Oxalide MorningTech #1 - BigData
1er MorningTech @Oxalide, animé par Ludovic Piot (@lpiot), le 15 décembre 2016.
Pour cette 1ère édition du Morning Tech nous vous proposons une overview sur un des thèmes du moment : le Big Data.
Au delà de ce buzz word nous aborderons :
Les grands concepts
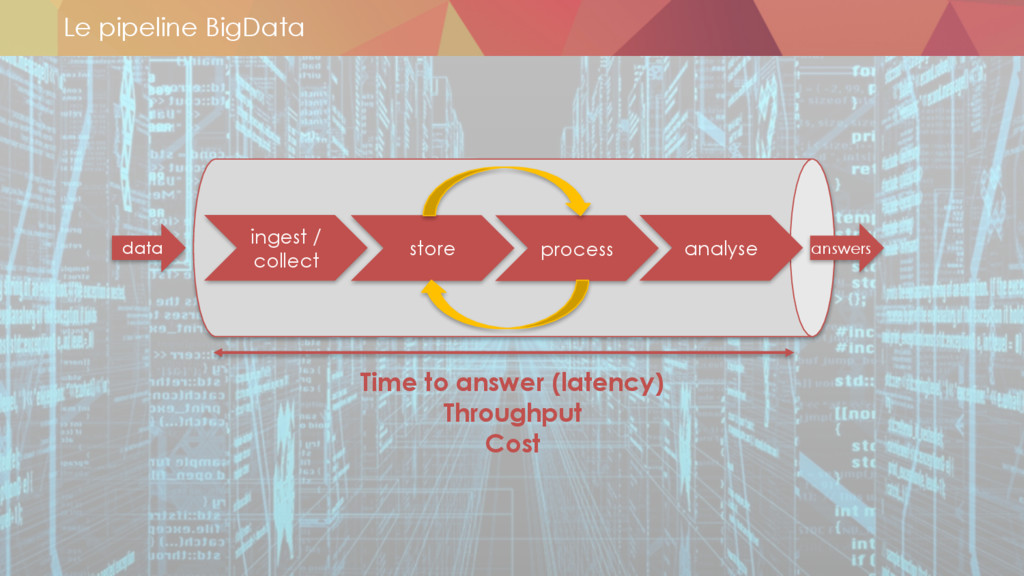
Les étapes clés des projets Big Data et les technologies à utiliser (stockage, ingestion, …)
Les enjeux des architectures Big Data (architecture lambda, …)
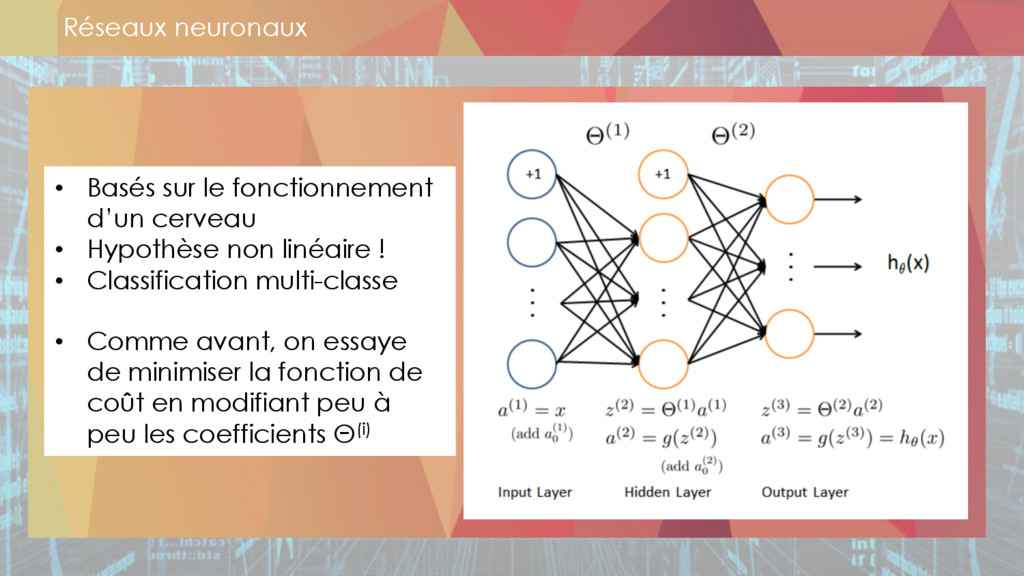
L'intelligence artificielle (machine learning, deep learning, …)
Et nous finirons par un cas d'usage du big data sur AWS autour de l'utilisation des données gyroscopiques de vos internautes mobiles
Subject: Oxalide's 1st MorningTech talk about BigData.
Date: 15-dec-2016
Speakers: Ludovic Piot (@lpiot, @oxalide)
Language: french
Lien SpeakerDeck : https://speakerdeck.com/lpiot/oxalide-morningtech-number-1-bigdata
Lien SlideShare : https://www.slideshare.net/LudovicPiot/oxalide-morningtech-1-bigdata
YouTube Video capture: https://youtu.be/7O85lRzvMY0
Main topics:
* Les grands enjeux du BigData
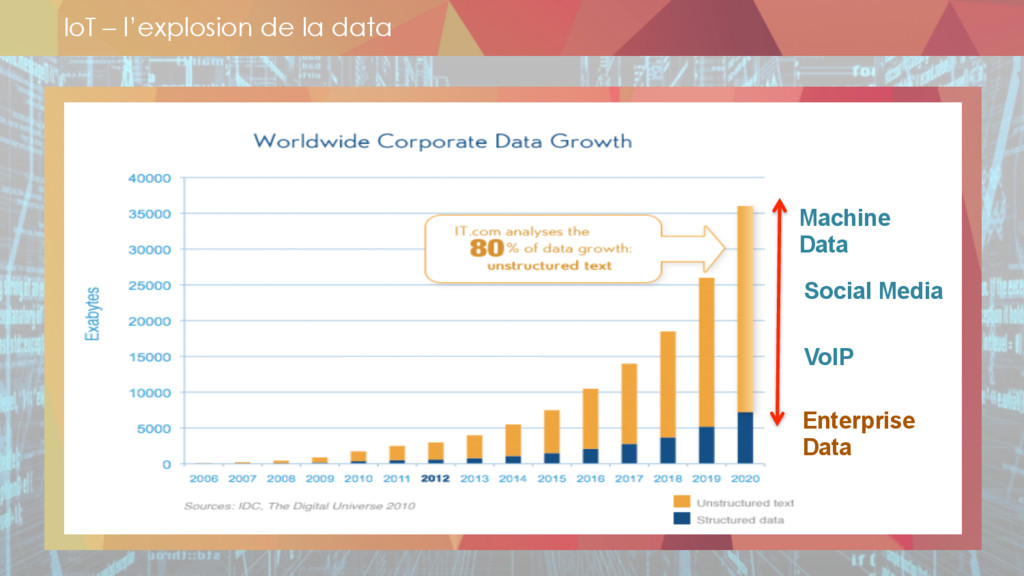
** les 3 V du Gartner : volume, variété, vélocité
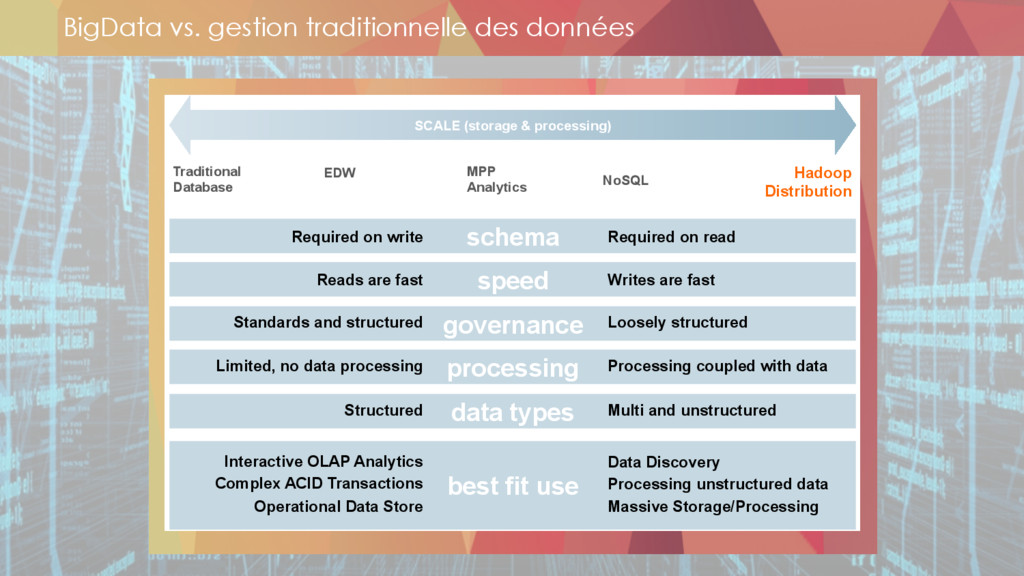
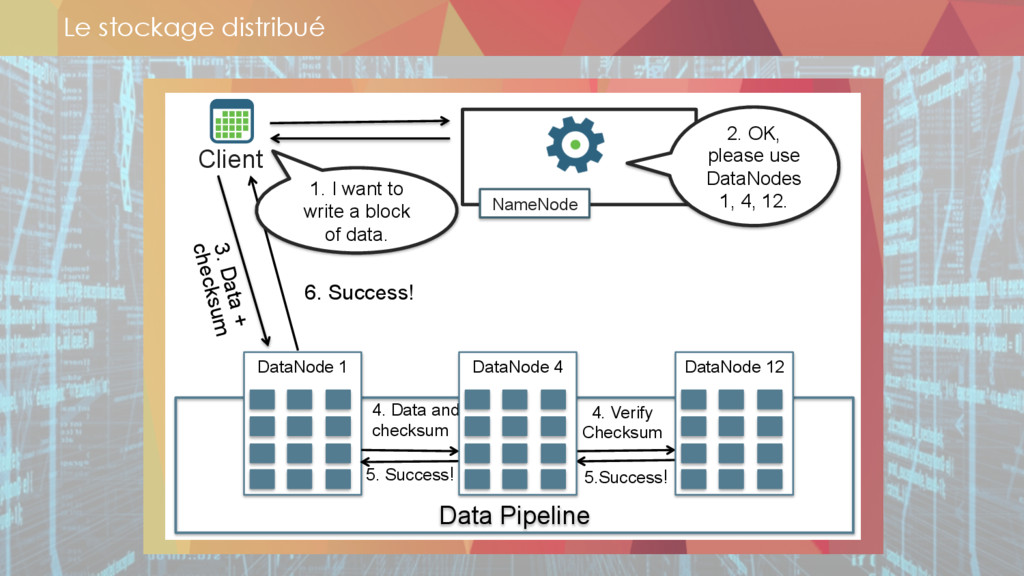
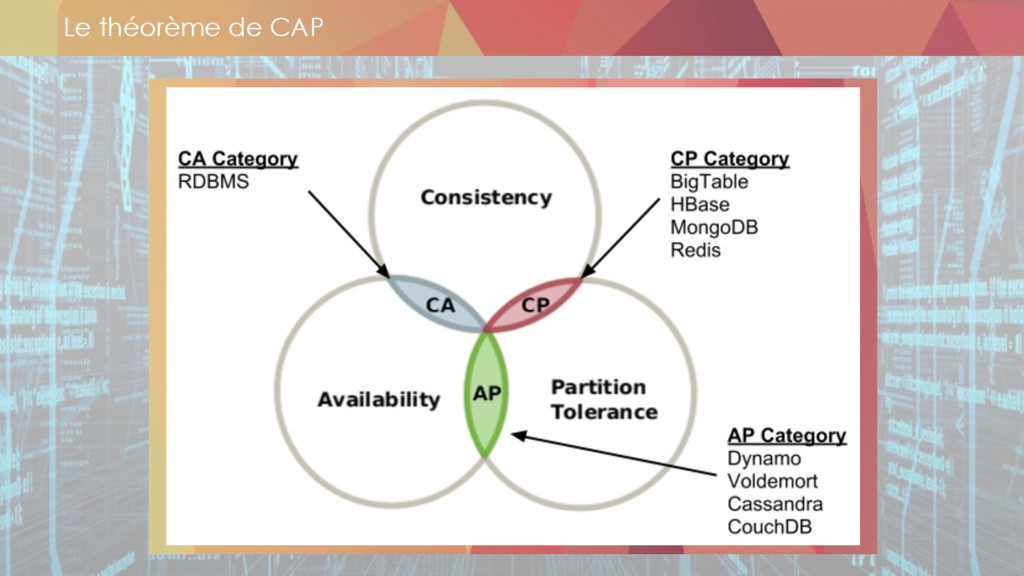
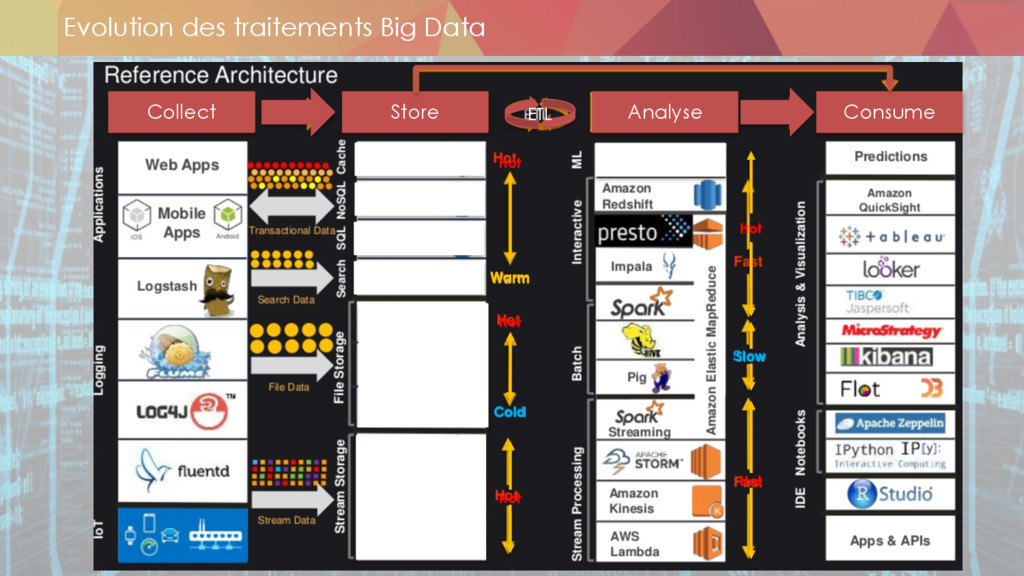
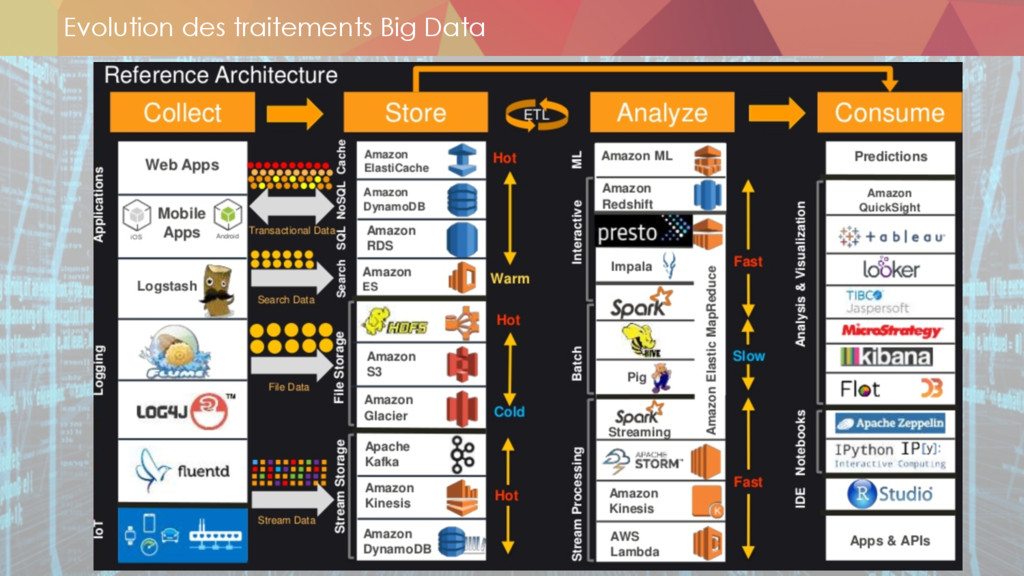
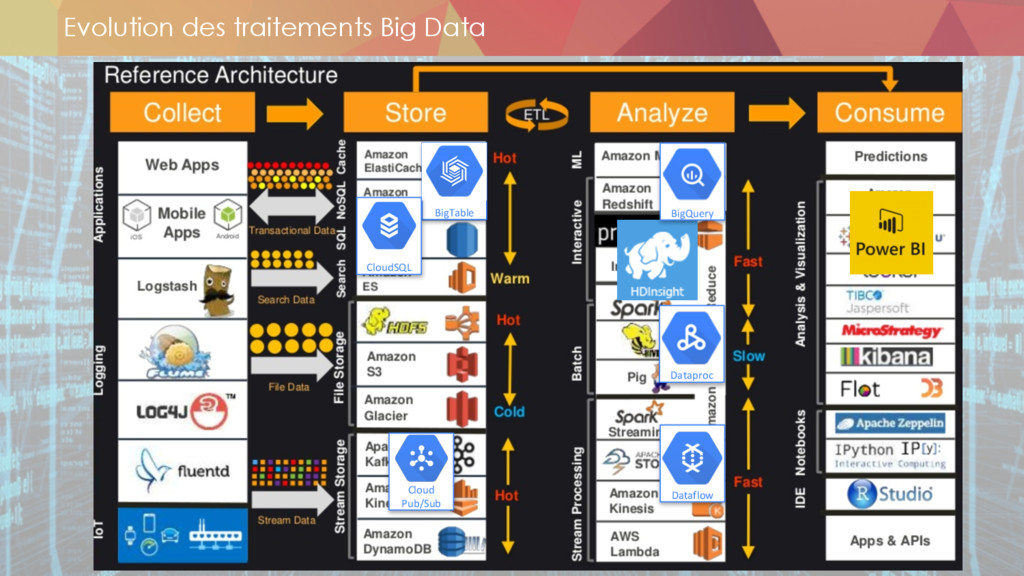
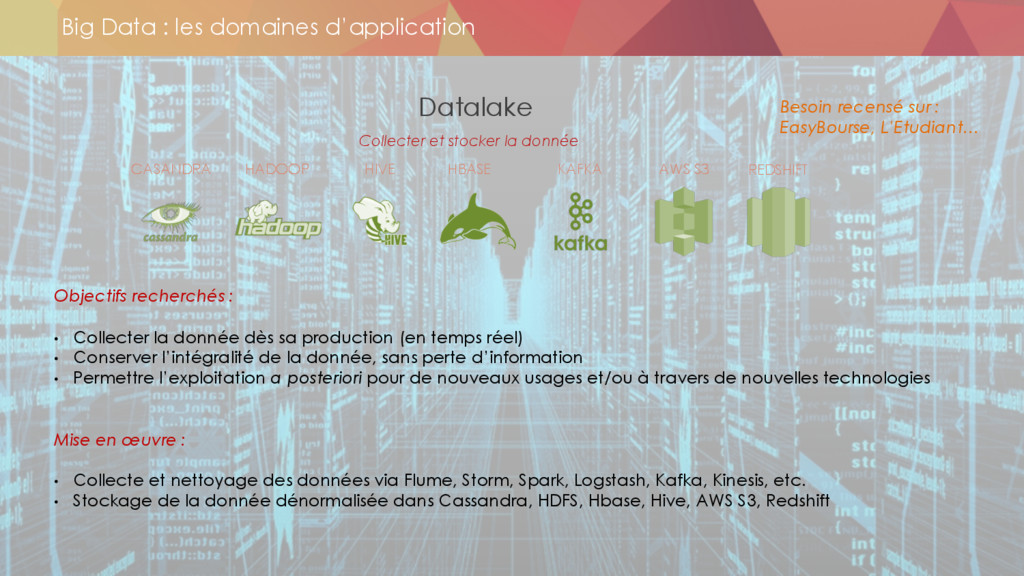
* Le stockage des données
** datalake
** les technos
* L'ingestion des données
** ETL
** datastream
** les technos
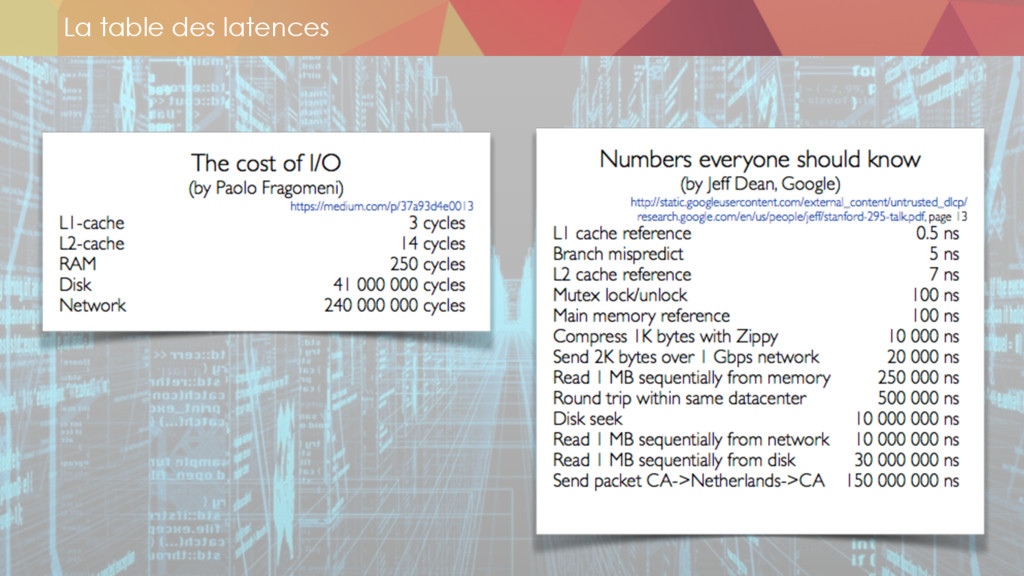
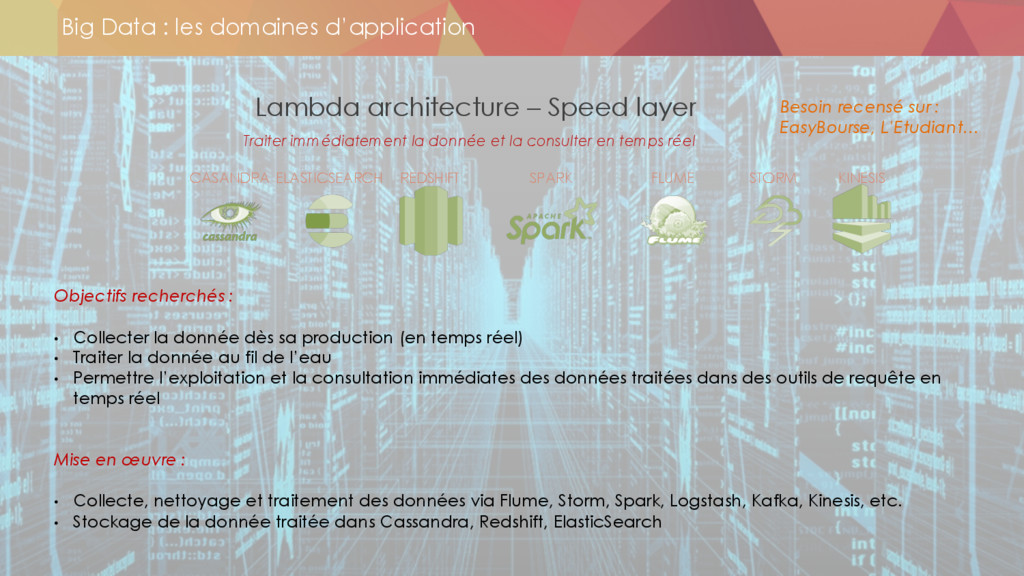
* Les enjeux du compute
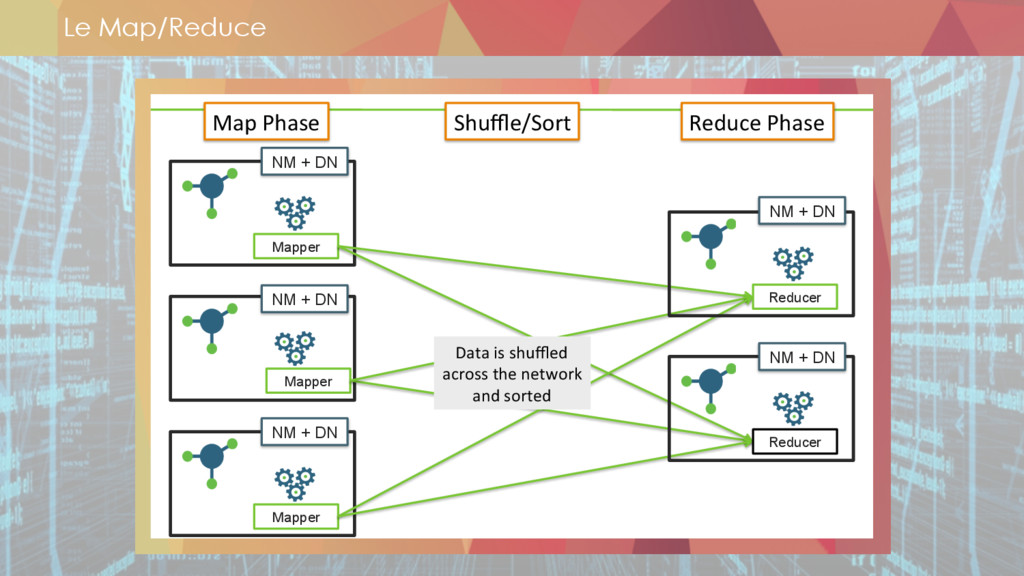
** map-reduce
** spark
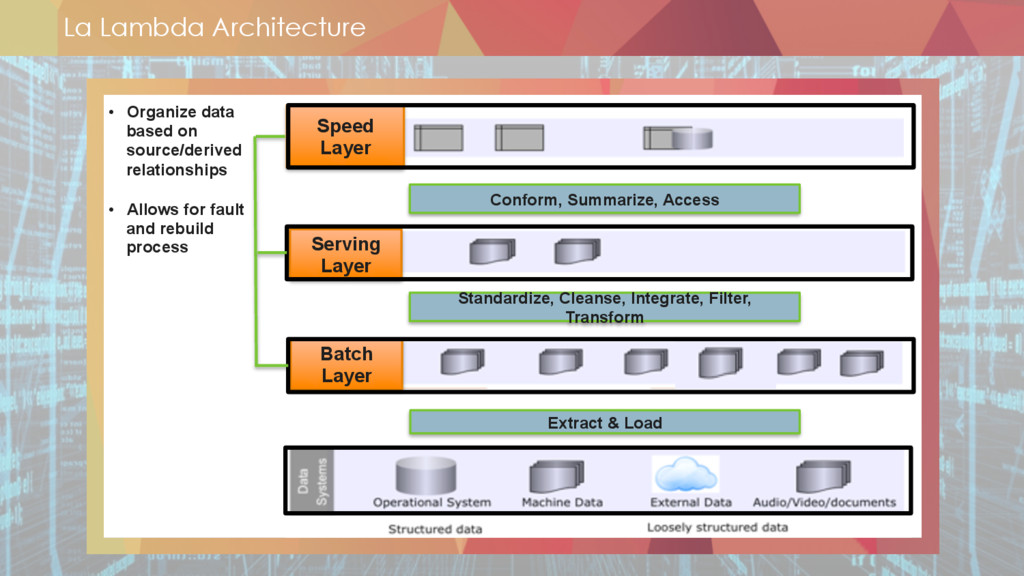
** lambda architecture
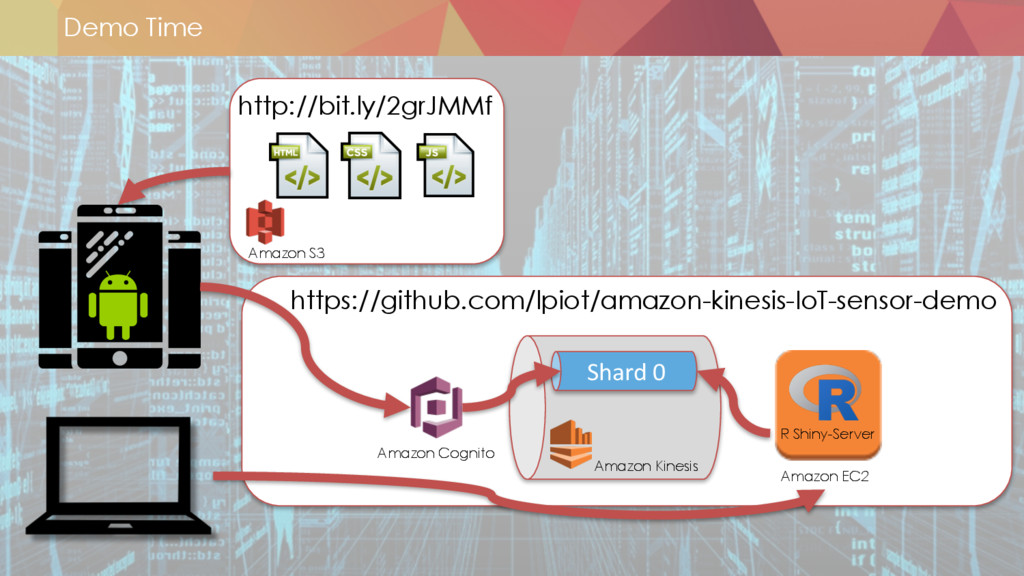
* Démo d'une plateforme BigData sur AWS
* L'intelligence artificielle
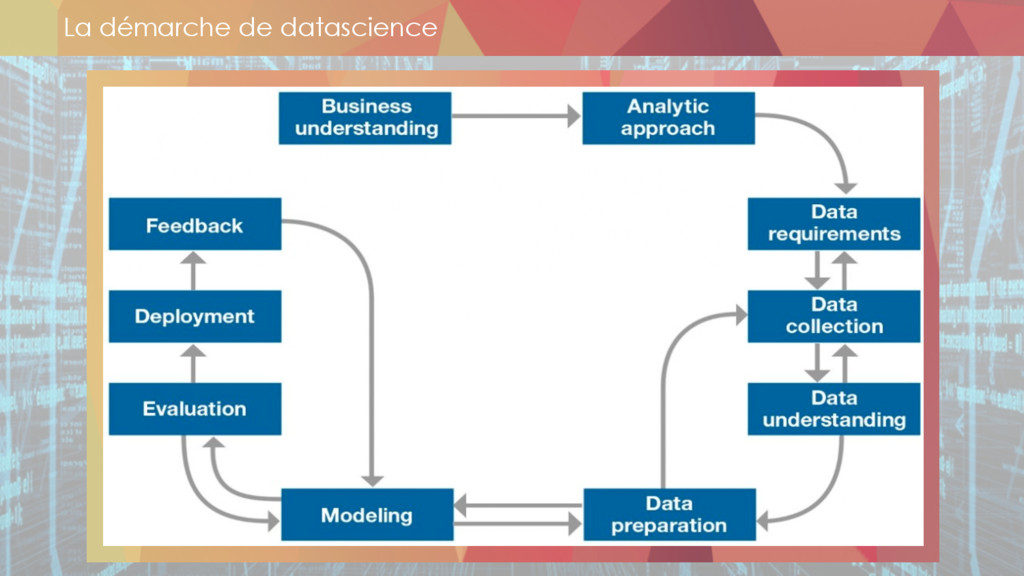
** datascience exploratoire et notebooks,
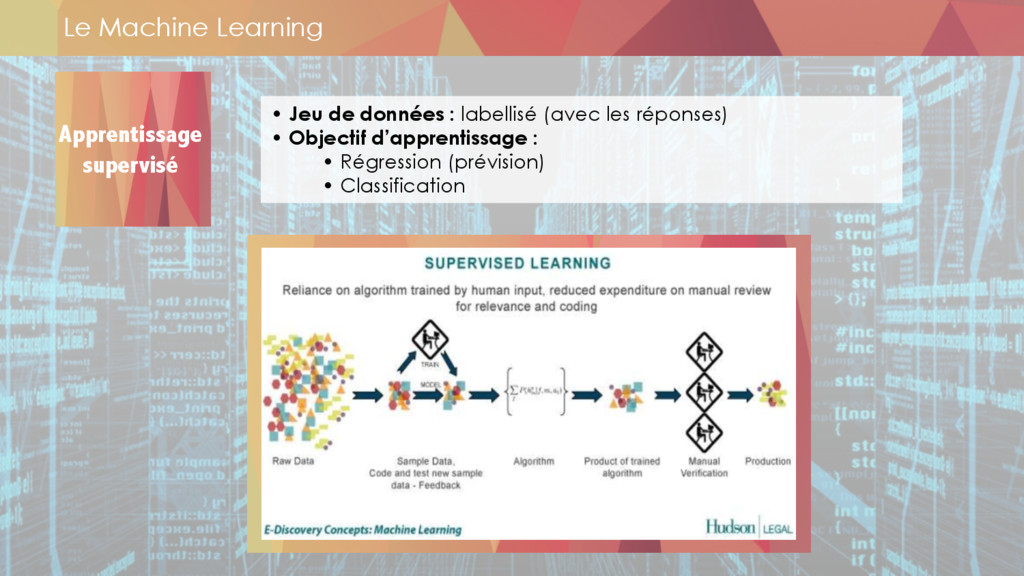
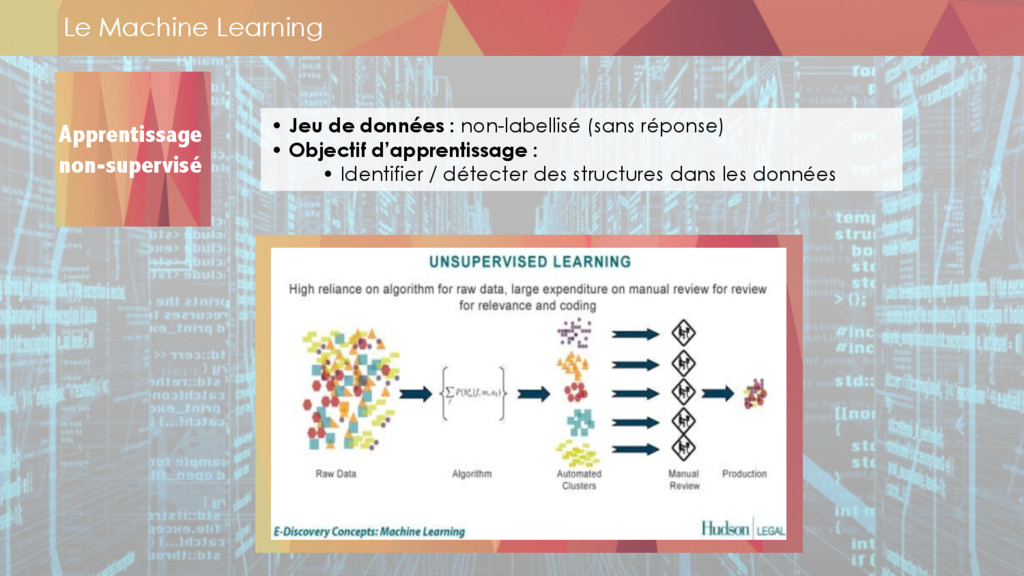
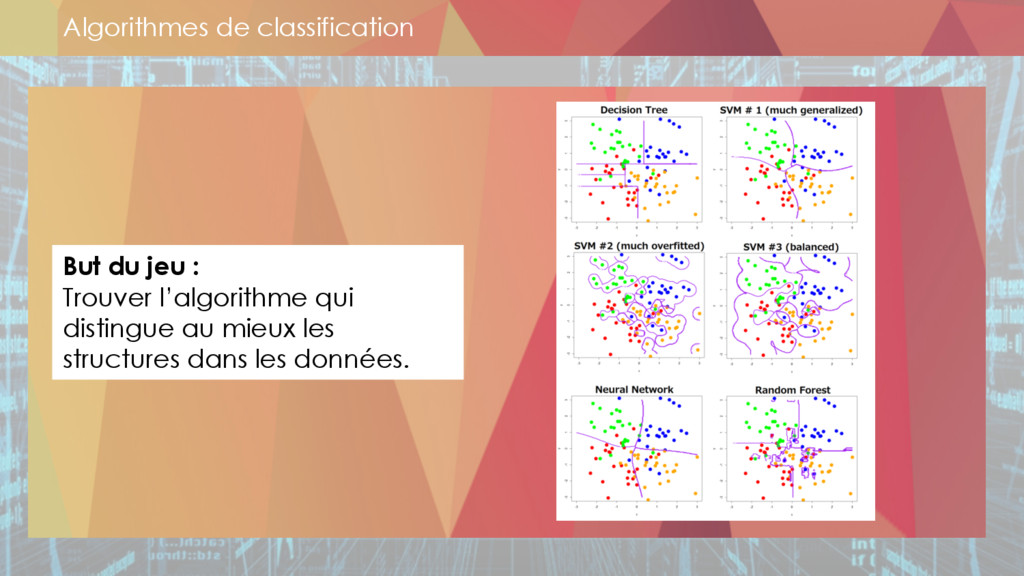
** machine learning,
** deep learning,
** data pipeline
** les technos
* Pour aller plus loin
** La gouvernance des données
** La dataviz
{kind=link}
{kind=link}
{kind=link}
![Oxalide Recrute ! Contactez-nous à [email protected]](https://files.speakerdeck.com/presentations/14f06a946afe494e94dcb66f9244254f/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Sources • [6, 10] : Hortonworks : Operations Management with](https://files.speakerdeck.com/presentations/14f06a946afe494e94dcb66f9244254f/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}