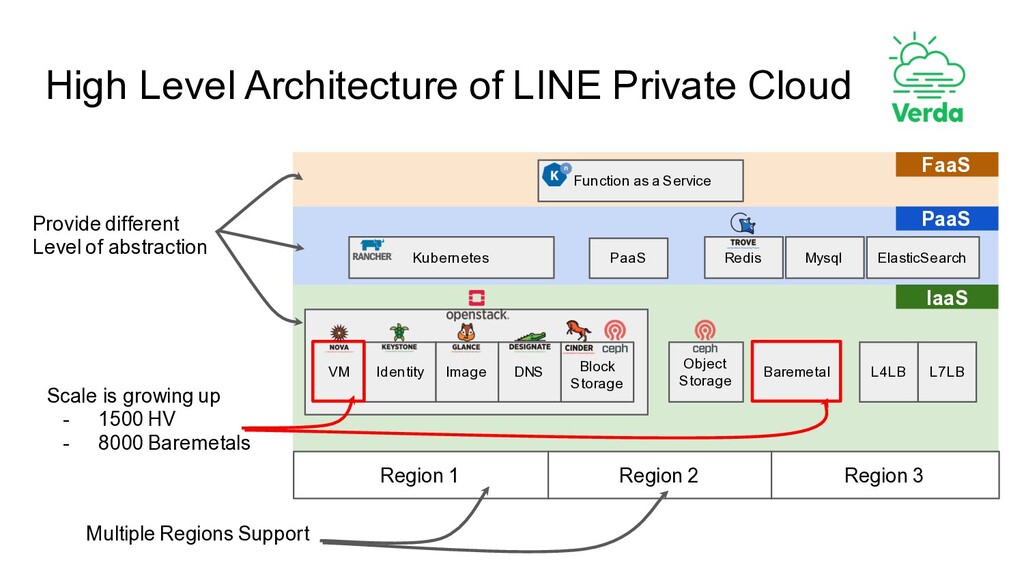
Region 2 Region 3 Identity Image DNS L4LB L7LB Block Storage Baremetal Object Storage Kubernetes VM Redis Mysql PaaS ElasticSearch FaaS Function as a Service Multiple Regions Support Scale is growing up - 1500 HV - 8000 Baremetals Provide different Level of abstraction PaaS
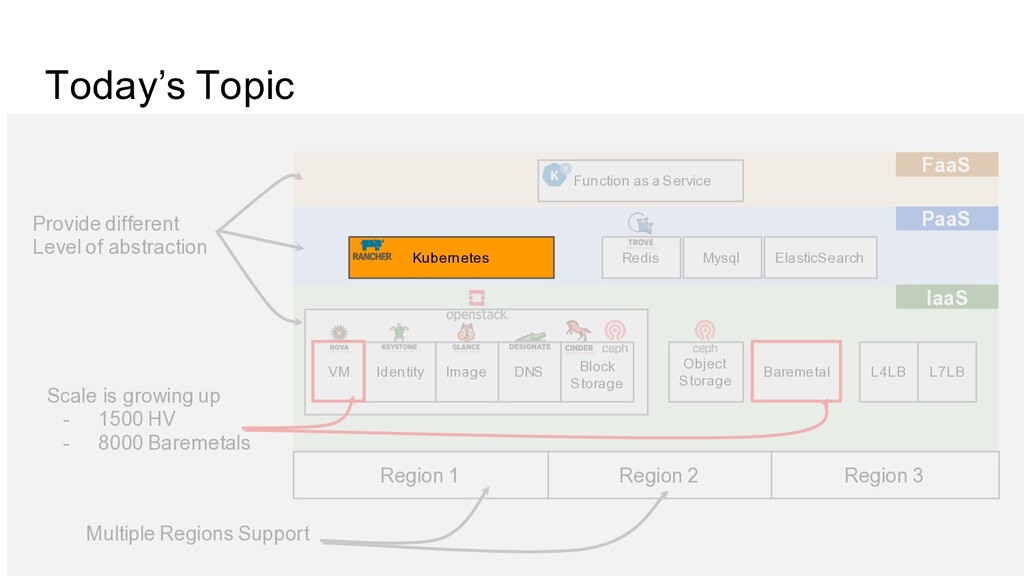
Image DNS L4LB L7LB Block Storage Baremetal Object Storage VM Redis Mysql PaaS ElasticSearch FaaS Function as a Service Multiple Regions Support Scale is growing up - 1500 HV - 8000 Baremetals Provide different Level of abstraction Kubernetes
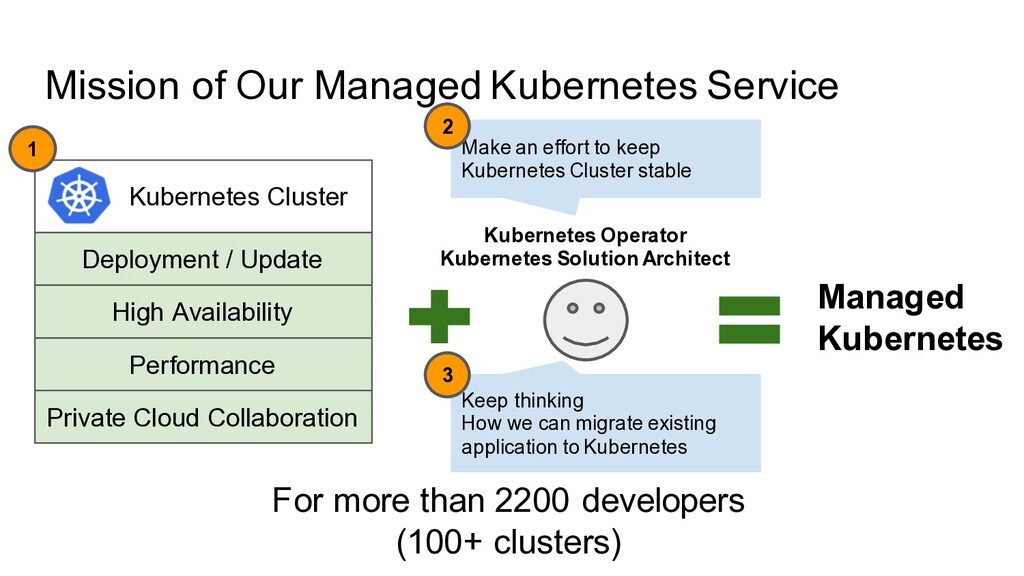
Kubernetes Mission of Our Managed Kubernetes Service For more than 2200 developers (100+ clusters) Kubernetes Operator Kubernetes Solution Architect High Availability Make an effort to keep Kubernetes Cluster stable Keep thinking How we can migrate existing application to Kubernetes 1 2 3
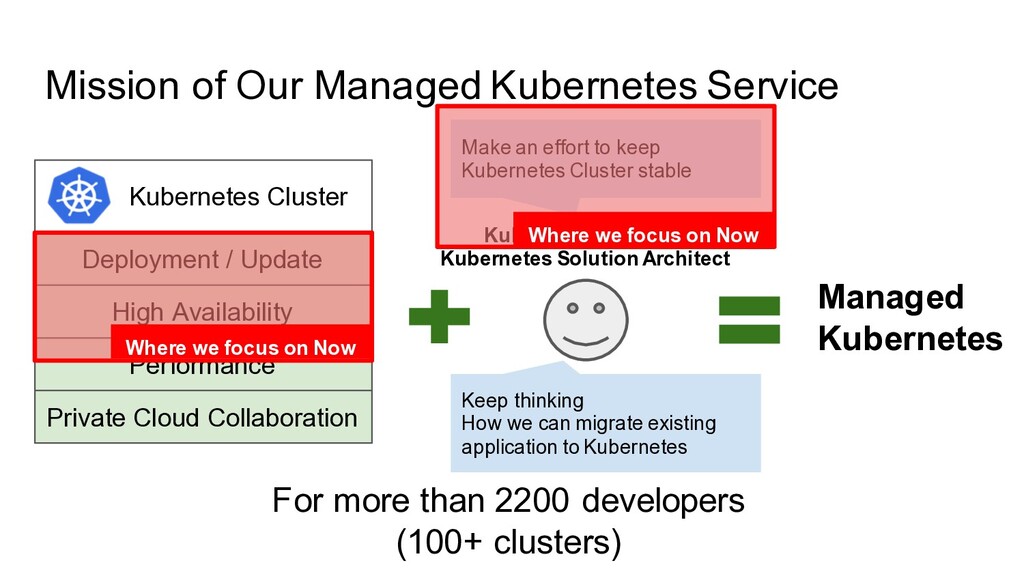
Kubernetes Mission of Our Managed Kubernetes Service For more than 2200 developers (100+ clusters) Kubernetes Operator Kubernetes Solution Architect High Availability Make an effort to keep Kubernetes Cluster stable Keep thinking How we can migrate existing application to Kubernetes Where we focus on Now Where we focus on Now
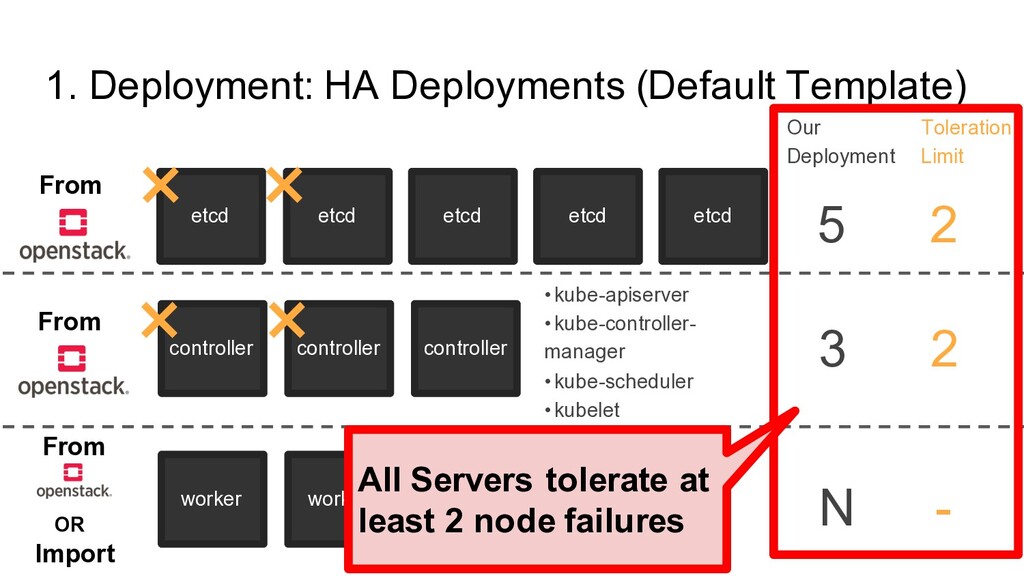
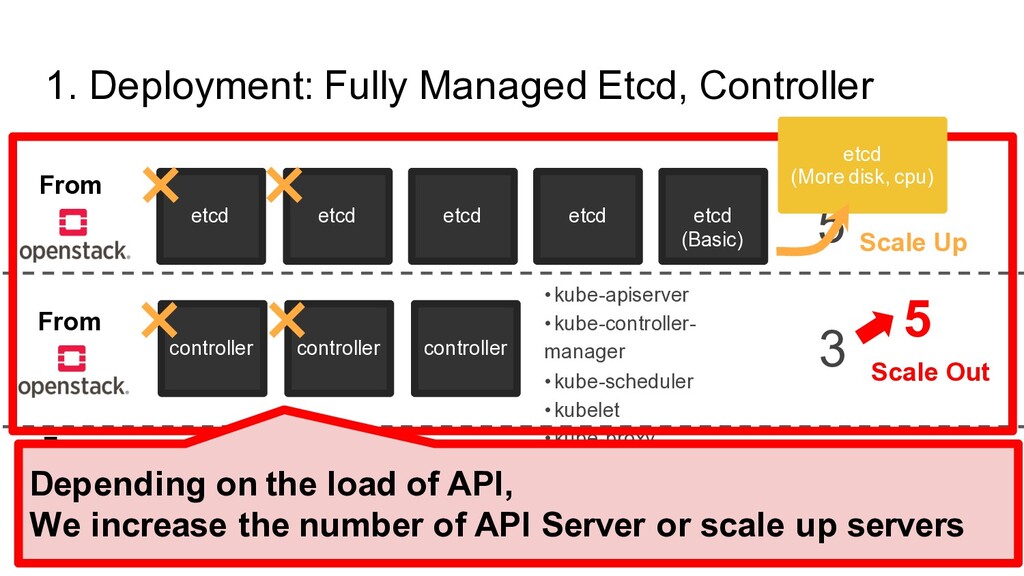
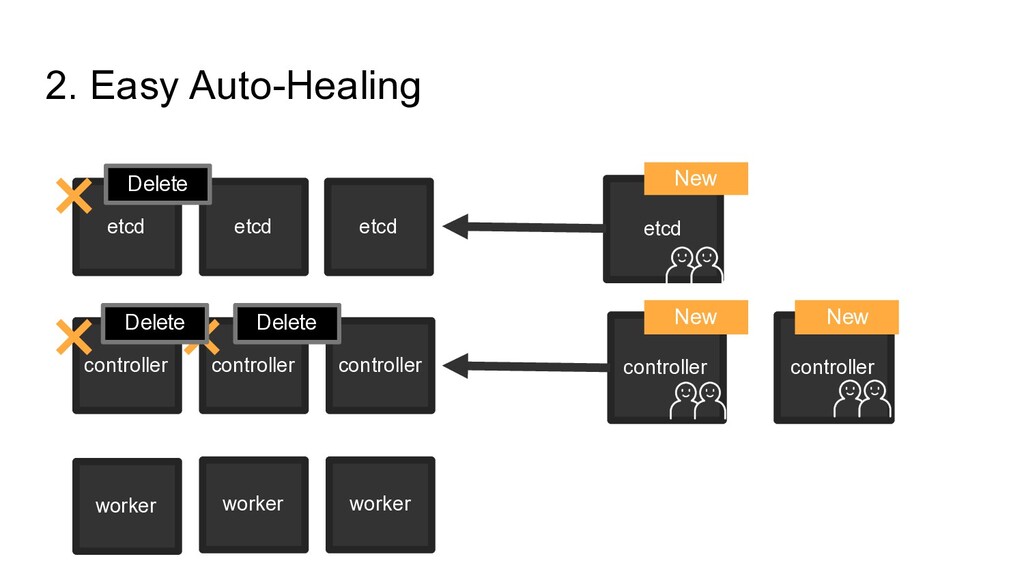
etcd (Basic) etcd controller controller controller 3 • kube-apiserver • kube-controller- manager • kube-scheduler • kubelet • kube-proxy × × × worker worker worker N • kubelet • kube-proxy - Our Deployment × From From From OR Import Depending on the load of API, We increase the number of API Server or scale up servers 5 etcd (More disk, cpu) Scale Out Scale Up
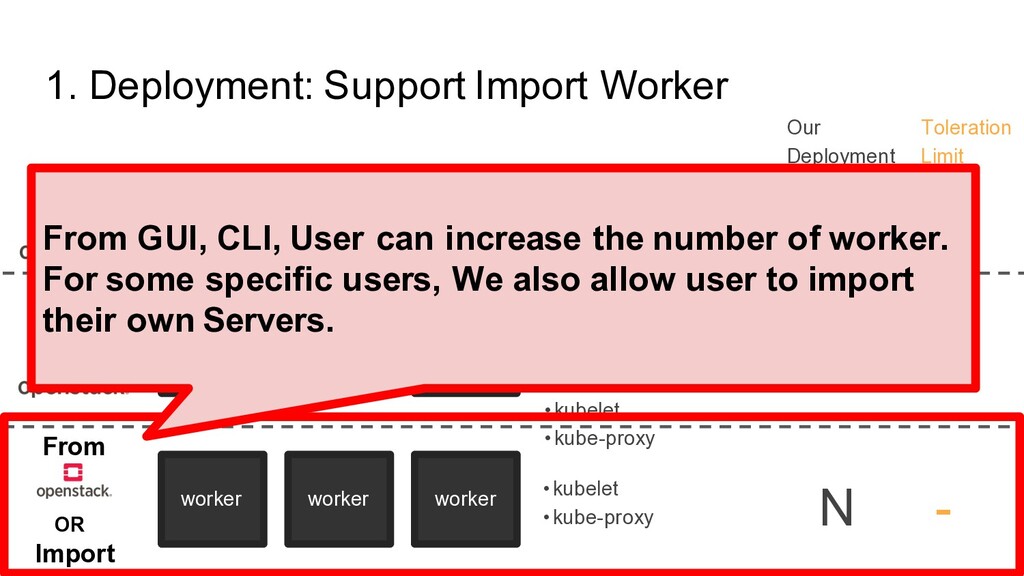
etcd etcd controller controller controller 3 • kube-apiserver • kube-controller- manager • kube-scheduler • kubelet • kube-proxy × × × 2 worker worker worker N • kubelet • kube-proxy - Toleration Limit Our Deployment × From From From OR Import From GUI, CLI, User can increase the number of worker. For some specific users, We also allow user to import their own Servers.
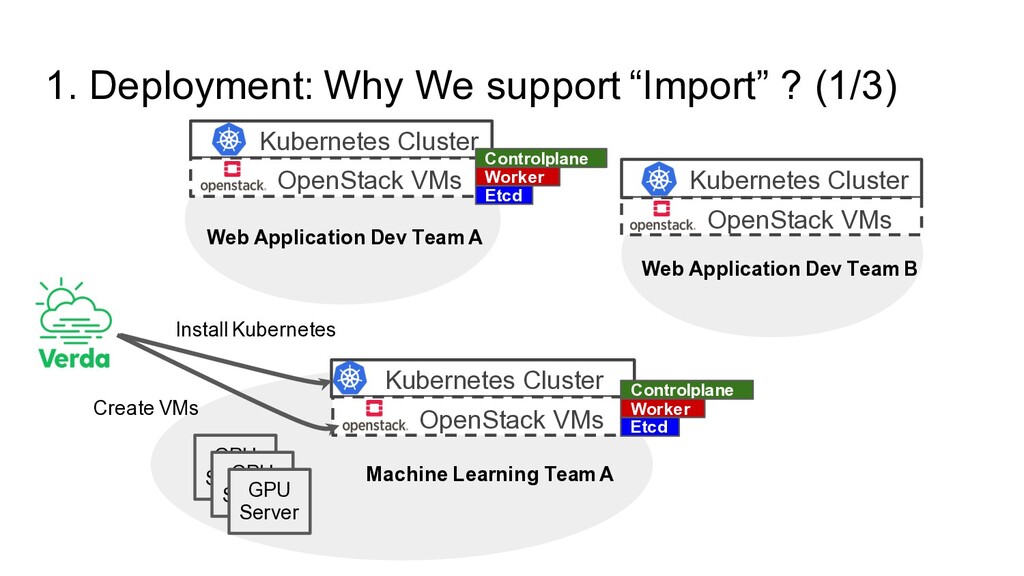
Dev Team A Machine Learning Team A Web Application Dev Team B Kubernetes Cluster OpenStack VMs Kubernetes Cluster OpenStack VMs Kubernetes Cluster OpenStack VMs Etcd Controlplane Etcd Controlplane Worker GPU Server GPU Server GPU Server Worker Web Application Dev Team A Create VMs Install Kubernetes
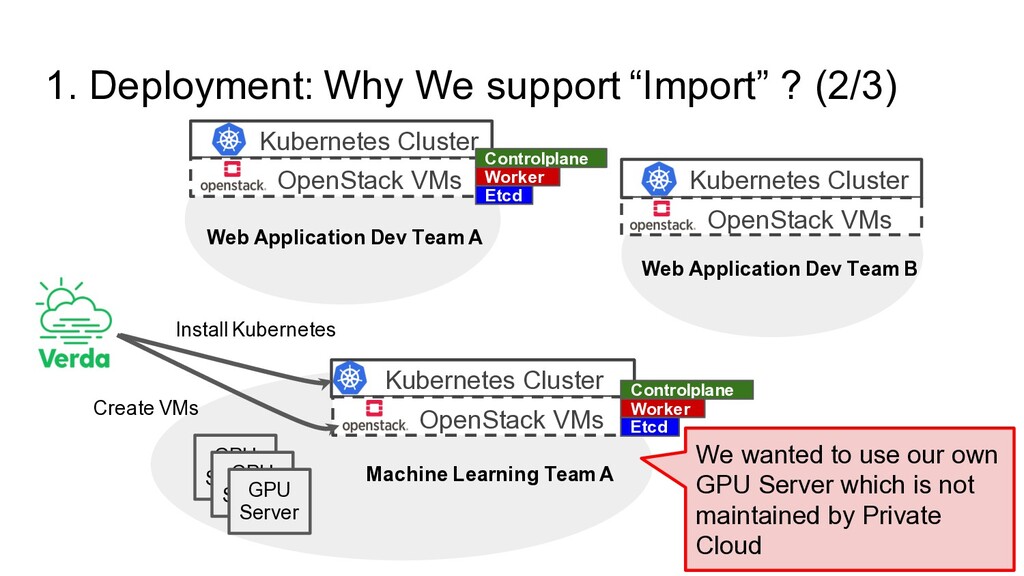
Dev Team A Machine Learning Team A Web Application Dev Team B Kubernetes Cluster OpenStack VMs Kubernetes Cluster OpenStack VMs Kubernetes Cluster OpenStack VMs Etcd Controlplane Etcd Controlplane Worker GPU Server GPU Server GPU Server Worker Web Application Dev Team A We wanted to use our own GPU Server which is not maintained by Private Cloud Create VMs Install Kubernetes
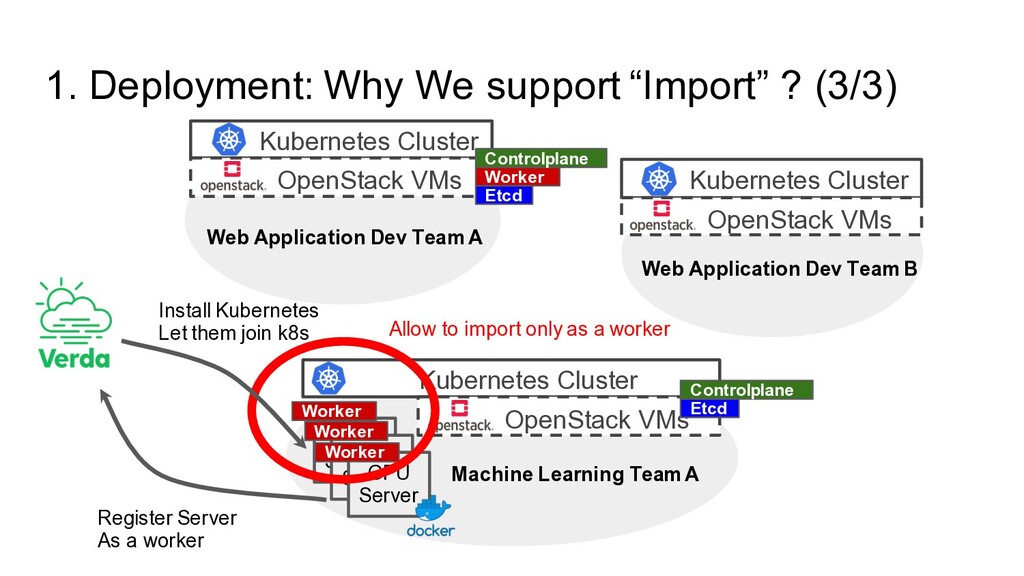
Dev Team A Machine Learning Team A Web Application Dev Team B Kubernetes Cluster OpenStack VMs Kubernetes Cluster OpenStack VMs Kubernetes Cluster OpenStack VMs GPU Server GPU Server GPU Server Worker Worker Worker Etcd Controlplane Etcd Worker Allow to import only as a worker Controlplane Register Server As a worker Install Kubernetes Let them join k8s
is encapsulation overhead, We’ve chosen simple implementation for easy operation. NetworkPolicy: Each Project will have their own Kubernetes Cluster, that’s why we don’t provide Network Security Etcd OpenStack VMs (At default: 5 Nodes) To make it easy to scale up, replace the node, We use OpenStack VMs. This is fully managed by Private Cloud Operator Controller OpenStack VMs (At default: 5 Nodes) To make it easy to scale up, scale out, replace the node, We use OpenStack VMs. This is fully managed by Private Cloud Operator Workers OpenStack VMs or Import (At default: 3 Nodes) OpenStack VMs: Scale Out is required to perform by End- User but Healing, Replacement is done by Operator Import Servers: required to be managed by End-User
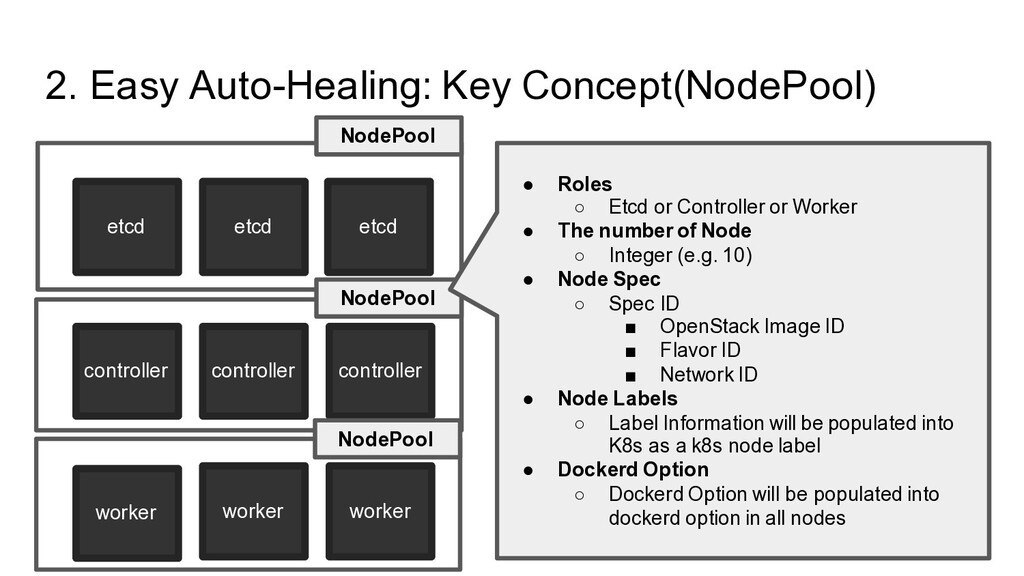
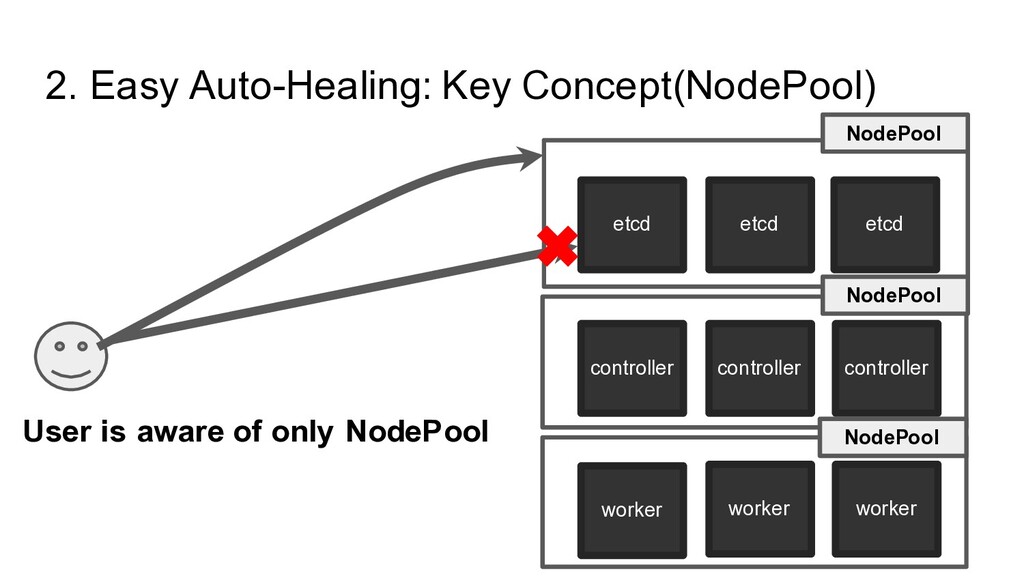
controller worker worker worker NodePool NodePool NodePool • Roles ◦ Etcd or Controller or Worker • The number of Node ◦ Integer (e.g. 10) • Node Spec ◦ Spec ID ▪ OpenStack Image ID ▪ Flavor ID ▪ Network ID • Node Labels ◦ Label Information will be populated into K8s as a k8s node label • Dockerd Option ◦ Dockerd Option will be populated into dockerd option in all nodes
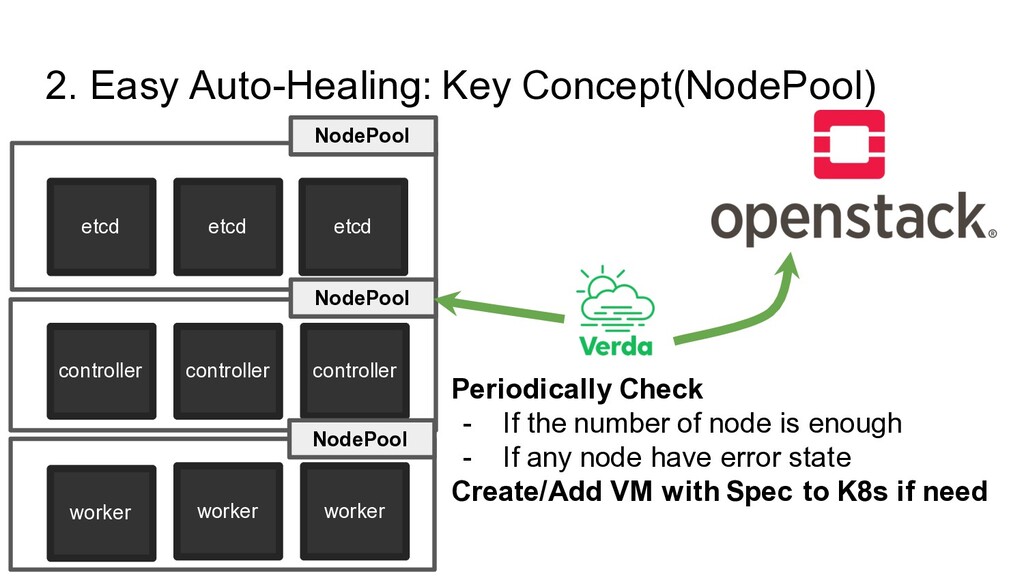
controller worker worker worker NodePool NodePool NodePool Periodically Check - If the number of node is enough - If any node have error state Create/Add VM with Spec to K8s if need
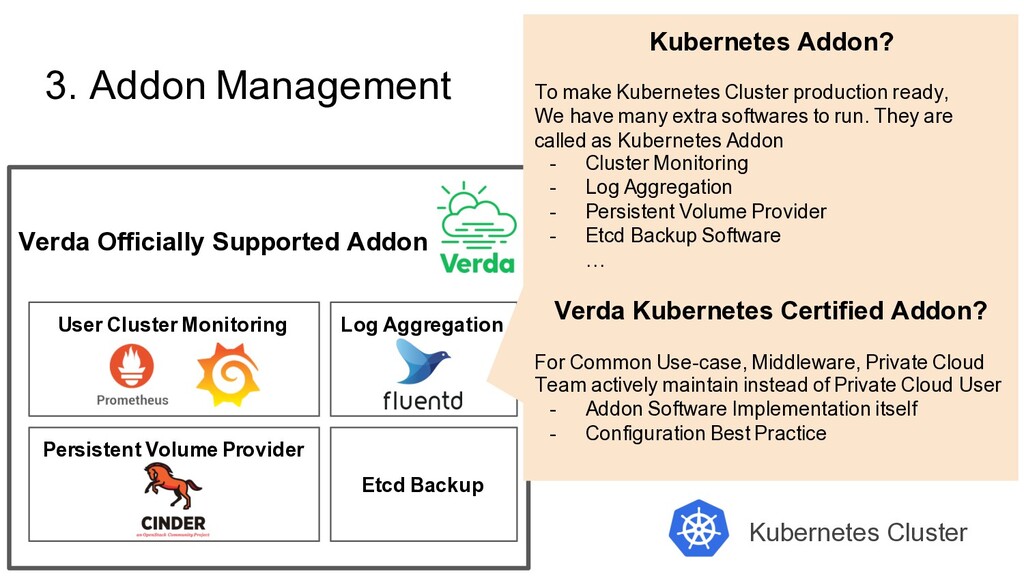
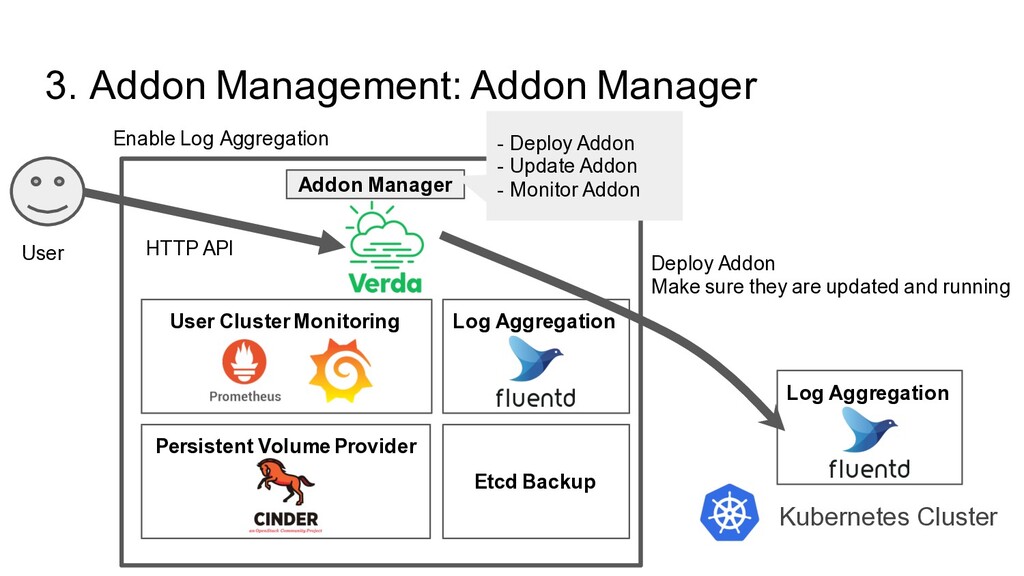
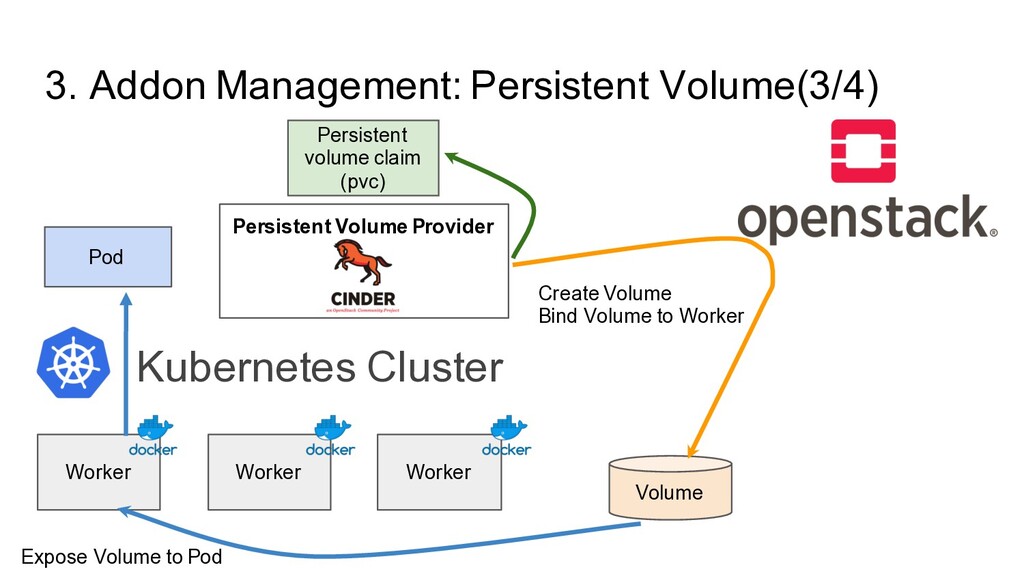
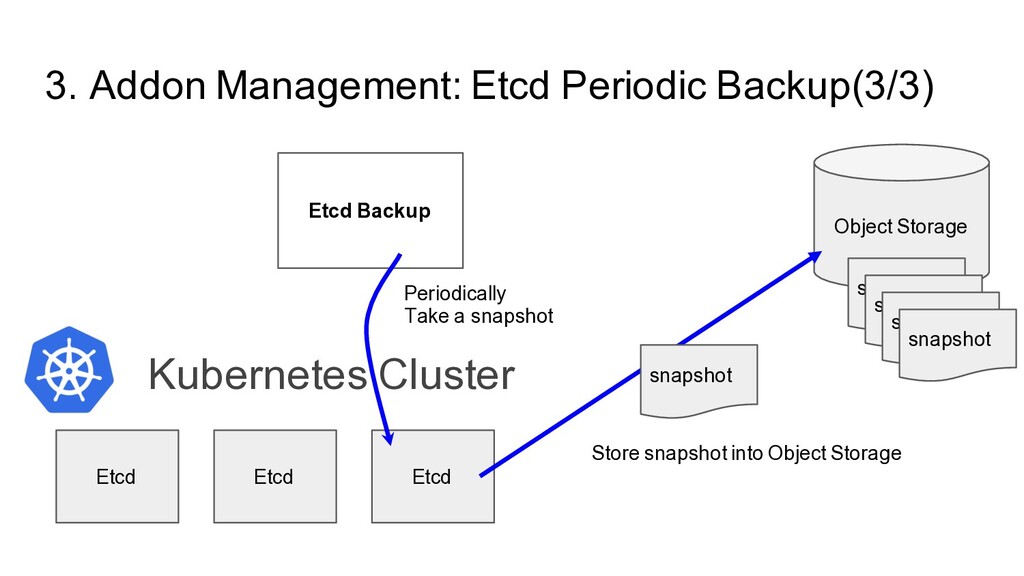
Etcd Backup Persistent Volume Provider Verda Officially Supported Addon Kubernetes Addon? To make Kubernetes Cluster production ready, We have many extra softwares to run. They are called as Kubernetes Addon - Cluster Monitoring - Log Aggregation - Persistent Volume Provider - Etcd Backup Software … Verda Kubernetes Certified Addon? For Common Use-case, Middleware, Private Cloud Team actively maintain instead of Private Cloud User - Addon Software Implementation itself - Configuration Best Practice
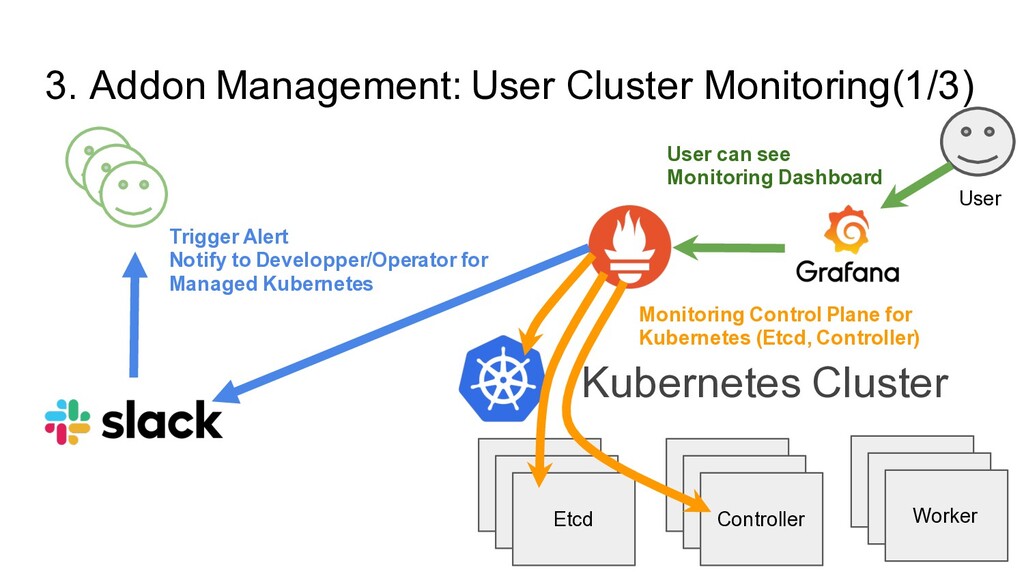
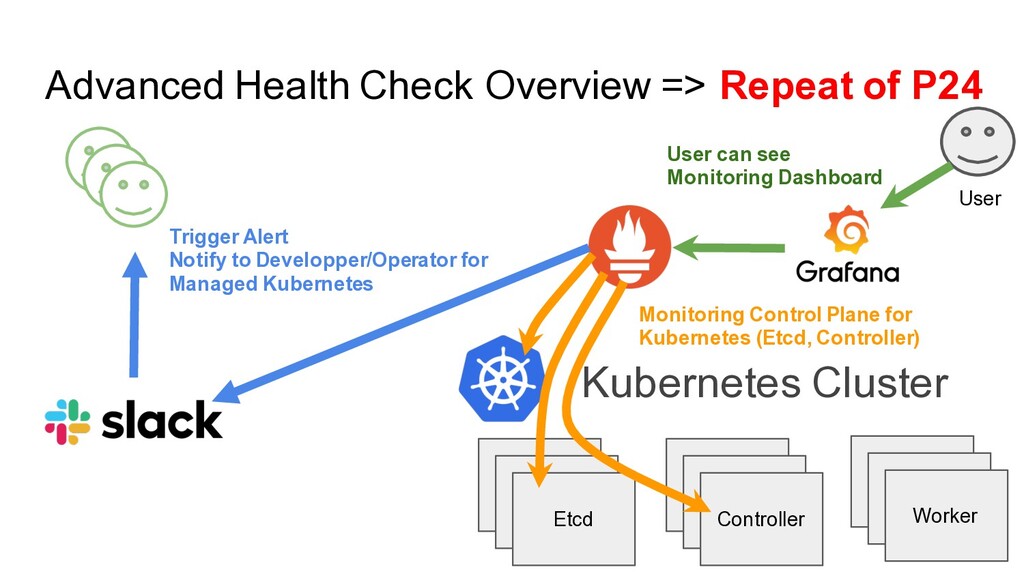
Etcd Etcd Etcd Controller Etcd Etcd Worker User User can see Monitoring Dashboard Monitoring Control Plane for Kubernetes (Etcd, Controller) Trigger Alert Notify to Developper/Operator for Managed Kubernetes
What • Simple stateless API Server Responsibility in our Managed Kubernetes • Provide interface of Managed Kubernetes Service for User ◦ This is only place for User Interface Why • Don’t expose Rancher API/GUI directly to User ◦ Avoid strongly depending on Rancher ◦ Restrict few Rancher Functionality • Easy to add extra business logic API
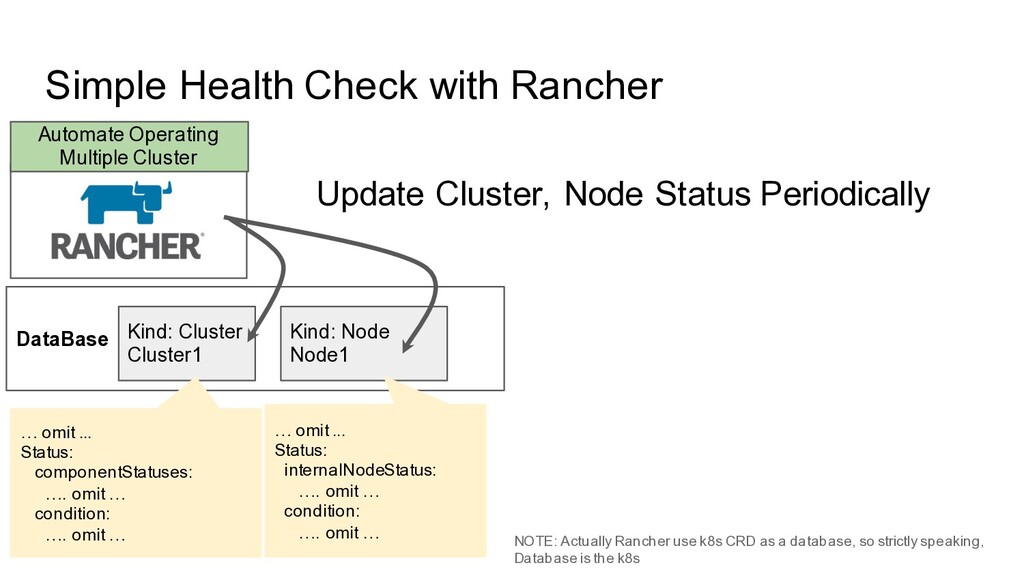
tools which is developed by Rancher Lab • Implemented based on Kubernetes (Use CRD, client-go heavily) • Provide multiple clusters management functionality Responsibility in our Managed Kubernetes • Provision • Update • Keep Kubernetes Cluster Available/Healthy ◦ Monitoring ◦ Healing
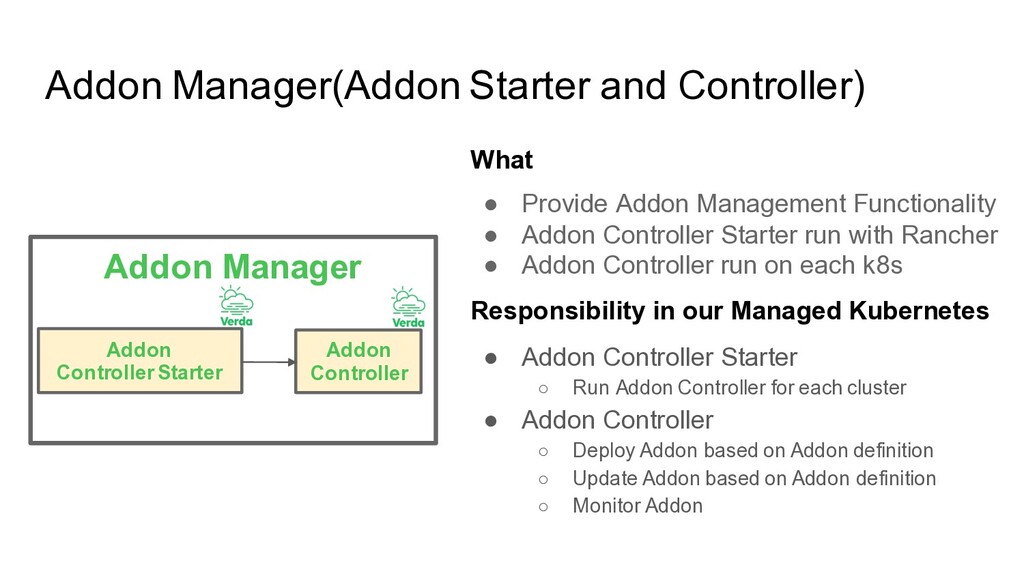
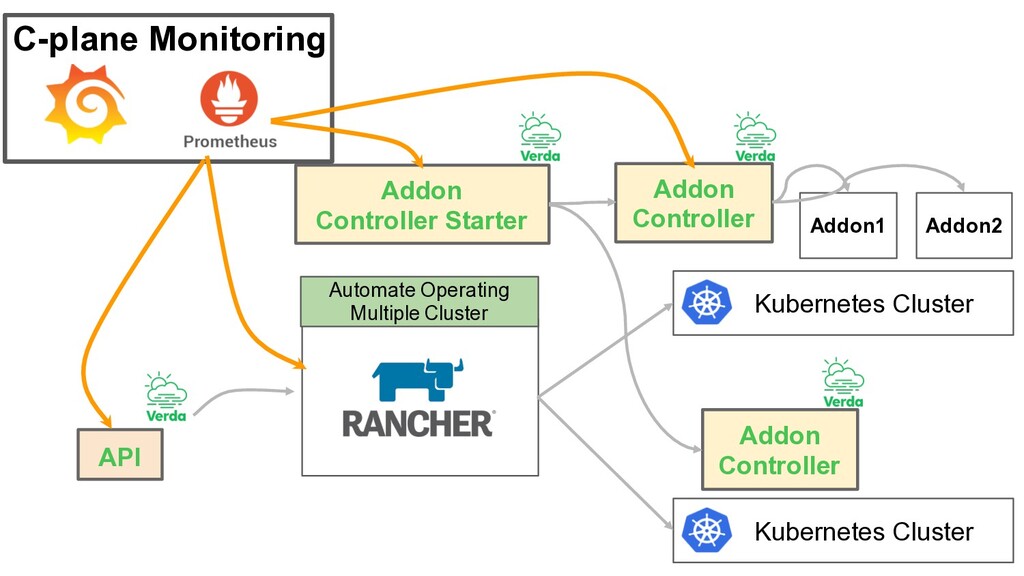
Functionality • Addon Controller Starter run with Rancher • Addon Controller run on each k8s Responsibility in our Managed Kubernetes • Addon Controller Starter ◦ Run Addon Controller for each cluster • Addon Controller ◦ Deploy Addon based on Addon definition ◦ Update Addon based on Addon definition ◦ Monitor Addon Addon Manager Addon Controller Addon Controller Starter
got broken? When entire cluster got down? When cluster need to update? When certificate to update? 1 API Call to replace Node with broken Node 1 API Call to restore etcd From snapshot 1 API Call to update k8s 1 API Call to rotate certificate Events
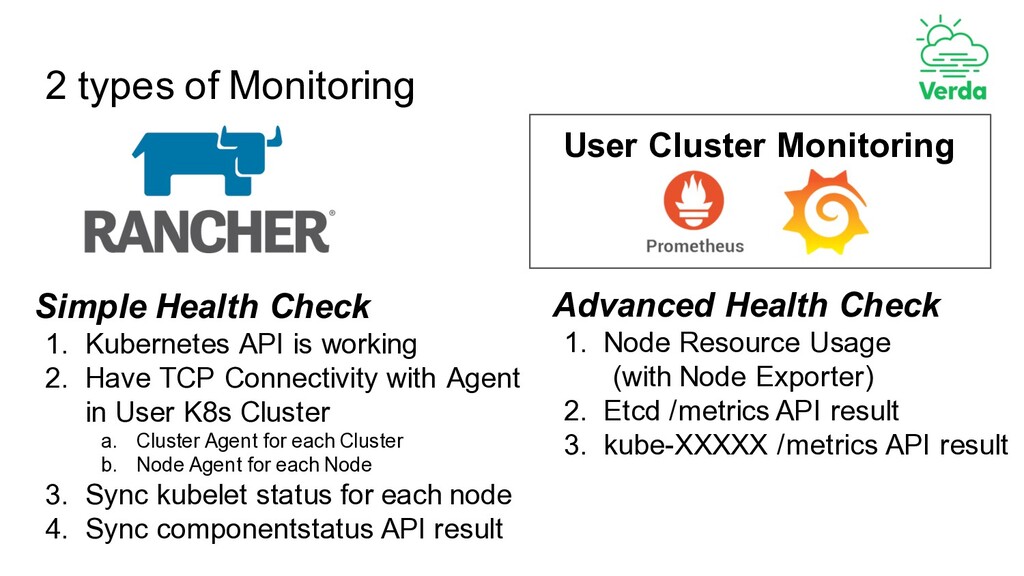
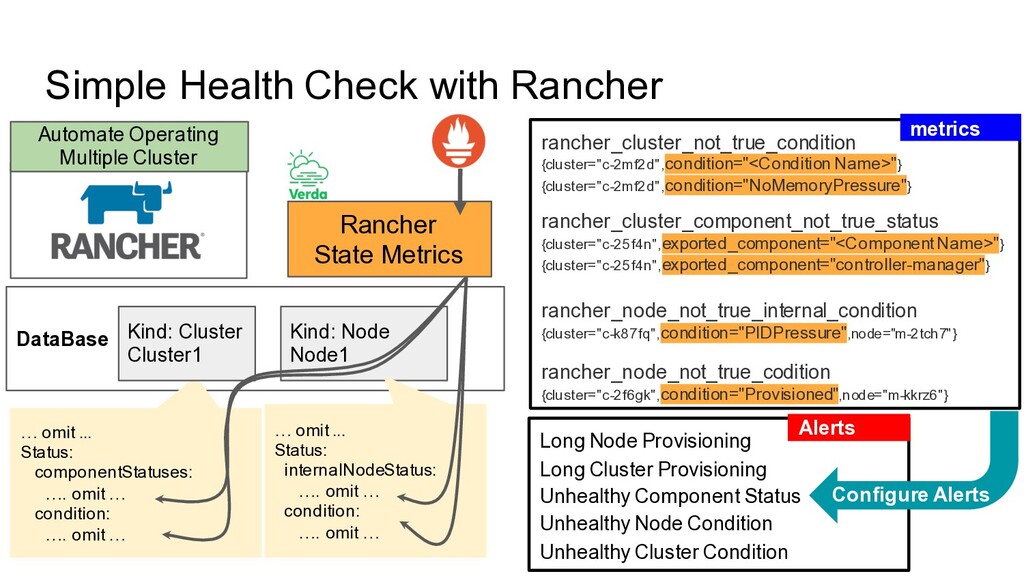
1. Kubernetes API is working 2. Have TCP Connectivity with Agent in User K8s Cluster a. Cluster Agent for each Cluster b. Node Agent for each Node 3. Sync kubelet status for each node 4. Sync componentstatus API result Advanced Health Check 1. Node Resource Usage (with Node Exporter) 2. Etcd /metrics API result 3. kube-XXXXX /metrics API result
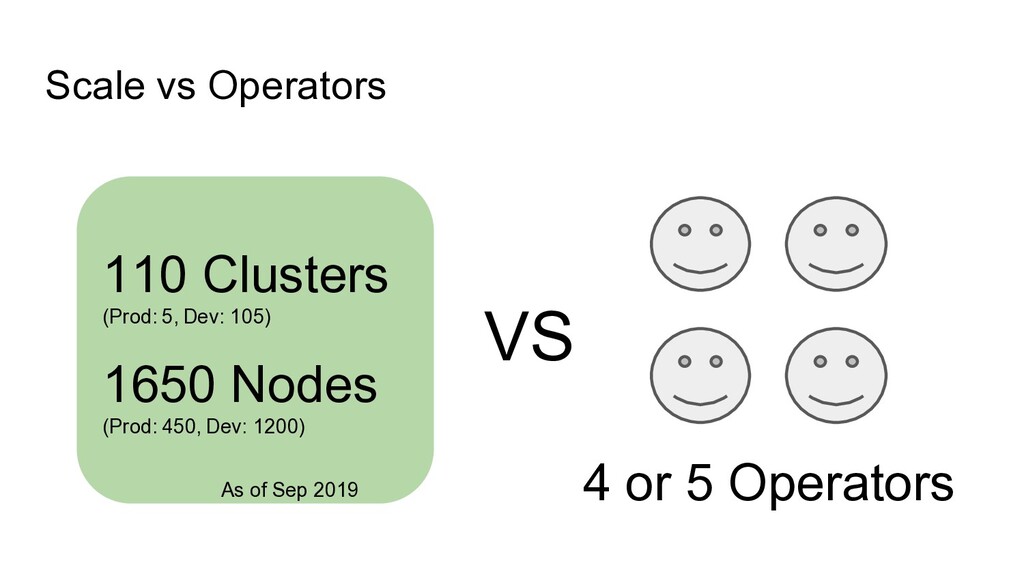
number of clusters are more than 90 Long Node Provisioning Long Cluster Provisioning Unhealthy Component Status Unhealthy Node Condition Unhealthy Cluster Condition We can notice each node, cluster’s status change
Etcd Etcd Etcd Etcd Etcd Controller Etcd Etcd Worker User User can see Monitoring Dashboard Monitoring Control Plane for Kubernetes (Etcd, Controller) Trigger Alert Notify to Developper/Operator for Managed Kubernetes
Controller Addon1 Addon2 Addon Controller Addon Controller Starter C-plane Monitoring Most Important It have many internal states to manage multiple k8s clusters
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}