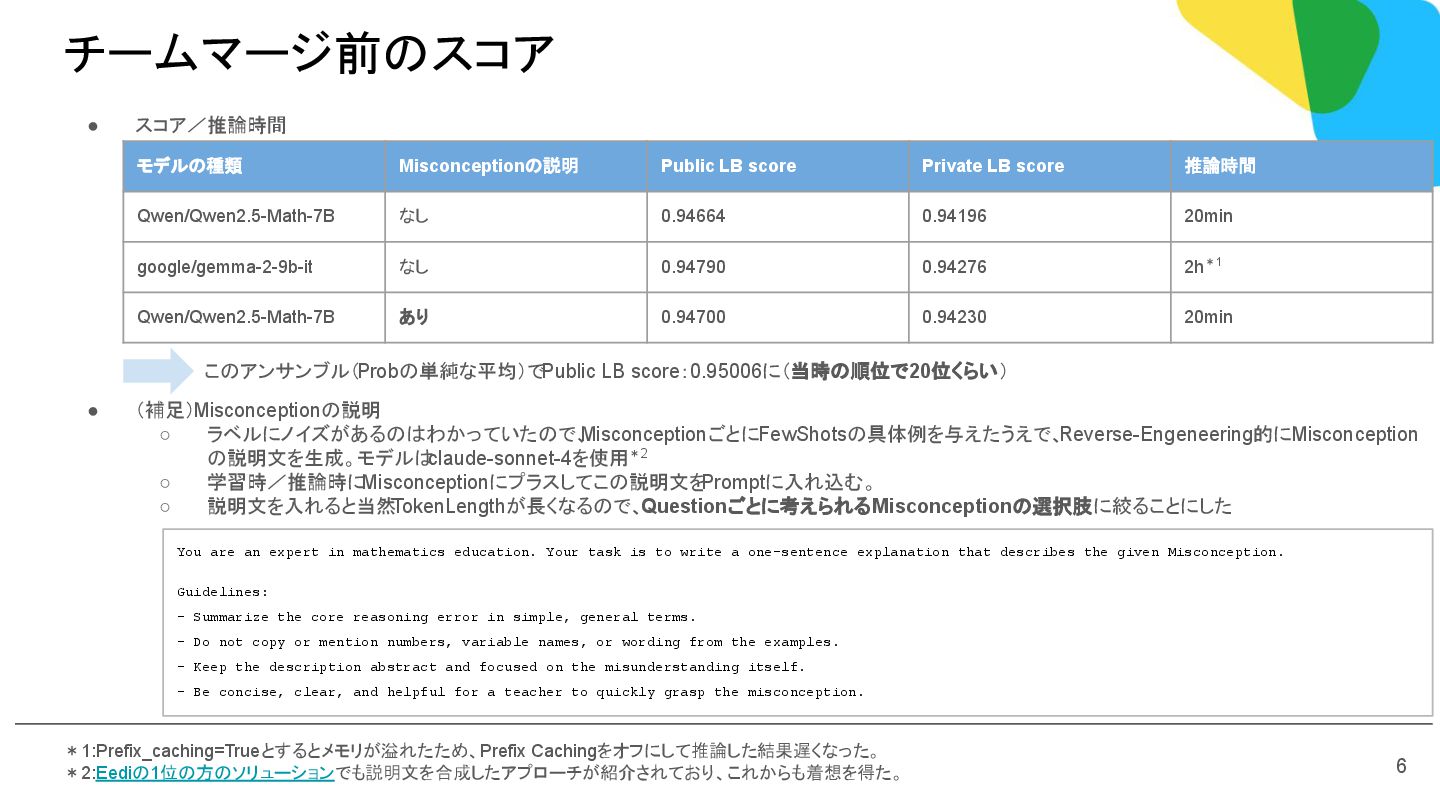
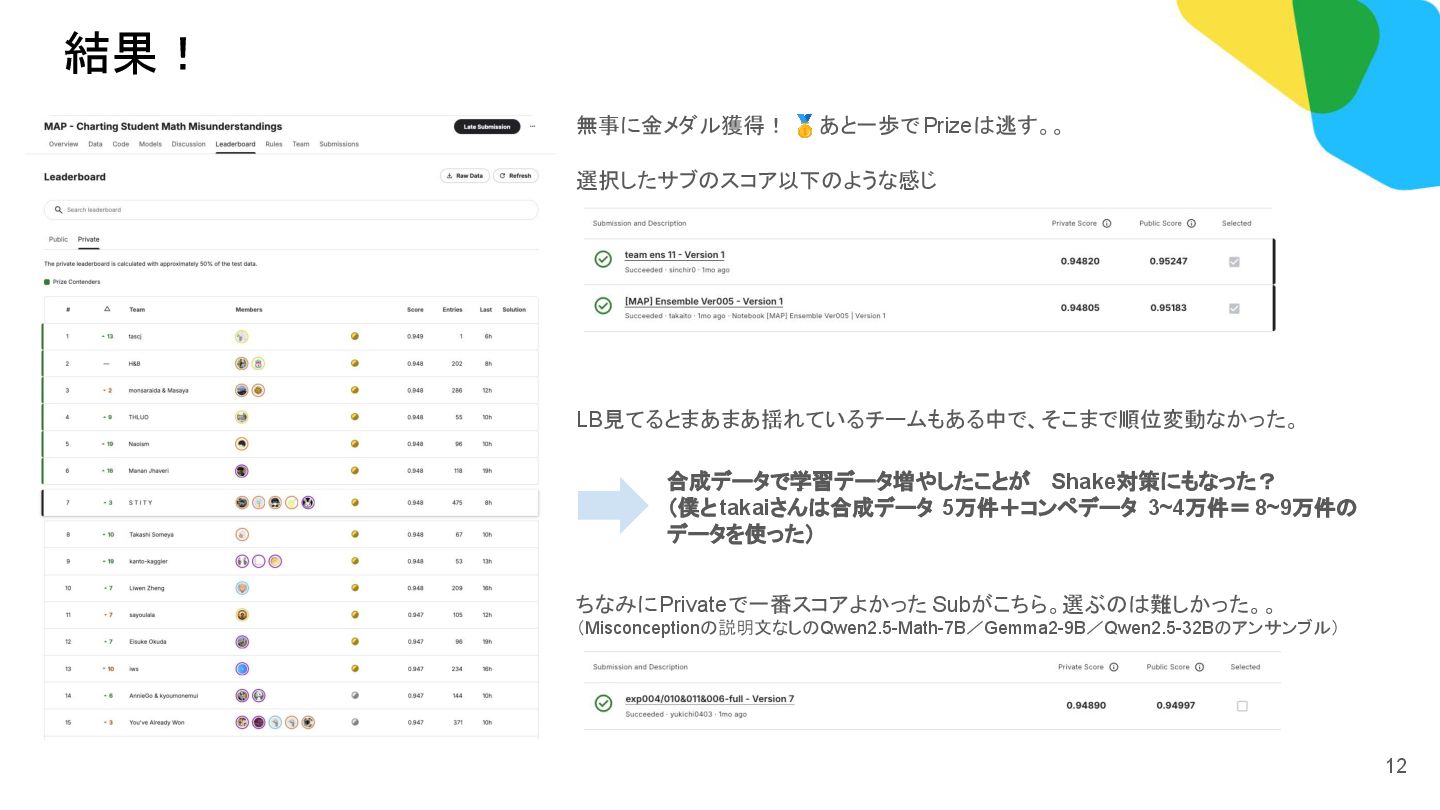
◦ 学習時/推論時にMisconceptionにプラスしてこの説明文を Promptに入れ込む。 ◦ 説明文を入れると当然 TokenLengthが長くなるので、Questionごとに考えられるMisconceptionの選択肢に絞ることにした チームマージ前のスコア モデルの種類 Misconceptionの説明 Public LB score Private LB score 推論時間 Qwen/Qwen2.5-Math-7B なし 0.94664 0.94196 20min google/gemma-2-9b-it なし 0.94790 0.94276 2h*1 Qwen/Qwen2.5-Math-7B あり 0.94700 0.94230 20min *1:Prefix_caching=Trueとするとメモリが溢れたため、Prefix Cachingをオフにして推論した結果遅くなった。 *2:Eediの1位の方のソリューションでも説明文を合成したアプローチが紹介されており、これからも着想を得た。 You are an expert in mathematics education. Your task is to write a one-sentence explanation that describes the given Misconception. Guidelines: - Summarize the core reasoning error in simple, general terms. - Do not copy or mention numbers, variable names, or wording from the examples. - Keep the description abstract and focused on the misunderstanding itself. - Be concise, clear, and helpful for a teacher to quickly grasp the misconception. このアンサンブル(Probの単純な平均)でPublic LB score:0.95006に(当時の順位で20位くらい) 6
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}