最新のVLM(Vision Language Model)ベースのOCRモデルを中心に、日本語ドキュメントの読み取り性能を検証・比較しました。
【検証内容】 以下の4つのモデルを用いて、請求書・統合報告書・近代文学・レシートの4種類のドキュメントにおける読み取り精度を評価しています。
【対象モデル】
DeepSeek-OCR
olmOCR2 7B (ローカルVLM)
Qwen3-VL 8B
Gemini 3.0 Pro (比較用ベースライン/趣味)
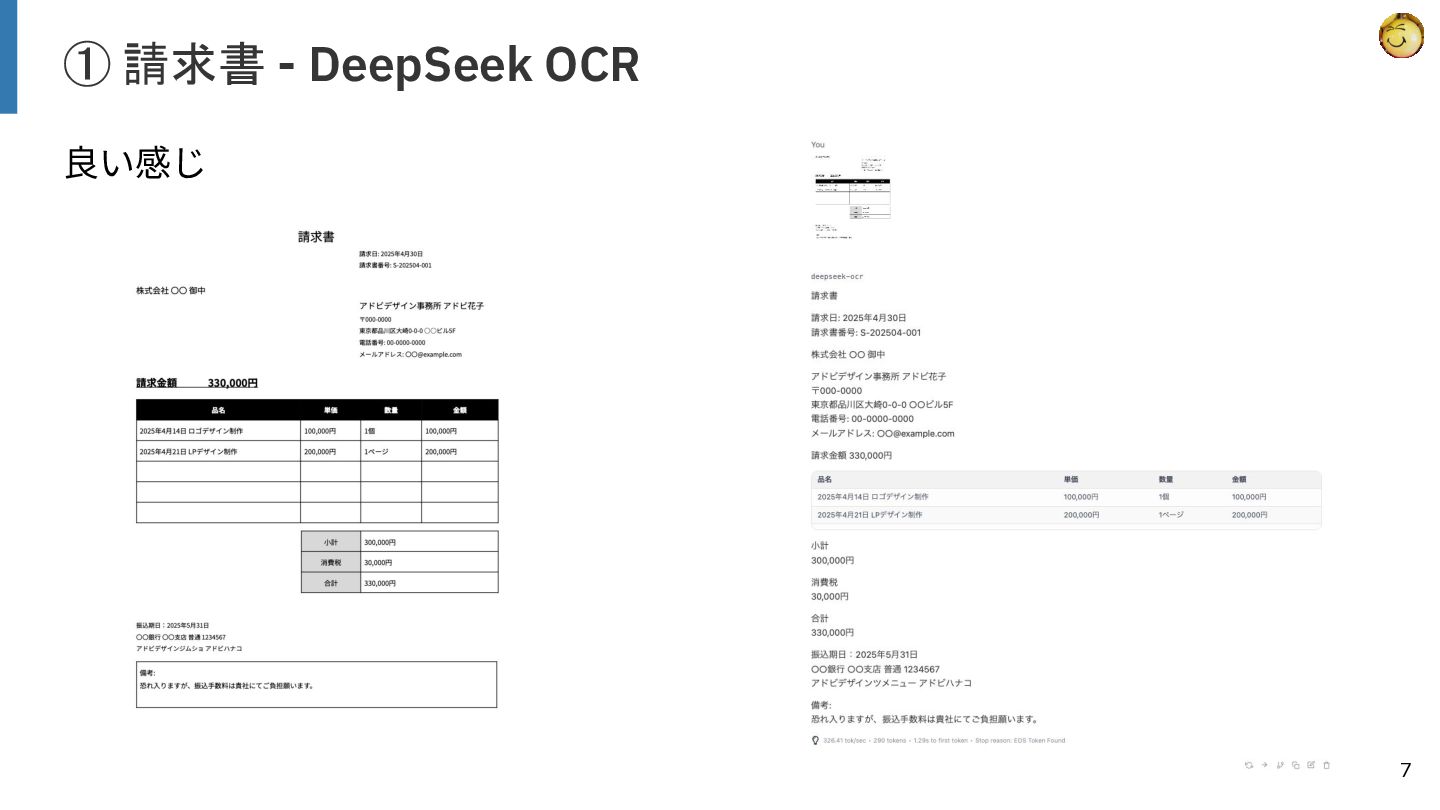
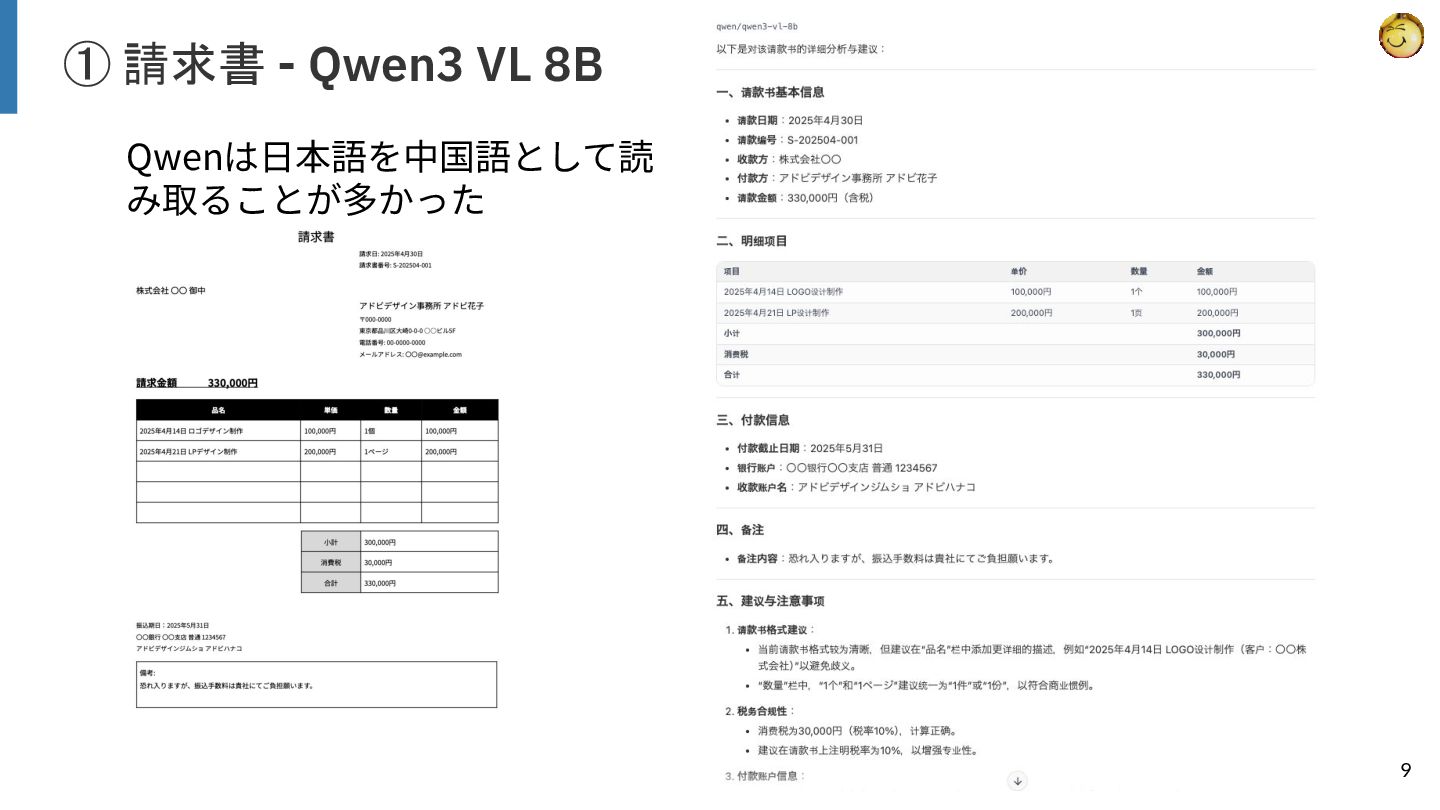
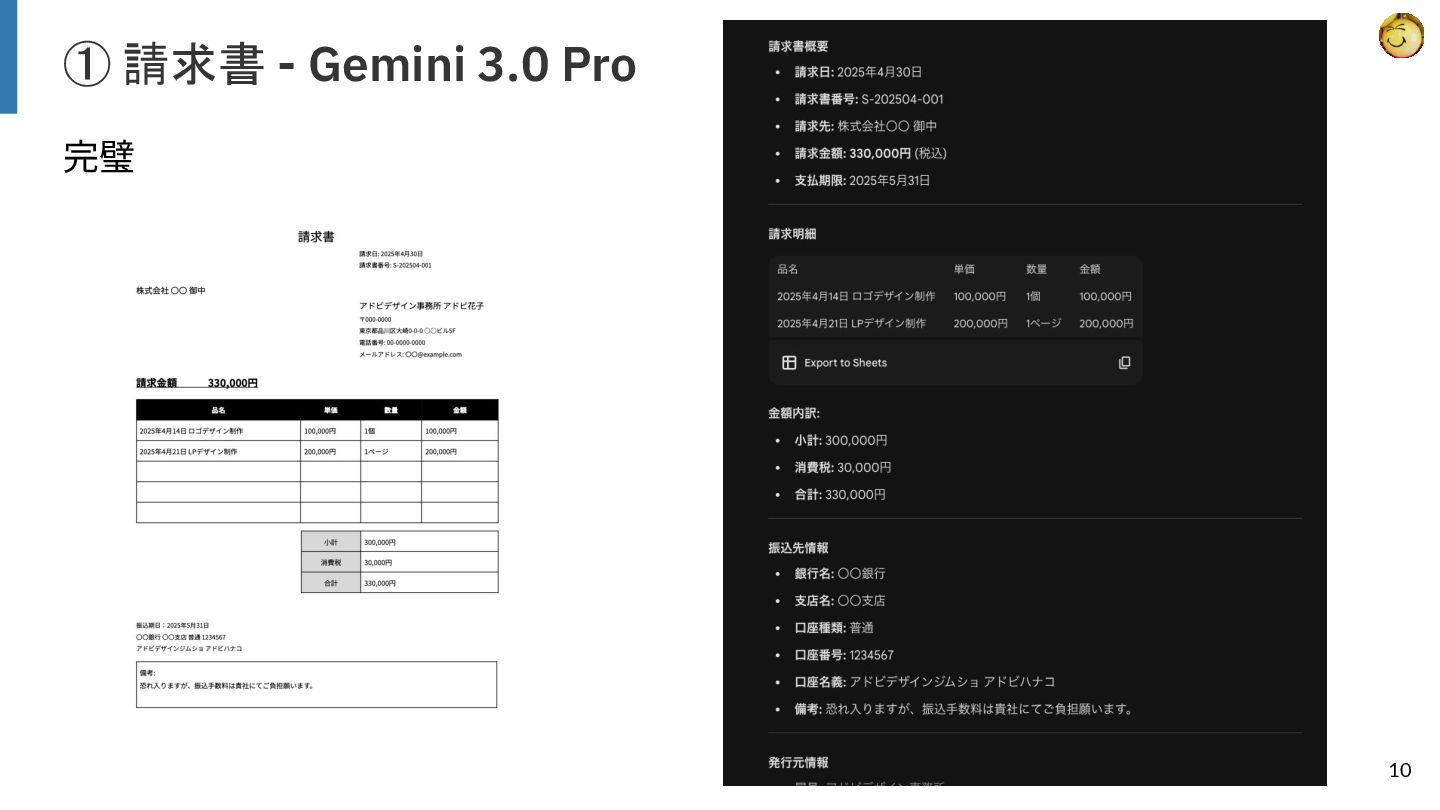
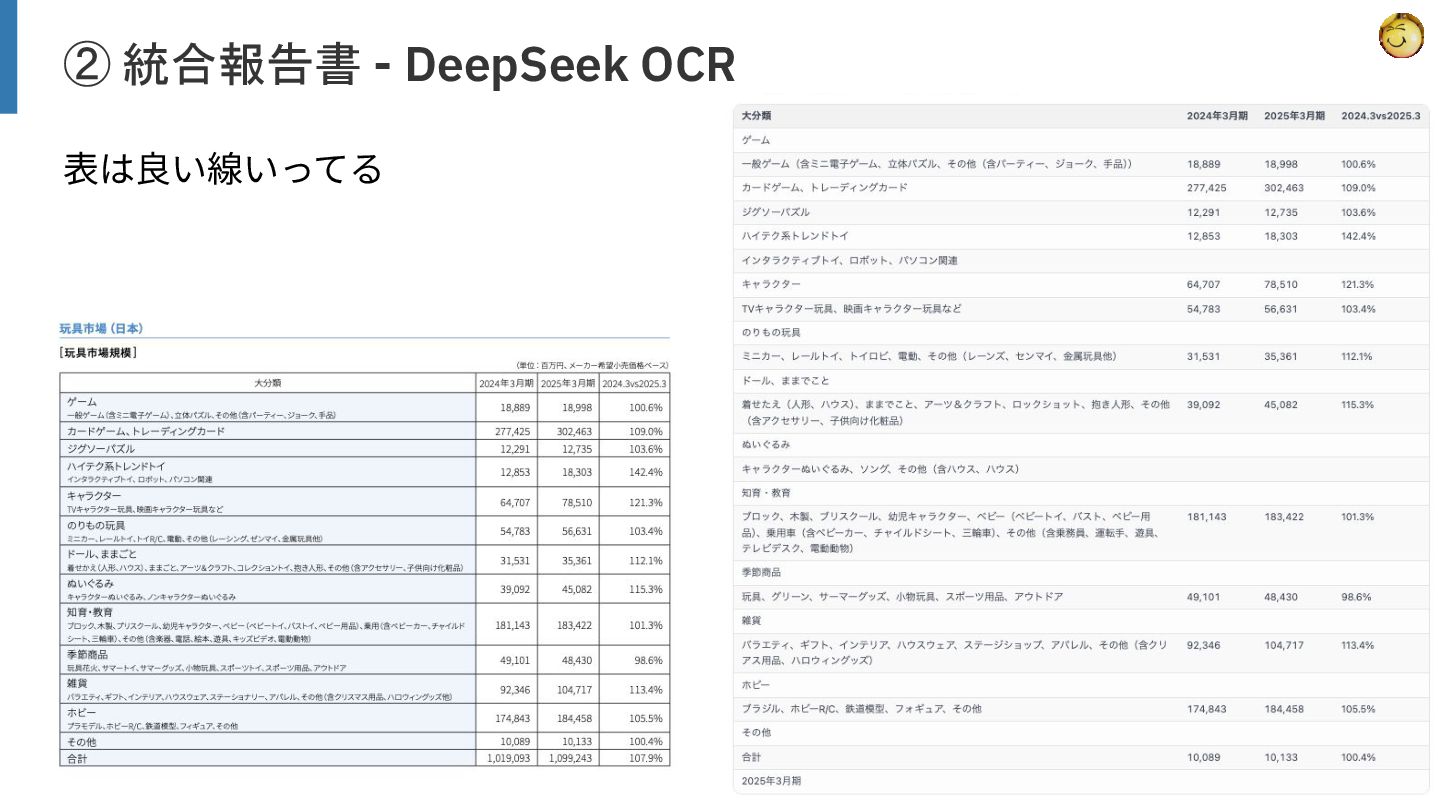
【検証結果】
ベースラインとしたGemini 3.0 Proが高い精度を示しましたが、ローカル動作する7Bクラスのモデルの中では「olmOCR2 7B」が特に健闘しており、レシートや一般的な文書において実用的な性能を示しました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
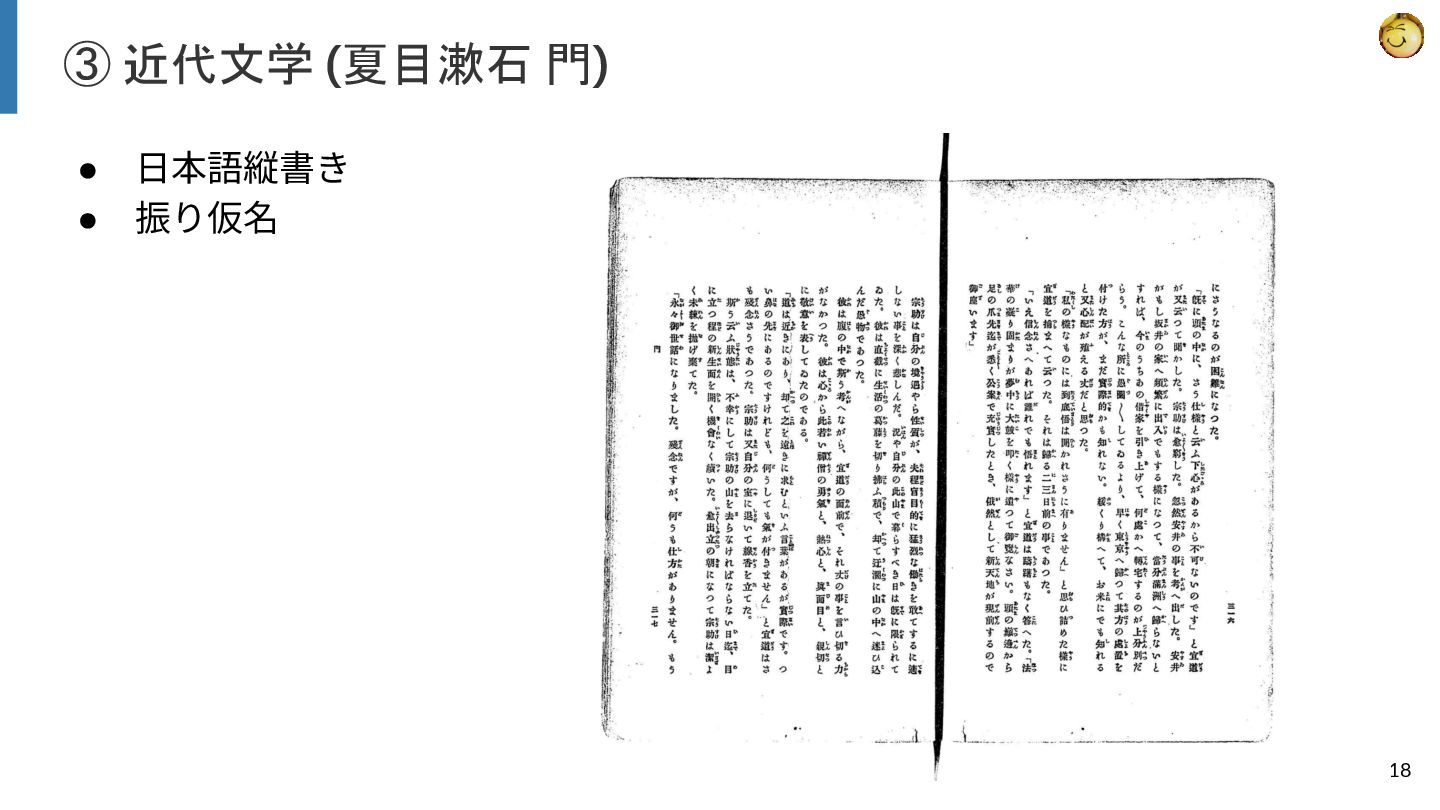{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
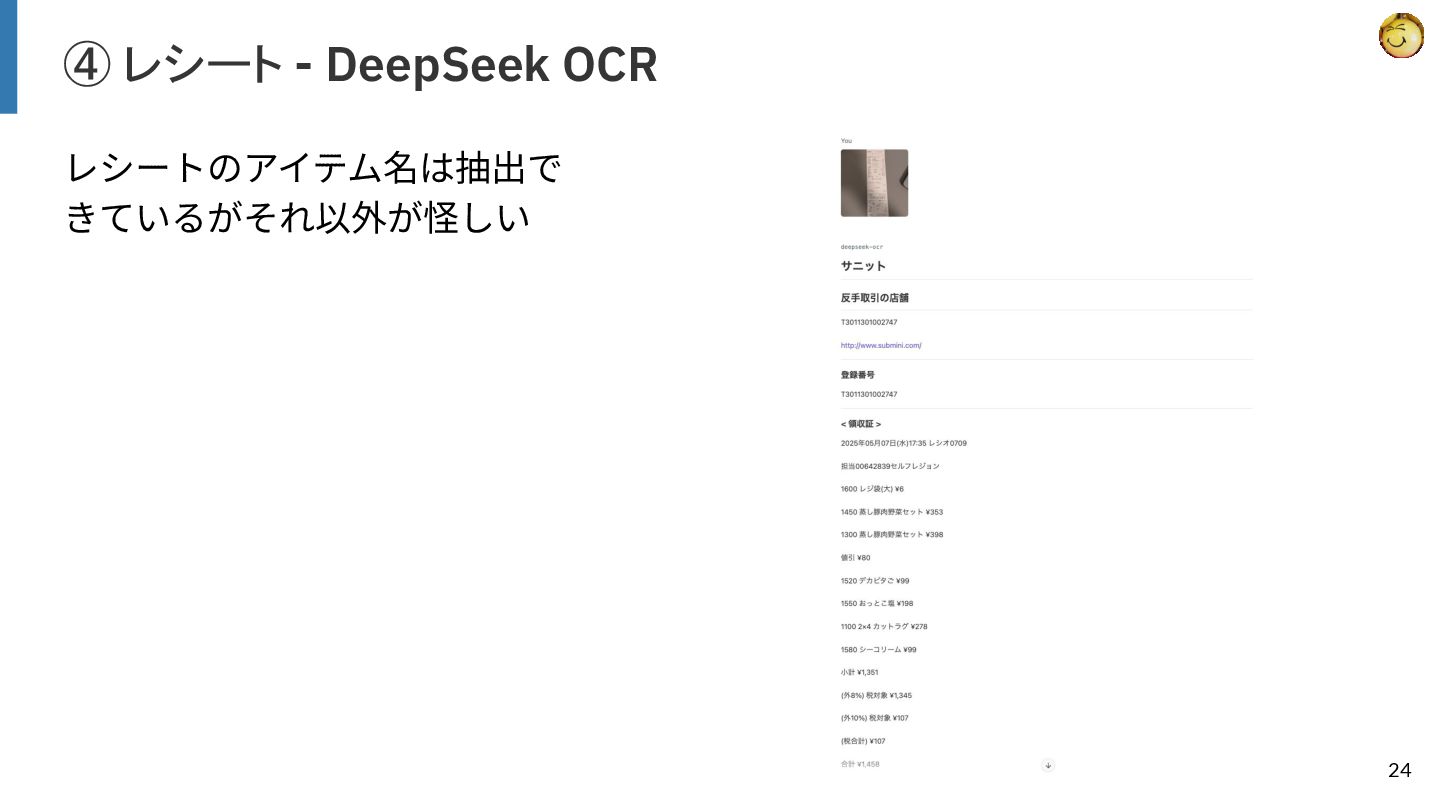{kind=link}
{kind=link}
{kind=link}
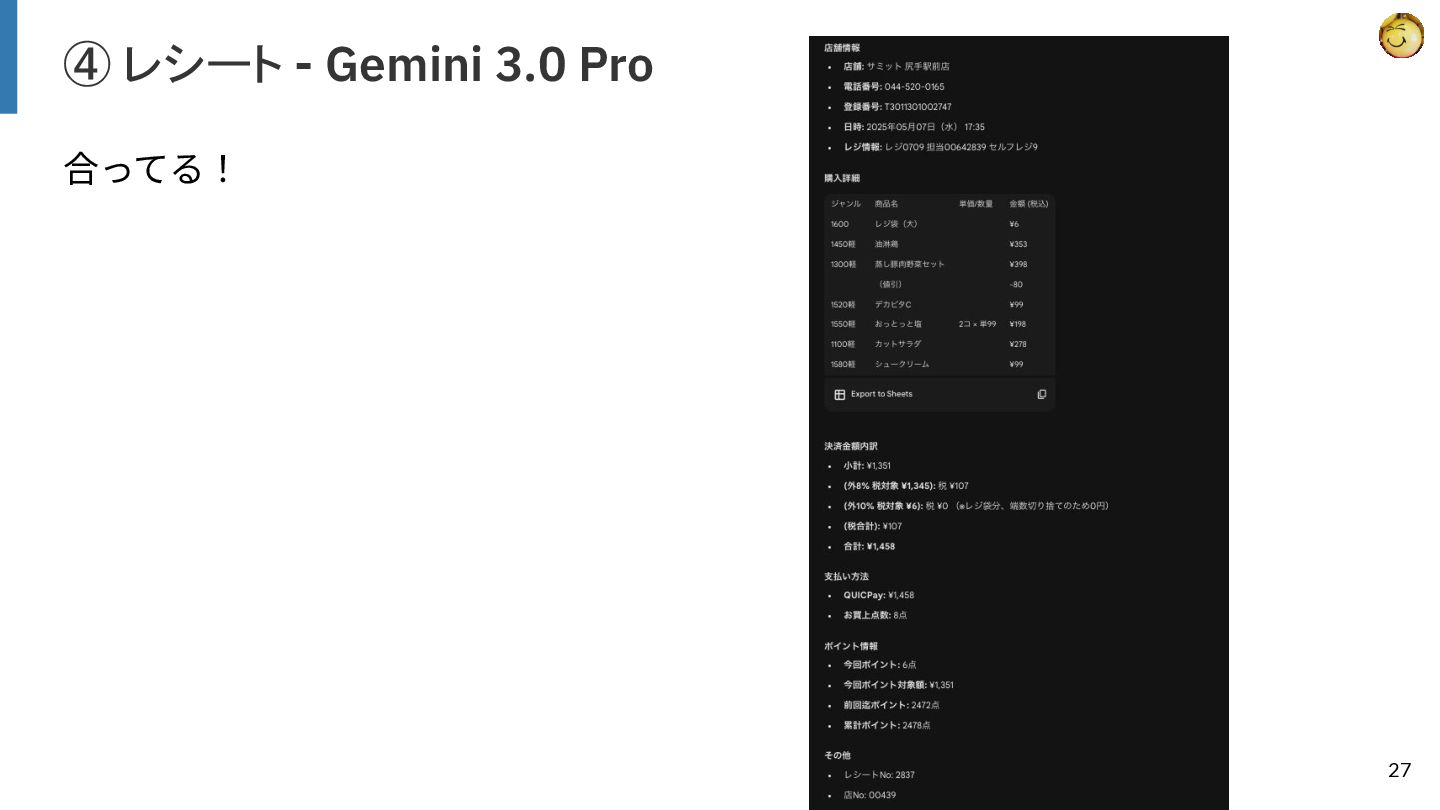{kind=link}
{kind=link}
{kind=link}