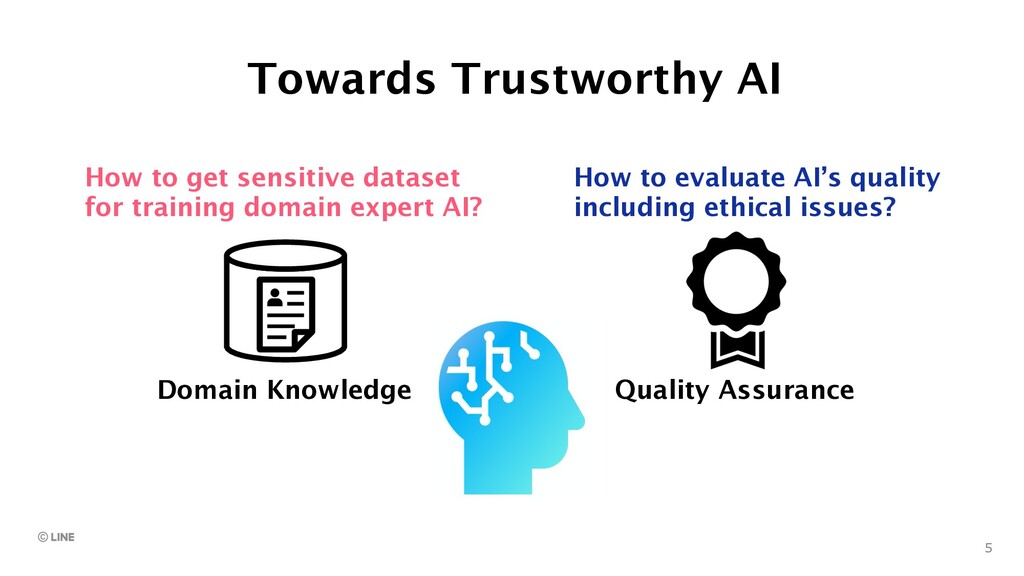
training domain expert AI? How to evaluate AI’s quality including ethical issues? Data Synthesis Federated Learning Ethics Test Evidence-based Verification
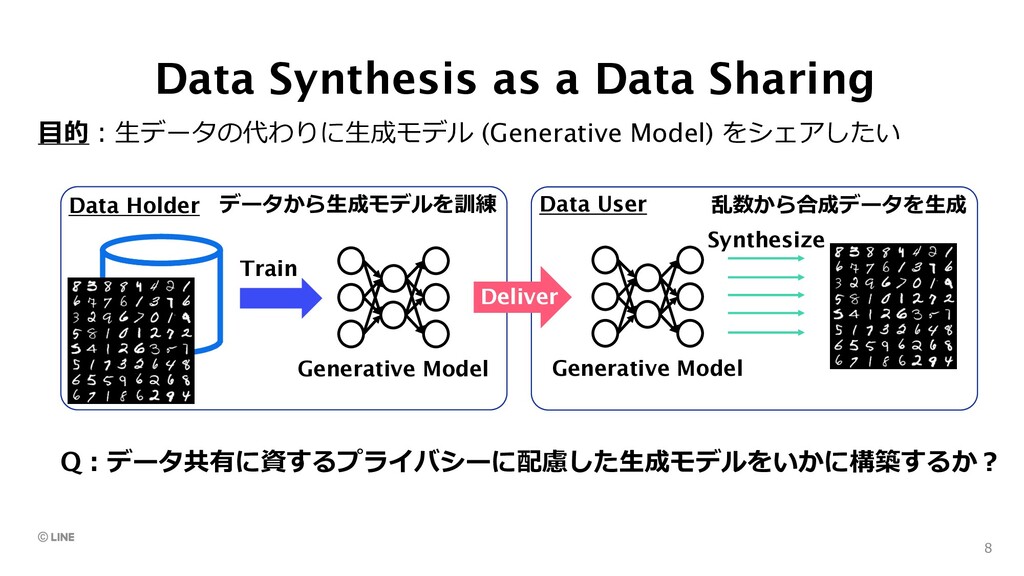
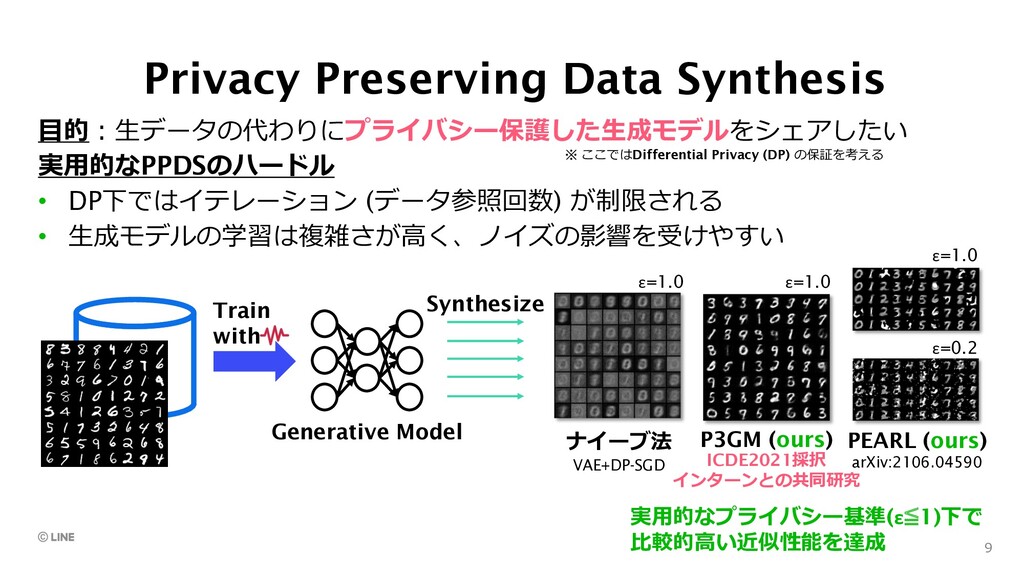
sensitive data through characteristic function representations • (3) train generator while (4) optimizing a critic to distinguish between the real and generated data 10 No limitation in learning iterations Well-reconstruction capability by critic PEARL: Private Embedding & Adversarial Reconstruction Learning
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![PEARL [Liew+, 2021] • (1) (2) differentially private embeddings from](https://files.speakerdeck.com/presentations/c298bcd7eecd48f281a0bdb5b38a42cc/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Adversarial Trigger [Wallance+, 2019] • ⾔語モデルに有害表現を誘発させるTriggerをAIで探索する技術 19 Trigger 外部モデル (GPT-2)](https://files.speakerdeck.com/presentations/c298bcd7eecd48f281a0bdb5b38a42cc/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}