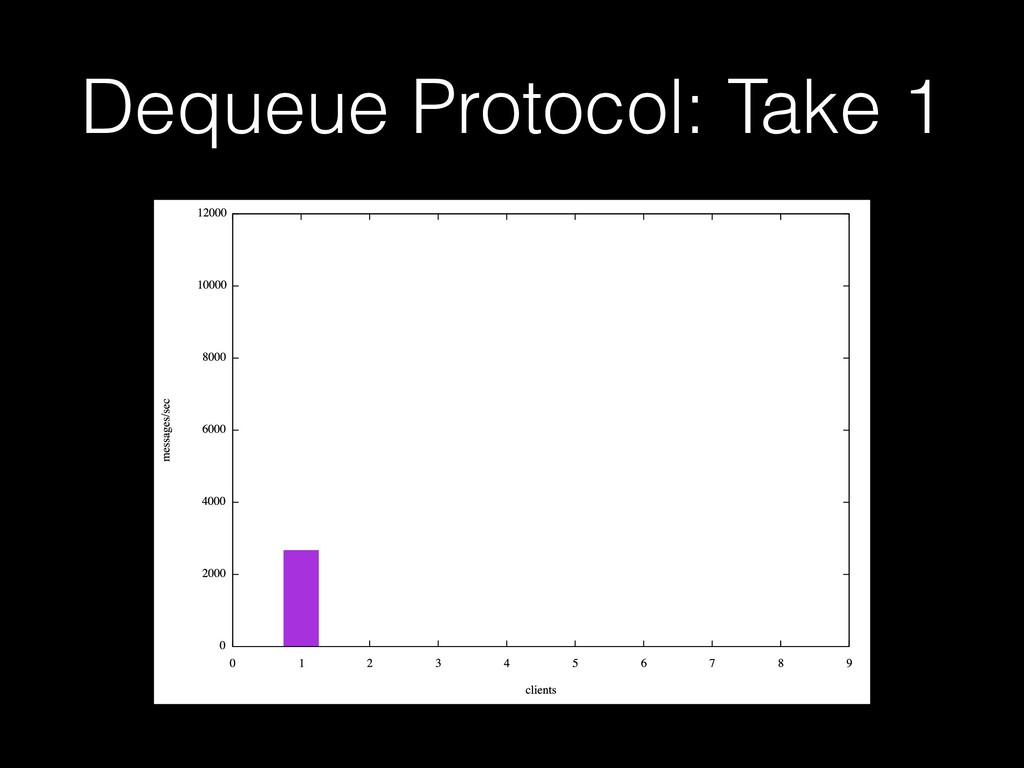
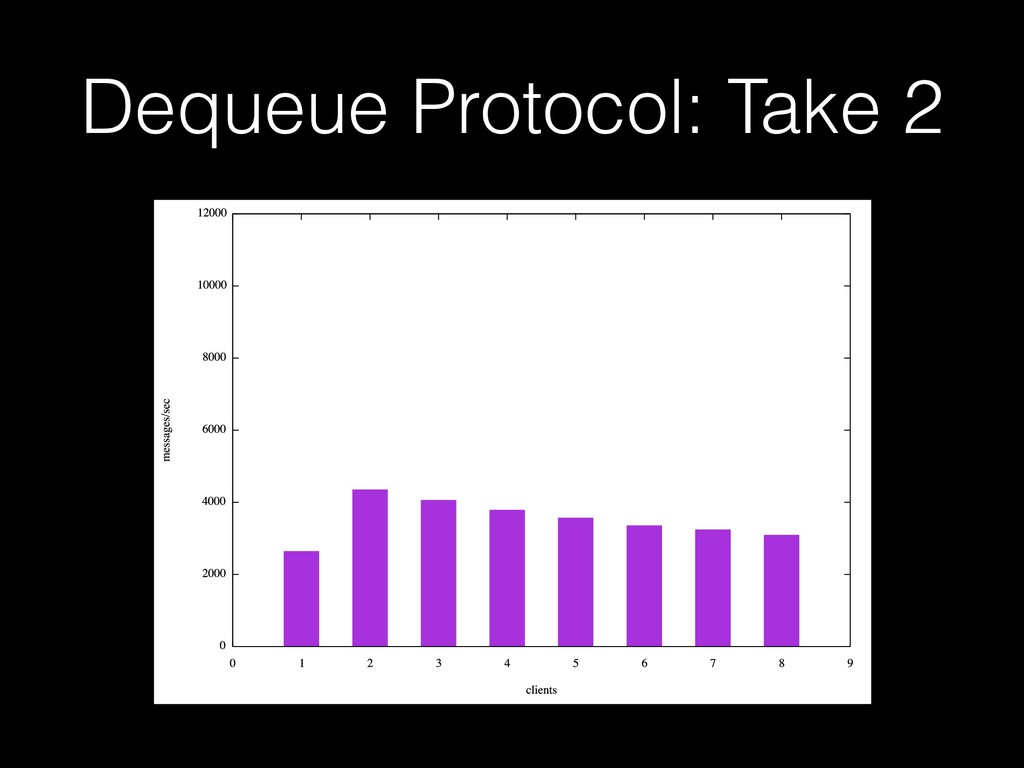
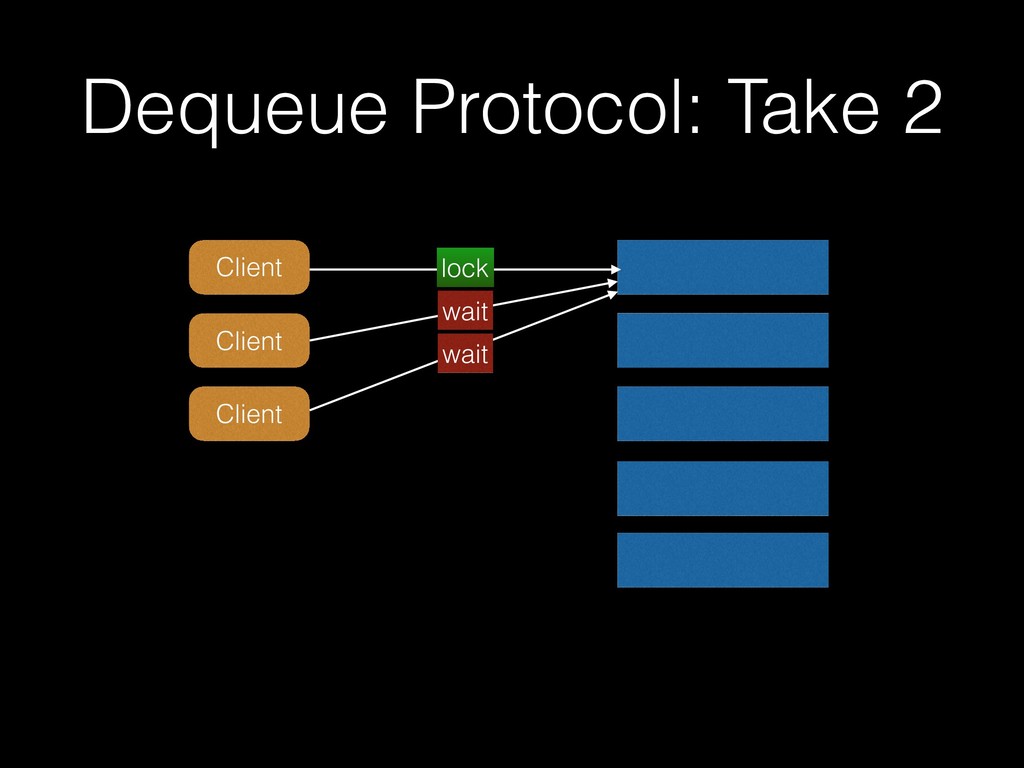
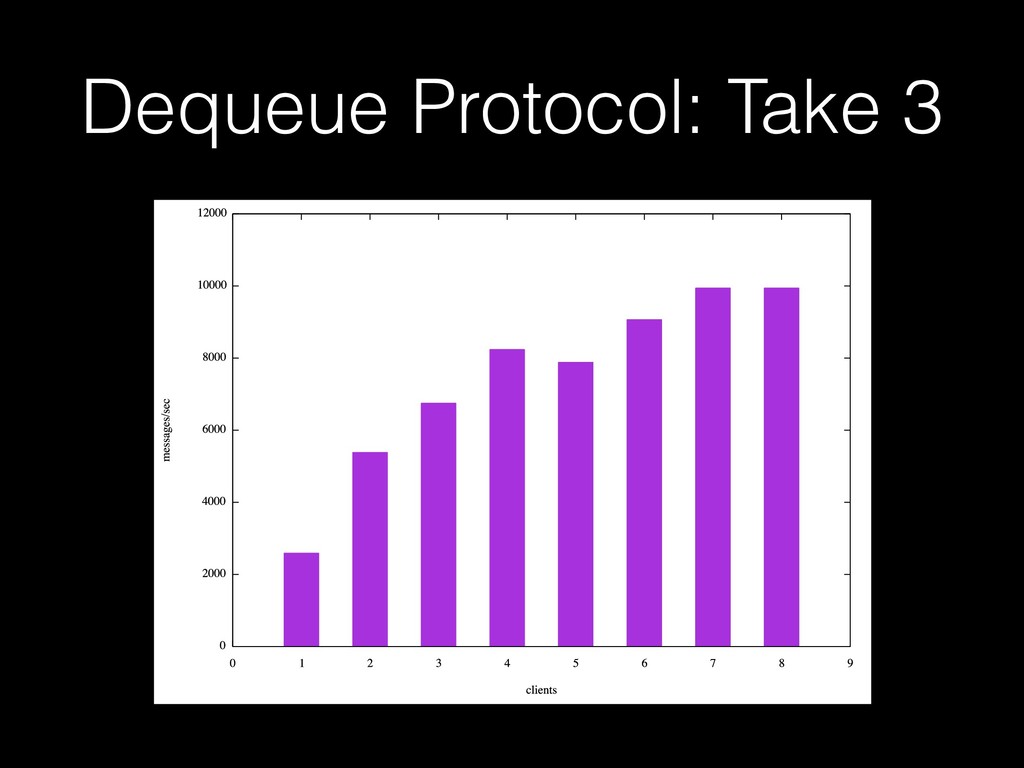
A talk I gave at PGCon 2016 in Ottawa. My first visit to a major PostgreSQL conference, my first attempt at public speaking, my first visit to Canada. Woo. A talk about job queue workloads in PostgreSQL. (I also gave variations of this talk at the PostgreSQL users group in Wellington, NZ, and PGDay 2017 in Melbourne, Australia).
https://www.pgcon.org/2016/schedule/events/929.en.html
https://www.youtube.com/watch?v=B81nQLg4RuU
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}