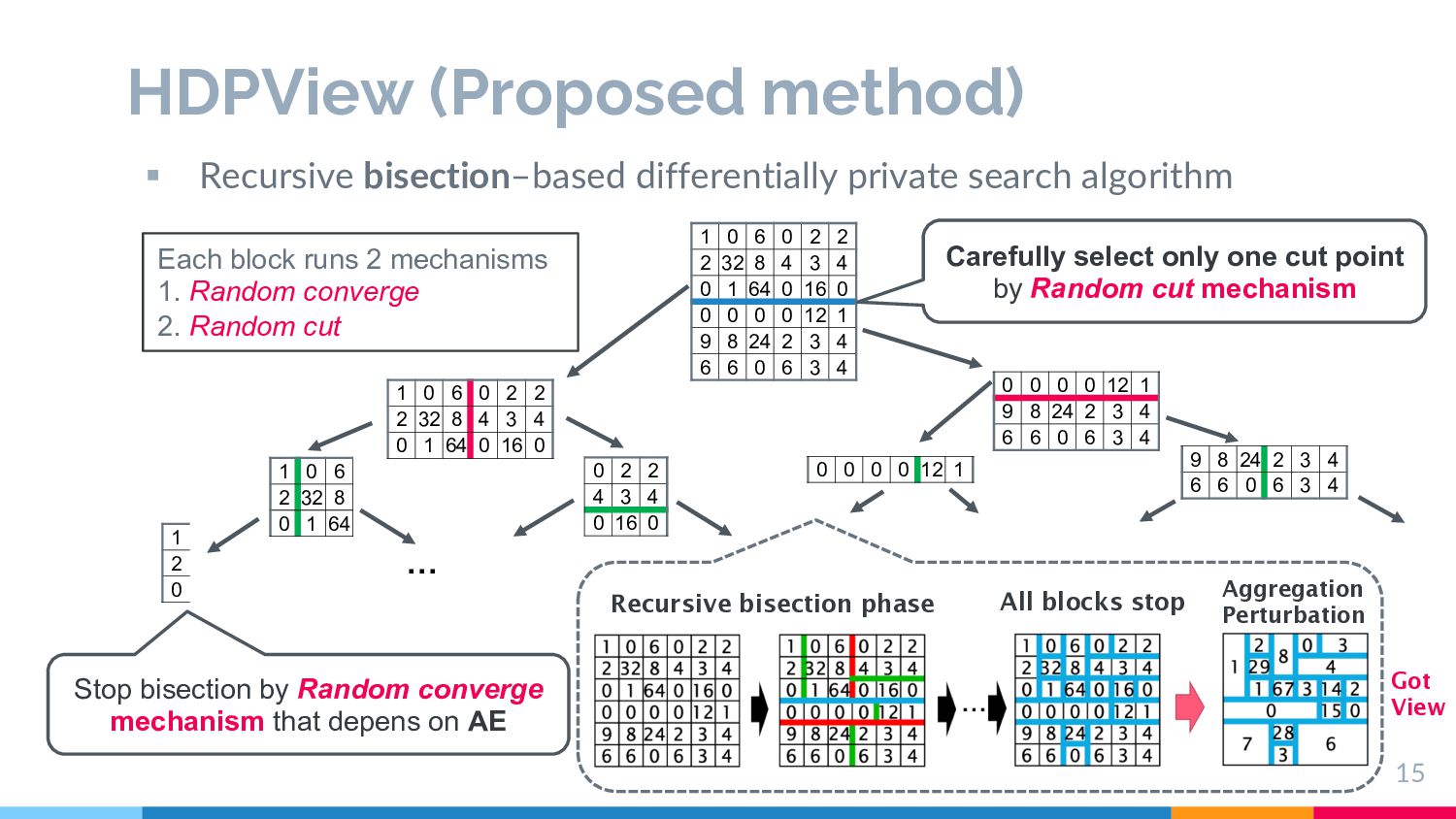
converge § We analyze a DP guarantee on the final view and an approximated error for the any queries on the view. (see our paper in detail) Only one cut point ! is probabilistically selected from all possible points using exponential mechanism Smaller total AE after bisection is more likely to be sampled Stop if Laplace noised AE of block Β is small enough #/%& is stddev of noise. If AE < #/%& , AE+PE will worsen by any bisection. if then, stop the recursive bisection Effective split for small AE Save unnecessary split req.2 DP
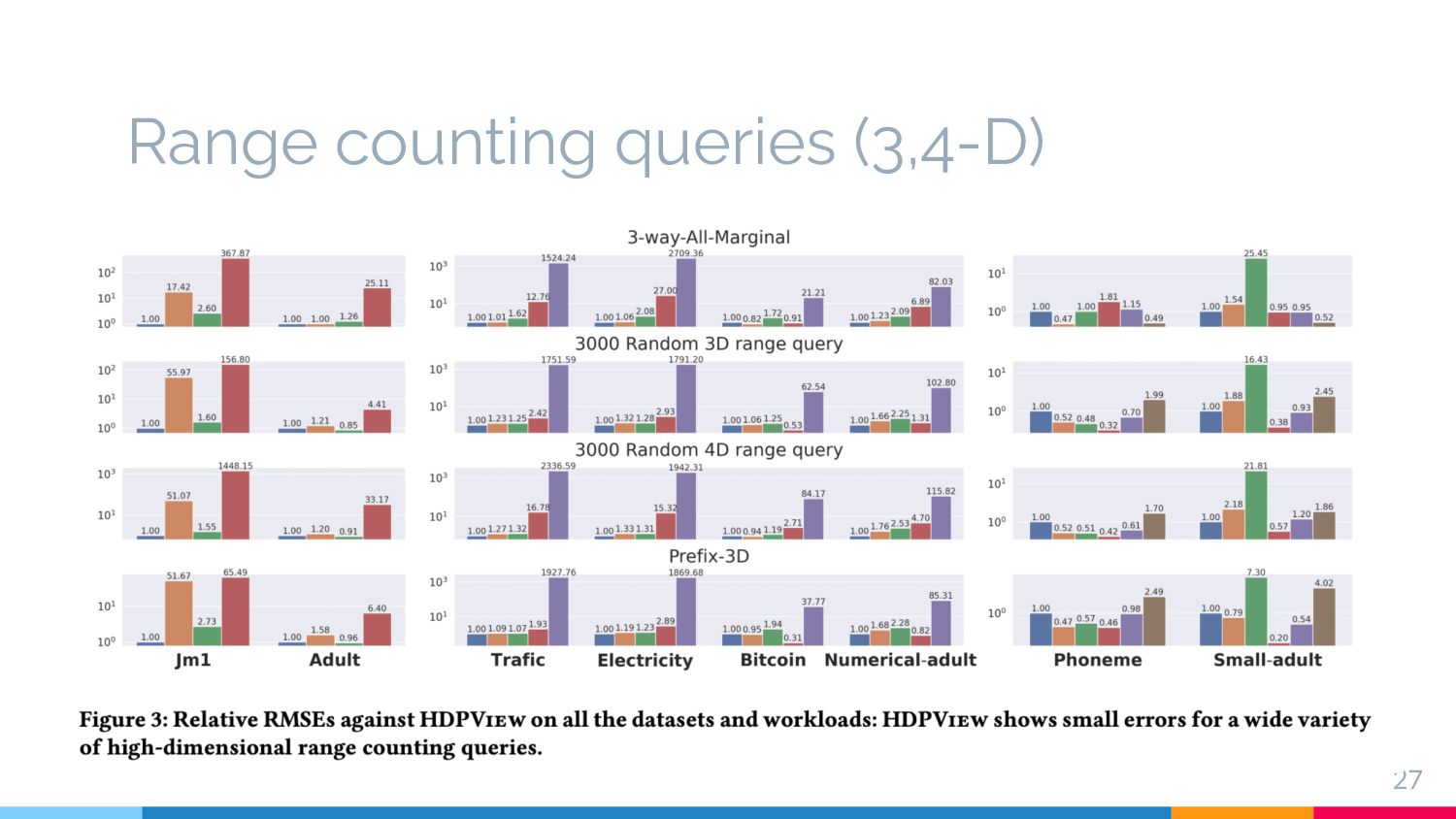
to explore the high-dimensional sensitive dataset? § We propose HDPView, which create a high-dimensional differentially private view by properly balancing AE and PE for high-dimensional data § The experiments show HDPView’s noise resistance and space-efficiency compared to existing works Conclusion
Algorithm ! provides "-Differential Privacy if for neighboring databases # and #′ (differ by only one record) satisfies: 23 Pr ! # Pr ! #′ ≤ exp(") Differential Privacy (DP) Privacy parameter We can analyze the output distribution over multiple algorithms in composable way (Composition Theorem)
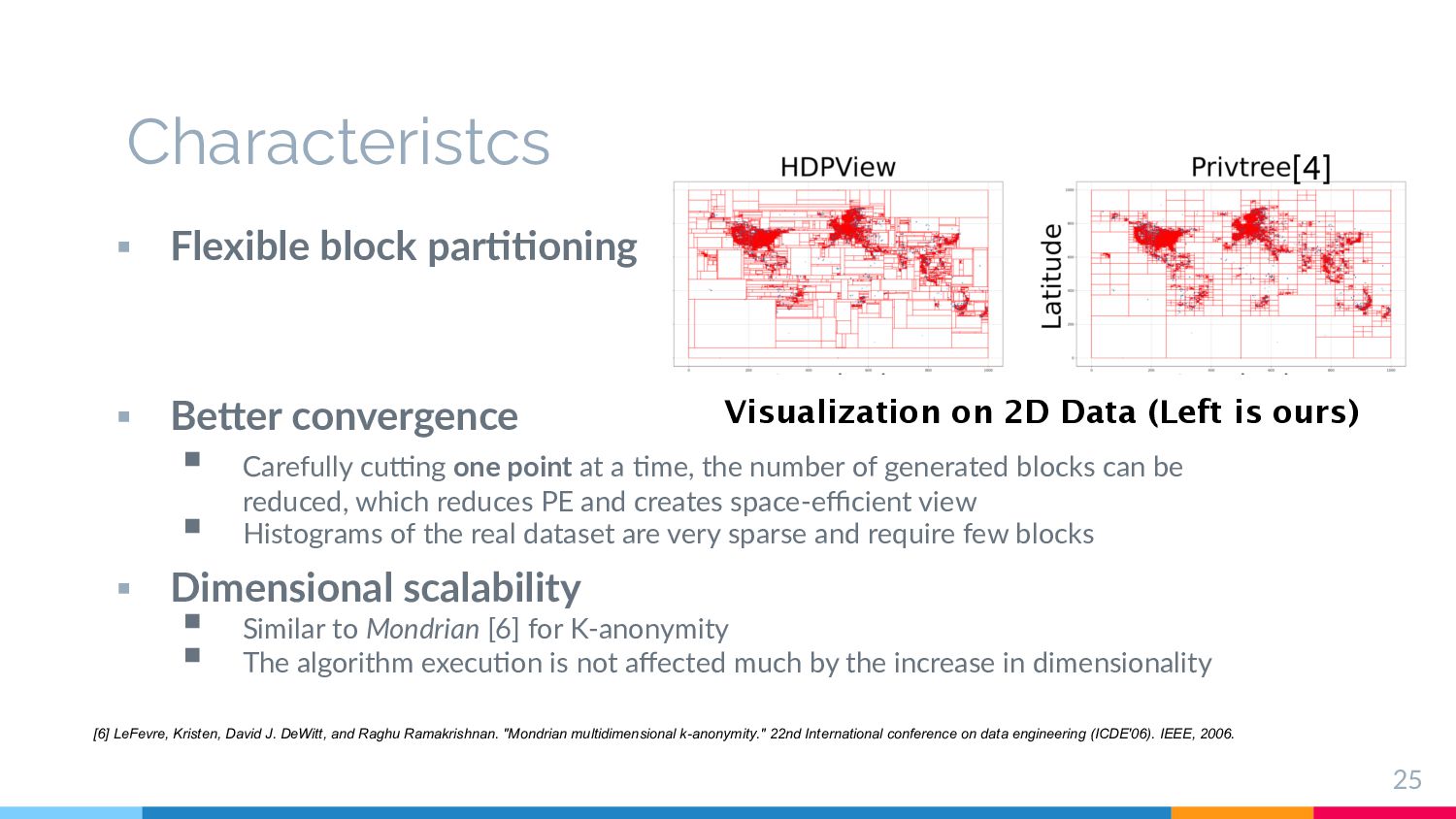
Carefully cu-ng one point at a 1me, the number of generated blocks can be reduced, which reduces PE and creates space-efficient view § Histograms of the real dataset are very sparse and require few blocks § Dimensional scalability § Similar to Mondrian [6] for K-anonymity § The algorithm execu1on is not affected much by the increase in dimensionality Visualization on 2D Data (Left is ours) [6] LeFevre, Kristen, David J. DeWitt, and Raghu Ramakrishnan. "Mondrian multidimensional k-anonymity." 22nd International conference on data engineering (ICDE'06). IEEE, 2006. [4]
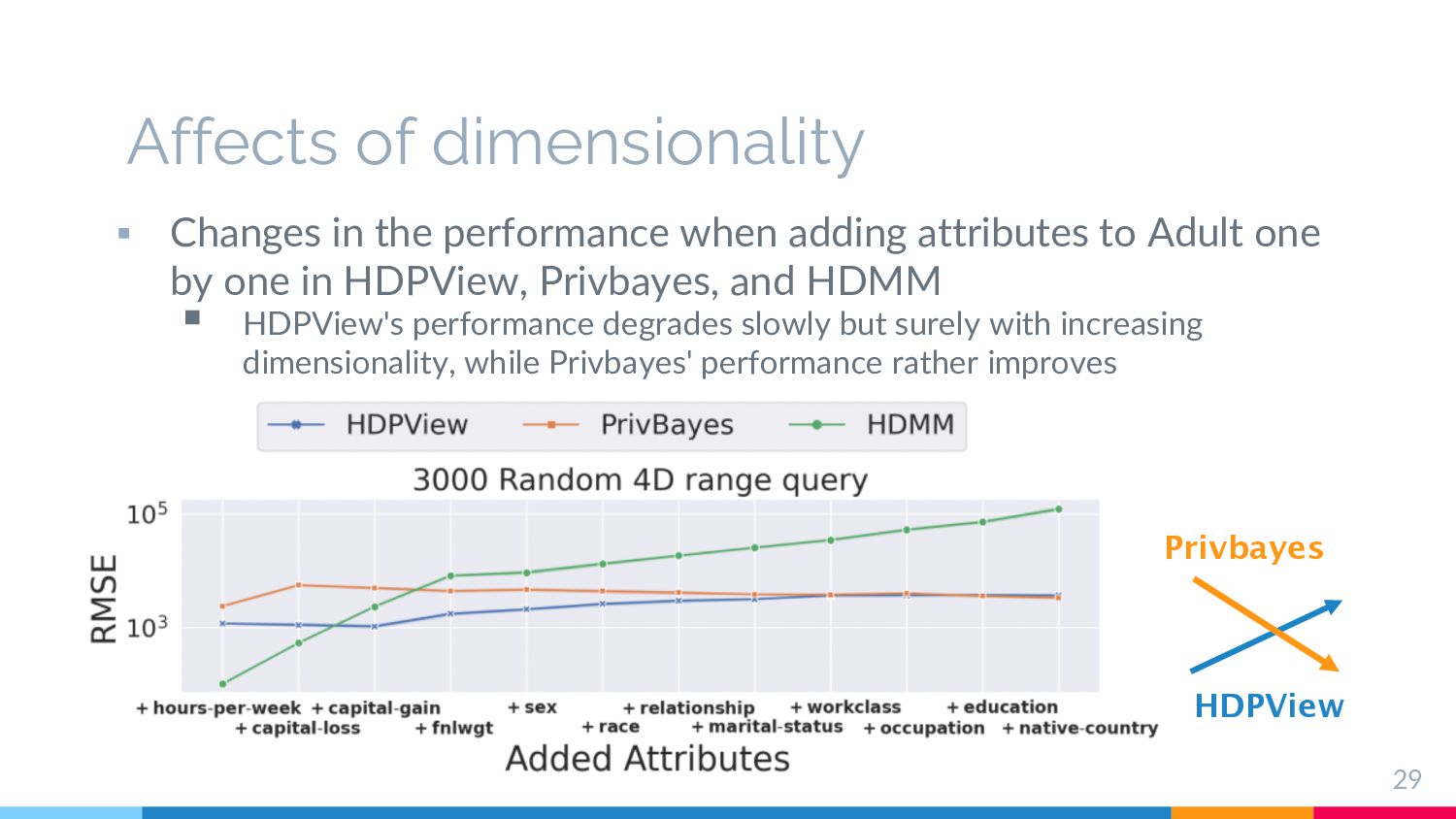
one by one in HDPView, Privbayes, and HDMM § HDPView's performance degrades slowly but surely with increasing dimensionality, while Privbayes' performance rather improves Affects of dimensionality 29 Privbayes HDPView
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![14 Existing Approach: Privtree [4] § Recursive splitting by Quadtree](https://files.speakerdeck.com/presentations/6a128250dd0f4ba59d7c4ae00abe5c24/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Contribution 24 HDMM [1] Privbayes [2], DP-GAN [3] Identity Privtree](https://files.speakerdeck.com/presentations/6a128250dd0f4ba59d7c4ae00abe5c24/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}