Natural language (built-‐into word out of typical dicHonaries, but present in “street vocabulary”). – Needs a postprocess phase. This try to get the semanHc informaHon of the text transcribed using Natural Language Understanding => InformaHon ExtracHon, AbstracHng, etc.
{kind=link}
{kind=link}
{kind=link}
![public $root = $integrador; $integrador = [$GARBAGE]](https://files.speakerdeck.com/presentations/a3d8266bfe074ffa906542dcb8a253d0/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
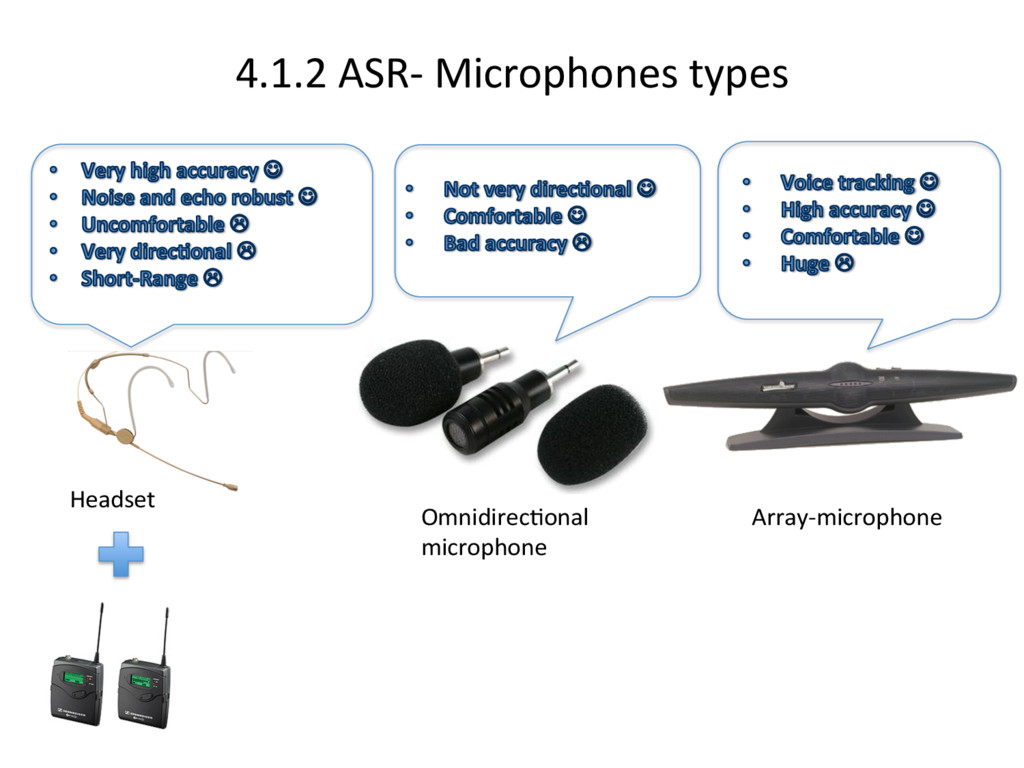{kind=link}
{kind=link}
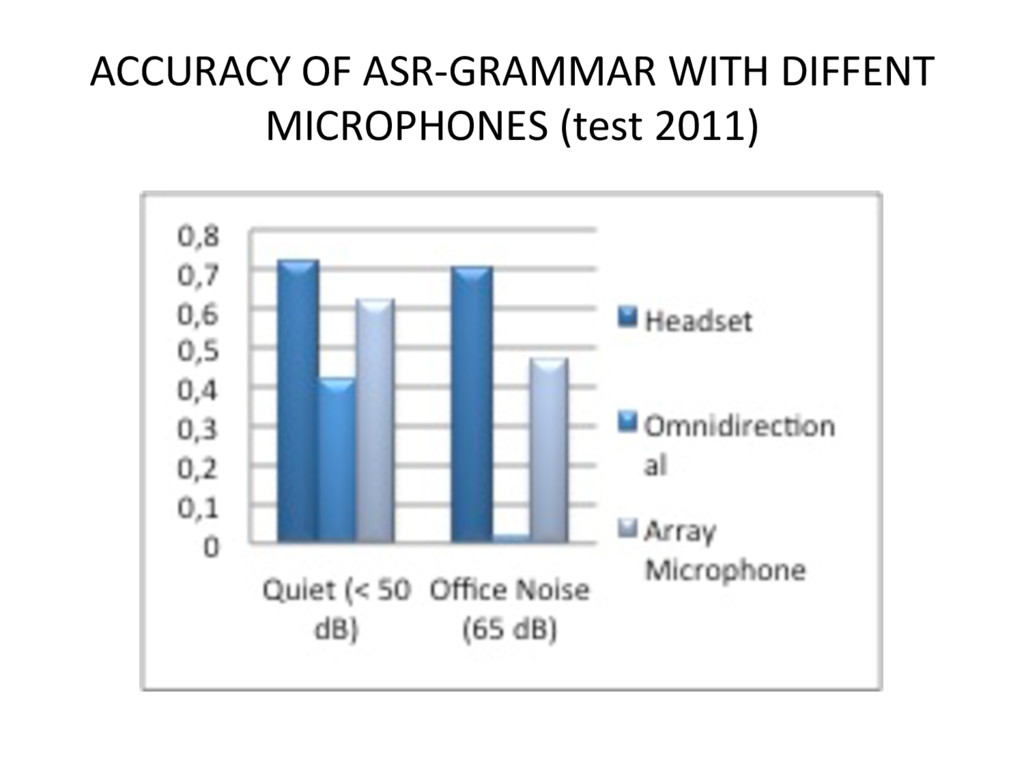{kind=link}
{kind=link}
{kind=link}