Après les 2 précédents ateliers Varnish, c’est au tour d’ElasticSearch de passer entre les mains Ludovic Piot (Oxalide) avec Edouard Fajnzilberg (Kernel42) . Ils ont déroulé le sujet avec les points de vue Syadmin et Dev.
Subject: Oxalide's workshop about an overview of elasticsearch.
Speakers: Edouard Fajnzilberg (Kernel42) and Ludovic Piot (Oxalide)
Language: french
Video capture: https://youtu.be/3bPoeVoUdFI
Main topics:
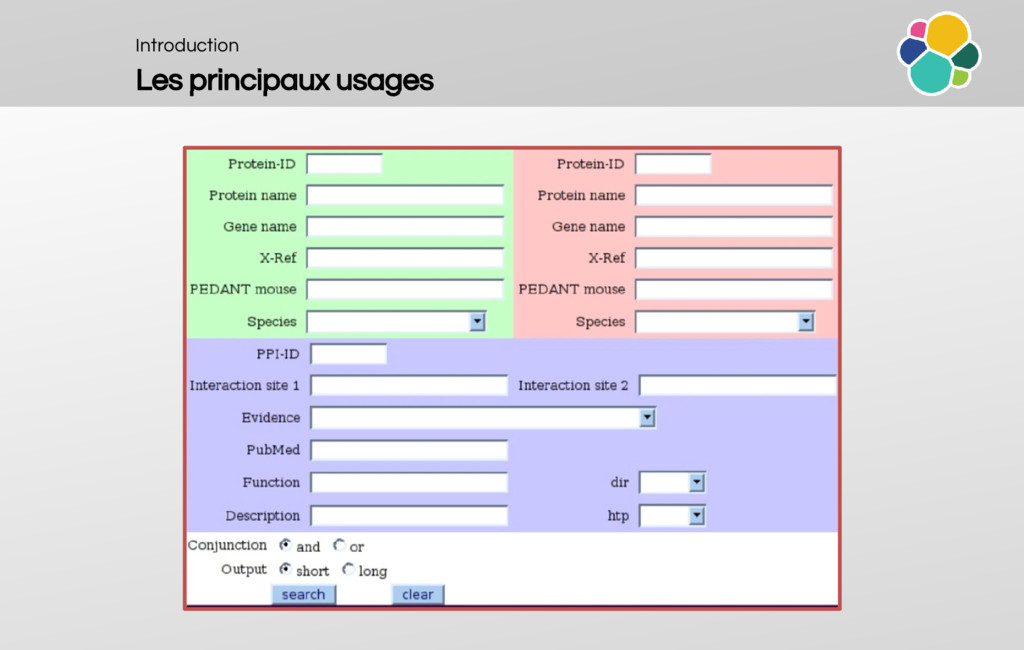
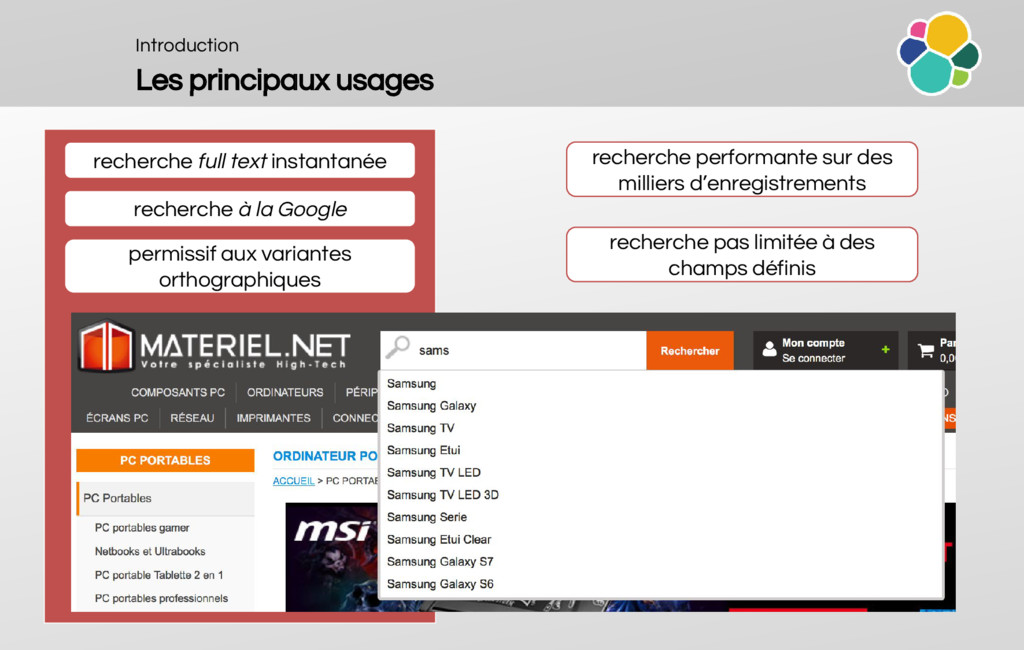
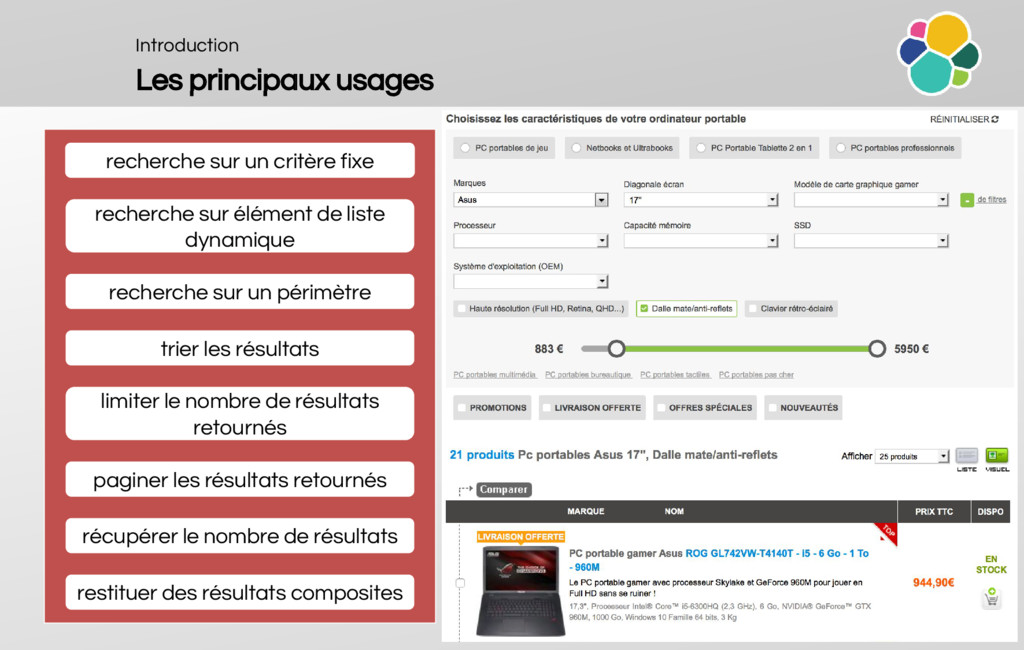
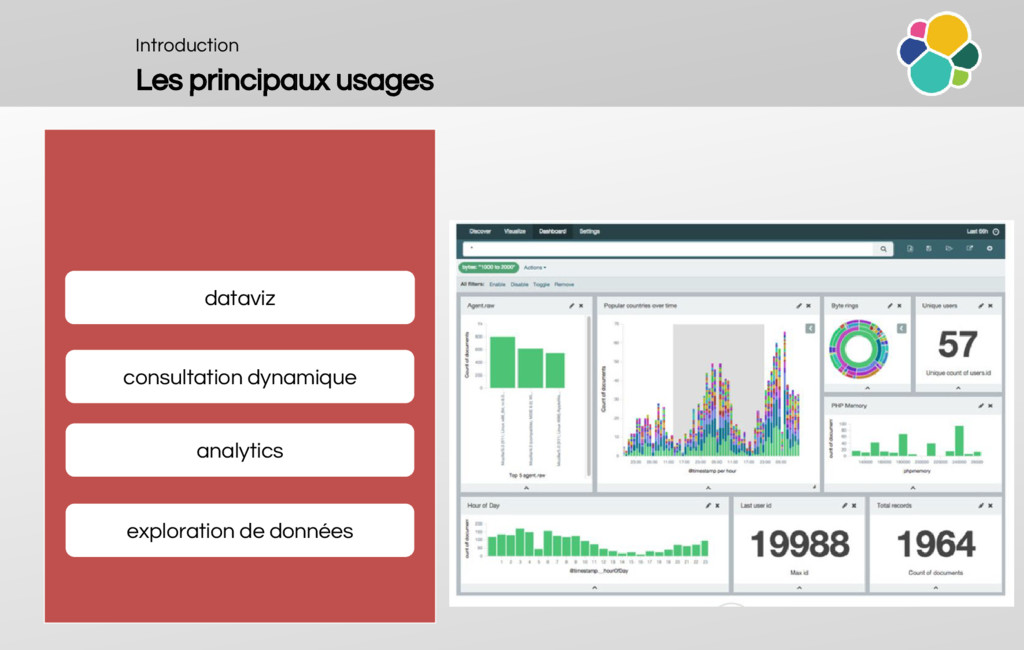
When do we use elasticsearch?
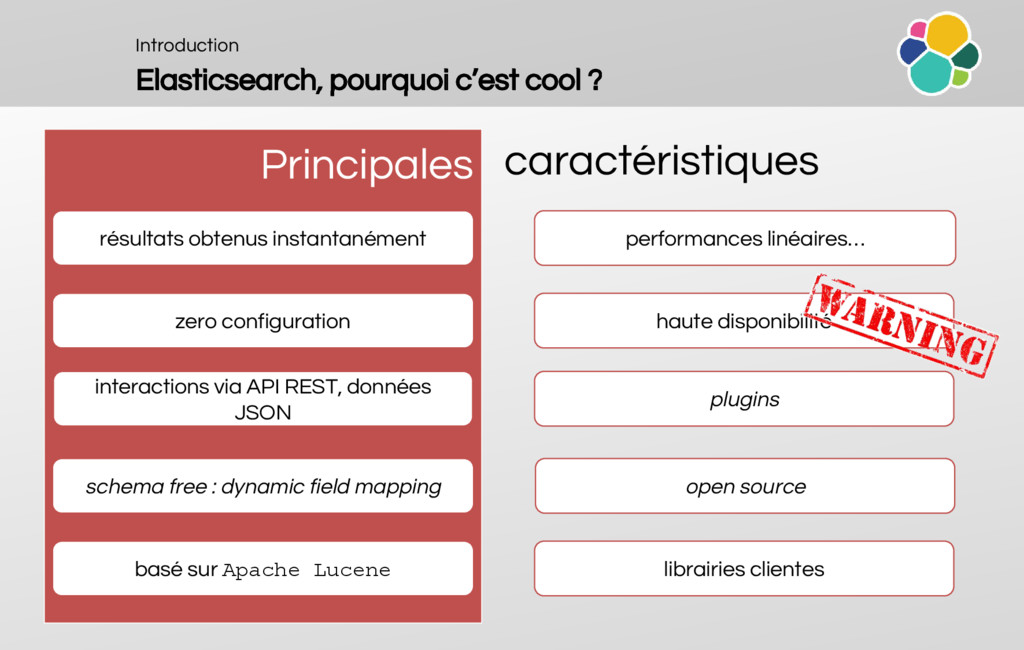
Why is it cool?
Introduction to Head plugin
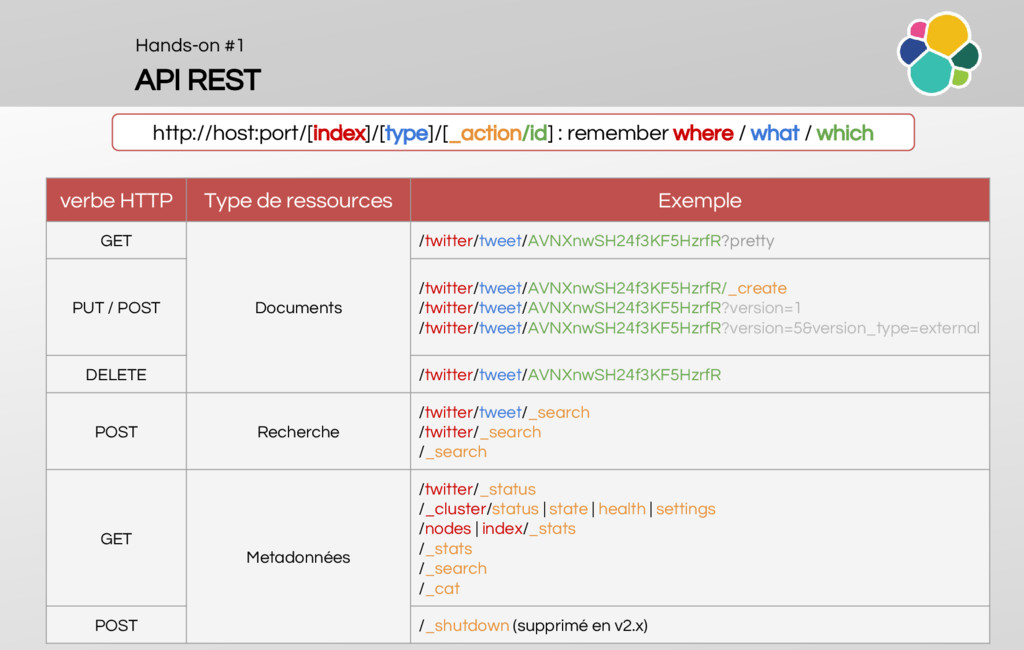
Introduction to the REST API
Introduction to the Query DSL and the JSON document
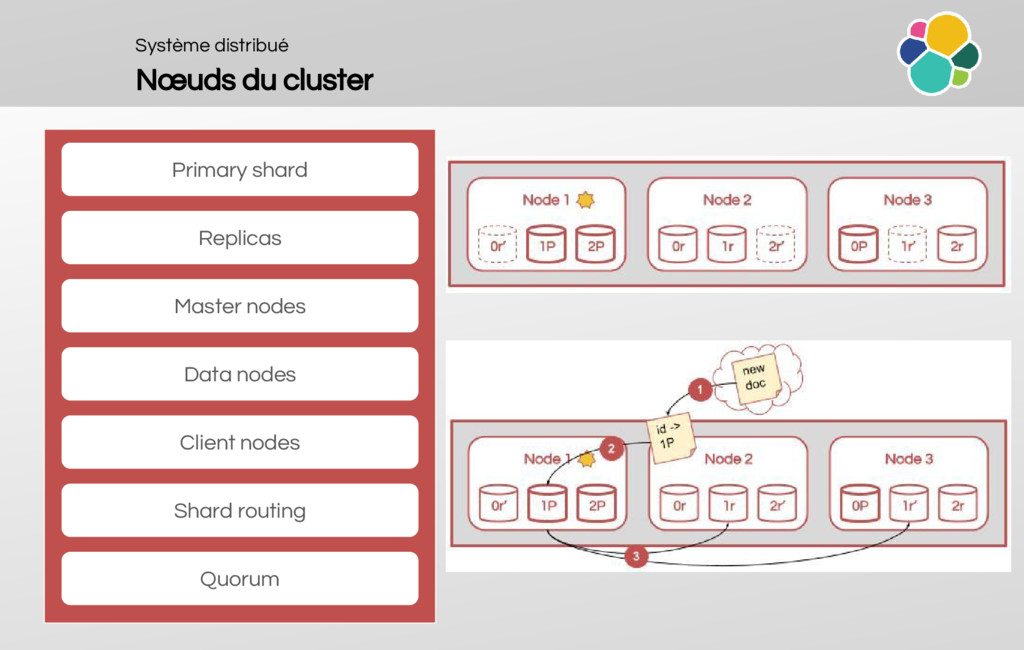
How to configure a cluster?
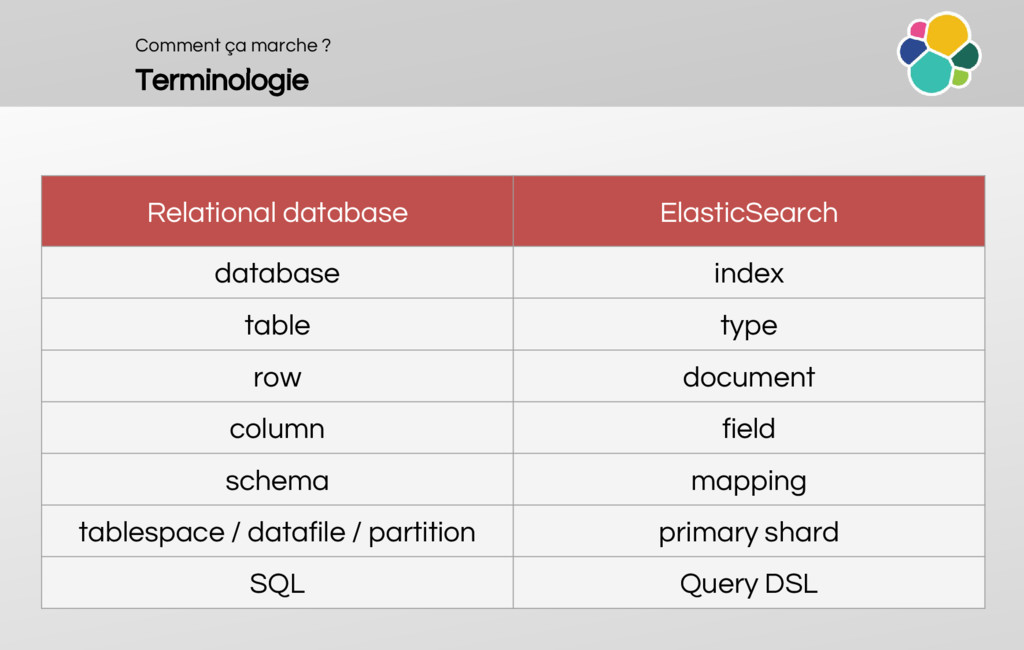
How does it compare to a SGBD-R?
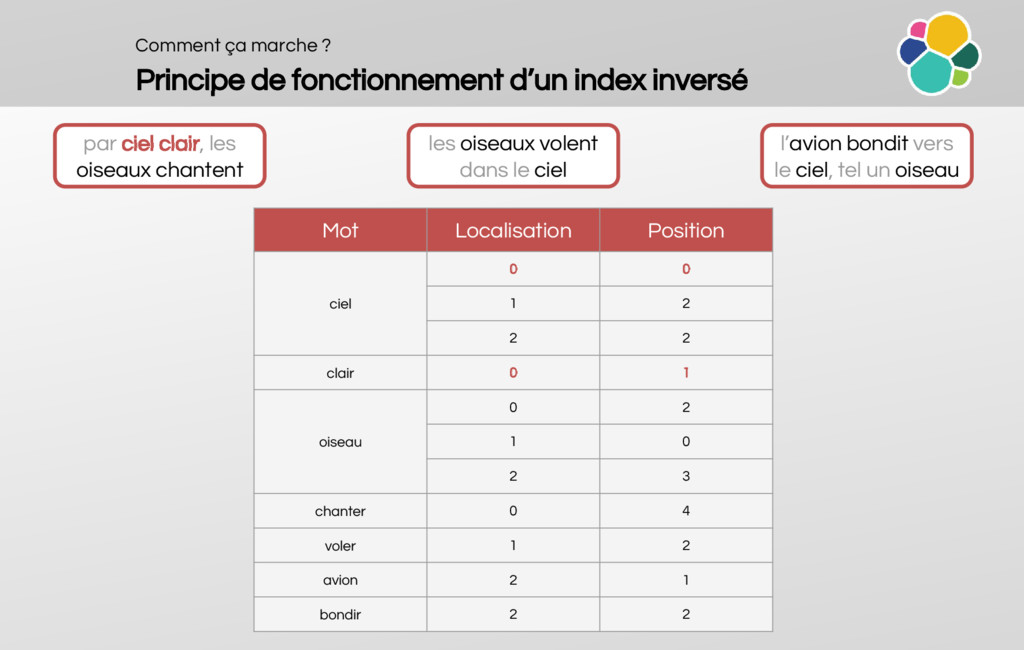
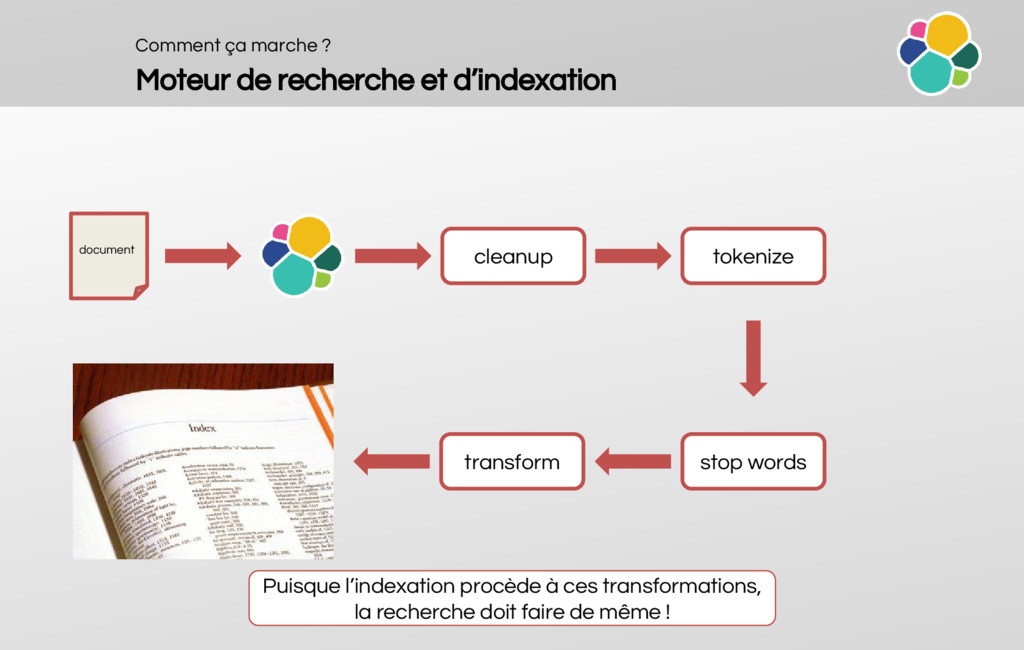
How does a reversed-index work?
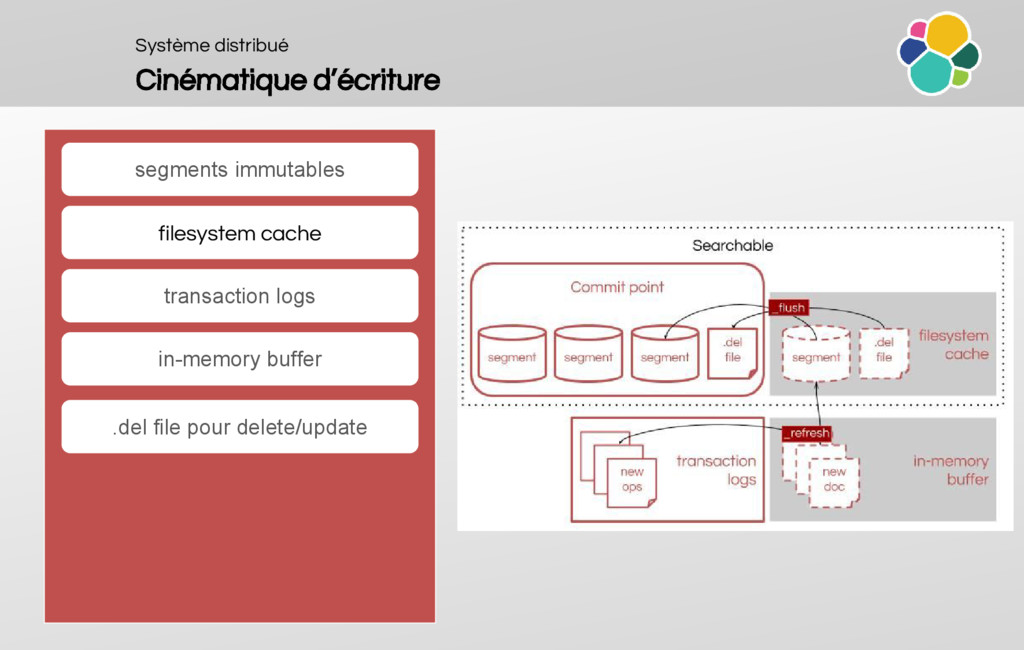
An explaination of Lucene Segments
An explaination of the cluster architecture
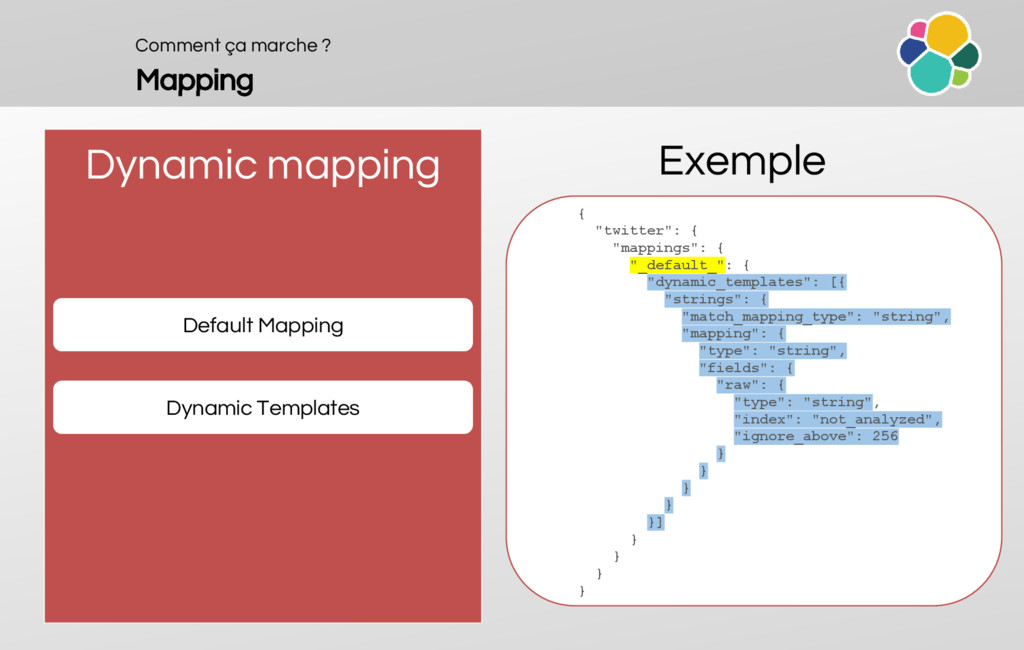
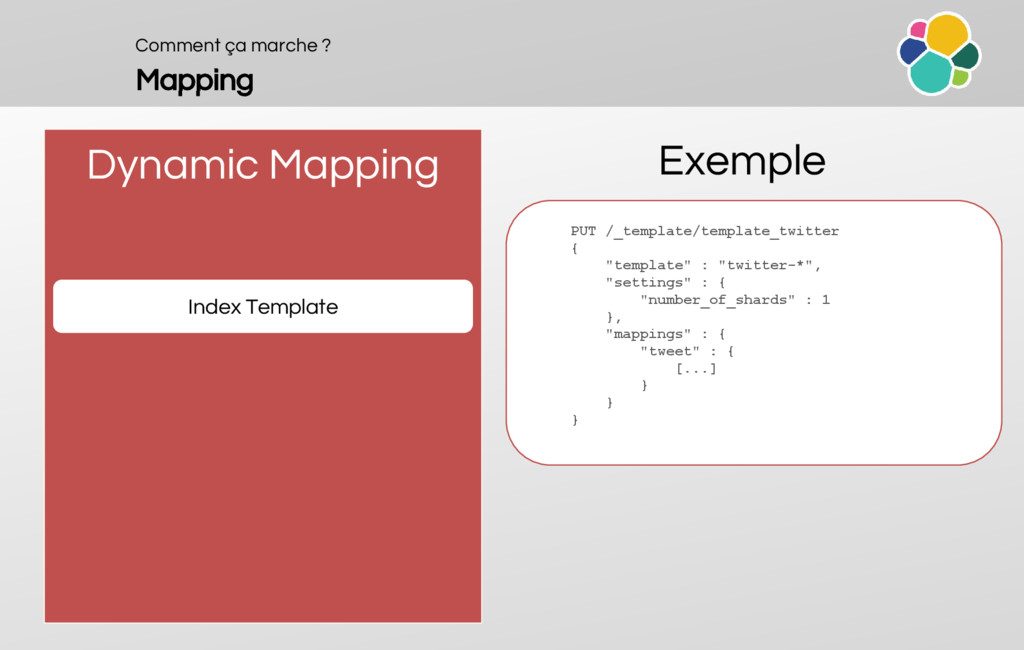
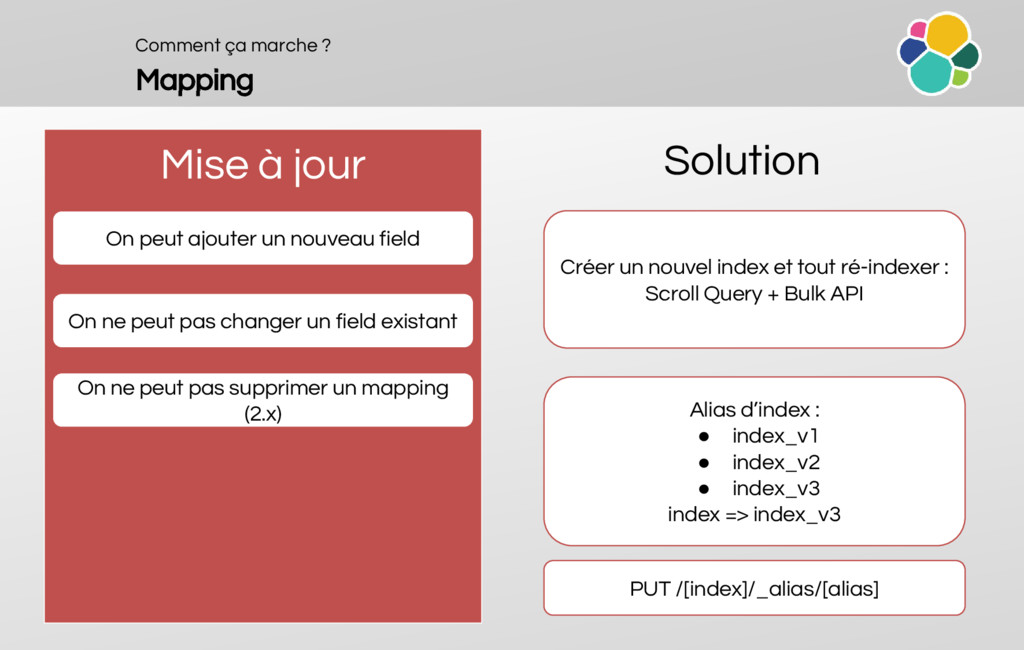
An overview of the mappings (principles, dynamic mapping and templates)
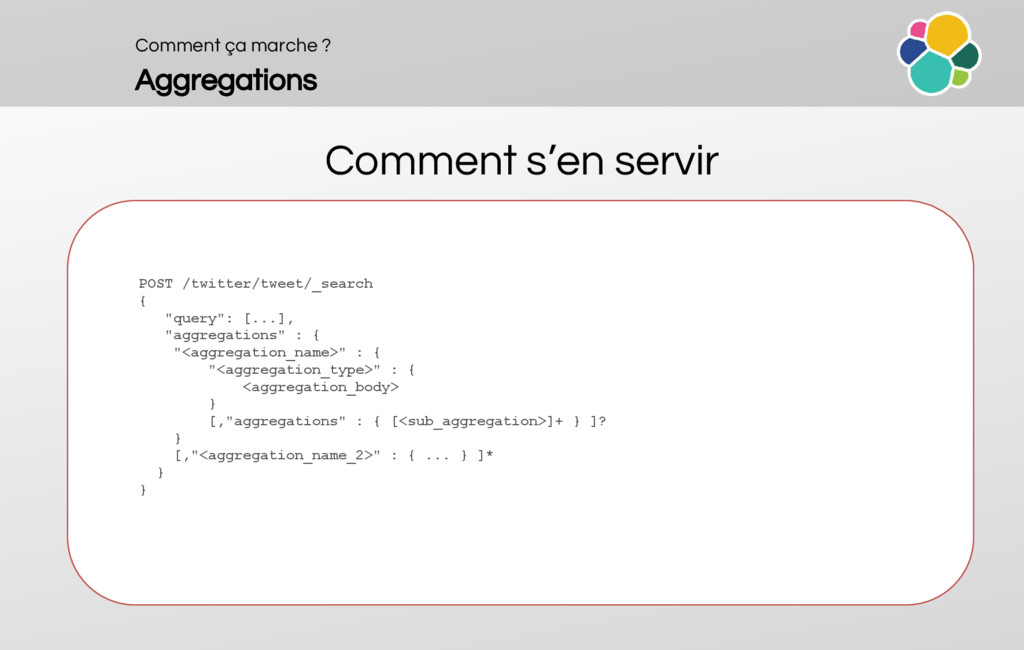
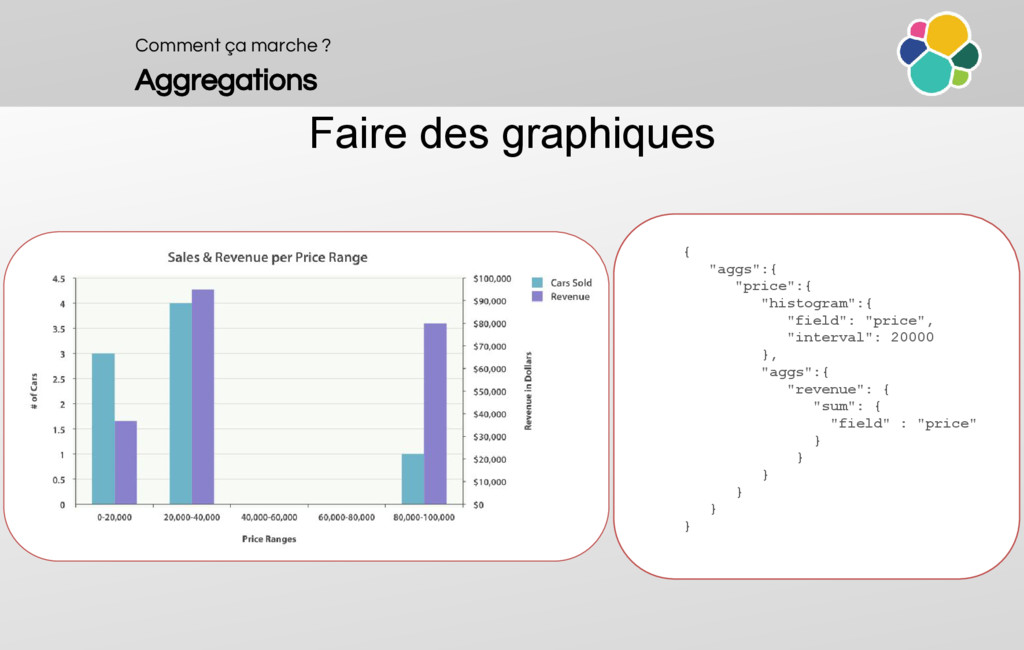
An overview of the aggregations (buckets, metrics, multiple, nestable, sortable, aggregation types, use cases, pipelines)
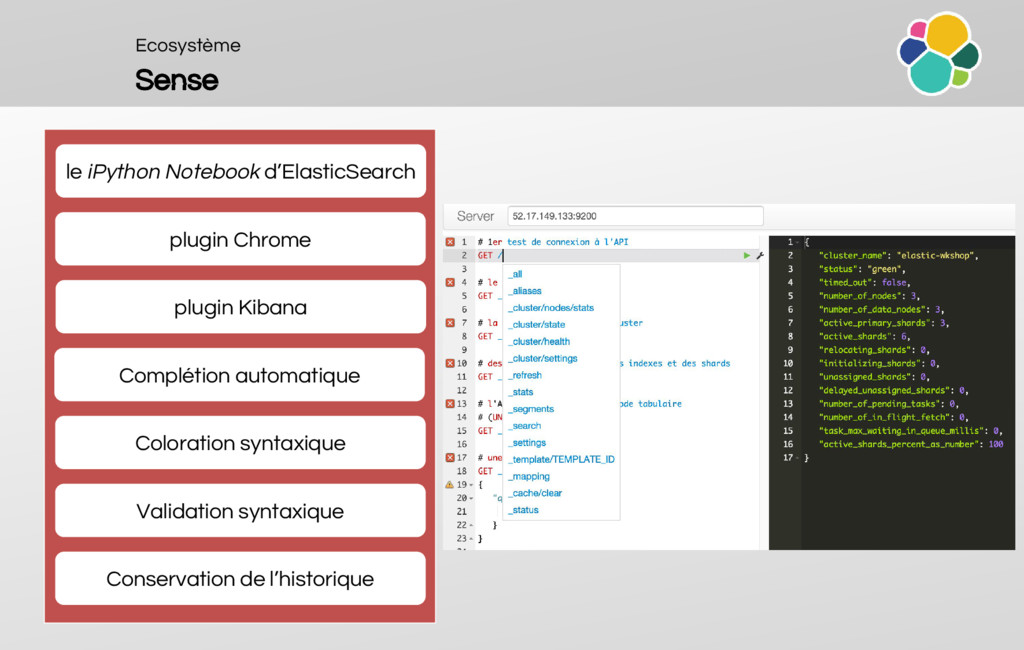
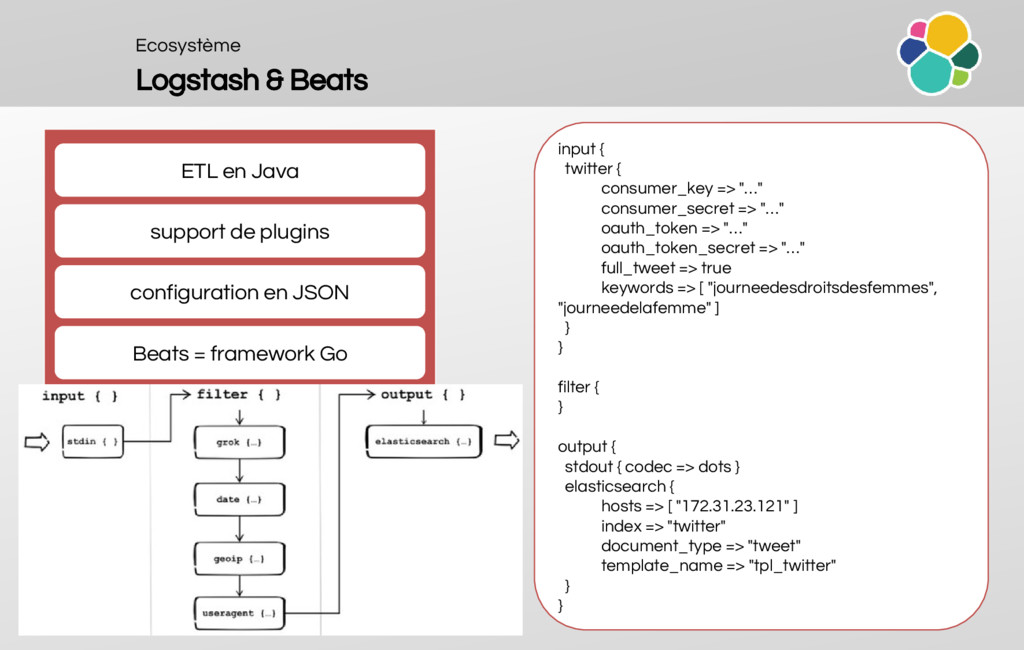
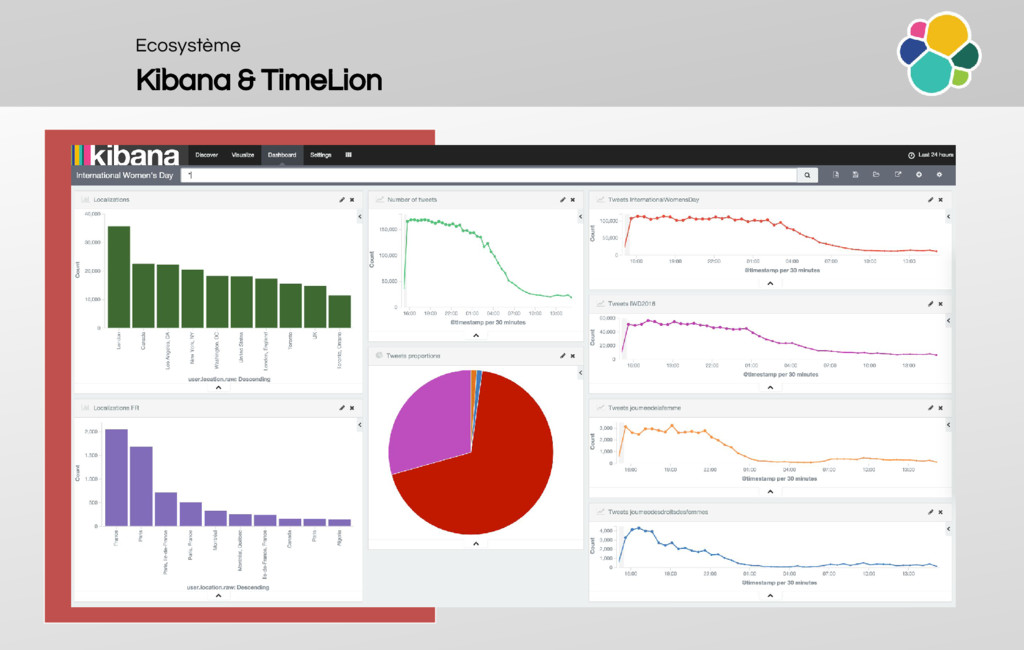
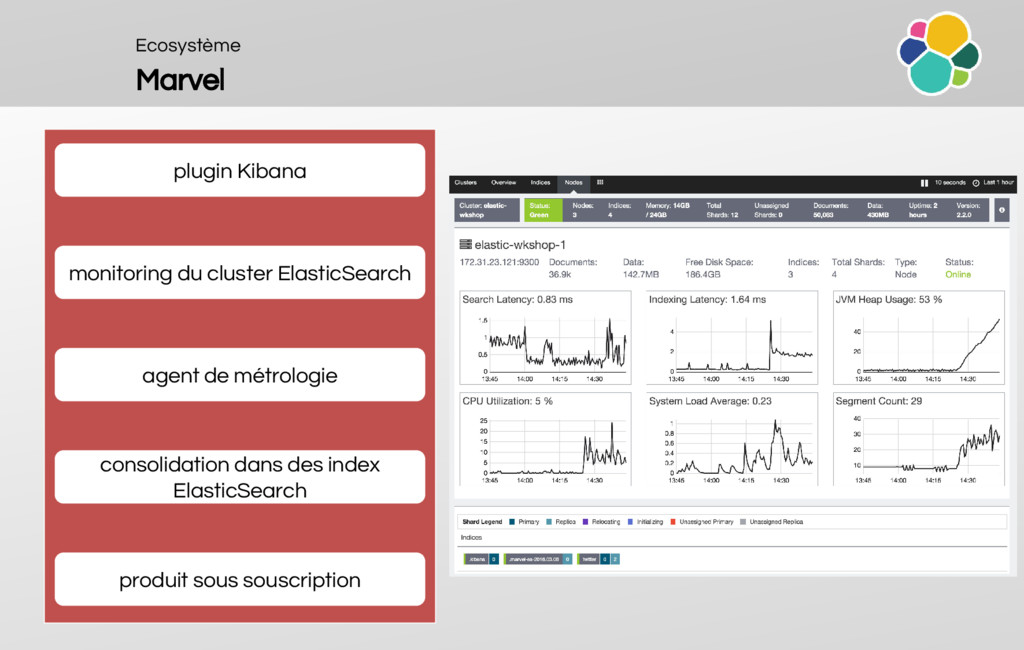
An overview of the ecosystem (Sense, Logstash, Beats, Kibana, TimeLion, Marvel, Watcher, Shield, Head, Kopf, HQ, Inquisitor, BigDesk, SegmentSpy)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Comment ça marche ? Mapping Principes PUT /[index]/_mapping Mapping par](https://files.speakerdeck.com/presentations/972a0fa461b44f5eadc2ecc9ffcc1615/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Comment ça marche ? Aggregations Mutiple Exemple { [...], "aggregations":](https://files.speakerdeck.com/presentations/972a0fa461b44f5eadc2ecc9ffcc1615/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}