Region 2 Region 3 Identity Image DNS L4LB L7LB Block Storage Baremetal Object Storage Kubernetes VM Redis Mysql PaaS ElasticSearch FaaS Function as a Service Multiple Regions Support Scale is growing up - 1500 HV - 8000 Baremetals Provide different Level of abstraction PaaS
Image DNS L4LB L7LB Block Storage Baremetal Object Storage VM Redis Mysql PaaS ElasticSearch FaaS Function as a Service Multiple Regions Support Scale is growing up - 1500 HV - 8000 Baremetals Provide different Level of abstraction Kubernetes
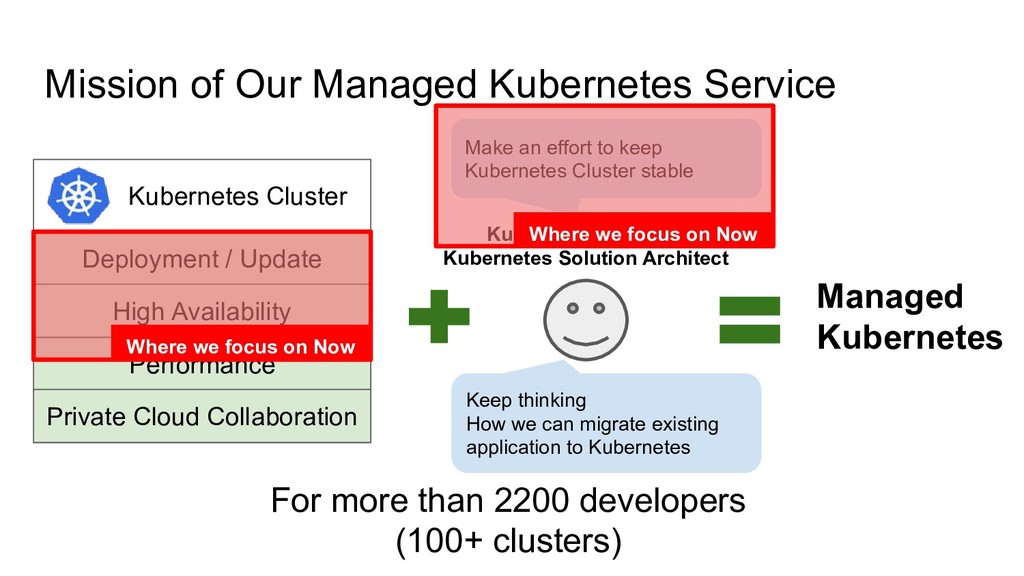
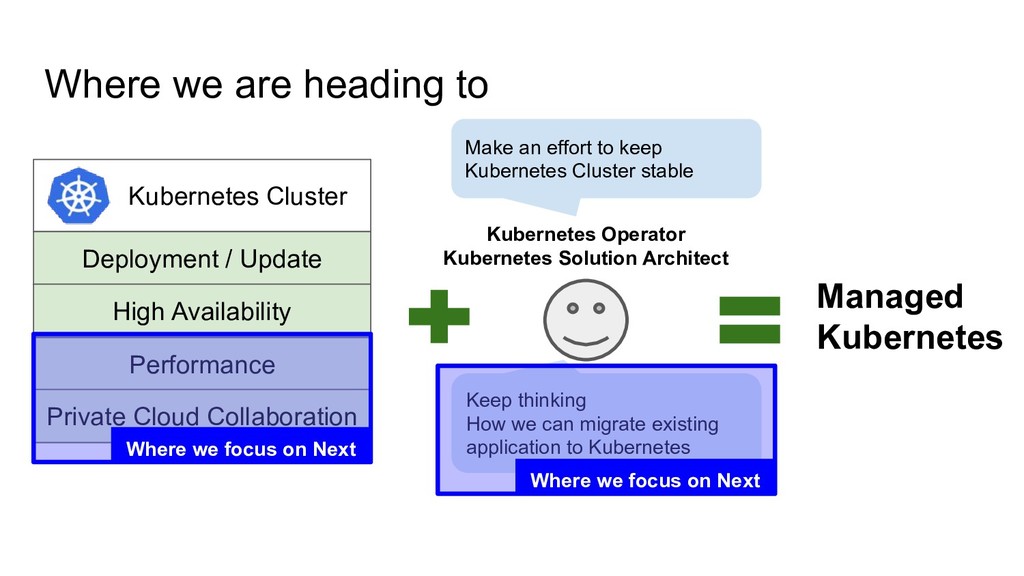
Kubernetes Mission of Our Managed Kubernetes Service For more than 2200 developers (100+ clusters) Kubernetes Operator Kubernetes Solution Architect High Availability Make an effort to keep Kubernetes Cluster stable Keep thinking How we can migrate existing application to Kubernetes
Kubernetes Mission of Our Managed Kubernetes Service For more than 2200 developers (100+ clusters) Kubernetes Operator Kubernetes Solution Architect High Availability Make an effort to keep Kubernetes Cluster stable Keep thinking How we can migrate existing application to Kubernetes Where we focus on Now Where we focus on Now
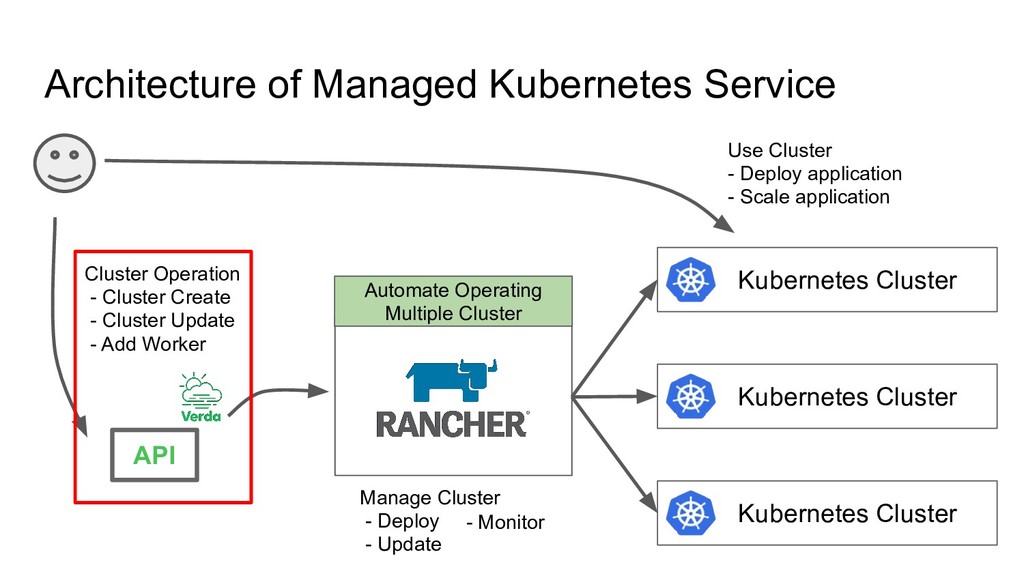
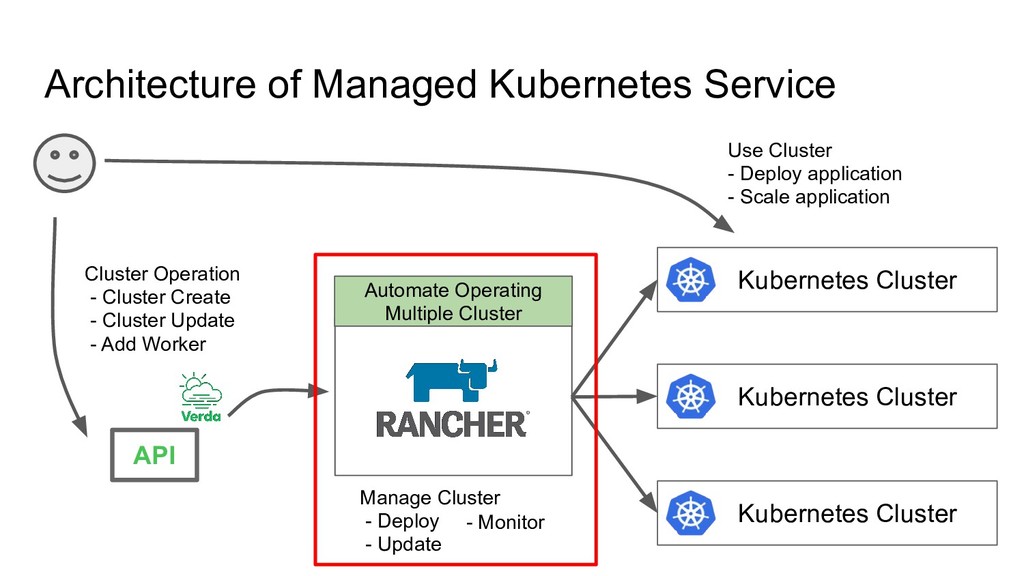
Responsibility 1. Hide Rancher API/GUI from User 2. Aggregate Rancher API e.g. 1 Cluster Create API will internally make following Rancher API Calls - POST /v3/clusters - POST /v3/nodepools (multiple times) 3. Support Multiple Rancher deployments Why 1. Avoid strongly depending on Rancher 2. By limiting features, fixing user cluster deployment, Reduce risk for user to configure/use in wrong way 3. As a last resort to scale, we can support multiple rancher deployments by putting extra API in front of them API
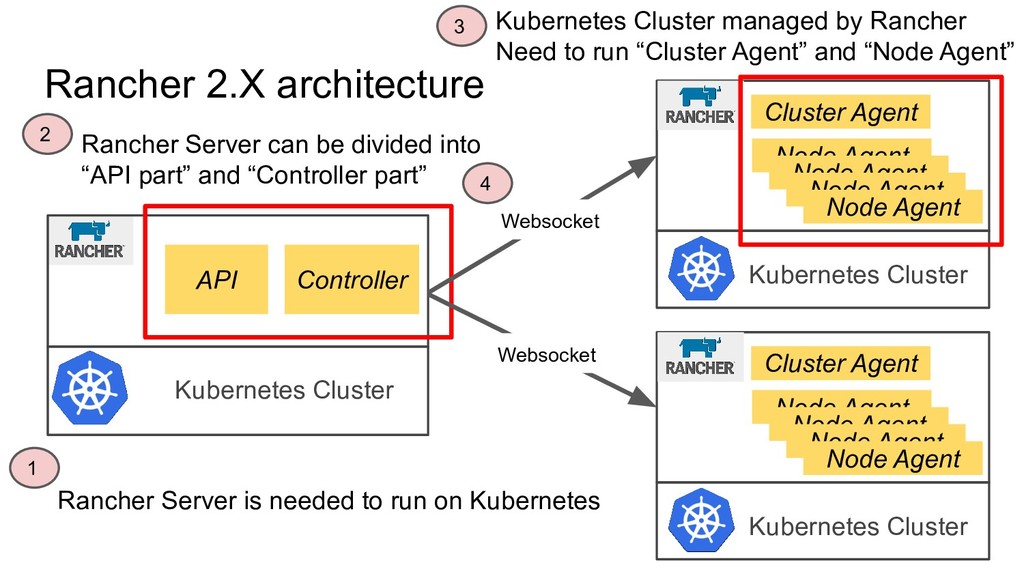
Agent Node Agent Node Agent Node Agent Node Agent Kubernetes Cluster Cluster Agent Node Agent Node Agent Node Agent Node Agent Rancher Server is needed to run on Kubernetes Rancher Server can be divided into “API part” and “Controller part” Kubernetes Cluster managed by Rancher Need to run “Cluster Agent” and “Node Agent” Websocket Websocket 1 2 3 4
CRD as a Data Store 2. Implement logic as a controller by using informer, workqueue from client-go 3. Use ConfigMap based leader election from client-go 4. Use endpoints resource for Rancher Server Discovery 5. Use Kubernetes rolebinding, role for API Authorization
CRD as a Data Store 2. Implement logic as a controller by using informer, workqueue from client-go 3. Use ConfigMap based leader election from client-go 4. Use endpoints resource for Rancher Server Discovery 5. Use Kubernetes rolebinding, role for API Authorization
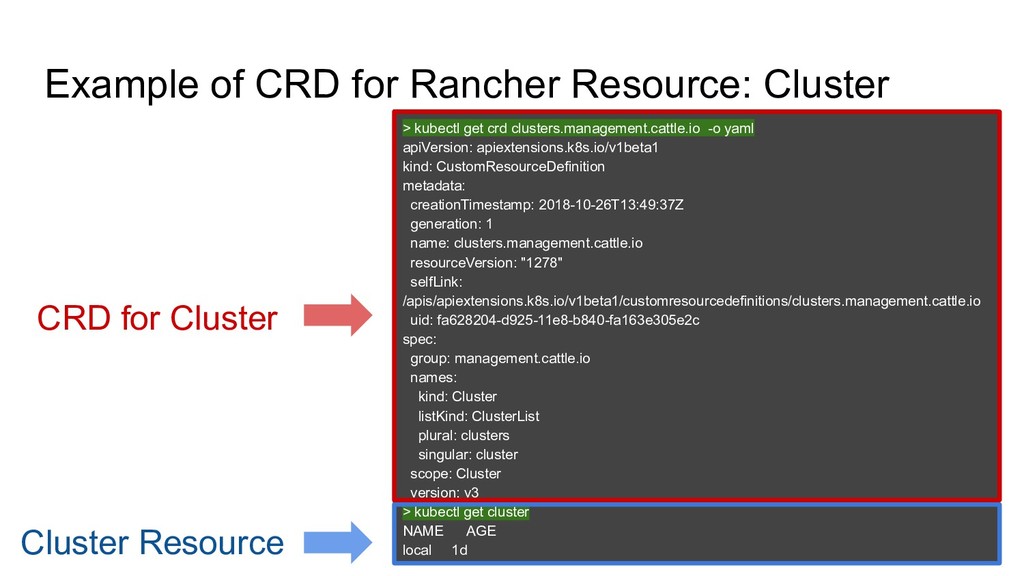
Watch Kubernetes Cluster Cluster Agent Node Agent NodeA NodeB CRD ・・・ Use CRD(Custom Resource Definition) to store Cluster, Node, User Informations…. Rancher API is just to create Kubernetes Custom Resource (kind of API proxy) When Controller detect new cluster resource, Do provisioning
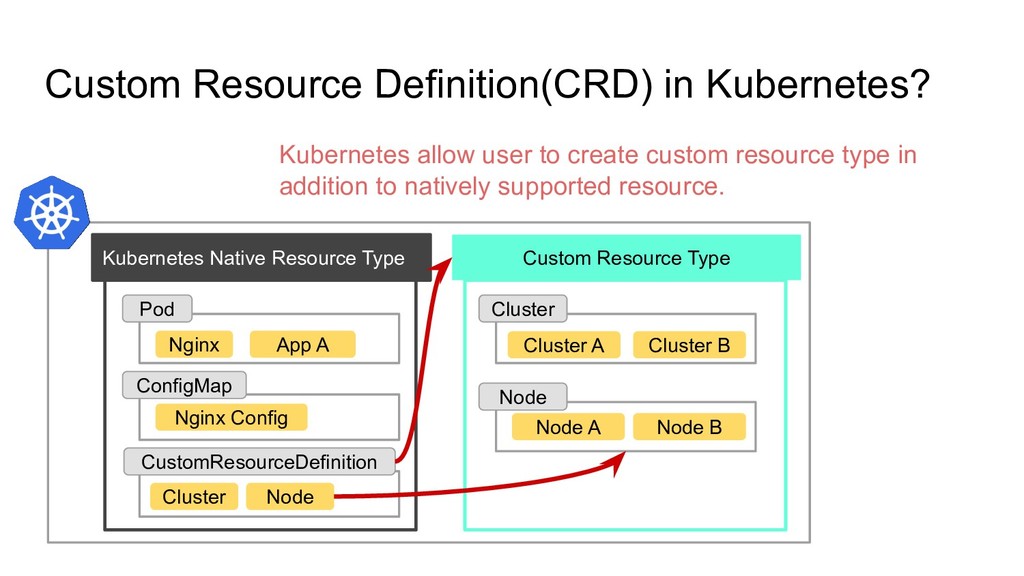
Resource Type CustomResourceDefinition ConfigMap Pod Nginx App A Nginx Config Cluster Node Cluster Node Cluster A Cluster B Node A Node B Kubernetes allow user to create custom resource type in addition to natively supported resource.
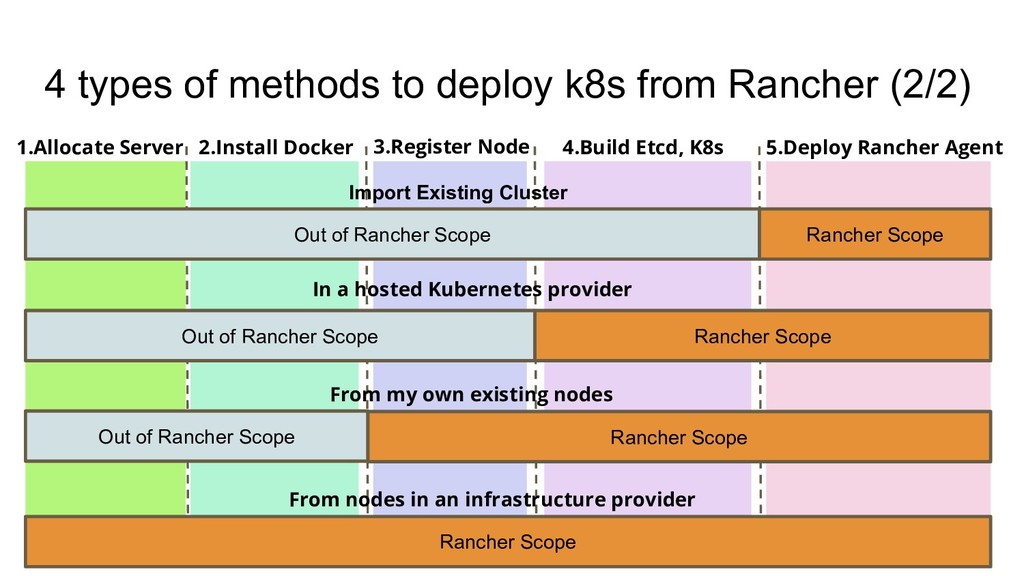
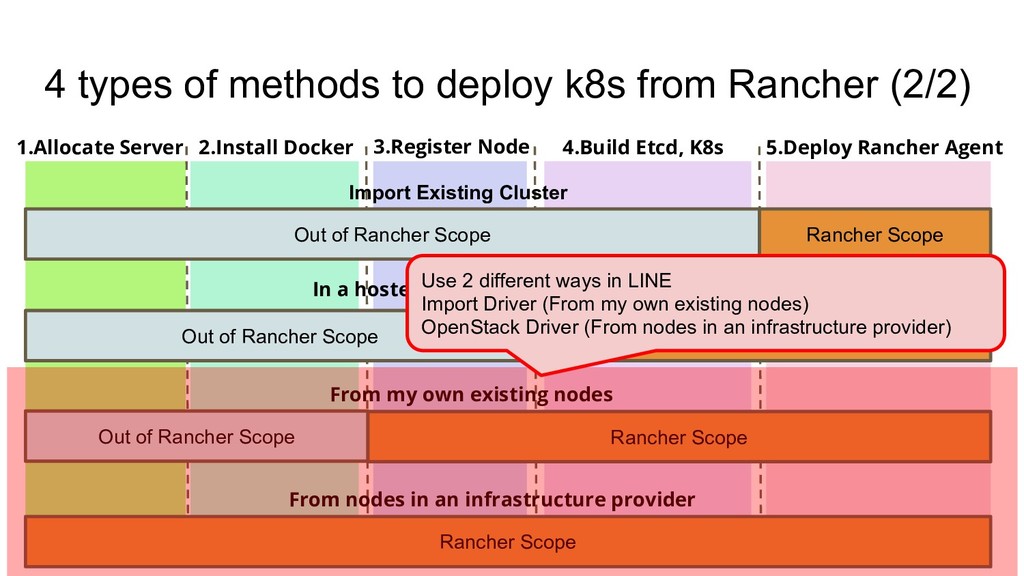
1.Allocate Server 2.Install Docker 3.Register Node 4.Build Etcd, K8s 5.Deploy Rancher Agent Rancher Scope Rancher Scope Rancher Scope Rancher Scope Out of Rancher Scope Out of Rancher Scope Import Existing Cluster In a hosted Kubernetes provider Out of Rancher Scope From my own existing nodes From nodes in an infrastructure provider
1.Allocate Server 2.Install Docker 3.Register Node 4.Build Etcd, K8s 5.Deploy Rancher Agent Rancher Scope Rancher Scope Rancher Scope Rancher Scope Out of Rancher Scope Out of Rancher Scope Import Existing Cluster In a hosted Kubernetes provider Out of Rancher Scope From my own existing nodes From nodes in an infrastructure provider Use 2 different ways in LINE Import Driver (From my own existing nodes) OpenStack Driver (From nodes in an infrastructure provider)
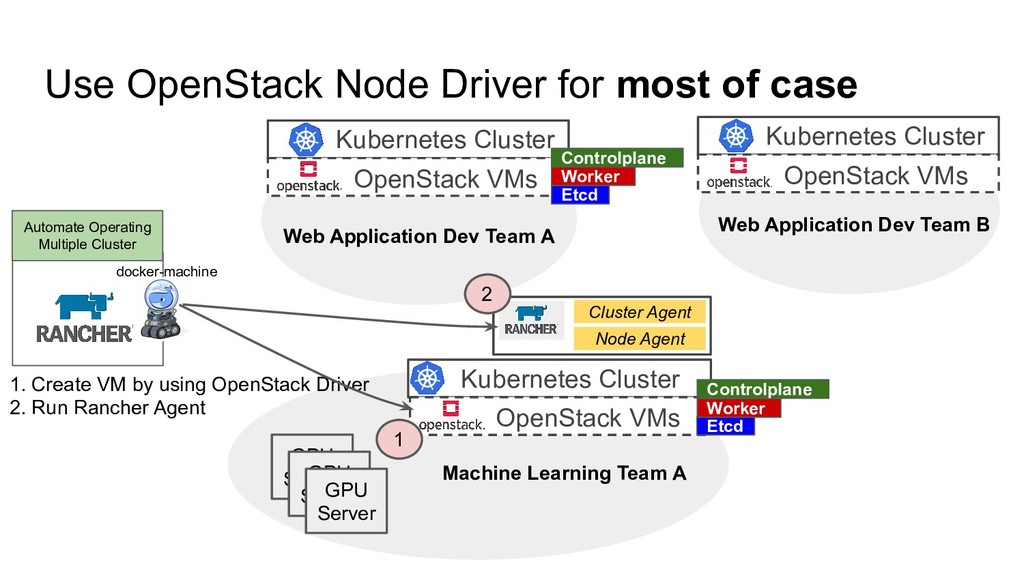
Multiple Cluster Web Application Dev Team A Machine Learning Team A Web Application Dev Team B Kubernetes Cluster OpenStack VMs Kubernetes Cluster OpenStack VMs Kubernetes Cluster OpenStack VMs Etcd Controlplane Etcd Controlplane Worker 1. Create VM by using OpenStack Driver 2. Run Rancher Agent GPU Server GPU Server GPU Server Worker docker-machine Cluster Agent Node Agent 1 2
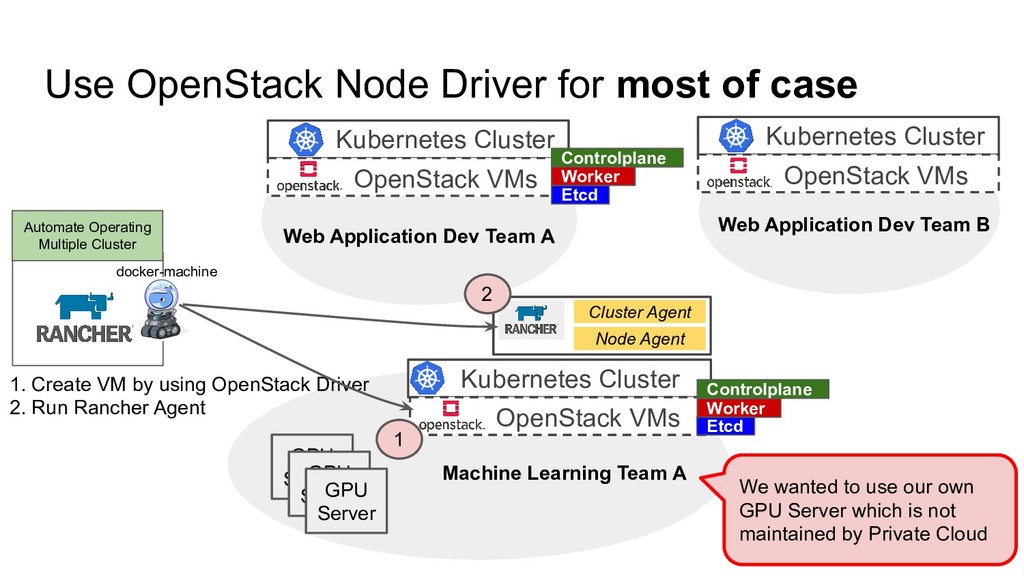
Multiple Cluster Web Application Dev Team A Machine Learning Team A Web Application Dev Team B Kubernetes Cluster OpenStack VMs Kubernetes Cluster OpenStack VMs Kubernetes Cluster OpenStack VMs We wanted to use our own GPU Server which is not maintained by Private Cloud Etcd Controlplane Etcd Controlplane Worker 1. Create VM by using OpenStack Driver 2. Run Rancher Agent GPU Server GPU Server GPU Server Worker docker-machine Cluster Agent Node Agent 1 2
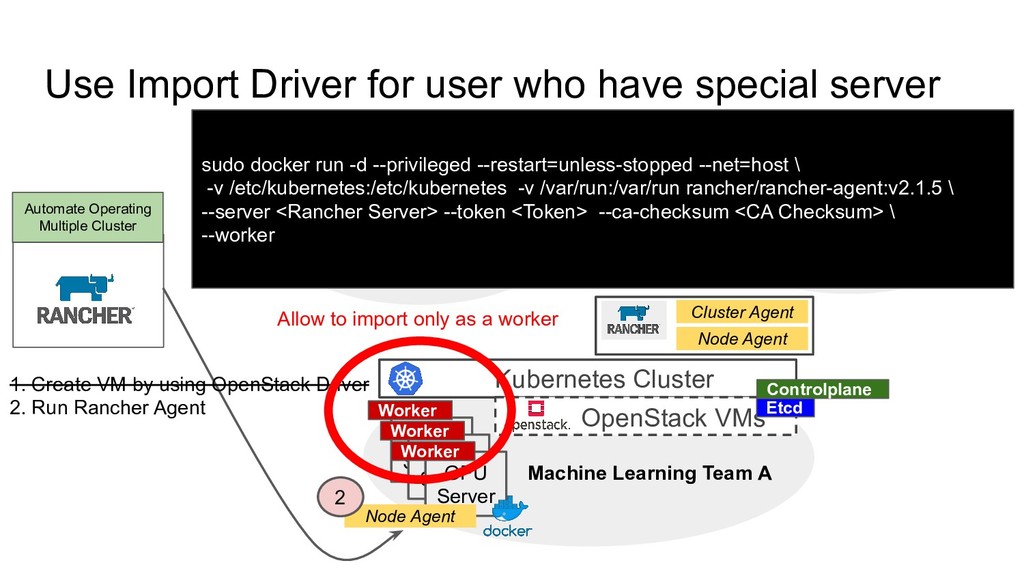
Operating Multiple Cluster Web Application Dev Team A Machine Learning Team A Web Application Dev Team B Kubernetes Cluster OpenStack VMs Kubernetes Cluster OpenStack VMs Kubernetes Cluster OpenStack VMs GPU Server GPU Server GPU Server Worker Worker Worker Etcd Controlplane Etcd Controlplane Worker Cluster Agent Node Agent 1. Create VM by using OpenStack Driver 2. Run Rancher Agent Node Agent 2 Allow to import only as a worker sudo docker run -d --privileged --restart=unless-stopped --net=host \ -v /etc/kubernetes:/etc/kubernetes -v /var/run:/var/run rancher/rancher-agent:v2.1.5 \ --server <Rancher Server> --token <Token> --ca-checksum <CA Checksum> \ --worker
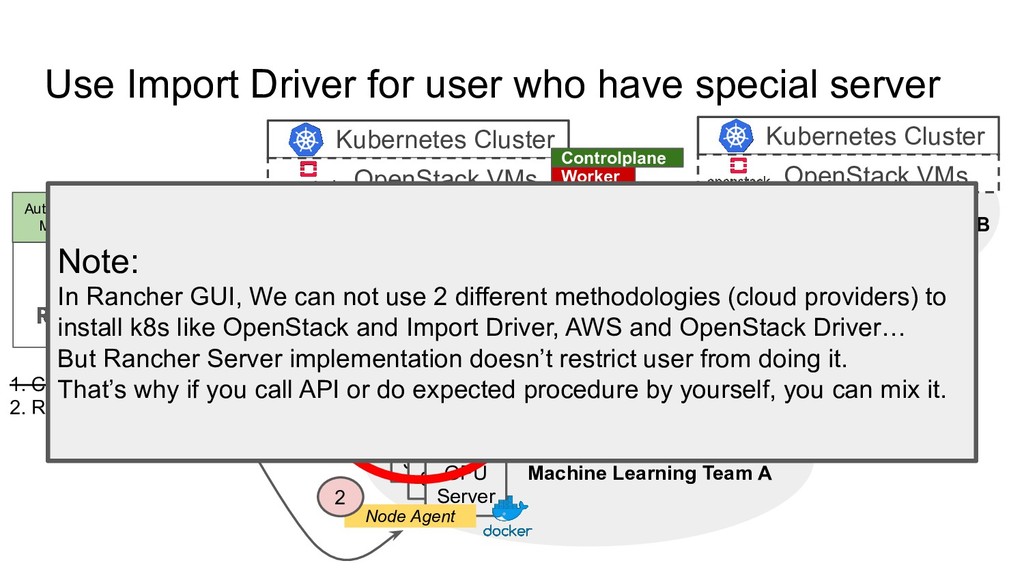
Operating Multiple Cluster Web Application Dev Team A Machine Learning Team A Web Application Dev Team B Kubernetes Cluster OpenStack VMs Kubernetes Cluster OpenStack VMs Kubernetes Cluster OpenStack VMs GPU Server GPU Server GPU Server Worker Worker Worker Etcd Controlplane Etcd Controlplane Worker Cluster Agent Node Agent 1. Create VM by using OpenStack Driver 2. Run Rancher Agent Node Agent 2 Allow to import only as a worker Note: In Rancher GUI, We can not use 2 different methodologies (cloud providers) to install k8s like OpenStack and Import Driver, AWS and OpenStack Driver… But Rancher Server implementation doesn’t restrict user from doing it. That’s why if you call API or do expected procedure by yourself, you can mix it.
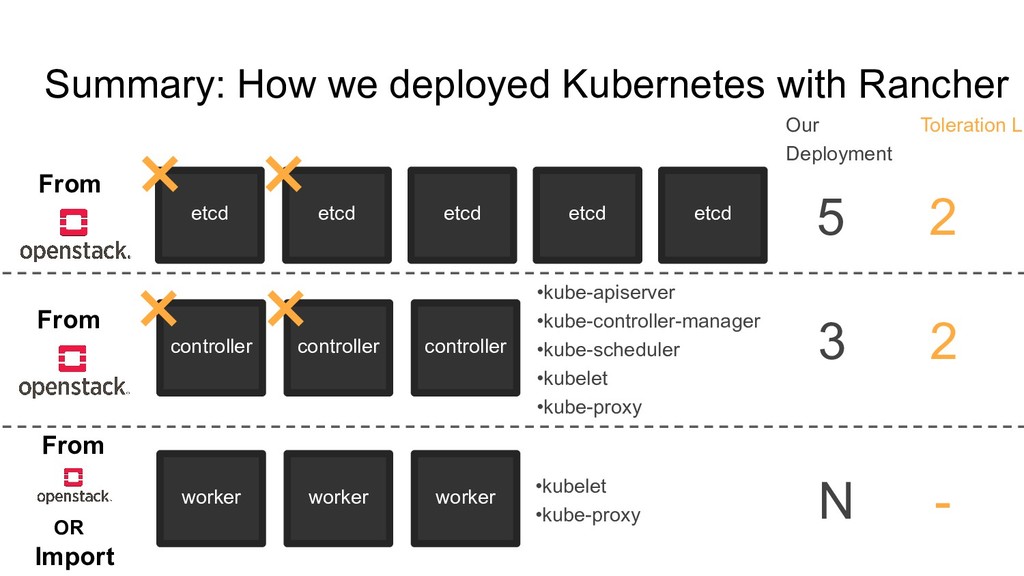
3 •kube-apiserver •kube-controller-manager •kube-scheduler •kubelet •kube-proxy × × × 2 worker worker worker N •kubelet •kube-proxy - Toleration Li Our Deployment × Summary: How we deployed Kubernetes with Rancher From From From OR Import
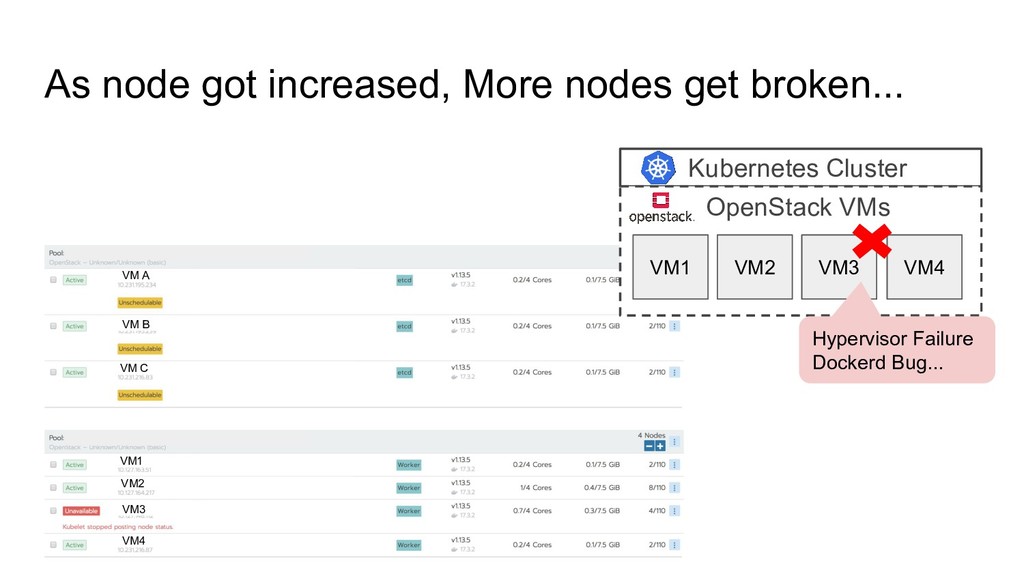
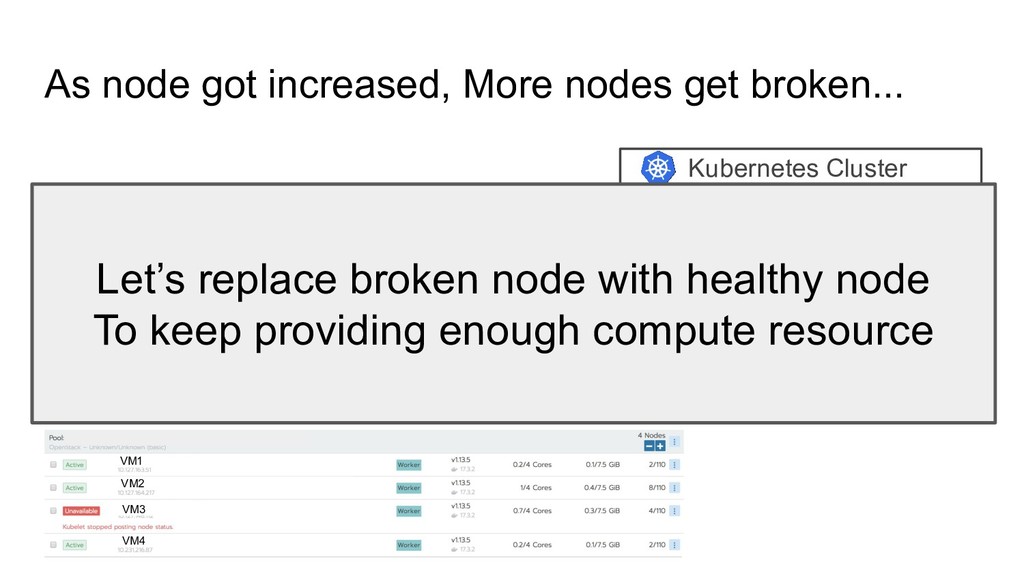
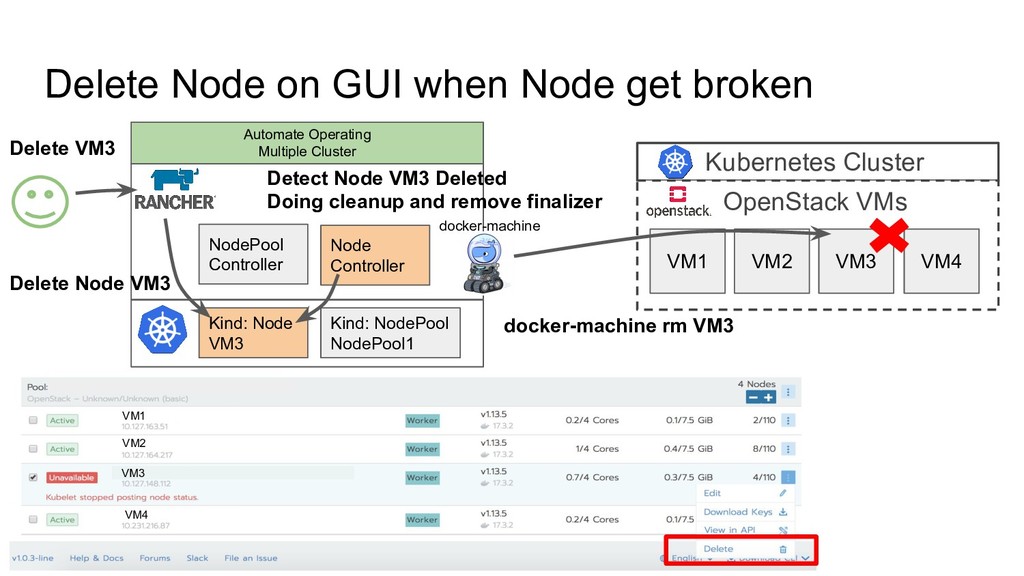
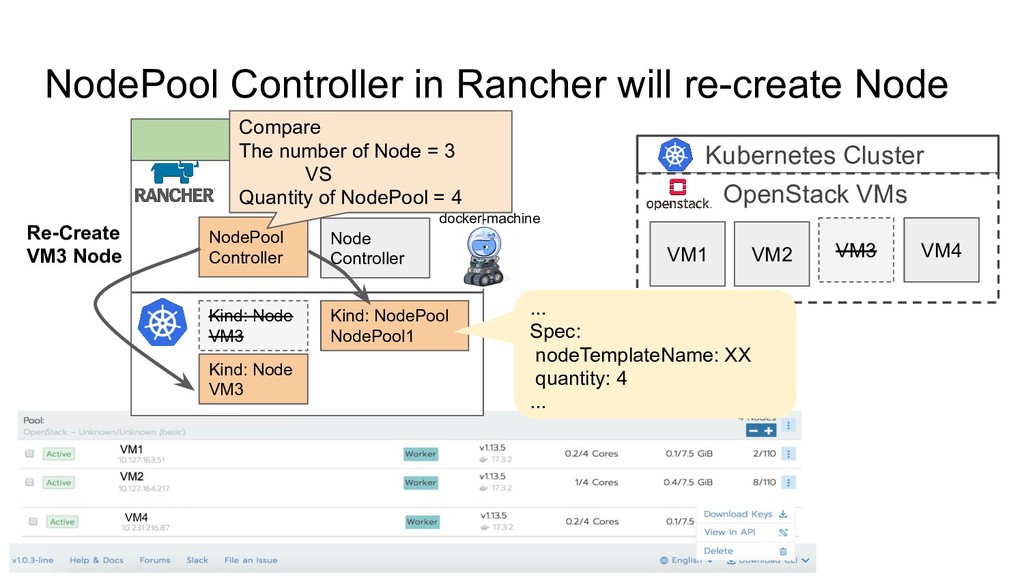
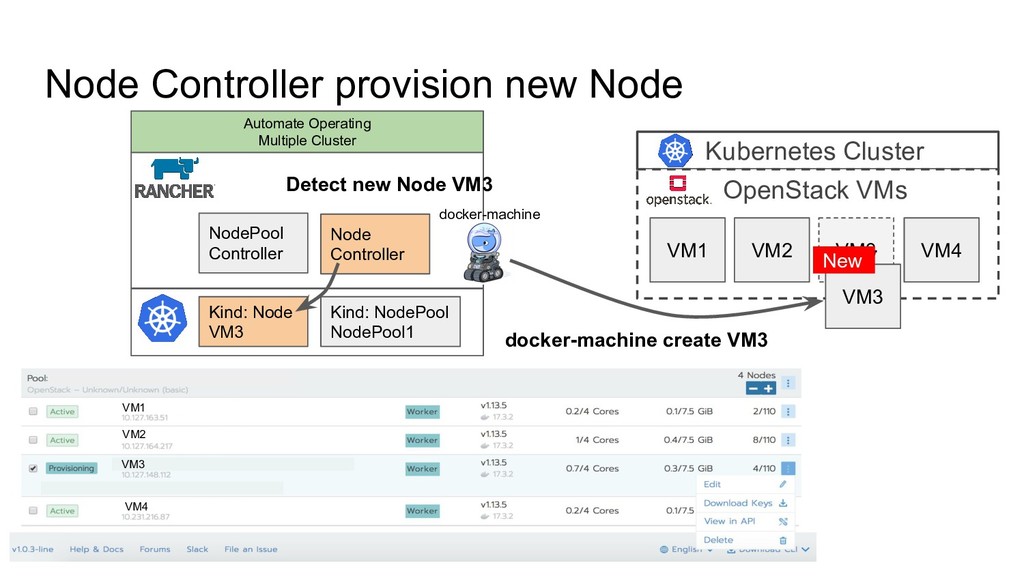
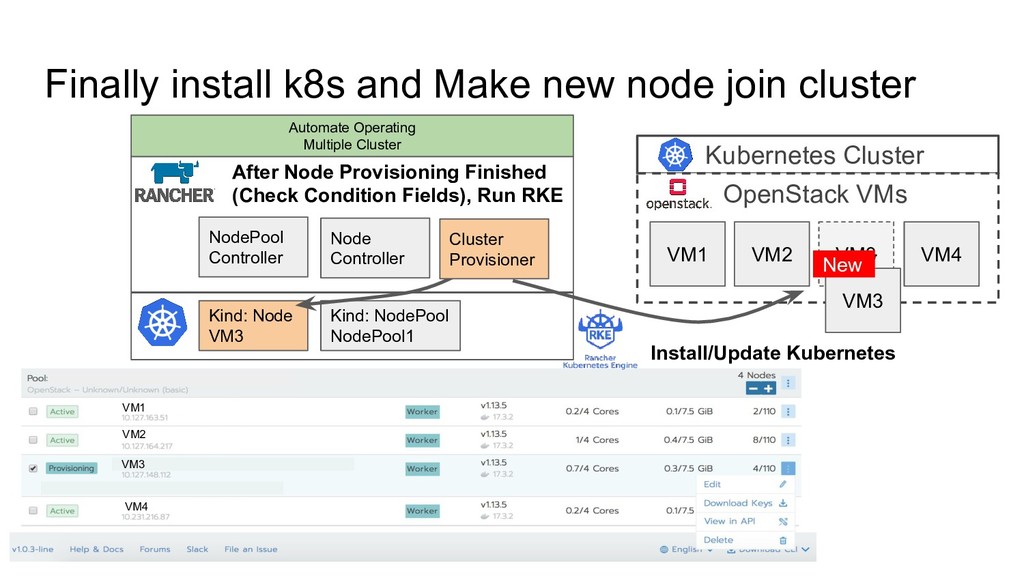
OpenStack VMs VM1 VM2 VM3 VM4 Hypervisor Failure Dockerd Bug... VM1 VM2 VM3 VM4 VM A VM B VM C Let’s replace broken node with healthy node To keep providing enough compute resource
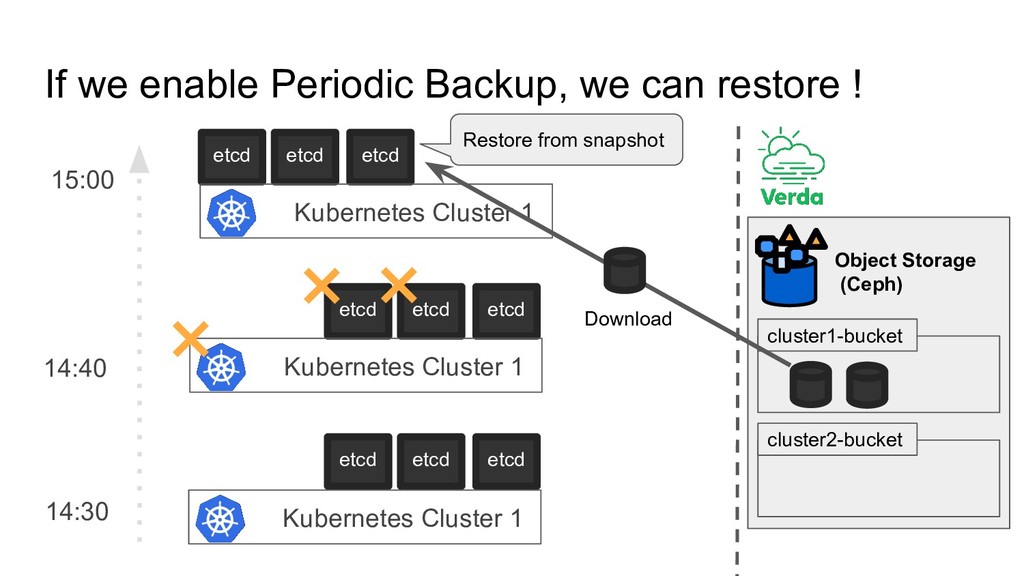
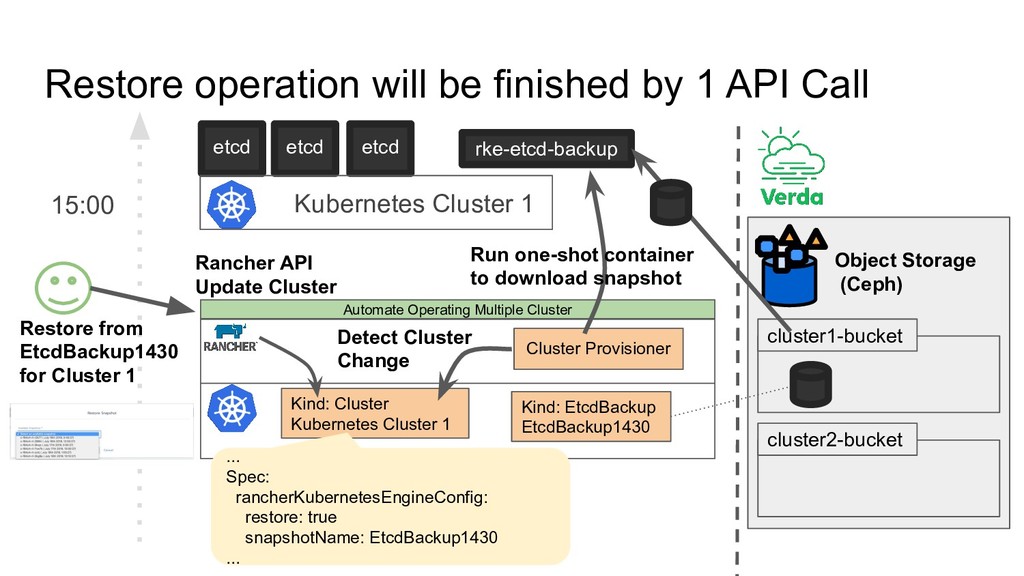
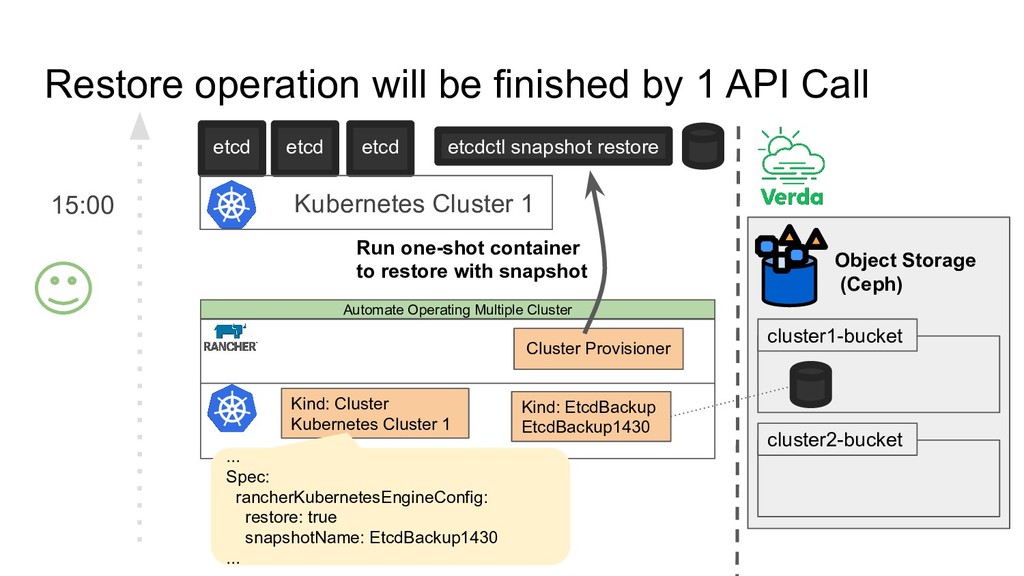
14:30 14:40 etcd etcd etcd × × × There is always risk for etcd data to be gone - Crush multiple etcd nodes - Accidently deleted data (Human Error) Kubernetes Cluster 1 Kubernetes Cluster 1
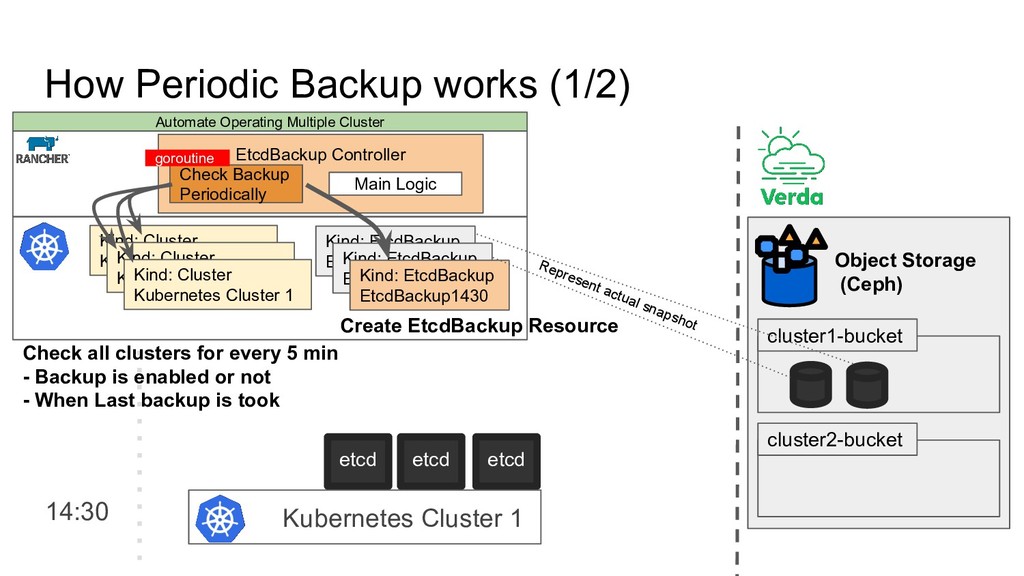
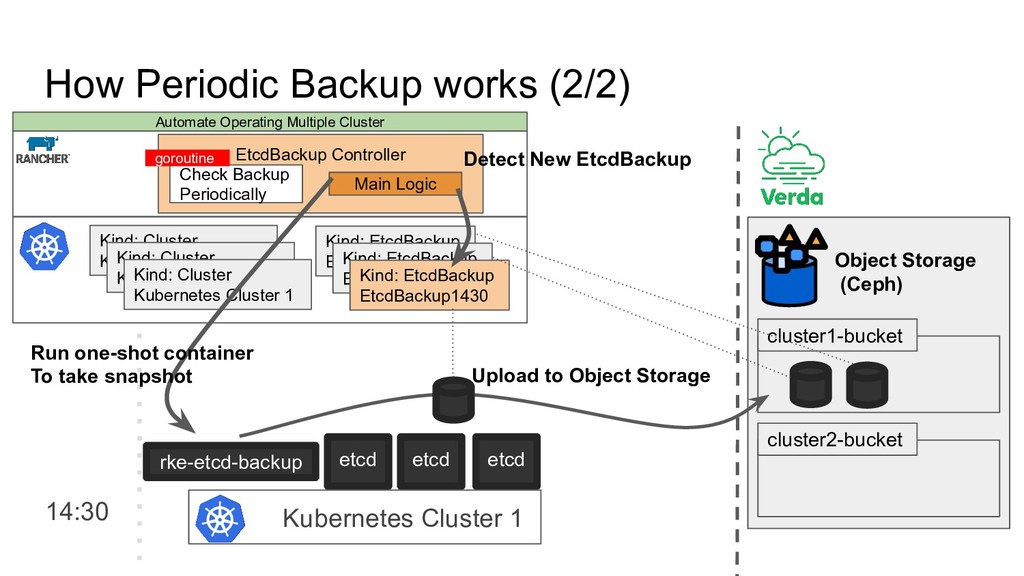
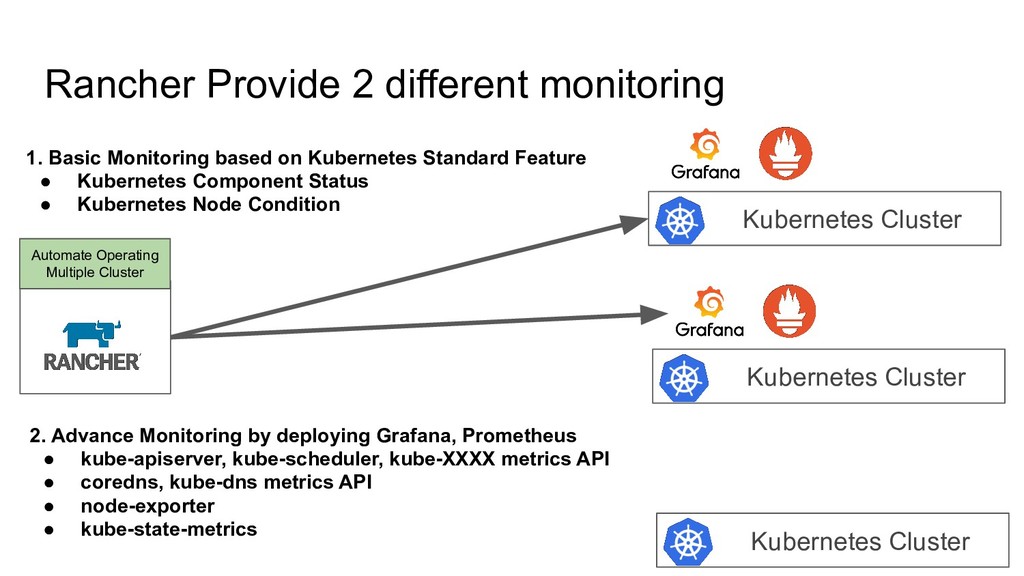
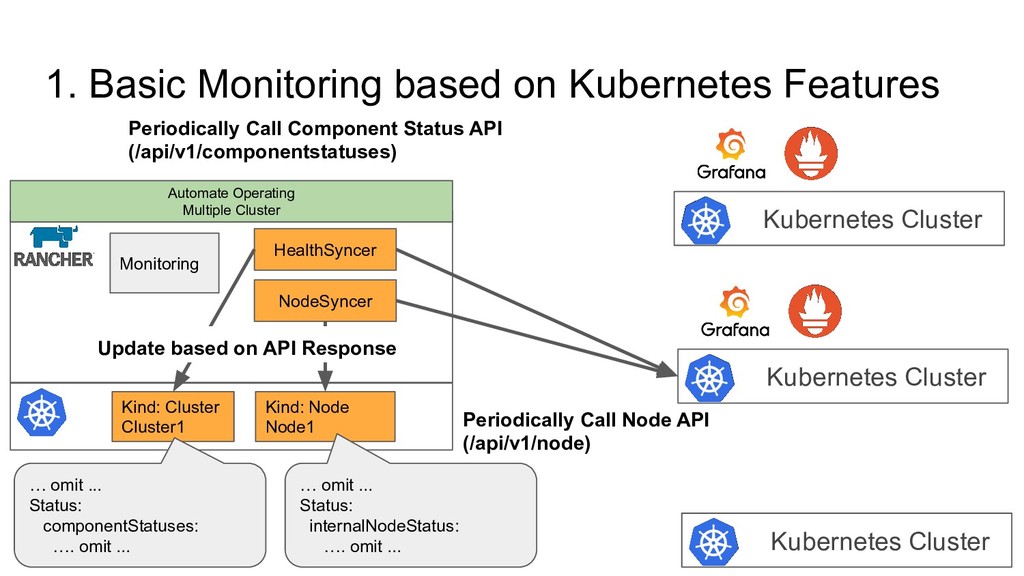
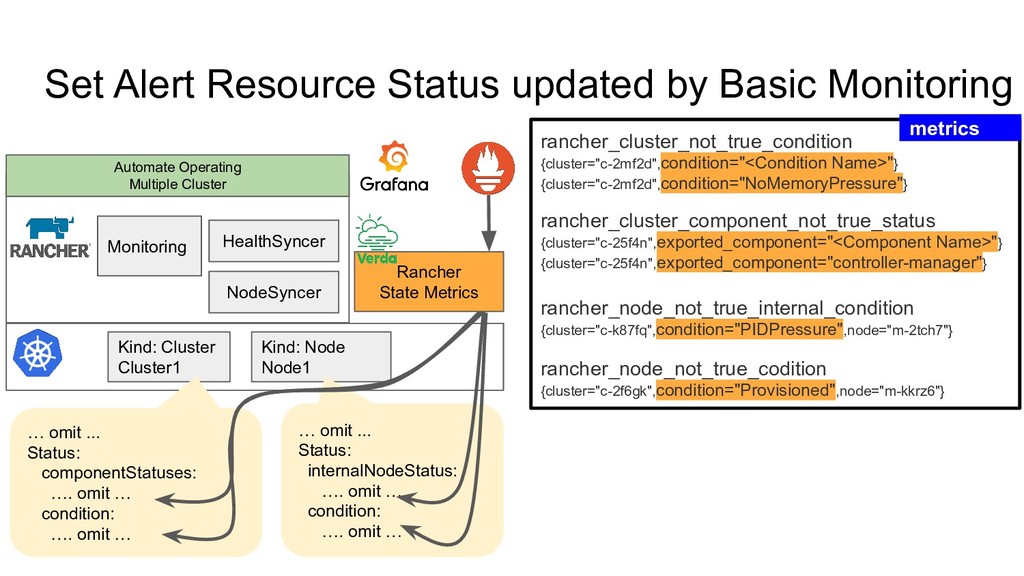
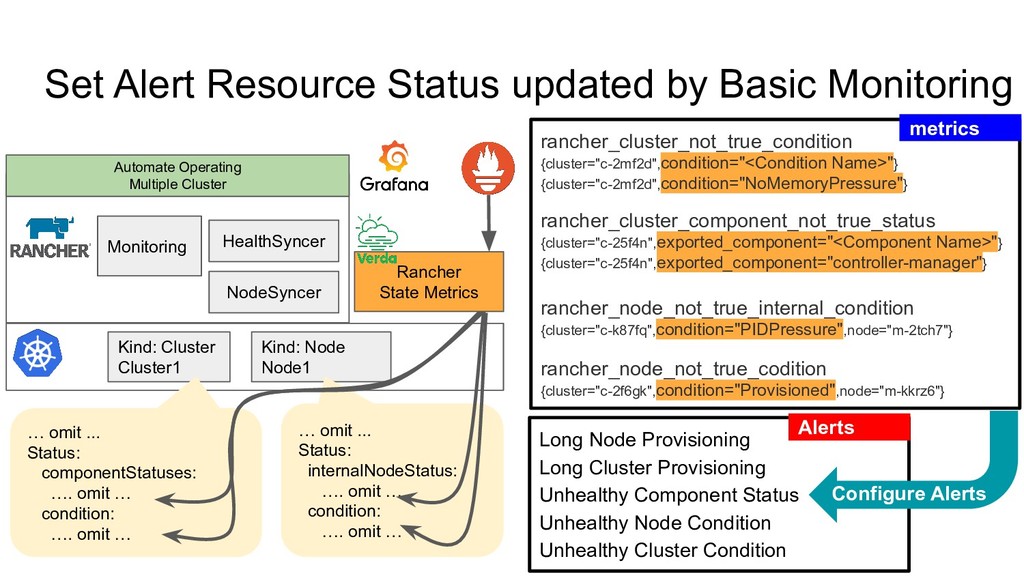
Kubernetes Cluster 1. Basic Monitoring based on Kubernetes Standard Feature • Kubernetes Component Status • Kubernetes Node Condition 2. Advance Monitoring by deploying Grafana, Prometheus • kube-apiserver, kube-scheduler, kube-XXXX metrics API • coredns, kube-dns metrics API • node-exporter • kube-state-metrics Automate Operating Multiple Cluster • Use only Basic Monitoring ◦ Set alert for Node Status, Cluster Status on CRD • We don’t enable Rancher’s Advanced Monitoring ◦ We have/use our own Prometheus, Grafana Configuration
number of clusters are more than 90 Long Node Provisioning Long Cluster Provisioning Unhealthy Component Status Unhealthy Node Condition Unhealthy Cluster Condition We can notice each node, cluster’s status change
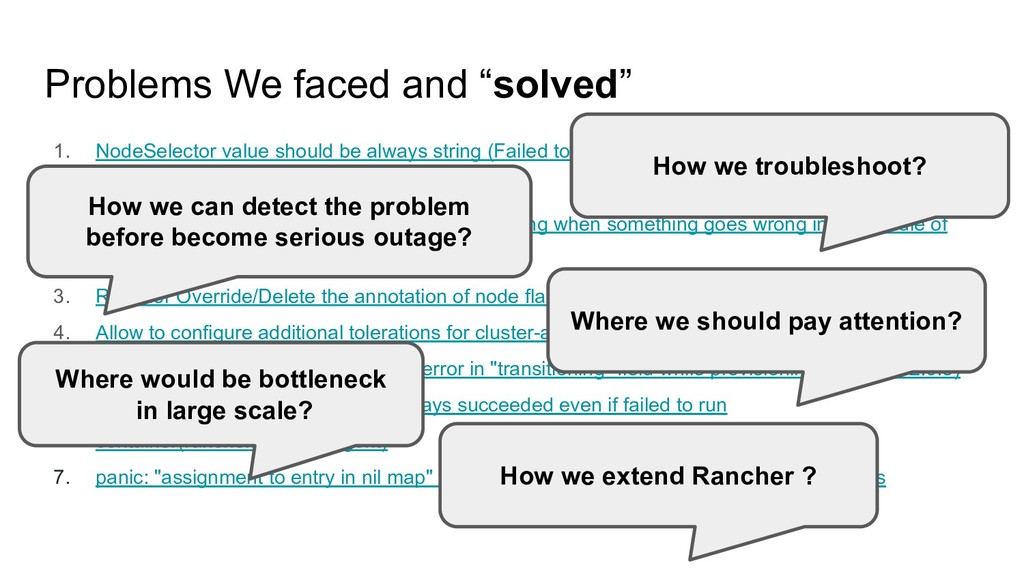
always string (Failed to deploy ingress-nginx, kube-dns, coredns when specify "XXX.com: true" in nodeSelector 2. Rancher Cluster Agent, Node Agent might get hung when something goes wrong in the middle of WebSocket Session Handshake 3. Rancher Override/Delete the annotation of node flannel internally used to setup Vtep on the Host 4. Allow to configure additional tolerations for cluster-agent, node-agent rancher will deploy 5. Cluster with RKE driver always have error in "transitioning" field while provisioning (master, v2.0.8) 6. deployAgent in node-controller is always succeeded even if failed to run container(rancher/rancher-agent) 7. panic: "assignment to entry in nil map" when try to create node by calling POST /v3/nodes
always string (Failed to deploy ingress-nginx, kube-dns, coredns when specify "XXX.com: true" in nodeSelector 2. Rancher Cluster Agent, Node Agent might get hung when something goes wrong in the middle of WebSocket Session Handshake 3. Rancher Override/Delete the annotation of node flannel internally used to setup Vtep on the Host 4. Allow to configure additional tolerations for cluster-agent, node-agent rancher will deploy 5. Cluster with RKE driver always have error in "transitioning" field while provisioning (master, v2.0.8) 6. deployAgent in node-controller is always succeeded even if failed to run container(rancher/rancher-agent) 7. panic: "assignment to entry in nil map" when try to create node by calling POST /v3/nodes How we can detect the problem before become serious outage? How we troubleshoot? Where would be bottleneck in large scale? Where we should pay attention? How we extend Rancher ?
string (Failed to deploy ingress-nginx, kube-dns, coredns when specify "XXX.com: true" in nodeSelector 2. Rancher Cluster Agent, Node Agent might get hung when something goes wrong in the middle of WebSocket Session Handshake 3. Rancher Override/Delete the annotation of node flannel internally used to setup Vtep on the Host 4. Allow to configure additional tolerations for cluster-agent, node-agent rancher will deploy 5. Cluster with RKE driver always have error in "transitioning" field while provisioning (master, v2.0.8) 6. deployAgent in node-controller is always succeeded even if failed to run container(rancher/rancher-agent) 7. panic: "assignment to entry in nil map" when try to create node by calling POST /v3/nodes How we can detect the problem? How we troubleshoot? How we grasp what We submitted 1 CFP for North America 2019 “If it’s accepted”, let us talk about our story more detail Today Hopefully on KubeCon
Update Private Cloud Collaboration Managed Kubernetes Kubernetes Operator Kubernetes Solution Architect High Availability Make an effort to keep Kubernetes Cluster stable Keep thinking How we can migrate existing application to Kubernetes Where we focus on Next Where we focus on Next
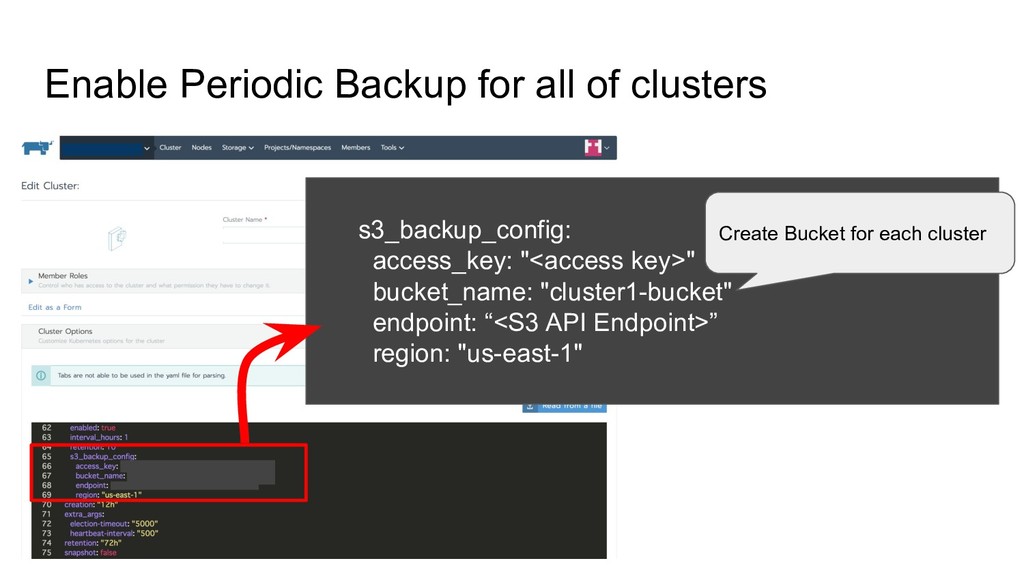
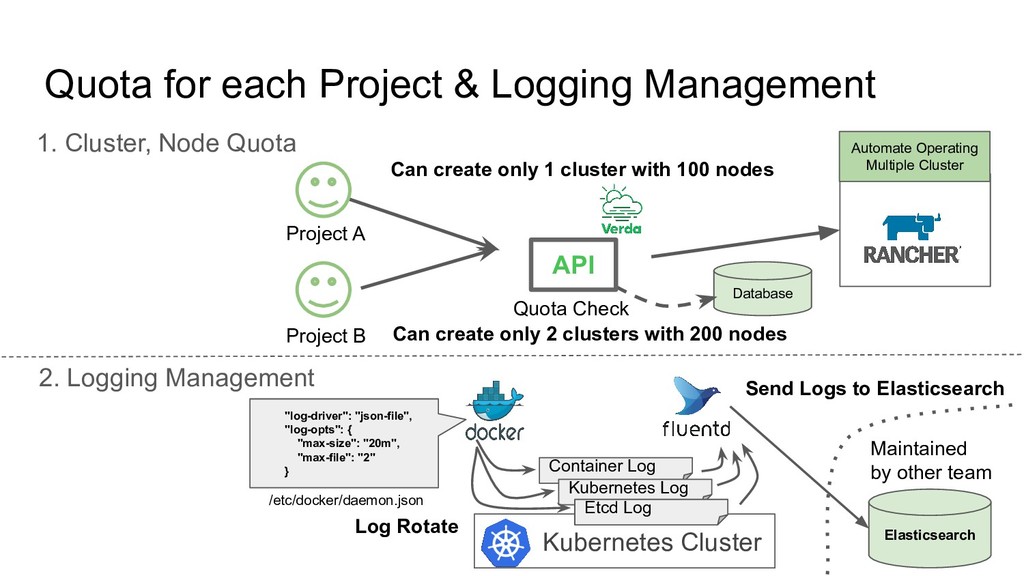
Quota 2. Logging Management Automate Operating Multiple Cluster Project A Project B Can create only 1 cluster with 100 nodes Can create only 2 clusters with 200 nodes Database Quota Check Kubernetes Cluster Elasticsearch Maintained by other team Container Log Kubernetes Log Etcd Log Log Rotate Send Logs to Elasticsearch "log-driver": "json-file", "log-opts": { "max-size": "20m", "max-file": "2" } /etc/docker/daemon.json API
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}