Mit Apache Ignite steht eine hoch-performante, integrierte und verteilte In-Memory Plattform bereit die im Zusammenspiel mit Kubernetes zu wahrer Hochform aufläuft. In dieser Kombination lassen sich flexibel skalierbare In-Memory Computing Systeme elegant realisieren. In diesem Vortrag stellen wir die wesentlichen Features und die Architektur von Apache Ignite vor. Anhand von anschaulichen Beispielen zeigen wir mögliche Use-Cases, wie etwa den Einsatz als Kommunikations-Backbone einer Microservice-Architektur oder als Plattform zur Verarbeitung von kontinuierlichen Event-Daten. Zur Demonstration von Resilienz und Skalierbarkeit werden die Beispiele auf einem tragbaren K8S Cluster ausgeführt.
@data2day @qaware #CloudNativeNerd
![Mario-Leander Reimer [email protected] @LeanderReimer Elegantes In-Memory Computing mit Apache Ignite](https://files.speakerdeck.com/presentations/6d1d7de06f134a05a815ffd3b700fdb2/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
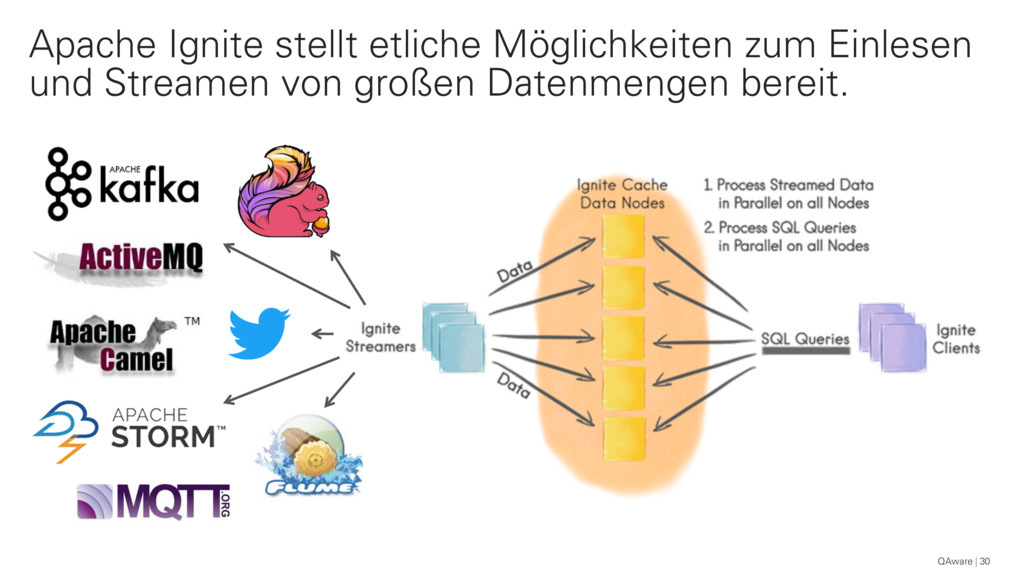{kind=link}
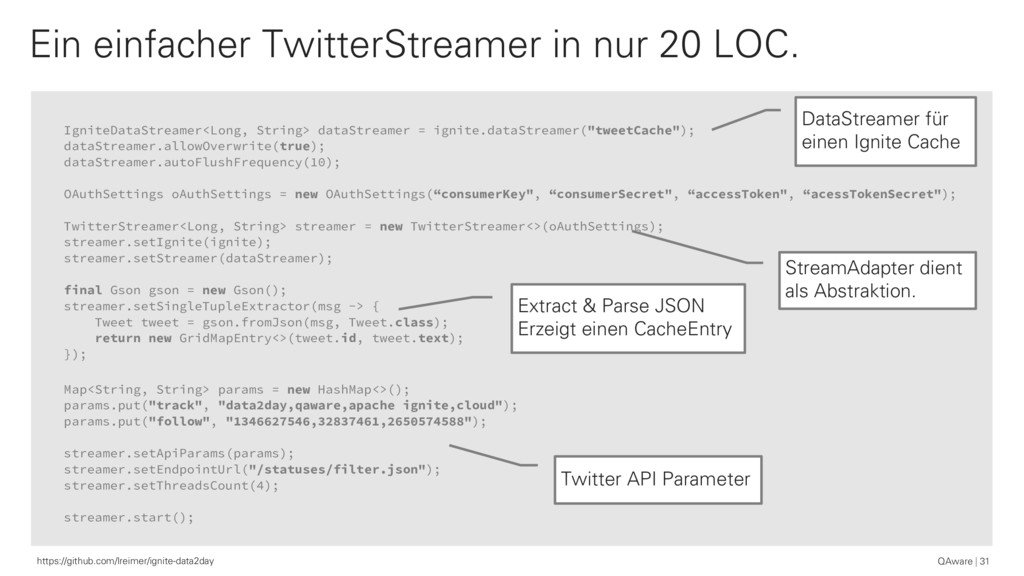{kind=link}
{kind=link}
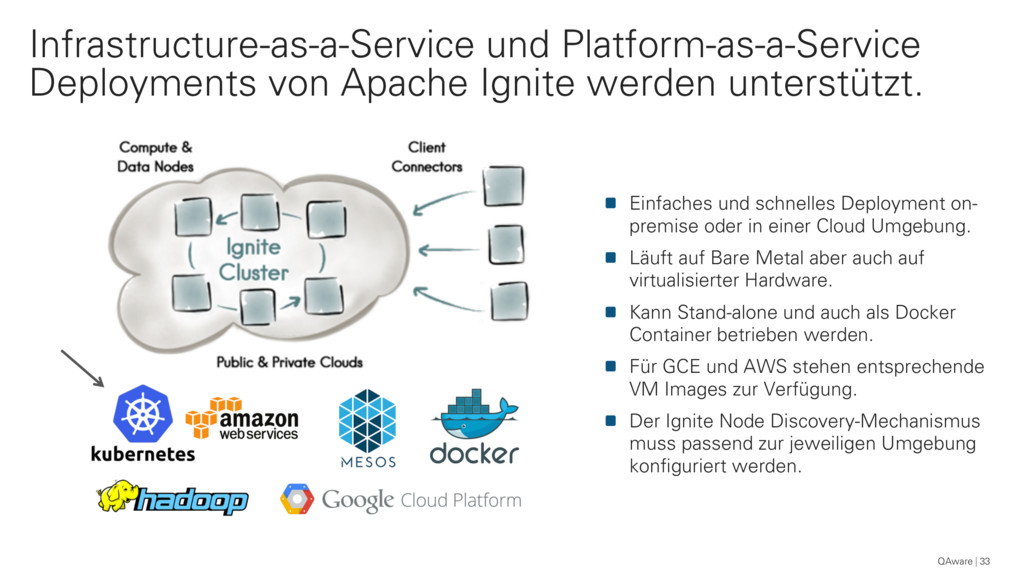{kind=link}
{kind=link}
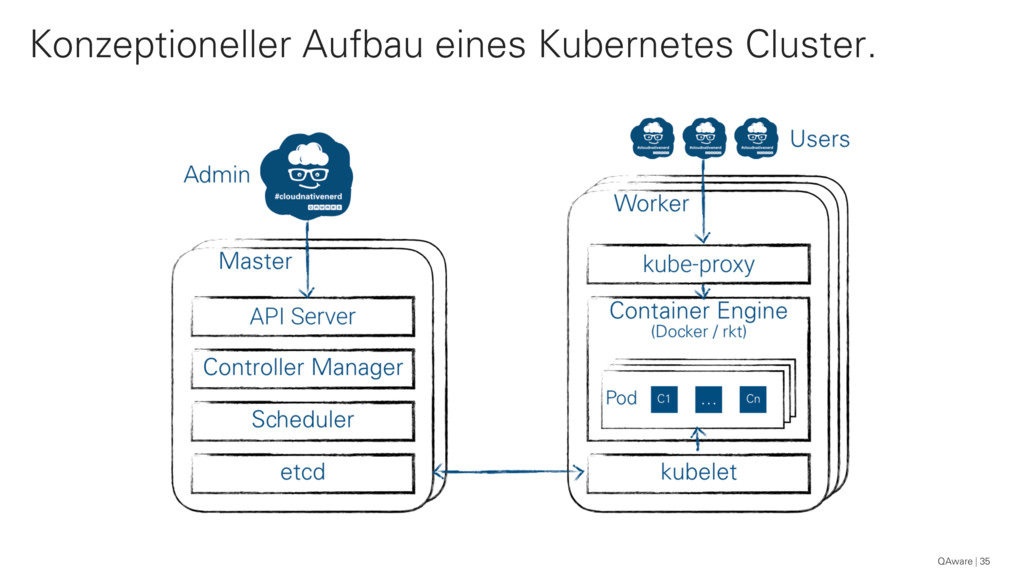{kind=link}
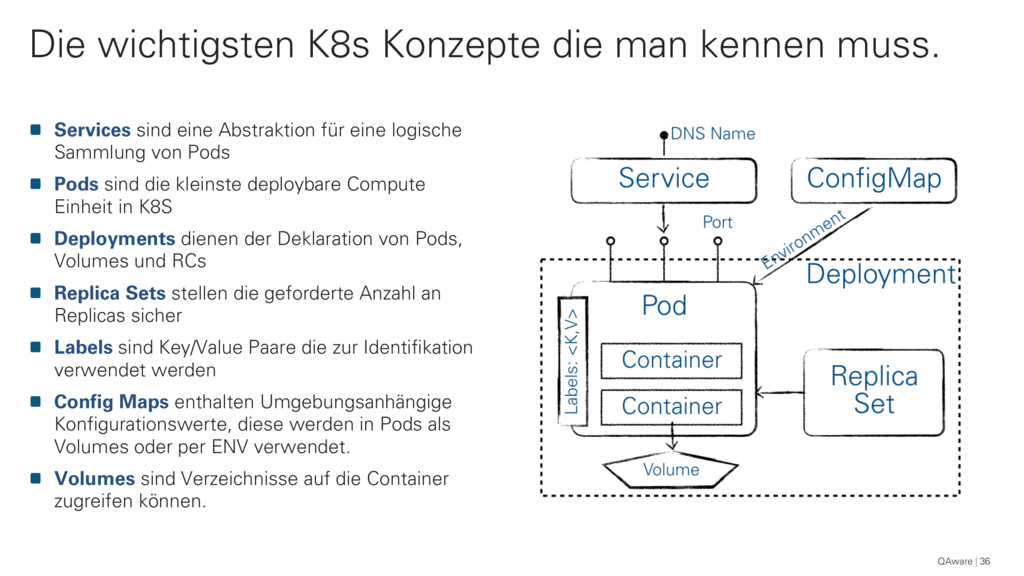{kind=link}
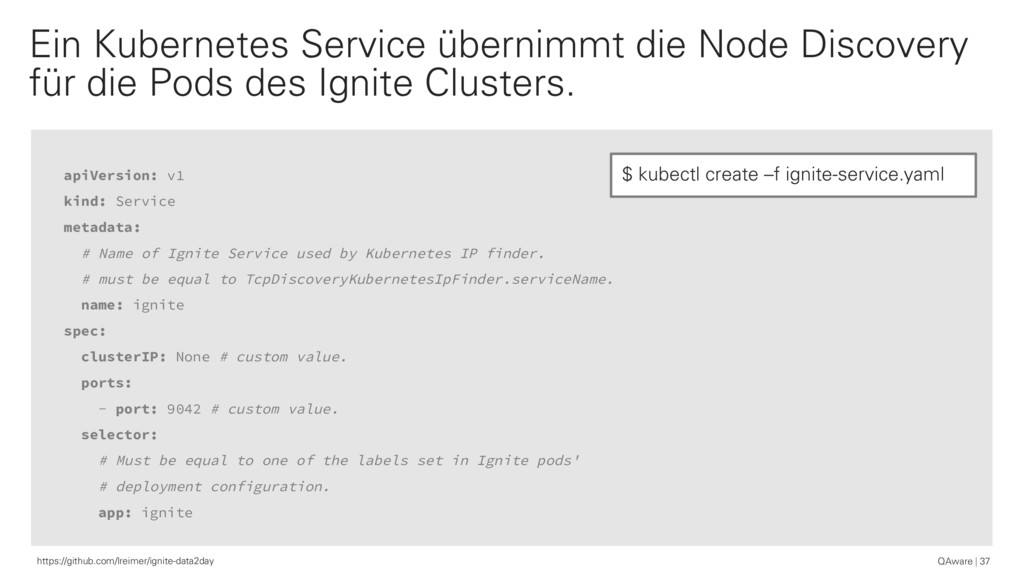{kind=link}
{kind=link}
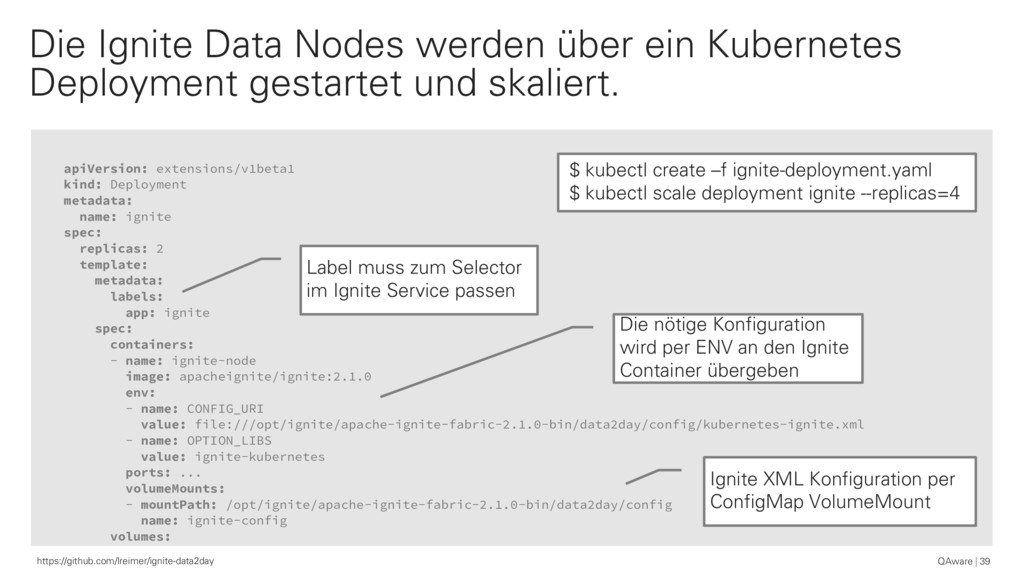{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Mario-Leander Reimer [email protected] @LeanderReimer github.com/lreimer linkedin.com/qaware slideshare.net/qaware twitter.com/qaware xing.com/qaware](https://files.speakerdeck.com/presentations/6d1d7de06f134a05a815ffd3b700fdb2/slide_43.jpg){kind=link}