Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Improving Data Gathering And Research
Search
Luca Matteis
November 26, 2011
Programming
160
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Improving Data Gathering And Research
How to improve data gathering using web scraping methodologies.
Luca Matteis
November 26, 2011
More Decks by Luca Matteis
See All by Luca Matteis
Linked Open Data
lmatteis
1
140
What I do
lmatteis
1
83
Crop Ontology
lmatteis
1
98
Why NPM rocks!
lmatteis
2
300
Informatics Development Tools
lmatteis
0
110
Other Decks in Programming
See All in Programming
信頼性について考えてみる(SRE NEXT 2026 miniLT)
hayama17
0
230
AIエージェントで 変わるAndroid開発環境
takahirom
2
740
その節約、円になってますか?
isamumumu
0
540
為什麼你並不需要ViewModel / No, you don't need a ViewModel
lovee
1
450
琵琶湖の水は止められてもNet--HTTPのリトライは止められない / You might be able to stop the water flow of Lake Biwa but you can't stop Net::HTTP retries
luccafort
PRO
0
490
使いながら育てる Claude Code — 開発フローの1コマンド化 × 繰り返し指摘の自動仕組み化
shiki_kakaku
0
1.4k
数百円から始めるRuby電子工作
tarosay
0
120
OpenSpecのproposalにbrainstormingを持たせてみた
tigertora7571
1
150
Welcome to the "Parametricity" 🏙️ − Generic だけど Specific な世界 −
guvalif
PRO
1
190
Built Our Own Background Agent at LayerX #aidevex_findy
layerx
PRO
9
3.8k
광주소프트웨어마이스터고등학교 DevFest 특강 - 바이브 코딩 시대에서 주니어 개발자로 살아남는 방법
utilforever
1
160
TSX の <Hoge<Fuga>> という構文に驚いた話 / tsx-type-argument-syntax
kanaru0928
0
140
Featured
See All Featured
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
230
Believing is Seeing
oripsolob
1
170
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
350
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
4k
Balancing Empowerment & Direction
lara
6
1.2k
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
450
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
190
Transcript
RESEARCH IMPROVING DATA GATHERING & Luca Matteis
What is Research?
"In the broadest sense of the word, the definition of
research includes any gathering of data, information and facts for the advancement of knowledge."
"Research is a process of steps used to collect and
analyze information to increase our understanding of a topic or issue"
Data is essential for research
Where do we get data from? Einstein got his data
from his own experiments and from other peoples experiments Information exchange took weeks if not months
Today we have the internet! Information exchange takes milliseconds Works
much better than anything Einstein had
BUT THERE’S STILL ISSUES
DATA IS SCATTERED ALL OVER THE WEB
http://science.com/paper.... http://newton.com/research... http://national.com/ goo... http://biology.com/ science... http://newscientist.com/ neutrinodiscovery... http:// astronomynow.com/
themoon http://space.com/ november2001 http://science.com/ paper.... http://newton.com/research... http://science.com/paper.... http://space.com/astro... http://space.com/astro... http://space.com/astro... http://science.com/paper....
Information that can be extremely valuable, lives somewhere online and
we don’t know it because we can’t find it
EVEN WITH GOOGLE, IT’S STILL HARD TO FIND WHAT WE
NEED
Scientific data searching is facilitated if there is a central
repository or data bank
http://science.com/paper.... http://newton.com/research... http://national.com/ goo... http://biology.com/ science... http://newscientist.com/ neutrinodiscovery... http:// astronomynow.com/
themoon http://space.com/ november2001 http://science.com/ paper.... http://newton.com/research... http://science.com/paper.... http://space.com/astro... http://space.com/astro... http://space.com/astro... http://science.com/paper....
When our information is centralized by context, we can more
easily find what we’re looking for
We already have websites that centralize this information
And allow us to find data that Google couldn’t
BUT THERE’S ROOM FOR IMPROVEMENT
How is this data currently being centralized?
Each center sends us their data in the form of
Excel or Access files, through FTP or Email
None
THIS IS AN ENTIRELY MANUAL PROCESS
Is this sustainable?
Is this sustainable? This process needs to be automated
• no human interference • less communication hassles • less
human errors • more accurate data • more data What are the advantages of automating the data exchange process?
How do we automate? Centers no longer have to send
us anything. We get it directly from their website
There’s no secret. Google, hotel sites, flight search engines and
many others do this It is called web scraping
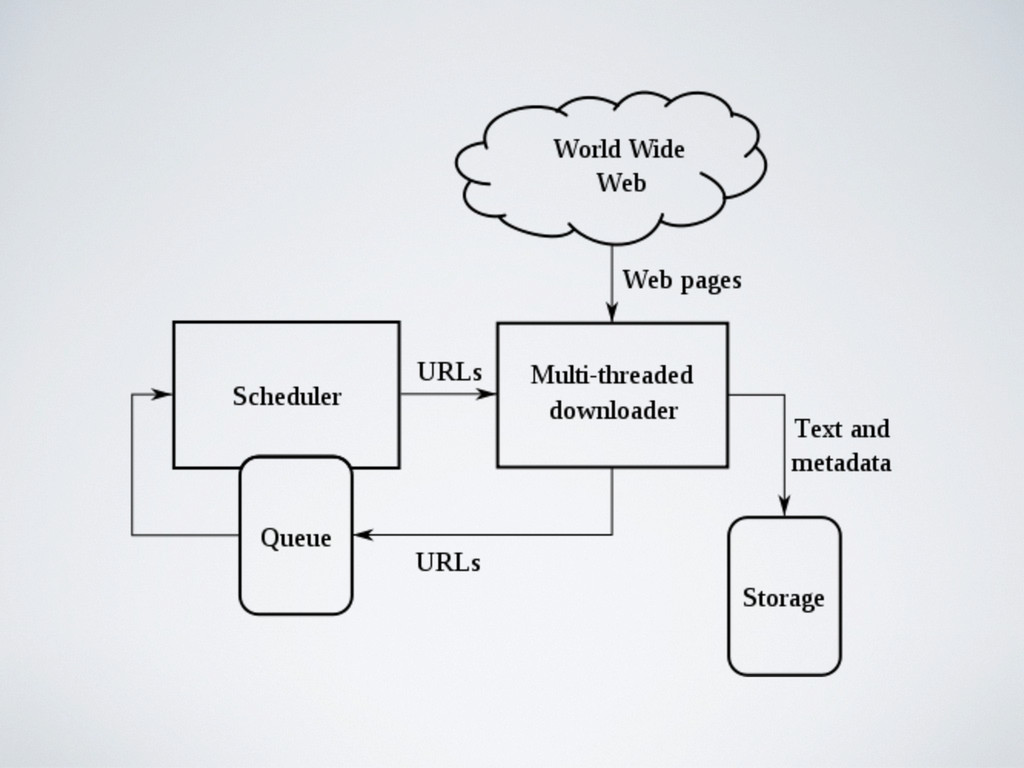
How does it work
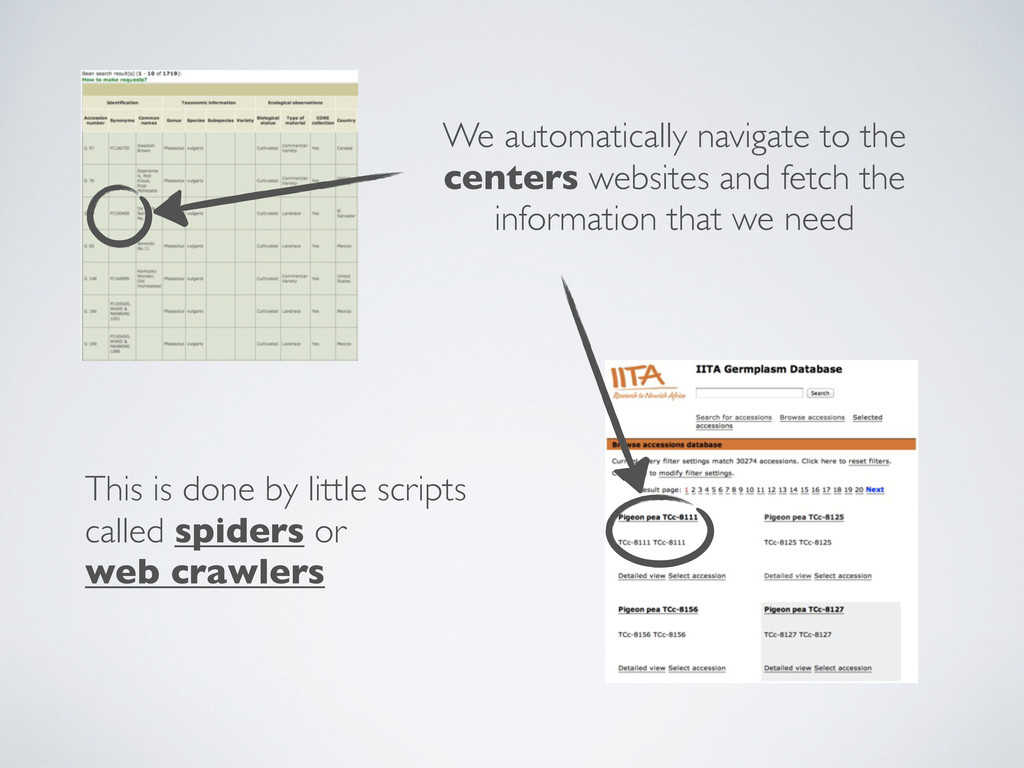
We automatically navigate to the centers websites and fetch the
information that we need
We automatically navigate to the centers websites and fetch the
information that we need This is done by little scripts called spiders or web crawlers
What? Spiders?
“A Web crawler (or spider) is a computer program that
browses the World Wide Web in a methodical, automated manner or in an orderly fashion.”
None
This process allows us to reach more centers and gather
more data
For each center to have a website that displays their
information The main requirement Without a website we wouldn’t be able to automate this exchange
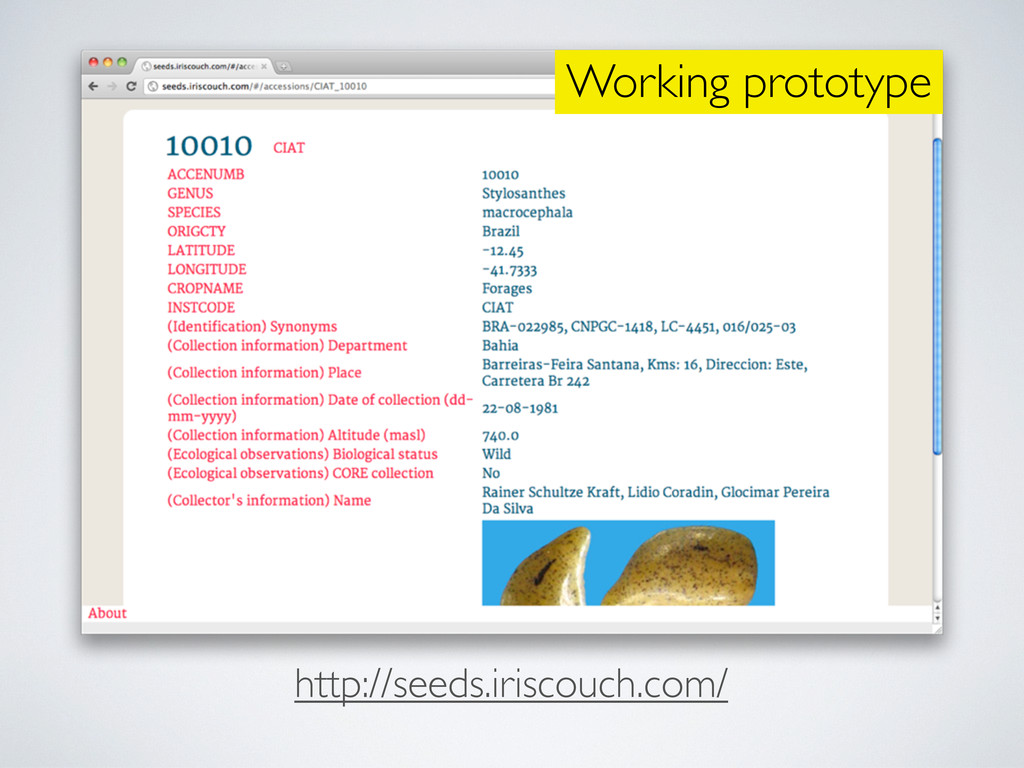
Working prototype http://seeds.iriscouch.com/
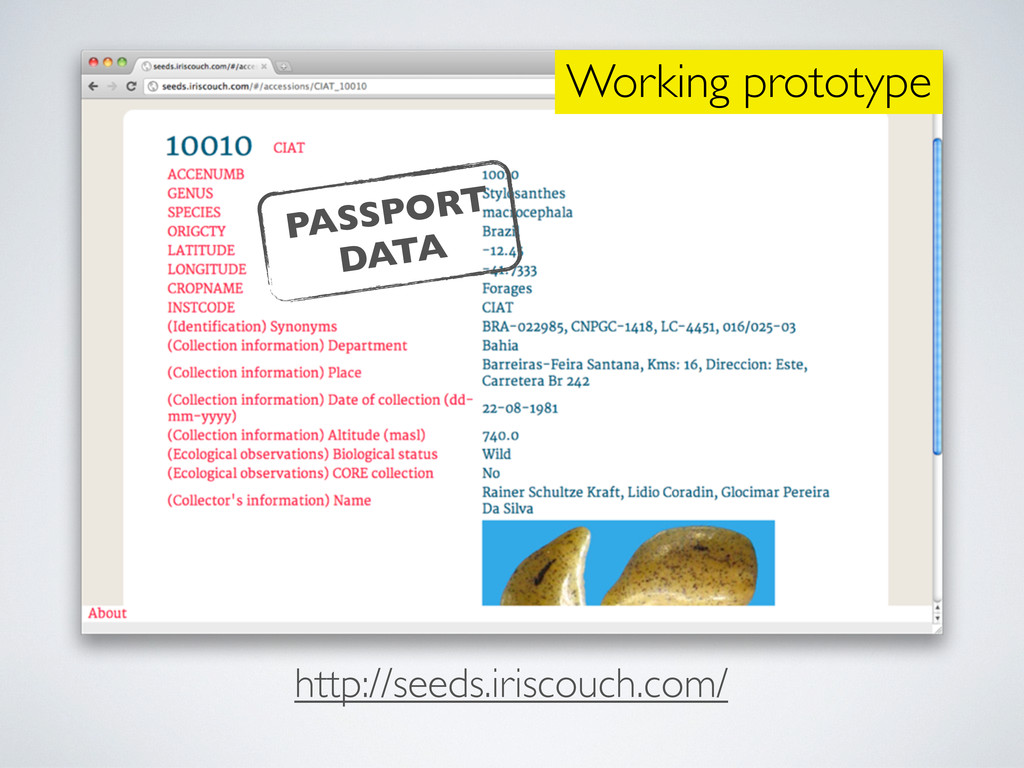
Working prototype http://seeds.iriscouch.com/ PASSPORT DATA
Working prototype http://seeds.iriscouch.com/ PASSPORT DATA CHARACTERIZATION
Working prototype http://seeds.iriscouch.com/ PASSPORT DATA CHARACTERIZATION OTHER...
RECAP
RECAP Automation of the data exchange process is the only
sustainable solution
RECAP Automation of the data exchange process is the only
sustainable solution With new technologies, web scraping has become a very reliable system
RECAP Automation of the data exchange process is the only
sustainable solution With new technologies, web scraping has become a very reliable system The process is modular and will allow us to plug-in systems such as GRIN-Global
THANK YOU
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}